NVIDIA DGX spark 不是這邊的主力部署, 不過這裡有一些數據分享給想知道或是有類似需求的朋友.
我的LLM的用途主要是工作上(驅動/韌體 開發/debug), 基本上需要模型跑在全精度或至少Q8量化以上. 我試過FP8相較BF16已經略差, Q4實際使用上是無法達到我的需求.
在這個前提下, 我需要的是更多的vram, 能夠跑Q8以上的模型, 並且至少需要256K context, 才能比較舒適的使用. DGX spark雖然不快, 但是如果我想跑minimax, deepseek, mimo之類的模型, 選擇似乎也不多. 如果有超大模型, 超長上下文, 多併發的需求, 同時又不能使用雲端模型的情況下, DGX spark是可以考慮的選擇之一.
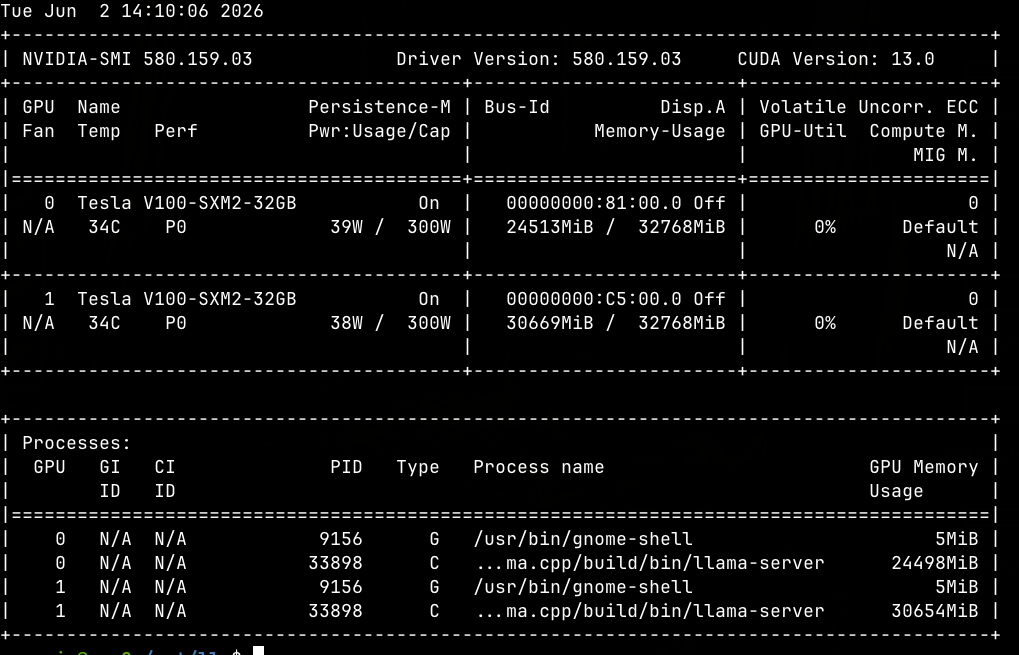
現在我手上有4台DGX spark, 因為QSFP switch還沒到手, 所以只能先倆倆對接, 四台還沒辦法接在一起. DGX spark自帶兩個connectX-7 QSFP介面, 把多台接在一起的時候,透過RDMA 和張量並行,集群可實現部分加速, 越多台速度越快,這應該比mac的exo快, 我沒有多台mac, 所以不知道實際狀況如何. 目前我是跑Qwen/Qwen3.6-27B-FP8(模型權重30.9G)跟deepseek-ai/DeepSeek-V4-Flash全精度模型(模型權重160G), 下面速度供大家參考:
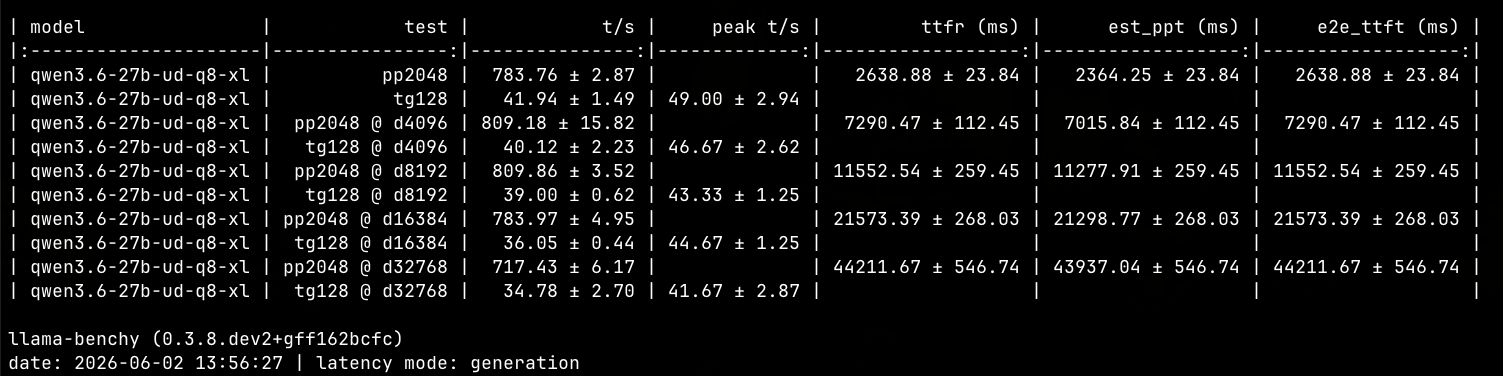
Qwen/Qwen3.6-27B-FP8單spark:

Qwen/Qwen3.6-27B-FP8雙spark:
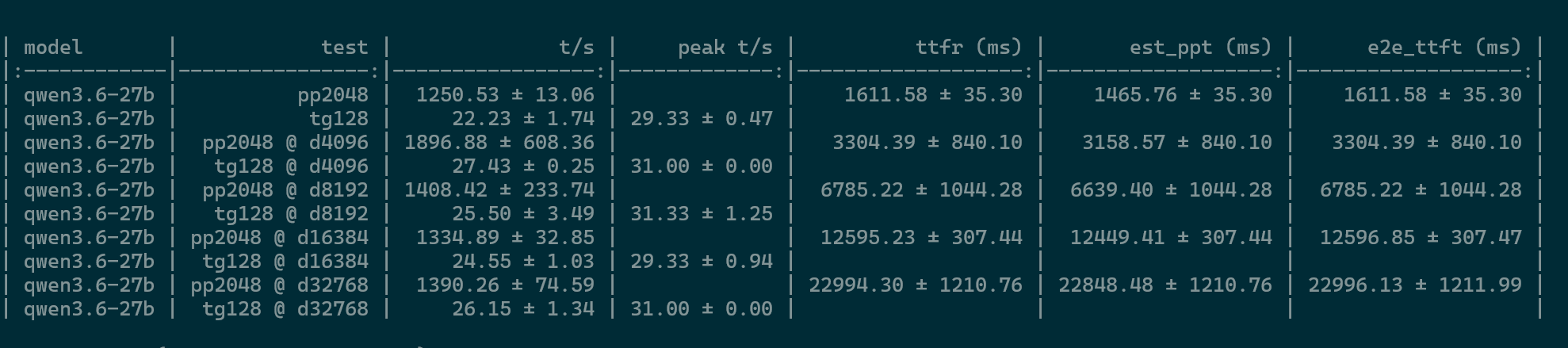
deepseek-ai/DeepSeek-V4-Flash, 雙spark:

速度不是非常快, 不過因為平常我也不跟它們聊天, 都是用opencode或pi把工作丟給它們就去做別的事了, 所以也還好. 基本上有個20我就覺得可以用了, 畢竟這是8 bit的模型, 也不能強求什麼了.
這兩個模型依我的使用比較起來, 感覺智力上相當接近, qwen 3.6 27B在tool call上出錯比較少, 是真的能打. 雖然跟claude opus 4.7或GPT 5.5相較之下還是有差異, 不過也堪用了.
至於ComfyUI嘛.. 它就是一個沒有什麼跑不動, 卻也沒有什麼跑的快的狀態.
6/2更新, deepseek v4 flash spark論壇上有新的優化, 請gemini cli照做後性能有所提升.
論壇網頁:
https://forums.developer.nvidia.com/t/deepseek-v4-flash-official-fp8-running-across-2x-dgx-spark-tp-2-mtp-200k-ctx-recipe-numbers/370309/135
測試: