
@ezios nvlink 多贵啊,有点浪费了吧。如果用nvlink,数据交换基本走nvlink,有可能第二张不需要pcie速度。一般来讲,x1 是矿卡标配,用pcie跑tp还是不要太慢,每张卡地位是对等的,没有第二张怎样的说法。说是不要太慢,有 gen3 x8 = gen4 x4 也就够了,很多主板还是有的。
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s -
你们说说这是在干啥,把人家华南金牌都干缺货了人不在国内,直接搞了块二手技嘉 ga-x99-ud4p 加 E5 2690v4,四条间隔2槽的pcie,原生支持4路SLI。DDR4 32GB(感觉其实16GB问题不大)。不需要延长线直插四张 3060,虽然不比双卡快但一共48GB,加起来折合不到8000人民币,还是非常非常香的
-
来自RTX PRO 5000的碎碎念想说现在很多机箱每个槽中间没有那一条,整体就是一个洞
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@joker_chang 搞了张 x99,应该直接插上就可以了。然后在 nvtop 里面检查一下至少有 PCIe Gen 3@ 8x 就行了
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@joker_chang 这个真不懂,没有玩过 x99
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@vosrock 不错,显存差点,搞两张
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@vosrock 上哪找 3000 人民币的 4080?
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@asd2667 赞!倒腾一下 #23225 可以双 q8 或双 q4,但目前性能略有损失。
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@kop-wang 尝试下来确实有用。按评论所说,回退到 #22616 之前,打上 #23225 补丁,开 MTP 可以开到 128k 上下文了
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@tommam 理论上 Gen4 x4 就相当于 Gen3 x8 了,很多新一点的主板是有的。比如 1 x PCIe 4.0 x16 + 1 x PCIe 3.0 x16,或者 1 x PCIe 5.0 x16 + 1 x PCIe 4.0 x4。不是非得 x8+x8。
随便挑一个 华硕TUF GAMING B760M-PLUS D4重炮手,就是 Gen5 x16 + Gen4 x4。

这种配置近期似乎比较流行。但 Gen4 x4 那一路走的是芯片组不是 CPU,可能会有一点影响。
主板支持 PCIe 通道拆分的话可以买线拆分成 Gen5 x8+x8。
-
双 3090(NVLink)跑 Qwen3.6-27B,128K 上下文实测应该可以快很多,可以看一下我的双 3060 帖子
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@kop-wang 感谢提供信息
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s@kop-wang 帖子里已经说明了,SPLIT_MODE_TENSOR 目前开不了 kv 量化。
-
从纯游戏机改成游戏+AI双用机,Qwen 3.6 27B MTP 速度只有 37 t/s,求大神指点怎么升级可以去看看我刚发的双 3060 帖子,主板合适的话 5080 16GB + 5060Ti 16GB 肯定能跑到 65。
-
(双卡指南) 最丐 Qwen3.6-27b - 3000 元双 RTX 3060 - 50t/s注意:以下方法,双 N 卡的,最弱超过 3060 12GB 的,统统都可以尝试。
虽然入手了 7900 xtx,但实测下来感觉算力发挥很不稳定。开 MTP 后 decode 确实可以达到 40-60 t/s,但 prefill 怎么也快不起来。无论 rocm 还是 vulkan,prefill 速度相当不稳定,哪怕是长段 prompt 最多也就 500+ t/s,常常只能跑到 300+ t/s。
一直手痒想试试极限丐版 24GB 双 3060,正好这几天以合理的价格淘到了第二张。话不多说,拆掉 7900 xtx,上机实测。
测试配置
- 测试平台:i7 4770k + 技嘉 GA-Z87MX-D3H
- 相当古董的平台了,用了十多年。值得注意的是它支持 SLI,两条主 PCIE 插槽同时使用时等效于两条 PCIE 3.0 x8 插槽。较新的主板似乎很少有这种分配,但不少会有一条满速 PCIE 5.0 x16 加一条 PCIE 4.0 x4。总所周知 PCIE 4.0 x4 等效于 PCIE 3.0 x8。所以这个平台跑双卡的 PCIE 条件和较新的主板其实是相同的。
- 显示器插主板用集显
- 系统:Kubuntu 24.04
- CUDA: 13.2
- 模型:
- unsloth/Qwen3.6-27B-MTP-GGUF
- unsloth/Qwen3.6-27B-GGUF
- 量化:Qwen3.6-27B-Q4_K_S.gguf
- 软件:llama.cpp 5/25/2026 master 自行编译 CUDA 版本,官方没有预编译Linux CUDA版本下载
- 前置安装
sudo apt install nvidia-cuda-toolkit
- 前置安装
- 配置(详细配置见帖子最后):
- tensor parallel
-sm tensor -ts 1,1 -sm tensor和-ctk-ctv没法同时开,也就是无法量化 kv cache,只能开到 64k 上下文。我一般需要开 160k 上下文,这就有点难受了(更新:打上补丁可以开到 128k 上下文)--spec-type draft-mtp --spec-draft-n-max 1这个配置比较稳定,--spec-draft-n-max 2很容易跑一段时间后因为瞬时显存消耗过大 OOM。
- tensor parallel
实测记录
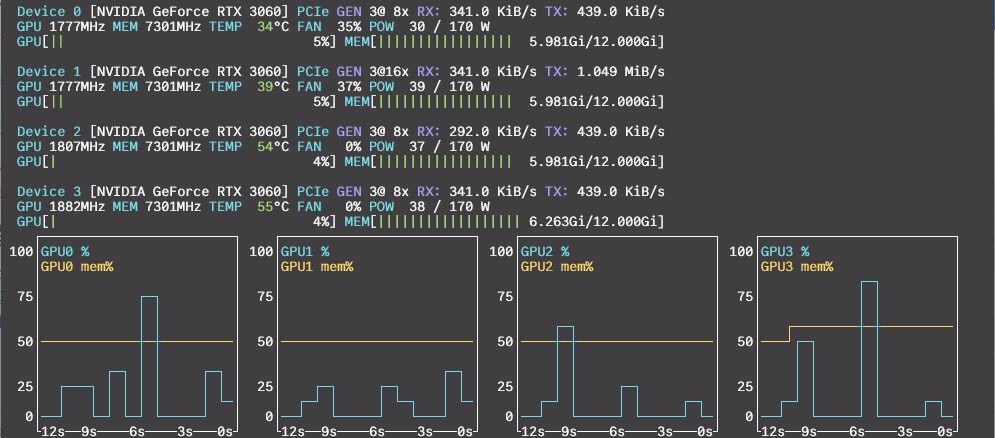
2.16.262.271 I slot print_timing: id 0 | task 701 | prompt eval time = 3056.70 ms / 1394 tokens ( 2.19 ms per token, 456.05 tokens per second) 2.16.262.276 I slot print_timing: id 0 | task 701 | eval time = 22538.95 ms / 975 tokens ( 23.12 ms per token, 43.26 tokens per second) 2.16.262.277 I slot print_timing: id 0 | task 701 | total time = 25595.65 ms / 2369 tokens 2.16.262.291 I slot print_timing: id 0 | task 701 | graphs reused = 1016 2.16.262.292 I slot print_timing: id 0 | task 701 | draft acceptance = 0.77618 ( 593 accepted / 764 generated) 2.16.262.310 I statistics draft-mtp: #calls(b,g,a) = 10 1038 1038, #gen drafts = 1038, #acc drafts = 959, #gen tokens = 2076, #acc tokens = 1792, dur(b,g,a) = 0.018, 8380.839, 3.772 ms 2.16.263.267 I slot release: id 0 | task 701 | stop processing: n_tokens = 12343, truncated = 0可以看到,在 12k 的实际上下文长度下,pp 456.05 t/s,tg 43.26 t/s。初始速度甚至高达 pp 600+ t/s,tg 50 t/s。这个速度大大超出了我的预料。虽然没有 7900 xtx 的最大速度快,但速度极其稳定,GPU 占用率长时间稳定 100%,不得不说还是 CUDA 成熟。
另外,关闭 MTP 后 context 可以开到 96k,pp 速度更快,tg 速度下降到 31 t/s,也相当不错了。
Context Window Prefill (pp) Generation (tg) MTP 初始峰值 64k 620 t/s 50 t/s MTP 32k 64k 482 t/s 36.36 t/s 关闭 MTP 初始峰值 96k 620 t/s 31 t/s 关闭 MTP 20k 96k 605 t/s 29.10 t/s 关闭 MTP 50k 96k 438 t/s 26.59 t/s 总结
优点
- 性价比极高,目测闲鱼 3000 以内能够搞定。
- CUDA 生态完善,GPU 占用率长时间稳定 100%,编译完成后不用折腾,省心。
- 3060 身材苗条,有单、双风扇短版,大部分 ATX 和 mATX 主板、机箱都无压力。
缺点
- SPLIT_MODE_TENSOR 暂时无法使用 kv cache 量化,导致 24GB 仍稍显不足。但这肯定不是小众需求,简单 q8 也能翻倍到 128k / 192k,未来可期。一旦 kv 量化解决,我就可以把 7900 xtx 淘汰了。
推论
- 双 16GB、速度稍快的卡,比如 4060Ti、5060Ti,虽然性价比会下降,但效果只会更好。还是那句话,CUDA 发挥稳定,省心。同样是 32GB,比跛脚 AI PRO R9700 肯定快得多,价格还稍低。
- 更新:外网有人根据本帖配置用双 5060Ti 跑出 pp 700 t/s, tg 65 t/s。
其它
- vllm 也有简单尝试,但 vllm 可能是对 VRAM 紧张的场景优化不佳,怎么跑都 OOM。且 vllm 启动太慢了,调试麻烦,不折腾了。
附录
详细配置
--no-mmproj-offload \ -dev CUDA0,CUDA1 -sm tensor -ts 1,1 \ --fit off \ --host 0.0.0.0 --port "$PORT" \ -t 0 -ngl 99 -np 1 \ --kv-unified --flash-attn on --ctx-size 64000 \ # 或 96000 --spec-type draft-mtp --spec-draft-n-max 1 \ # 或去掉 -rea on \ --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0.0 --repeat-penalty 1.0 --presence-penalty 0.0
虽然入手了 7900 xtx,但实测下来感觉算力发挥很不稳定。开 MTP 后 decode 确实可以达到 40-60 t/s,但 prefill 怎么也快不起来。无论 rocm 还是 vulkan,prefill 速度相当不稳定,哪怕是长段 prompt 最多也就 500+ t/s,常常只能跑到 300+ t/s。
一直手痒想试试极限丐版 24GB 双 3060,正好这几天以合理的价格淘到了第二张。话不多说,拆掉 7900 xtx,上机实测。
测试配置
- 测试平台:i7 4770k + 技嘉 GA-Z87MX-D3H
- 相当古董的平台了,用了十多年。值得注意的是它支持 SLI,两条主 PCIE 插槽同时使用时等效于两条 PCIE 3.0 x8 插槽。较新的主板似乎很少有这种分配,但不少会有一条满速 PCIE 5.0 x16 加一条 PCIE 4.0 x4。总所周知 PCIE 4.0 x4 等效于 PCIE 3.0 x8。所以这个平台跑双卡的 PCIE 条件和较新的主板其实是相同的。
- 显示器插主板用集显
- 系统:Kubuntu 24.04
- CUDA: 13.2
- 模型:
- unsloth/Qwen3.6-27B-MTP-GGUF
- unsloth/Qwen3.6-27B-GGUF
- 量化:Qwen3.6-27B-Q4_K_S.gguf
- 软件:llama.cpp 5/25/2026 master 自行编译 CUDA 版本,官方没有预编译Linux CUDA版本下载
- 前置安装
sudo apt install nvidia-cuda-toolkit
- 前置安装
- 配置(详细配置见帖子最后):
- tensor parallel
-sm tensor -ts 1,1 -sm tensor和-ctk-ctv没法同时开,也就是无法量化 kv cache,只能开到 64k 上下文。我一般需要开 160k 上下文,这就有点难受了--spec-type draft-mtp --spec-draft-n-max 1这个配置比较稳定,--spec-draft-n-max 2很容易跑一段时间后因为瞬时显存消耗过大 OOM。
- tensor parallel
实测记录
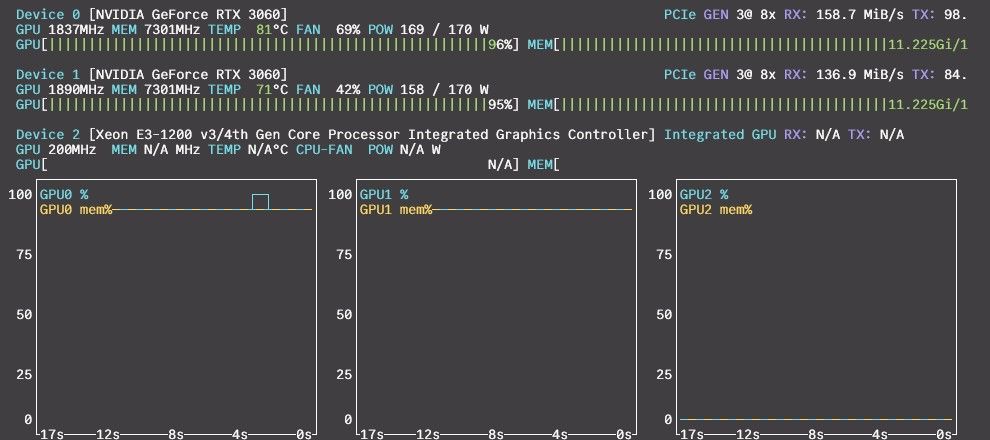
2.16.262.271 I slot print_timing: id 0 | task 701 | prompt eval time = 3056.70 ms / 1394 tokens ( 2.19 ms per token, 456.05 tokens per second) 2.16.262.276 I slot print_timing: id 0 | task 701 | eval time = 22538.95 ms / 975 tokens ( 23.12 ms per token, 43.26 tokens per second) 2.16.262.277 I slot print_timing: id 0 | task 701 | total time = 25595.65 ms / 2369 tokens 2.16.262.291 I slot print_timing: id 0 | task 701 | graphs reused = 1016 2.16.262.292 I slot print_timing: id 0 | task 701 | draft acceptance = 0.77618 ( 593 accepted / 764 generated) 2.16.262.310 I statistics draft-mtp: #calls(b,g,a) = 10 1038 1038, #gen drafts = 1038, #acc drafts = 959, #gen tokens = 2076, #acc tokens = 1792, dur(b,g,a) = 0.018, 8380.839, 3.772 ms 2.16.263.267 I slot release: id 0 | task 701 | stop processing: n_tokens = 12343, truncated = 0可以看到,在 12k 的实际上下文长度下,pp 456.05 t/s,tg 43.26 t/s。初始速度甚至高达 pp 600+ t/s,tg 50 t/s。这个速度大大超出了我的预料。虽然没有 7900 xtx 的最大速度快,但速度极其稳定,GPU 占用率长时间稳定 100%,不得不说还是 CUDA 成熟。
另外,关闭 MTP 后 context 可以开到 96k,pp 速度更快,tg 速度下降到 31 t/s,也相当不错了。
Context Window Prefill (pp) Generation (tg) MTP 初始峰值 64k 620 t/s 50 t/s MTP 32k 64k 482 t/s 36.36 t/s 关闭 MTP 初始峰值 96k 620 t/s 31 t/s 关闭 MTP 20k 96k 605 t/s 29.10 t/s 关闭 MTP 50k 96k 438 t/s 26.59 t/s 总结
优点
- 性价比极高,目测闲鱼 3000 以内能够搞定。
- CUDA 生态完善,GPU 占用率长时间稳定 100%,编译完成后不用折腾,省心。
- 3060 身材苗条,有单、双风扇短版,大部分 ATX 和 mATX 主板、机箱都无压力。
缺点
- SPLIT_MODE_TENSOR 暂时无法使用 kv cache 量化,导致 24GB 仍稍显不足。但这肯定不是小众需求,简单 q8 也能翻倍到 128k / 192k,未来可期。一旦 kv 量化解决,我就可以把 7900 xtx 淘汰了。更新:经 @kop-wang 提醒,回退到 PR#22616 之前,打上 PR#23225 补丁,开 MTP 可以开到 128k 上下文。
推论
- 双 16GB、速度稍快的卡,比如 4060Ti、5060Ti,虽然性价比会下降,但效果只会更好。还是那句话,CUDA 发挥稳定,省心。同样是 32GB,比跛脚 AI PRO R9700 肯定快得多,价格还稍低。
- 更新:外网有人根据本帖配置用双 5060Ti 跑出 pp 700 t/s, tg 65 t/s。
- 主要是 SPLIT_MODE_TENSOR 立功了。但凡双 N 卡的,最小超过 12 GB 的,统统都可以尝试。
其它
- vllm 也有简单尝试,但 vllm 可能是对 VRAM 紧张的场景优化不佳,怎么跑都 OOM。且 vllm 启动太慢了,调试麻烦,不折腾了。
附录
详细配置
--no-mmproj-offload \ -dev CUDA0,CUDA1 -sm tensor -ts 1,1 \ --fit off \ --host 0.0.0.0 --port "$PORT" \ -t 0 -ngl 99 -np 1 \ --kv-unified --flash-attn on --ctx-size 64000 \ # 或 96000 --spec-type draft-mtp --spec-draft-n-max 1 \ # 或去掉 -rea on \ --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0.0 --repeat-penalty 1.0 --presence-penalty 0.0 - 测试平台:i7 4770k + 技嘉 GA-Z87MX-D3H
-
从纯游戏机改成游戏+AI双用机,Qwen 3.6 27B MTP 速度只有 37 t/s,求大神指点怎么升级这一套按市价 $1300 + $500 + $200 再加张 5070ti $1000,价钱快赶上5090了,真不如全卖了直接上 5090。
不要瞎脑补了,什么全blackwell分层更平衡。分层的原理是一张一张接力跑,跑的时候别的卡都干等着,卡越多越浪费,更不要说什么 egpu 了。分层解决的是显存不够必须和主内存交换的瓶颈问题。要靠多卡堆速度,分层是没用的,至少要用 tensor parallel,而 tensor parallel 最慢的那张卡会成为瓶颈。
要上 80,靠堆卡很难。说实在,很少看到多卡长上下文能超过 60。或许主板 pcie 没瓶颈的话,双 5080 或者 4090 是可以,甚至双 5070 Ti 也有可能。但基本没见人报过数据,因为愿意花这钱的大部分直接 5090 了,还免去一切折腾烦恼。
-
请教一下大神,我的旧电脑如何怎样升级比较合适我怎么看 B450M MORTAR 有 4 条内存槽?确定没看错吗?
-
X99 Dual 7900 XTX + DFlash Qwen3.6-27B 實測这散热真的行吗?
-
雙 RX 7900 XTX + Ubuntu 24.04 + ROCm 6.3 實戰報告@terry 怎么感觉我的 ASRock Phantom Gaming Radeon RX 7900 XTX 动静巨大

-
Lucebox DFlash + PFlash 编译与部署指南 Qwen3.6-27B 方便抄作业 (Linux)@David-Zhang 不是这个意思。草稿质量高应该只影响预测命中率,最终准确率还是要看主模型和主模型的kv cache。