
交个作业。
我的机器是 M5 Pro 64GB(18 CPU + 20 GPU),测试了几个 runtime:Ollama、LM Studio 和 MTPLX。
模型主要是 Qwen3.6 27B 和 Qwen3.6 35B-A3B,均为 Q4 量化。
先说结论:
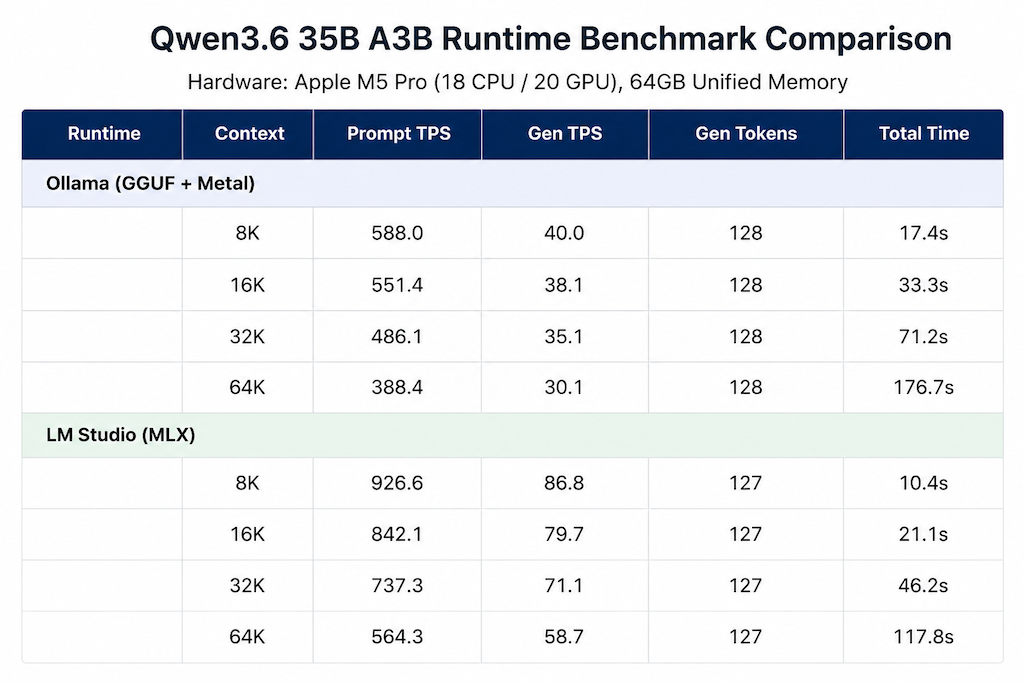
- 35B-A3B 在 MLX runtime(LM Studio)下,64K 上下文仍能跑到 50+ tok/s,已经达到可用状态,但智力相比 dense 27B 还是略弱一些。
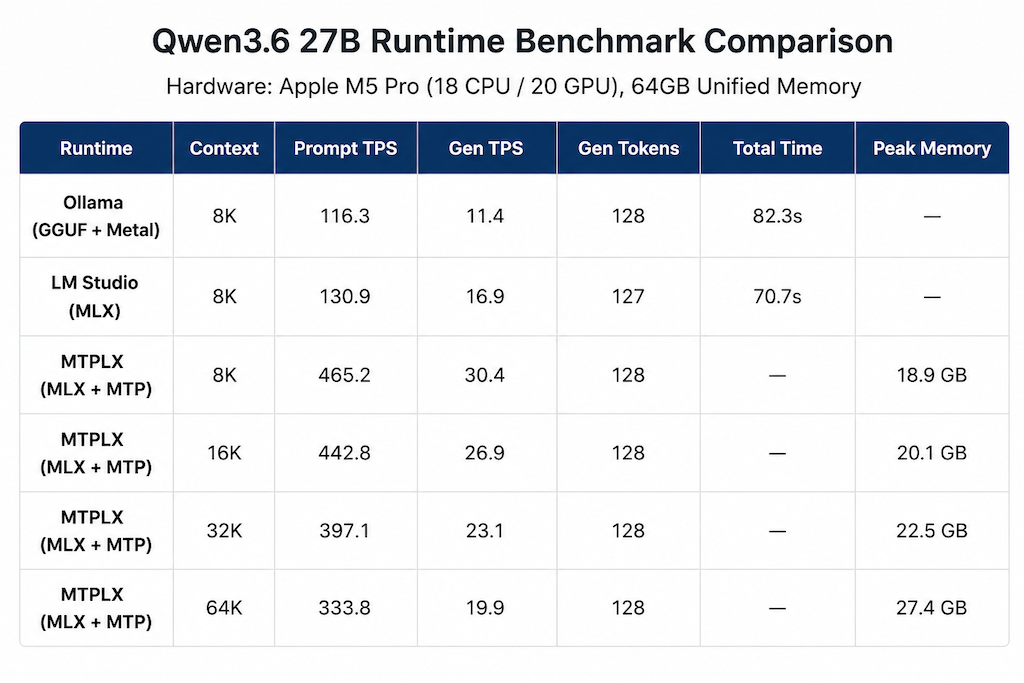
- 27B dense 在 MLX + MTP(MTPLX)下,64K 上下文能跑到 19+ tok/s, 提升巨大, 但仍然只是勉强可用.
- MTPLX 在 64K 下的 speculative decoding 命中率依然很高,更长上下文不知道.
- Μ5 max 内存带宽可以达到pro的两倍, 如果MTPLX的生态成熟了, 感觉27b的LLM可用.
35b测试结果:
27b测试结果:
说明:
1, 4k, 8K 上下文测试没有意义, 所以大家关注16K以上的结果就好.
2, Mac 环境很难搞干净, 我的MBP是主力机, 里面各种服务软件很多. 所以不能作为基准, 但是相互的比较还是有意义的.
3, vMLX 之前测试过, 很不稳定, 所以算了.
4, oMLX 看网上讲性能和LM Studio差不多, 所以也没测.

") . 当年攒机时候, CPU还有Cyrix和Ti, 显卡还有 ATI和S3, 还有voodoo, 当年吊打nvidia, 跑极品飞车的雨雾效果只有voodoo才能渲染出来. 操作系统当年只有 slackware, 后来才有红帽... 当时跑web还要用apache +cgi, 后来还有NT的IIS, 浏览器只能用lynx 和mosaic... 现在这些经验, 基本上一点儿用都没有了
. 当年攒机时候, CPU还有Cyrix和Ti, 显卡还有 ATI和S3, 还有voodoo, 当年吊打nvidia, 跑极品飞车的雨雾效果只有voodoo才能渲染出来. 操作系统当年只有 slackware, 后来才有红帽... 当时跑web还要用apache +cgi, 后来还有NT的IIS, 浏览器只能用lynx 和mosaic... 现在这些经验, 基本上一点儿用都没有了 

