
@Tony-Wang 可以跑的,还行。我max model len也是放满262k的 还行: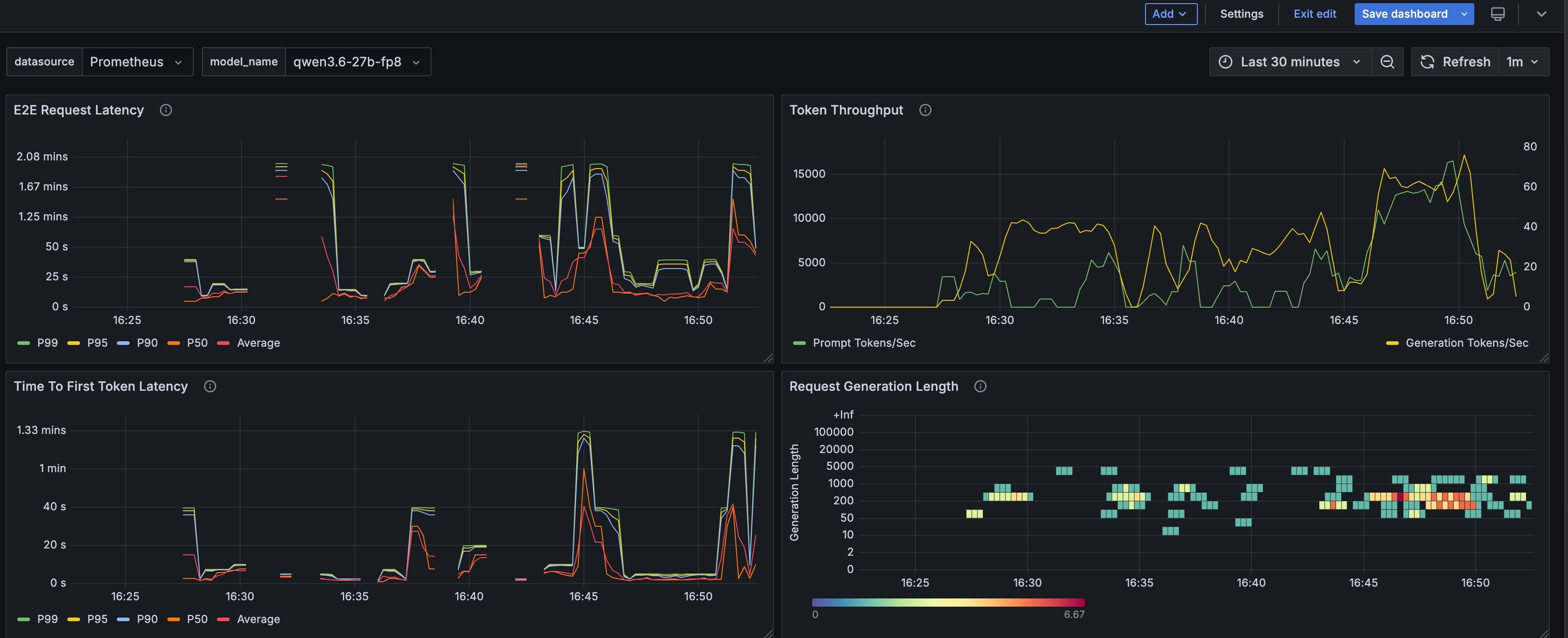
T
Tony Yun
@Tony Yun
-
GPT建议我降低--max-token-len 这合理吗? -
GPT建议我降低--max-token-len 这合理吗?@九龙杨生 0.98应该没什么问题,几乎没有因为OOM崩过
-
GPT建议我降低--max-token-len 这合理吗?@Xiaote 如果是coding呢?130k就不够了吧
-
GPT建议我降低--max-token-len 这合理吗?@566656661 L40S 48GB
-
GPT建议我降低--max-token-len 这合理吗?我现在的vllm启动命令:
--served-model-name qwen3.6-27b-fp8
--kv-cache-dtype fp8
--dtype auto
--max-model-len 262144
--gpu-memory-utilization 0.98
--max-num-seqs 32
--max-num-batched-tokens 4096
--trust-remote-code
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--reasoning-parser qwen3
--enable-prefix-caching
--compilation-config '{"cudagraph_capture_sizes": [1, 2, 4, 8]}'
--speculative-config '{"method": "mtp", "num_speculative_tokens": 3}'
--port 8000 --host 0.0.0.0但是经常超高cache,导致请求latency长达十几分钟。可是我不想限制max-model-len 这样最大上下文就没有260K了(gpt建议减半)。可130k上下文能干什么啊。
-
大家有什么让LLM 24小时不停工作的方案啊@kop-wang 感觉cron触发很呆 大部分时候都要人参与进去 单纯的cron好像很难生成什么高质量的内容
-
大家有什么让LLM 24小时不停工作的方案啊@566656661 那感觉还是deepseek v4 pro完全够用了 也用不了几块钱
-
Qwen3.6 27b FP8 260K CTX - 准备放弃了这正常thinking就老长了 叠加20tok/s 的吞吐慢如蜗牛。关了thinking直接降智,回答洗车店问题就整不对了。
用的L40S GPU,号称有FP8 tensor core,可没有任何感觉,跟用Q8感觉没有区别。
就这速度让agent干活我得等冒烟了。又没有特别好的工程方法让他们自己干活。 让它干一天估计不如deepV4Pro干一小时。
-
大家有什么让LLM 24小时不停工作的方案啊@tony-wang 因为租的云端GPU 不24小时跑回不了本
-
今天试了Qwen3.5 27B Q8量化 200K CTX@Shadow-Phoenix 用的就是uncensored 27B
-
大家有什么让LLM 24小时不停工作的方案啊老是手动trigger 要么agent干着干着就停了 人力监督很累
-
今天试了Qwen3.5 27B Q8量化 200K CTXGPU: L40S
确实可以的, prefill 2000 token/s, generation 20 tok/s.
但是跟deepseek V4 Pro 一比 又不香了 更快更好更便宜。不知道自己跑大模型有什么意义?