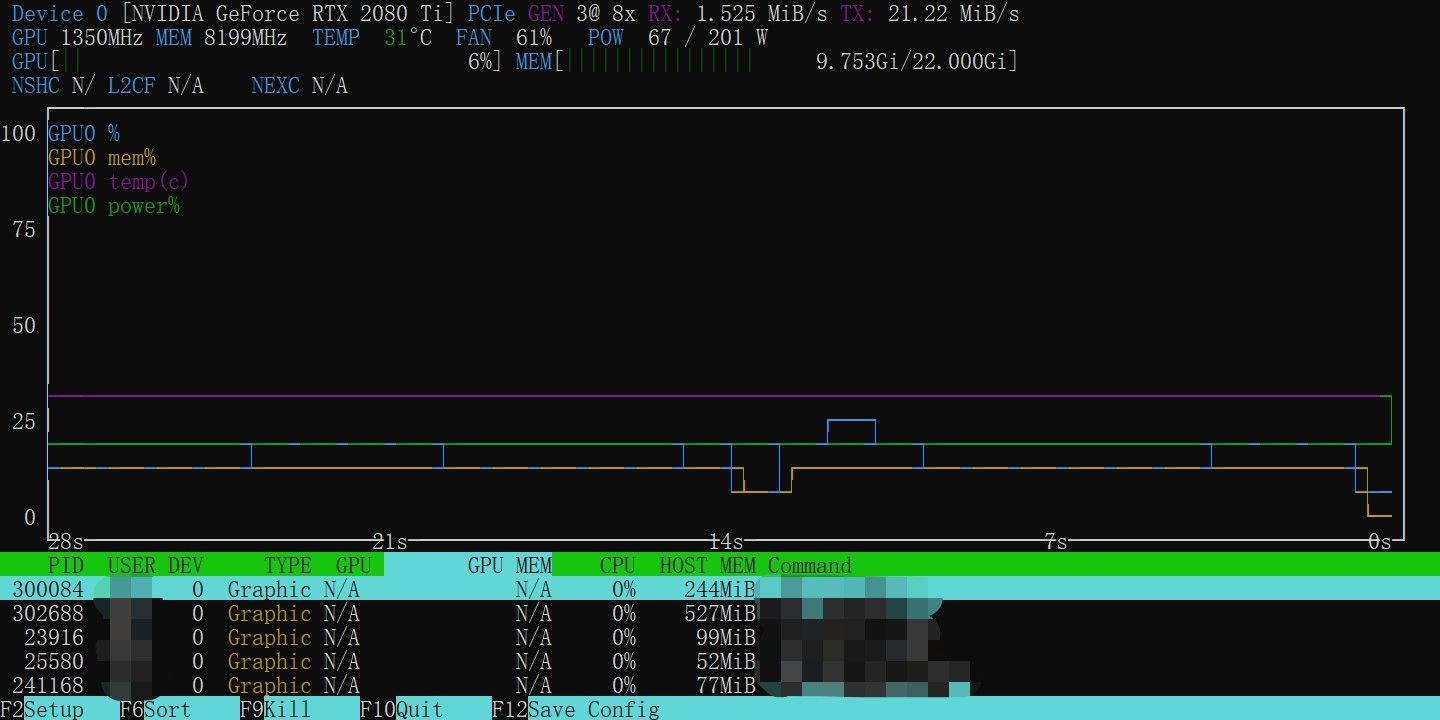
@Tide 限制显卡功率,同时给显存超频,测试一下稳定性。
我用着2080Ti 22GB改水冷的,用Nvidia Inspector工具,把功率限制在200W~230W,核心超频+40Mhz(也可以不超核心),显存超频+1200Mhz,跑下来温度最高只有不到50°C,热点不超过65°C,室温27°C左右。
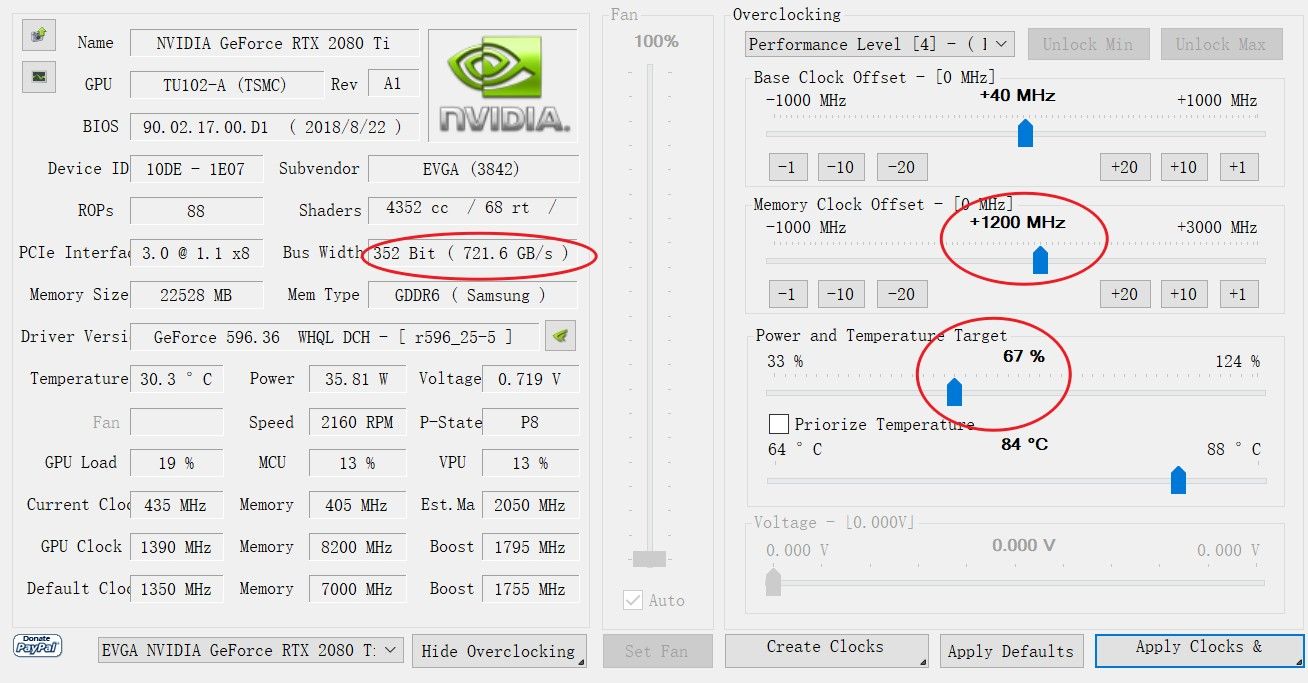
显存超频后带宽721.6GB/s,相比默认的616GB/s,提升超过17%,完美抵消限制功率导致的核心频率下降带来的性能损失,直接节约100W,33%的功率
Qwen 27B Q4_K_M,上下文开32K跑下来,decode 25 tok/s
用Llama.cpp benchmark跑分如图:
全默认,显卡功率300W:

核心超频+40Mhz,显存超频+1200Mhz:

核心超频+40Mhz,显存超频+1200Mhz,显卡功率锁67%限制在200W:

大语言模型主的矩阵运算要跑在GPU的Tensor Cores上,对GPU其他部分如大量的SM单元里的CUDA核心占用不高,GPU此时对功率的实际消耗并不需要太高。
并且大语言模型prefill阶段对核心频率有一定依赖,但降频对prefill性能影响不太大。
decode吐字阶段,对显存带宽的依赖程度大于核心算力,经常是显存带宽不足,喂不饱核心,核心有很多时间都在空转等数据。
综上,你的3080可以尝试限制功率,并小超显存,给显卡背板加装散热铝片+风扇。
然后实测看看数据。