
就DGX Spark虽说有128GB的统一内存,那可怜的273 GB/s的统一内存带宽,完全不值3万人民币以上的价格。
没有垃圾的产品,只有垃圾的价格,价格标个2万其实都还嫌它贵。
理想的情况是,带宽提升到800GB/s以上,其他无所谓。
Vivid Vector
@Vivid Vector
-
新手不要碰DGX Spark(重要事情说三遍) -
各位大神,我新机器,有没有必要升级内存@mark
你这内存64GB绰绰有余了,再升容量或频率对Qwen 27B这种稠密模型没有任何实质提升,要升就升显卡,或者再加一张DDR5内存那点小水管带宽以及CPU那点算力,在显存带宽和显卡张量核心面前就是渣滓
-
作为一个ai新手,想尝鲜尝试和学习,打算入一张V100 16G的,但是为啥论坛里完全不聊这张卡?真的是没有生产力?还是性价比太低?@hotpigwk
咸鱼上二手V100 16G的成品卡(转接好PCIE直插)就1100左右价格,直接买一张上来测试跑大模型,或者你要跑27B的就买2张,总价2200,自己折腾然后把实测数据截图发论坛里,就有话题有人聊了
-
装机翻车了,求救@pilipala
电源买振华或海韵,或者海韵代工的 -
Qwen3.6 27b & DeepSeek V4 Flash跑Hermes 资料截图,生成网页。@Chuyao-Chen
阉割版的RTX 6000D 84GB 是这个价格 -
买了2张5060Ti,谁能跑最便宜的Qwen 27B?@Tide
nvtop也是个不错的N卡监控工具,支持多卡
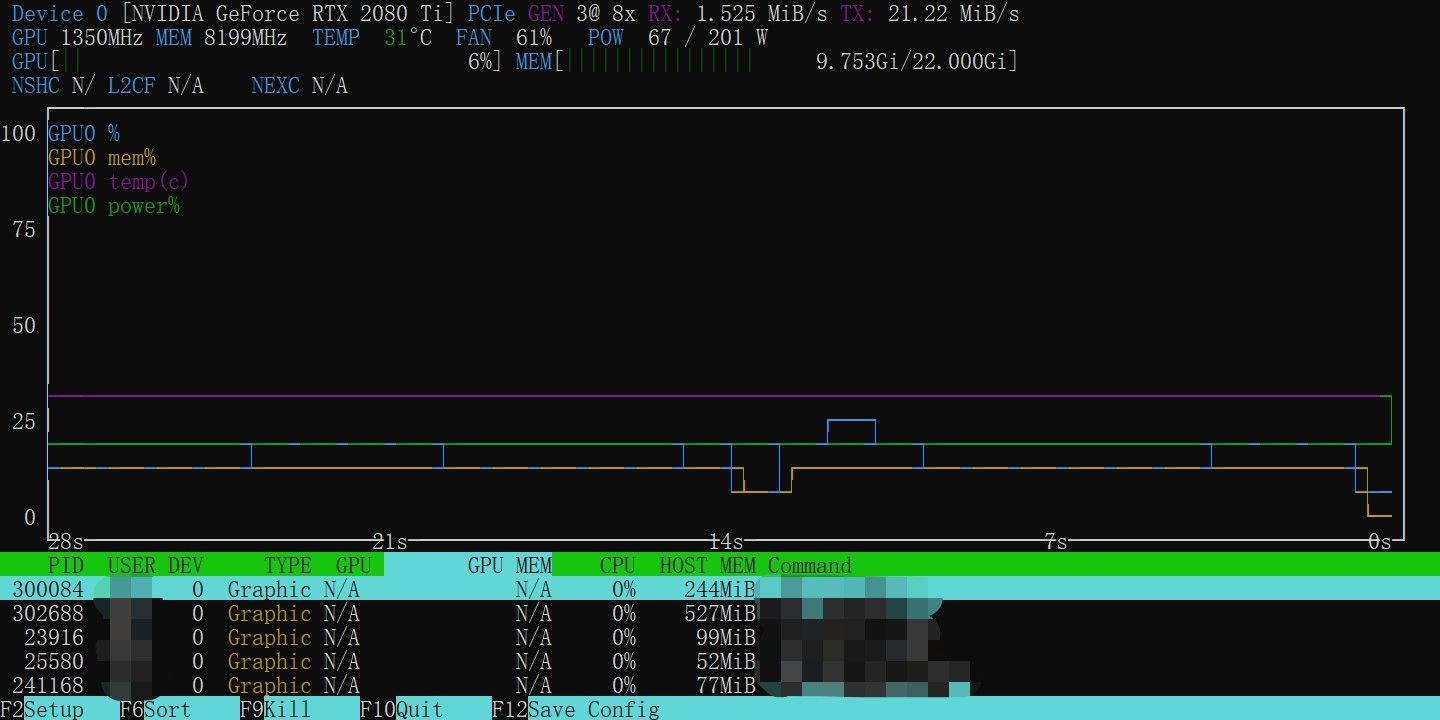
-
买了2张5060Ti,谁能跑最便宜的Qwen 27B?@暧昧光影
手上暂时没有3090Ti。
不过按我的经验,温度能控制得住的情况下,锁功率,小超核心,大超显存,对于跑LLM来说都适用。
B站有人实测PRO 6000 Max-Q 版,功率只有300W,相比满血600W的工作站版只损失10%的性能,而且他还没给显存超频。我看到的PRO 6000,跑LLM经常都是吃不满功耗,TDP 600W的工作站版,只吃到450W左右的样子。
跑满600W功耗的情况,通常是GPU SM里的CUDA核心满载,Tensor Cores也接近满载,同时显存空间和带宽也占用很高的情况才会出现。
LLM的矩阵运算主要靠Tensor Cores执行,且吃满显存空间和带宽,但SM CUDA核心通常空载。 -
买了2张5060Ti,谁能跑最便宜的Qwen 27B?@Tide 限制显卡功率,同时给显存超频,测试一下稳定性。
我用着2080Ti 22GB改水冷的,用Nvidia Inspector工具,把功率限制在200W~230W,核心超频+40Mhz(也可以不超核心),显存超频+1200Mhz,跑下来温度最高只有不到50°C,热点不超过65°C,室温27°C左右。
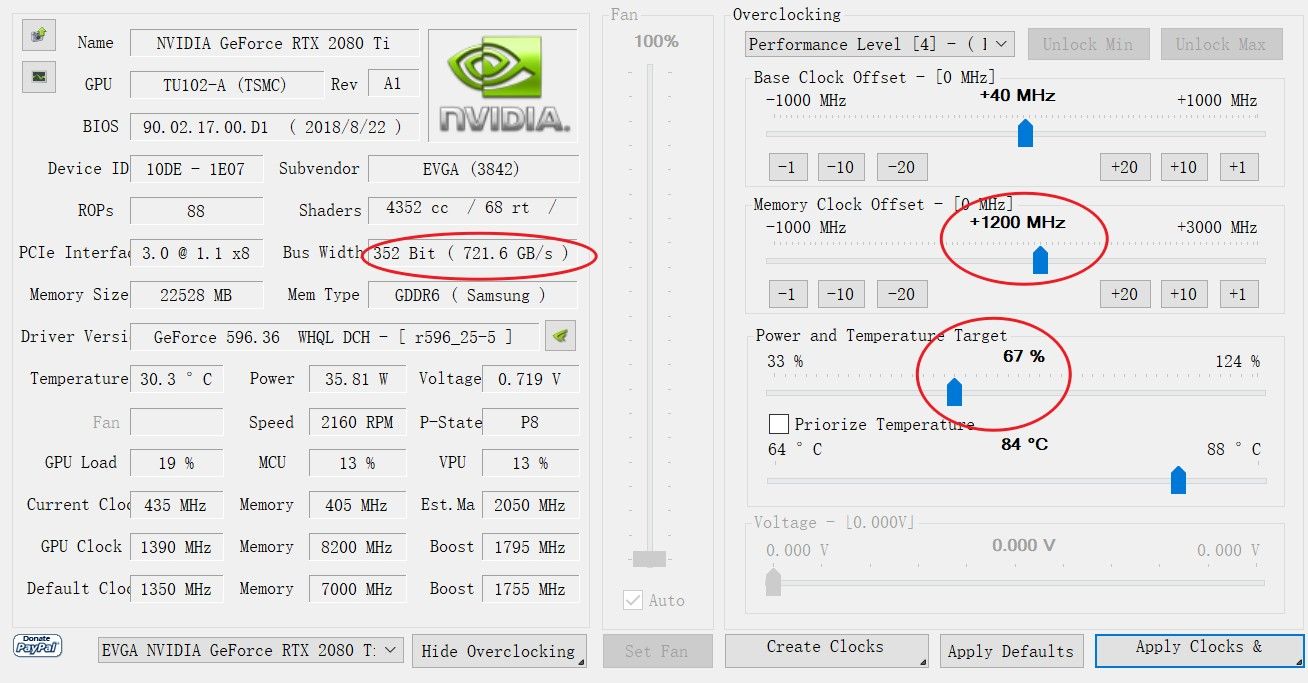
显存超频后带宽721.6GB/s,相比默认的616GB/s,提升超过17%,完美抵消限制功率导致的核心频率下降带来的性能损失,直接节约100W,33%的功率Qwen 27B Q4_K_M,上下文开32K跑下来,decode 25 tok/s
用Llama.cpp benchmark跑分如图:
全默认,显卡功率300W:

核心超频+40Mhz,显存超频+1200Mhz:

核心超频+40Mhz,显存超频+1200Mhz,显卡功率锁67%限制在200W:

大语言模型主的矩阵运算要跑在GPU的Tensor Cores上,对GPU其他部分如大量的SM单元里的CUDA核心占用不高,GPU此时对功率的实际消耗并不需要太高。
并且大语言模型prefill阶段对核心频率有一定依赖,但降频对prefill性能影响不太大。
decode吐字阶段,对显存带宽的依赖程度大于核心算力,经常是显存带宽不足,喂不饱核心,核心有很多时间都在空转等数据。综上,你的3080可以尝试限制功率,并小超显存,给显卡背板加装散热铝片+风扇。
然后实测看看数据。