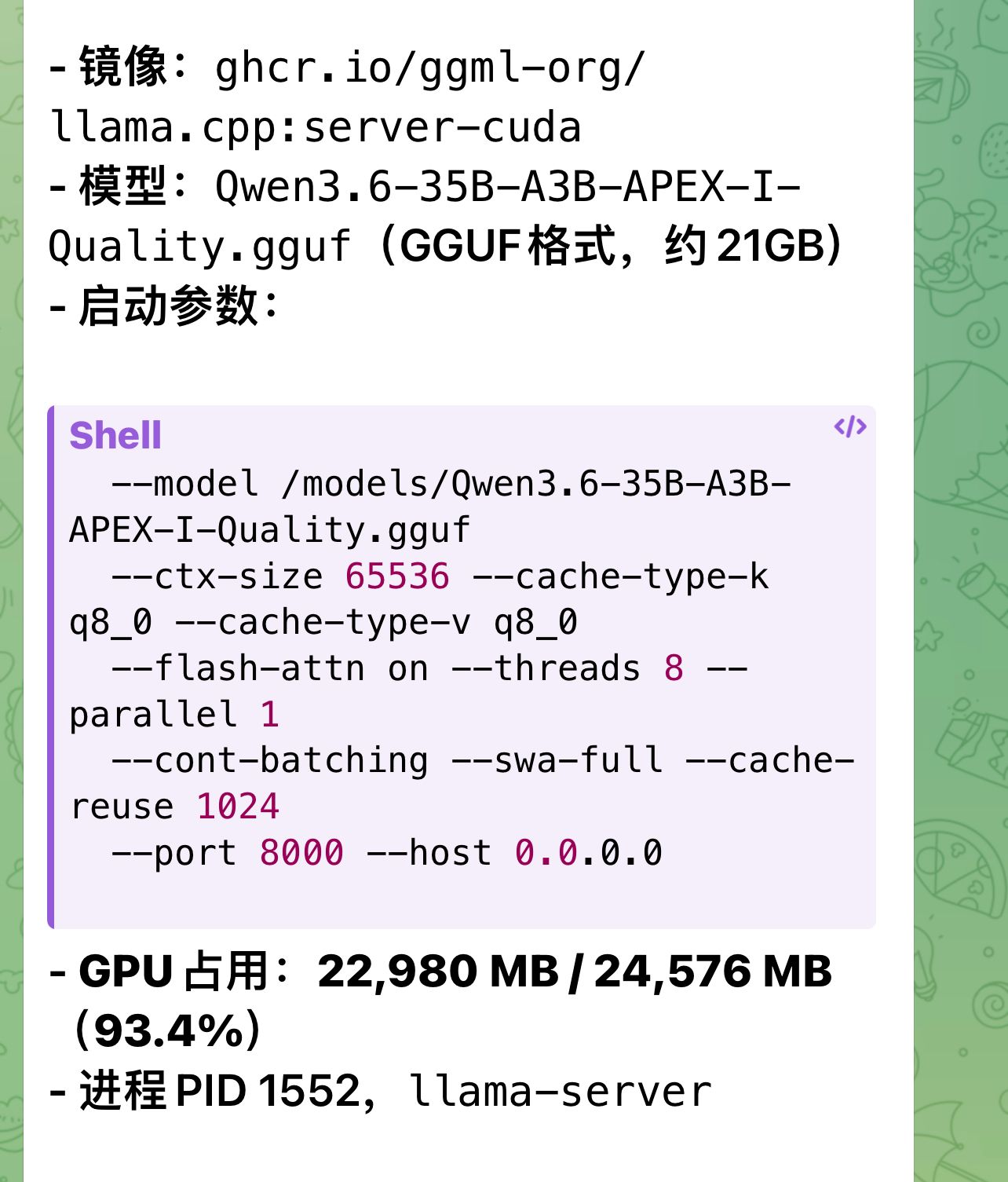
纠结电费的。可以不用:华南 x99 +e 2685 +3090
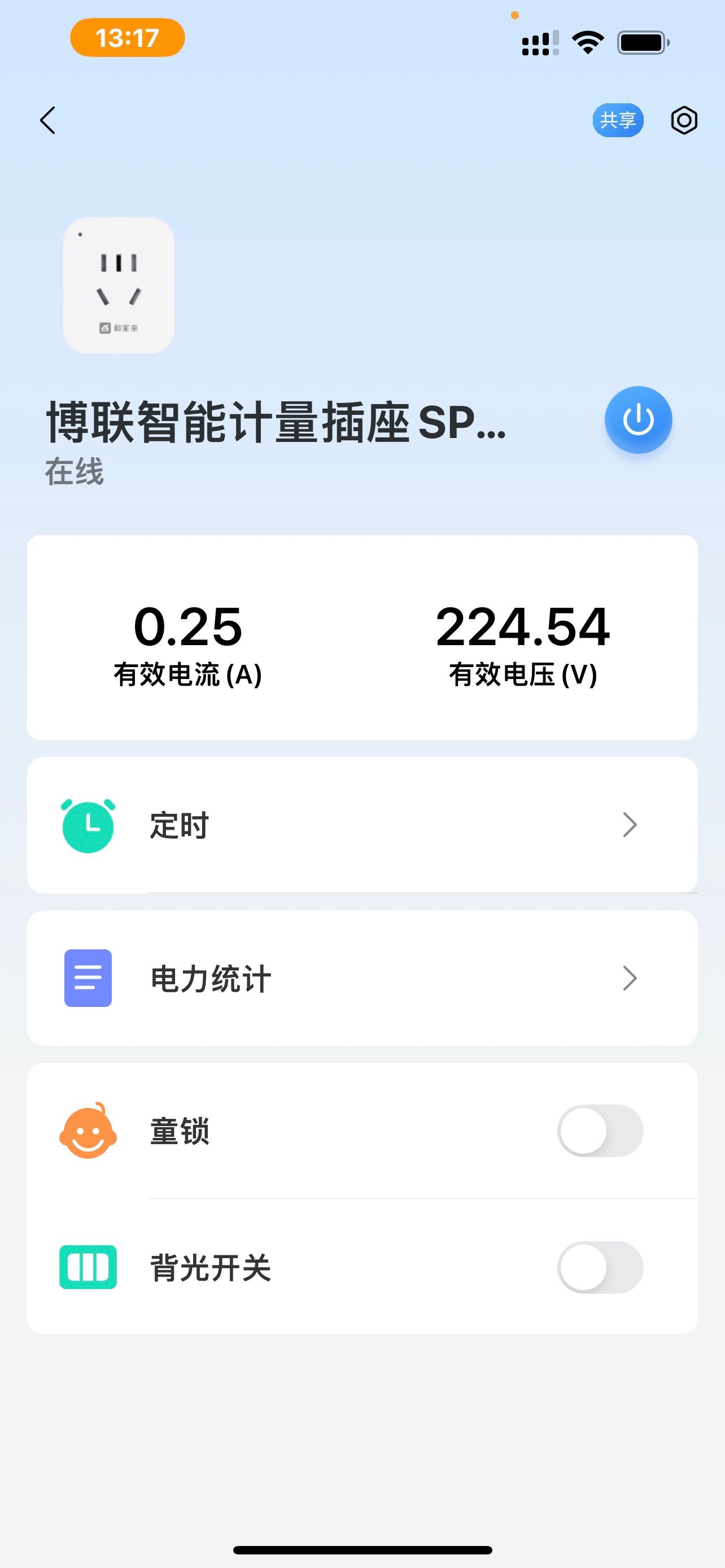
- 实测显卡没有加载任何东西的时候,50w 左右
2.显卡一旦跑过模型,然后没有任何负载,也有 20w 功耗
实测待机 70w
然后华南的主板没有 s3.也就是没有内存待机功能,只能休眠,休眠需要把内存写入 ssd。内存越大越慢开机也慢。而且服务器这么休眠重启后稳定性大为下降。所以根本不可能休眠
我的方案是,淘宝,拼多多,买一个 pci 的开机卡,然后把文档发给 herems。做一个开机就好了。
我的 hermes 默认用 deepseek。模型可以随时切换到本地,用完切换回 deepseek 就好了,顺便让 herems 把服务器关闭。
一切都可以在 hermes 的管理下,不需要人去动。
这么用还解决一个服务器噪音问题。