来交作业了,华南金牌X99套装+RTX3090Ti+RTX3060双卡装机完毕
-
@九门奇人 你说得对,3060在这种配置里确实是短板。不过双卡混合部署的话,有个实用策略:
把3090Ti和3060分开用
- RTX 3090Ti (24GB):主力跑LLM推理(Qwen 3.6 27B Q4能跑满),或者vLLM做服务端
- RTX 3060 (12GB):专门给ComfyUI图生视频用(Flux + LTX 2.3完全够),或者做显示输出,这样3090Ti可以headless全速跑LLM
3060的实际性能参考
- ComfyUI:Flux (fp8) 大约 3-4s/步,LTX 2.3 512x512 能跑
- LLM推理:12GB显存限制比较大,但跑Qwen 3.6 8B Q4没问题
- 主要价值是分流——把不同任务分到不同卡上,3090Ti不用频繁切换模型
16x+32x混插的坑
华南金牌X99的PCIe槽位分配要注意:第一条直连CPU的x16给3090Ti,第二条走芯片组的x4给3060就够了。如果插错槽,3060会跑在PCIe 2.0 x1,性能损失巨大。期待你的跑分!双卡3090Ti+3060这套组合性价比确实不错。
-
上周收到华南金牌的板U套装和Z40机箱+长城1250W电源,然后用自己旧电脑上的拆机件开始装机。
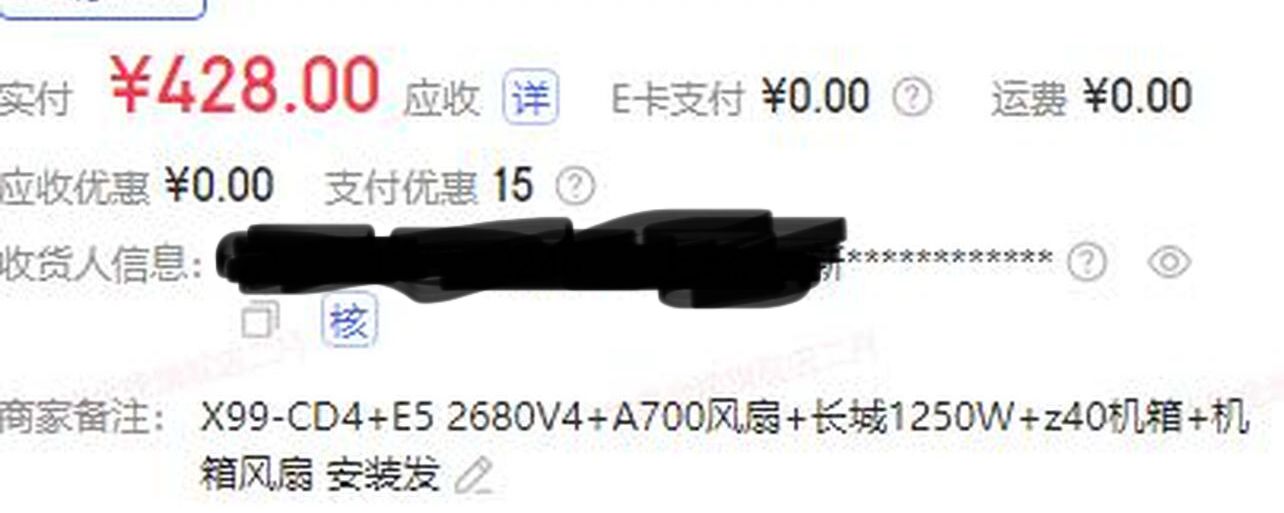
内存条4条插满(32x2+16x2),1T的SSD,3060怼上,重装全新的windows10,结果点不亮。
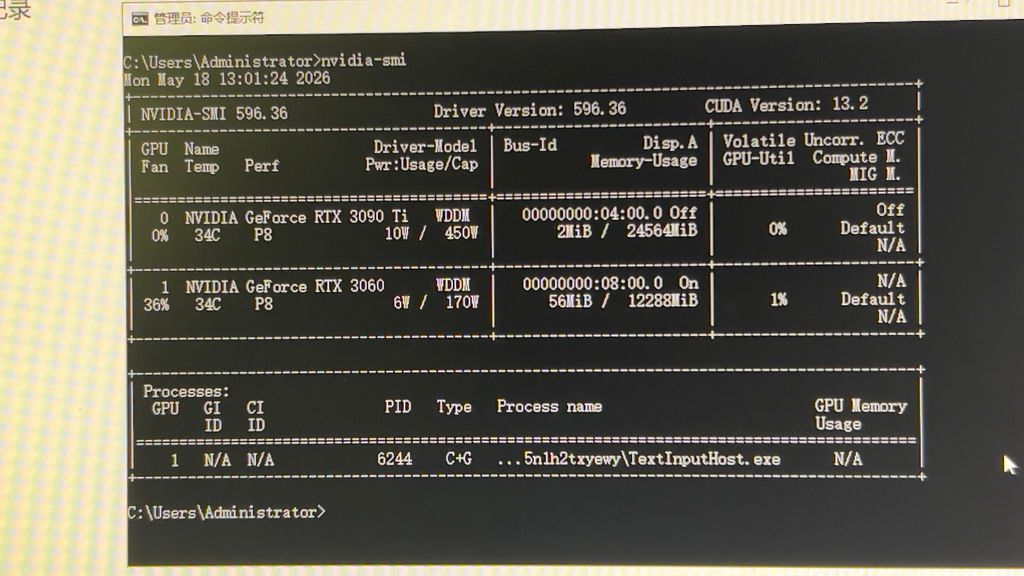
不知道是不是我的3060的问题,HDMI不行,换DP亮了。今天收到RTX3090Ti,双卡怼上,开机


开机正常,但是上周装的nividia显卡驱动丢了。重装驱动,结果发现3090不认。考虑到是不是槽位不对,将上图中两张卡的位置做了对调。重新开机,认到了3090,但是装完驱动后,显示器黑屏。插入3060的DP口,显示器正常显示。但是在任务管理器中看不到3090,只有3060。
以为买的3090Ti翻车了,本着死马当活马医,开始怼DeepSeek......
然后得知,要调整BIOS中的设置:


运气不错,BIOS调整很顺利,并且开机后都没有提示我需要重装显卡驱动,就一切正常。
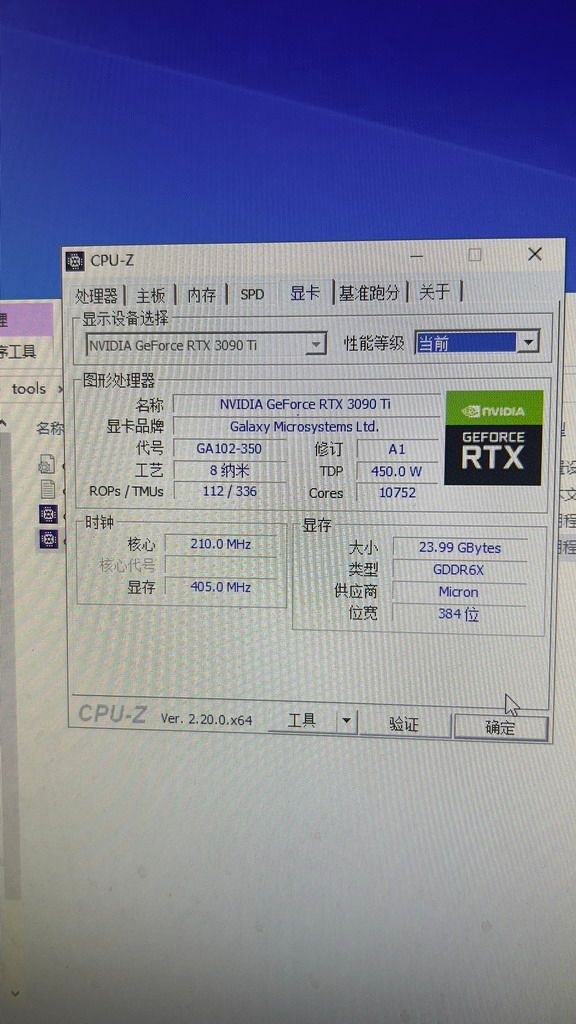
为了尽快验证新买的卡是能用的,下载LM Studio,加载unsloth\Qwen3.6-27B-GGUF(双卡顺序加载)
用一个我常用的测试题进行测试,结果只有不到20tokens/s
在LM Studio中关掉3060,只用3090单卡加载Qwen3.6-27B-GGUF,同样的问题,39tokens/s
====================================================
今天先到这里,明天开始折腾llama.cpp
-
@暧昧光影 windows10下llama.cpp是编译好了,但是今天的结果很不理想。不管是单3090还是3090+3060,都只能跑到个位数tokens/s
效果还不如前几天用LM Studio加载unsloth非MTP的版本
@暧昧光影 windows10下llama.cpp是编译好了,但是今天的结果很不理想。不管是单3090还是3090+3060,都只能跑到个位数tokens/s
效果还不如前几天用LM Studio加载unsloth非MTP的版本
试试vllm
-
@暧昧光影 windows10下llama.cpp是编译好了,但是今天的结果很不理想。不管是单3090还是3090+3060,都只能跑到个位数tokens/s
效果还不如前几天用LM Studio加载unsloth非MTP的版本
@joker_chang https://github.com/noonghunna/club-3090
照这个抄作业,不过前提是装linux,3090用llama.cpp方案,最低也能跑到20 tokens/s。用vllm方案可以跑到50+。
玩大模型还是别用windows了
-
@joker_chang https://github.com/noonghunna/club-3090
照这个抄作业,不过前提是装linux,3090用llama.cpp方案,最低也能跑到20 tokens/s。用vllm方案可以跑到50+。
玩大模型还是别用windows了
-
折腾了几天,踩了无数坑:
1、windows10的电源一定要用卓越性能,不然GPU的频率根本跑不起来,会被限制到180w左右
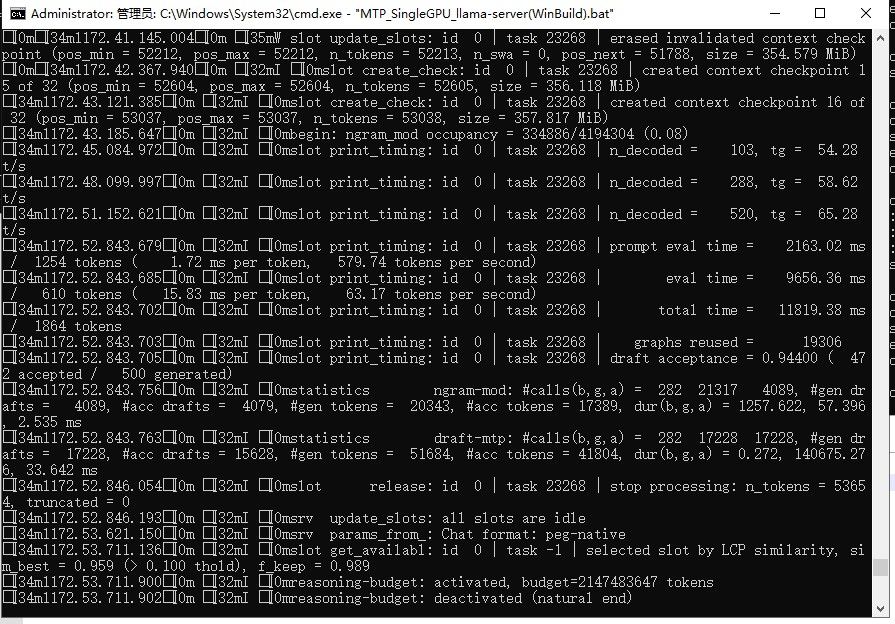
2、cmake编译llama.cpp不要抄作业(反正我本人没搞定,自己编译的能跑但是最多不到10tokens/s),直接用官方https://github.com/ggml-org/llama.cpp/releases的版本,3090下Windows x64 (CUDA 12)
3、官方编译的版本能Qwen3.6 27B跑到35tokens/s,不过MTP没什么效果,我跑unsloth的MTP版本Qwen3.6 27B,也就只能跑到37tokens/s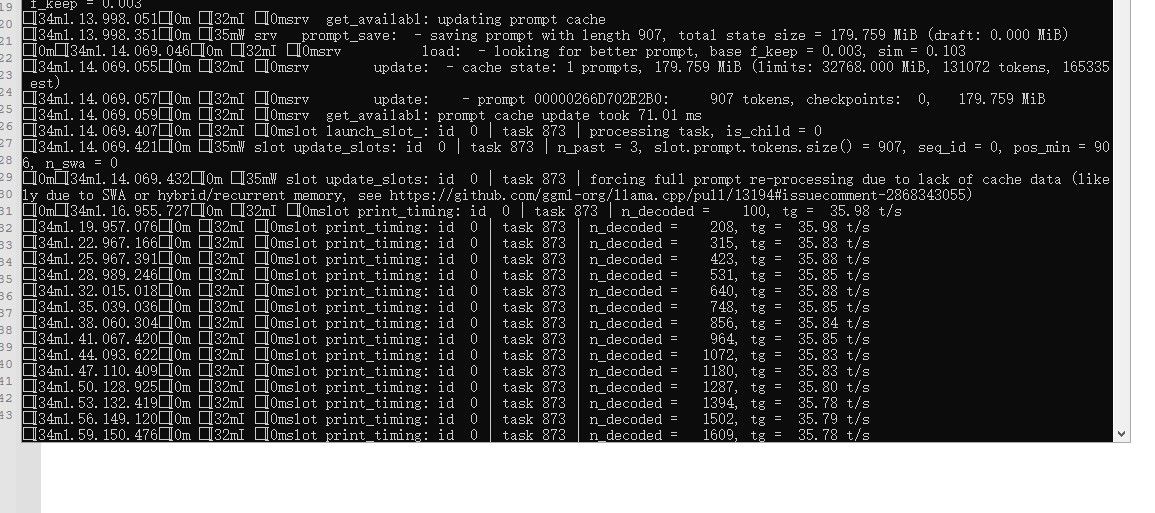
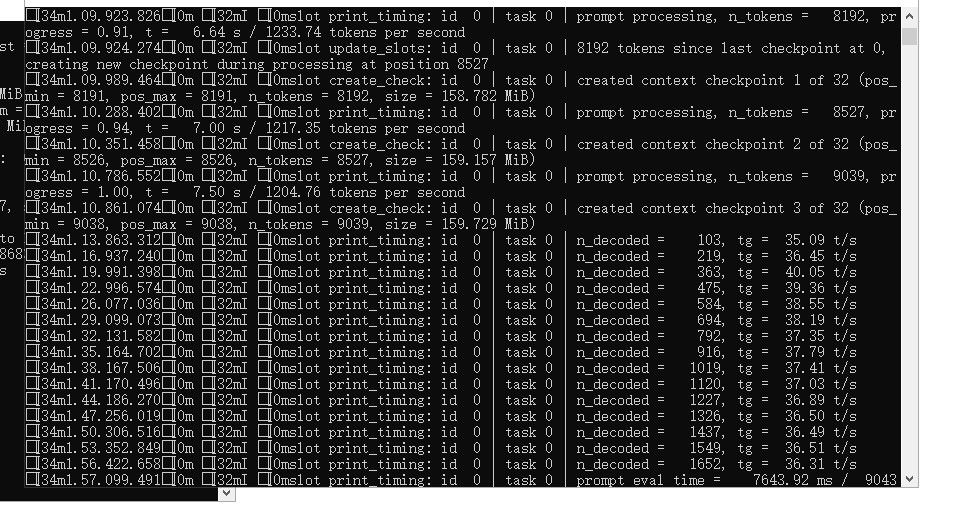
-
折腾了几天,踩了无数坑:
1、windows10的电源一定要用卓越性能,不然GPU的频率根本跑不起来,会被限制到180w左右
2、cmake编译llama.cpp不要抄作业(反正我本人没搞定,自己编译的能跑但是最多不到10tokens/s),直接用官方https://github.com/ggml-org/llama.cpp/releases的版本,3090下Windows x64 (CUDA 12)
3、官方编译的版本能Qwen3.6 27B跑到35tokens/s,不过MTP没什么效果,我跑unsloth的MTP版本Qwen3.6 27B,也就只能跑到37tokens/s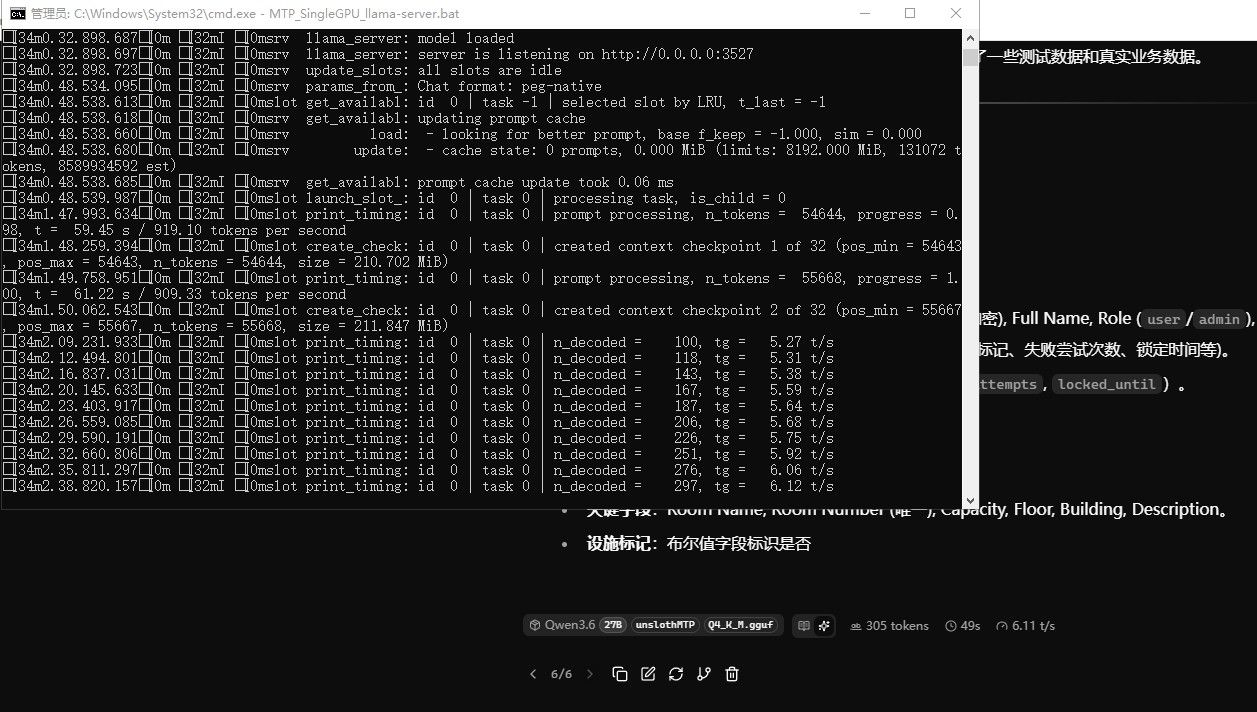
这是我自己编译的llama.cpp
同样的模型,同样的硬件,同样的启动脚本,差别简直了......
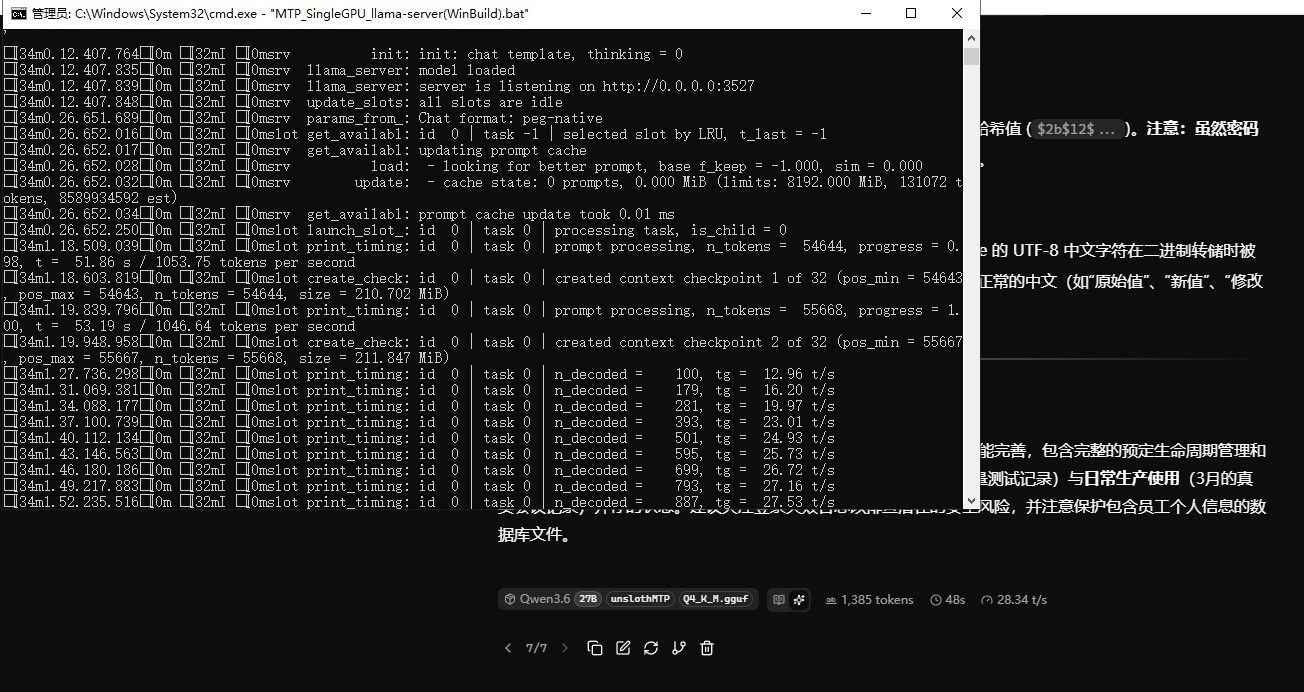
这是https://github.com/ggml-org/llama.cpp/releases/download/b9305/llama-b9305-bin-win-cuda-12.4-x64.zip的
哎~
-
折腾了几天,踩了无数坑:
1、windows10的电源一定要用卓越性能,不然GPU的频率根本跑不起来,会被限制到180w左右
2、cmake编译llama.cpp不要抄作业(反正我本人没搞定,自己编译的能跑但是最多不到10tokens/s),直接用官方https://github.com/ggml-org/llama.cpp/releases的版本,3090下Windows x64 (CUDA 12)
3、官方编译的版本能Qwen3.6 27B跑到35tokens/s,不过MTP没什么效果,我跑unsloth的MTP版本Qwen3.6 27B,也就只能跑到37tokens/s@joker_chang 你MTP没设置好, 你看看我的帖子
-
折腾了几天,踩了无数坑:
1、windows10的电源一定要用卓越性能,不然GPU的频率根本跑不起来,会被限制到180w左右
2、cmake编译llama.cpp不要抄作业(反正我本人没搞定,自己编译的能跑但是最多不到10tokens/s),直接用官方https://github.com/ggml-org/llama.cpp/releases的版本,3090下Windows x64 (CUDA 12)
3、官方编译的版本能Qwen3.6 27B跑到35tokens/s,不过MTP没什么效果,我跑unsloth的MTP版本Qwen3.6 27B,也就只能跑到37tokens/s