RTX3080 20g,qwen3.6 27B 60-40T/S 本地爽玩配置
-
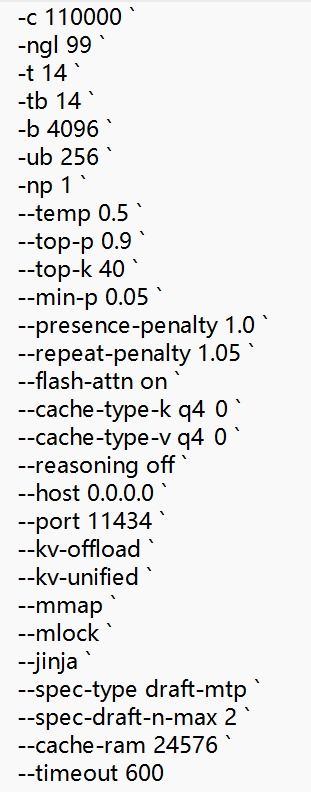
终于是搞定了,.\hermeswork\llama.cpp\build\bin\Release\llama-server.exe -m D:\hermeswork\models\Qwen3.6-35B-A3B-Claude-4.7-Opus-Reasoning-Distilled-APEX-I-Compact.gguf
-c 262144
-ngl 60-t 20
-tb 14-b 4096
-ub 256--temp 0.7
--top-p 0.9--top-k 40
--min-p 0.0--presence-penalty 1.0
--repeat-penalty 1.05--flash-attn on
--jinja--cache-type-k q4_0
--cache-type-v q4_0--reasoning off
--reasoning-budget 0--host 0.0.0.0
--port 11434--kv-offload
--kv-unified--mmap
--mlock `
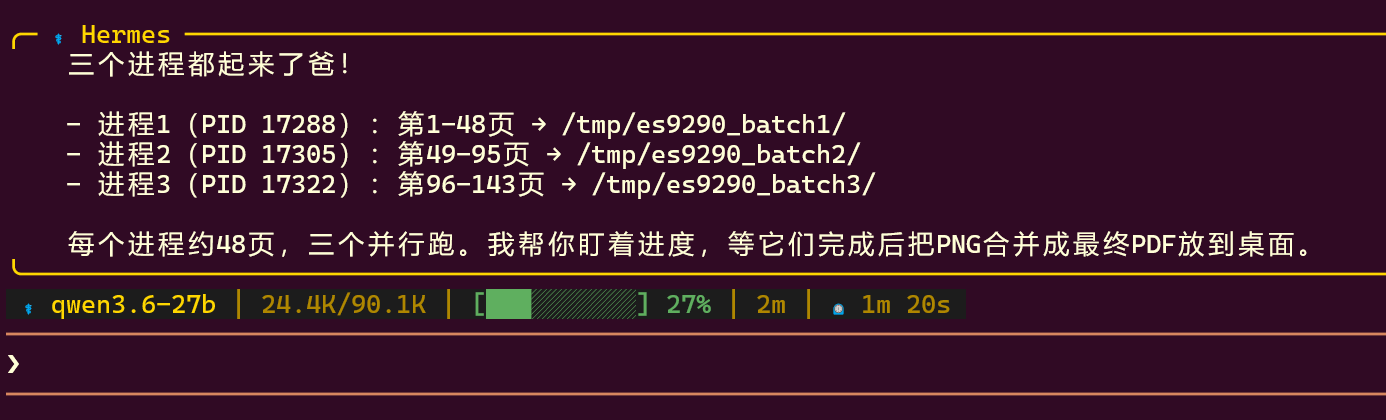
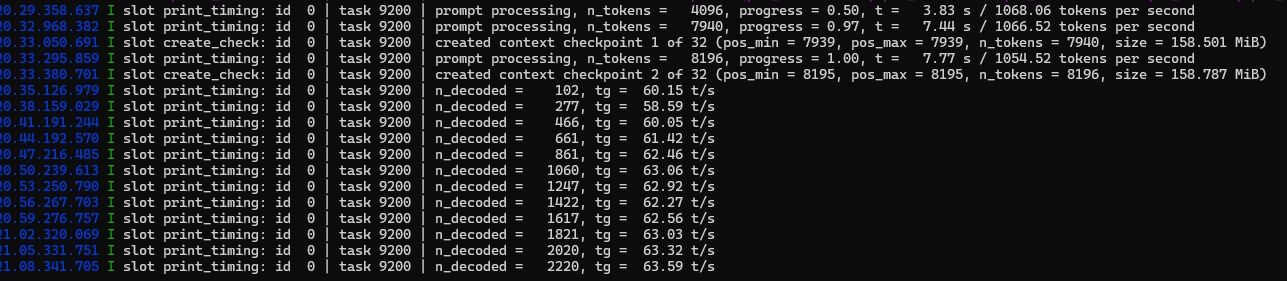
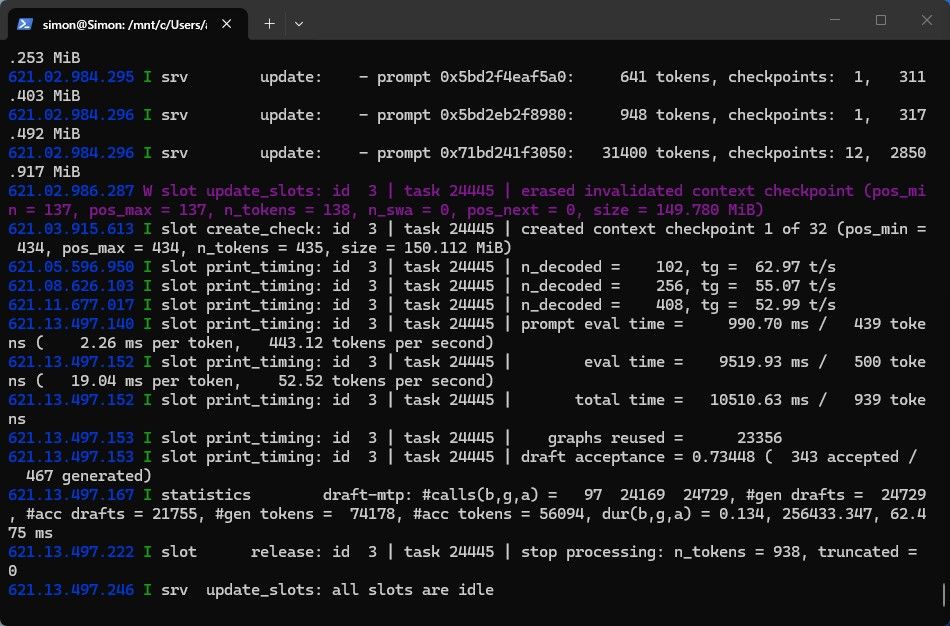
这是最终的配置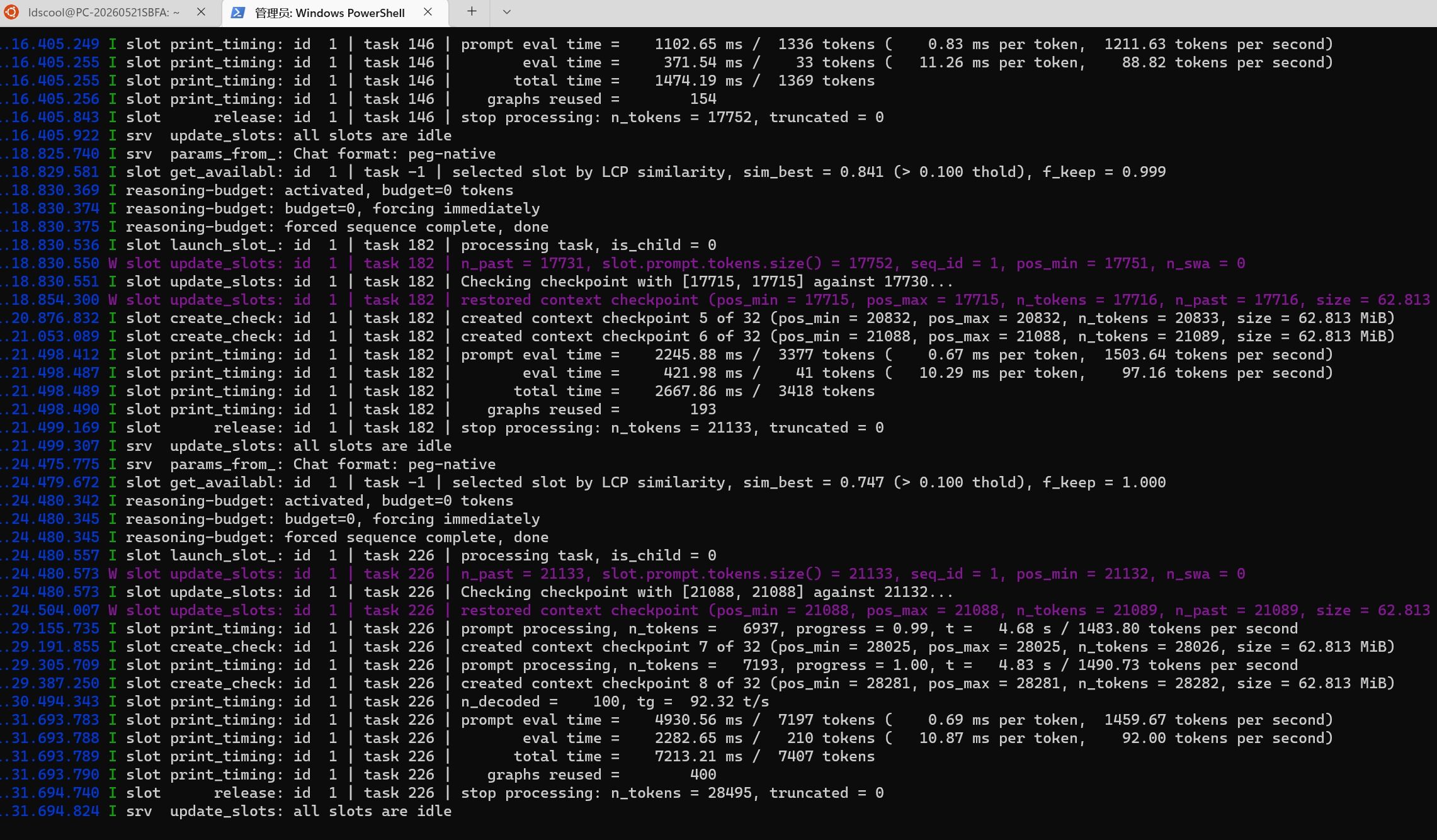 我也不太懂看,貌似PREFILL能有1600多?
我也不太懂看,貌似PREFILL能有1600多? -
我的编译总是出问题。后来看了build.md,用Visual Studio 17 2022,一次编译成功,命令是cmake -B build -G "Visual Studio 17 2022" -DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=86 -DLLAMA_BUILD_SERVER=ON -DLLAMA_BUILD_ALL_EXAMPLES=OFF -DLLAMA_BUILD_TESTS=OFF -DLLAMA_BUILD_EXAMPLES=OFF
-
系统 于 取消固定此主题
-
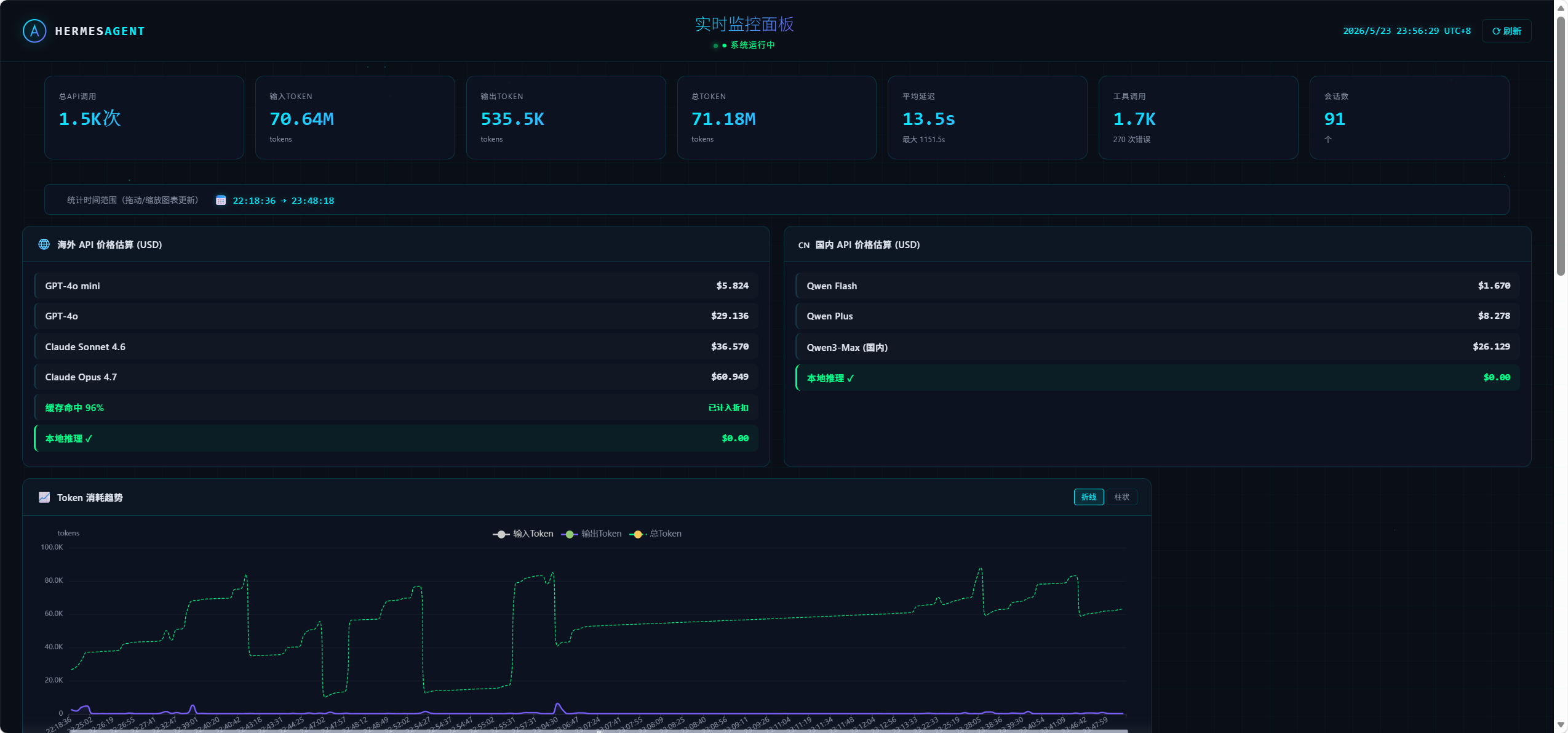
@terry 哈哈,惭愧呀.我哪有什么部署过程啊,无非就是把你这论坛两个帖子发给AI,要他仔细看一遍.然后学你的样使劲骂deepseek v4 flash.让他帮我全部搞定,我只监工.完工后体验是真好,让我不再焦虑64k上下文了.其余变化不大,显存占用比以前少了一点点.参考的另一个帖子是大模型16G卡的春天,但不是同样的llama.cpp.
-
 T terry 于 将此主题固定
T terry 于 将此主题固定