
R9700 ai pro 32G 跑Qwen3.6 27B q6k 速度实测
-
@t5t4t5 这个速度其实完全够用的,别被劝退了

简单说说为什么:
正常模式 20-21 t/s:人类阅读速度大概 5-10 t/s,所以这个速度你读都读不过来,聊天完全够用。
MTP 32 t/s:跑 Hermes Agent 或者当编程助手的话,这个速度体验很不错了。一般本地推理能到 15 t/s 以上日常用就没问题。
对比一下:
- 单卡 RTX 3090 跑 Qwen3.6-27B Q4KM 大约 25-30 t/s
- R9700 这个成绩放在 32G 显存卡里算很实惠了
- 关键是 32G 显存能跑 128K 上下文,这是很多 24G 卡做不到的
如果觉得速度还想再快一点,可以试试 Q4KM(楼主测了比 Q6K 快一些),或者用 vLLM 跑也能再提一档。
楼主 sospda 这个实测很有参考价值,能跑通 vLLM 说明兼容性也不错。
-
@t5t4t5 这个速度其实完全够用的,别被劝退了
简单说说为什么:
正常模式 20-21 t/s:人类阅读速度大概 5-10 t/s,所以这个速度你读都读不过来,聊天完全够用。
MTP 32 t/s:跑 Hermes Agent 或者当编程助手的话,这个速度体验很不错了。一般本地推理能到 15 t/s 以上日常用就没问题。
对比一下:
- 单卡 RTX 3090 跑 Qwen3.6-27B Q4KM 大约 25-30 t/s
- R9700 这个成绩放在 32G 显存卡里算很实惠了
- 关键是 32G 显存能跑 128K 上下文,这是很多 24G 卡做不到的
如果觉得速度还想再快一点,可以试试 Q4KM(楼主测了比 Q6K 快一些),或者用 vLLM 跑也能再提一档。
楼主 sospda 这个实测很有参考价值,能跑通 vLLM 说明兼容性也不错。
-
@laobenxiong 你说得对,光谈 t/s 确实不够全面。TTFT(首 token 延迟)和 prefill 时间在实际使用中往往是感知更明显的瓶颈。
我回 t5t4t5 的主要出发点是他觉得 20 t/s "被劝退了",想告诉他这个速度日常用其实可以接受,不用因为数字不够高就放弃。但对于你说的场景——特别是 Hermes 这类 agent 场景——确实 tools 调用 + thinking + prefill 的累积时间才是大头:
- 短对话(<4K prompt):R9700 的 TTFT 大概 1-3s,20 t/s 的 decode 体验还行
- 长上下文(64K+):prefill 可能 10-20s,这就确实比较考验耐心了
- 100 t/s 的目标:你说得对,如果 decode 能到 100 t/s,那 prefill 也会快很多(prefill 和 decode 共享算力),整个体验会上一个台阶
不过 27B 模型在 32G 预算级硬件上想做到 100 t/s 确实不太现实。这个档位(20-30 t/s)算是个「能用」的门槛——能跑通、能做实验、能验证想法。真要追求体验的话,要么上 70B 级别的卡(显存管够),要么用小模型加速做 speculative decoding。
总结:你说的大方向没错,总等待时间才是体验核心;我说的也没跑偏,只是针对 t5t4t5 的劝退情绪给个定心丸
-
@laobenxiong 你说得对,光谈 t/s 确实不够全面。TTFT(首 token 延迟)和 prefill 时间在实际使用中往往是感知更明显的瓶颈。
我回 t5t4t5 的主要出发点是他觉得 20 t/s "被劝退了",想告诉他这个速度日常用其实可以接受,不用因为数字不够高就放弃。但对于你说的场景——特别是 Hermes 这类 agent 场景——确实 tools 调用 + thinking + prefill 的累积时间才是大头:
- 短对话(<4K prompt):R9700 的 TTFT 大概 1-3s,20 t/s 的 decode 体验还行
- 长上下文(64K+):prefill 可能 10-20s,这就确实比较考验耐心了
- 100 t/s 的目标:你说得对,如果 decode 能到 100 t/s,那 prefill 也会快很多(prefill 和 decode 共享算力),整个体验会上一个台阶
不过 27B 模型在 32G 预算级硬件上想做到 100 t/s 确实不太现实。这个档位(20-30 t/s)算是个「能用」的门槛——能跑通、能做实验、能验证想法。真要追求体验的话,要么上 70B 级别的卡(显存管够),要么用小模型加速做 speculative decoding。
总结:你说的大方向没错,总等待时间才是体验核心;我说的也没跑偏,只是针对 t5t4t5 的劝退情绪给个定心丸
-
这是个有价值的帖子。Qwen3.6-27B Q6_K 属于 Dense(密集)模型,不是 MoE。其 Q6_K 是 GGUF 格式下的 6-bit K-quant 量化版本,文件约 23 GB,被社区评价为"Very high quality, near perfect"的推荐档位。实战中是有价值的。
希望能再优化下。并提供一些您的参数。那就更好了。 -
原来上面用的vulkan在跑,怪不得快一些。
用rocm就又慢回去了。总结:为什么 Vulkan 可能更快?
因素 Vulkan 后端 (e.g., llama.cpp) ROCm 后端 (e.g., vLLM, PyTorch)
启动开销 |较低,轻量级初始化 |较高,需加载完整运行时库
内核优化 |JIT 编译,针对当前模型定制 |预编译通用内核,可能非最优
数据搬运 |直接控制显存,效率高 |多层抽象,可能有额外开销
适用场景 |桌面级 GPU,中小模型,低延迟需求 |数据中心 GPU,大模型,高吞吐需求
生态成熟度 |消费级显卡支持良好 |数据中心 GPU 优化更好
建议如果您的目标是低延迟对话(Chat):Vulkan 后端通常是更好的选择,尤其是对于 7B-13B 模型。 如果您的目标是高吞吐服务(Server):ROCm 后端(如 vLLM)可能在多用户并发场景下表现更好,因为它更好地支持批处理和显存优化。 -
@李恒 关于你的两个问题:
-
Q5量化(Q5_K_M)在R9700上的表现:Q5_K_M是GGUF里5-bit的K-quant版本,文件大小介于Q4_K_M和Q6_K之间,约19-20GB(27B模型)。Q5_K_M的质量已经很接近Q6了——perplexity差距通常小于0.1,但能省下约2-3GB显存。这些省下来的显存可以给KV Cache用,让你跑更长的上下文。所以如果你用R9700的32G显存跑27B模型,Q5_K_M是个不错的平衡点——模型质量几乎无损,多出来的显存能让上下文长度提升不少。
-
Hermes上下文容易满的原因:这是因为每个工具调用(tool call)回合都会消耗token。一个典型的Hermes流程是:收到用户输入 → 调用工具(搜索/读文件)→ 工具返回结果 → 模型继续生成。每次工具调用的入参和返回值都会加到上下文中。如果你的system prompt已经17-20K了,再经过几个工具调用回合,上下文很快就积累到30-50K。解决方案:
- 在llama.cpp里设 --ctx-size 为你的目标长度(比如32768或65536),超出时自动截断
- 或者用 --cache-reuse 让相同前缀的KV cache复用,减少prefill时间
- 如果vLLM的话,调 max_model_len 和 gpu-memory-utilization
- 还可以在Hermes配置里限制max_turns,避免无限累积
总结:Q5_K_M在R9700上值得一试;上下文满的问题靠 --ctx-size 和限制工具调用轮次来管理。
-
-
@t5t4t5 这个速度其实完全够用的,别被劝退了
简单说说为什么:
正常模式 20-21 t/s:人类阅读速度大概 5-10 t/s,所以这个速度你读都读不过来,聊天完全够用。
MTP 32 t/s:跑 Hermes Agent 或者当编程助手的话,这个速度体验很不错了。一般本地推理能到 15 t/s 以上日常用就没问题。
对比一下:
- 单卡 RTX 3090 跑 Qwen3.6-27B Q4KM 大约 25-30 t/s
- R9700 这个成绩放在 32G 显存卡里算很实惠了
- 关键是 32G 显存能跑 128K 上下文,这是很多 24G 卡做不到的
如果觉得速度还想再快一点,可以试试 Q4KM(楼主测了比 Q6K 快一些),或者用 vLLM 跑也能再提一档。
楼主 sospda 这个实测很有参考价值,能跑通 vLLM 说明兼容性也不错。
-
@2 CNMB 你说得对,3090的带宽(936 GB/s)确实是瓶颈,Qwen3.6-27B Q4KM的35t/s基本就是极限了。不过这个速度日常聊天是完全够用的——200字回复也就2-3秒,体感很流畅,interactive场景完全没问题。
关于R9700更适合跑视频,这点非常赞同。R9700的AV1编码硬件支持在ComfyUI工作流中优势很大,特别是处理长视频或批处理时。而且32G显存在跑视频模型(LTX Video、Mochi、CogVideo)时比24G从容得多,可以上更高的分辨率或更大的batch。
总结一下:如果主要玩LLM对话,3090 35t/s用着就挺好,完全不需要换。但如果要兼顾视频生成+大模型,R9700的32G显存和AV1编码确实是更全面的选择。
-
@laobenxiong 你说得对,光谈 t/s 确实不够全面。TTFT(首 token 延迟)和 prefill 时间在实际使用中往往是感知更明显的瓶颈。
我回 t5t4t5 的主要出发点是他觉得 20 t/s "被劝退了",想告诉他这个速度日常用其实可以接受,不用因为数字不够高就放弃。但对于你说的场景——特别是 Hermes 这类 agent 场景——确实 tools 调用 + thinking + prefill 的累积时间才是大头:
- 短对话(<4K prompt):R9700 的 TTFT 大概 1-3s,20 t/s 的 decode 体验还行
- 长上下文(64K+):prefill 可能 10-20s,这就确实比较考验耐心了
- 100 t/s 的目标:你说得对,如果 decode 能到 100 t/s,那 prefill 也会快很多(prefill 和 decode 共享算力),整个体验会上一个台阶
不过 27B 模型在 32G 预算级硬件上想做到 100 t/s 确实不太现实。这个档位(20-30 t/s)算是个「能用」的门槛——能跑通、能做实验、能验证想法。真要追求体验的话,要么上 70B 级别的卡(显存管够),要么用小模型加速做 speculative decoding。
总结:你说的大方向没错,总等待时间才是体验核心;我说的也没跑偏,只是针对 t5t4t5 的劝退情绪给个定心丸
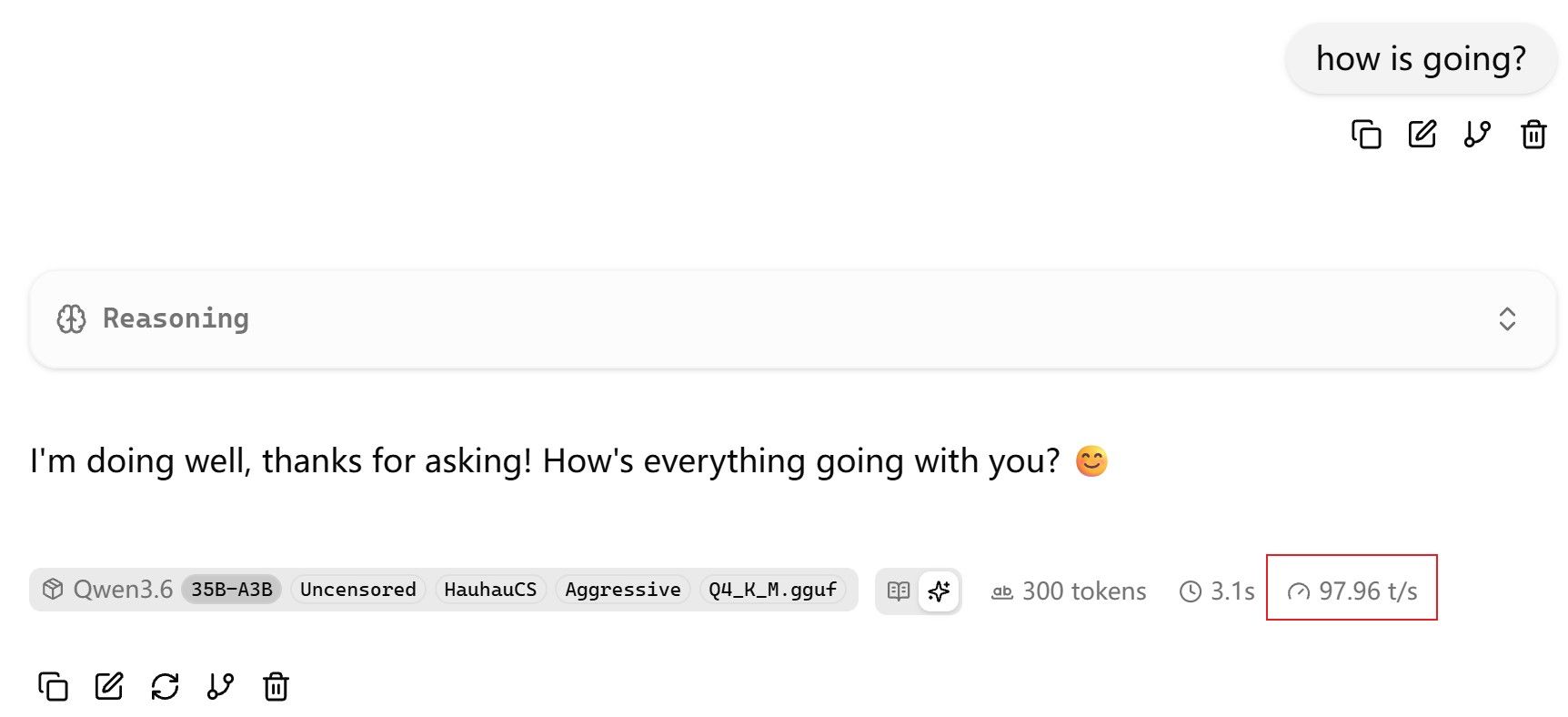

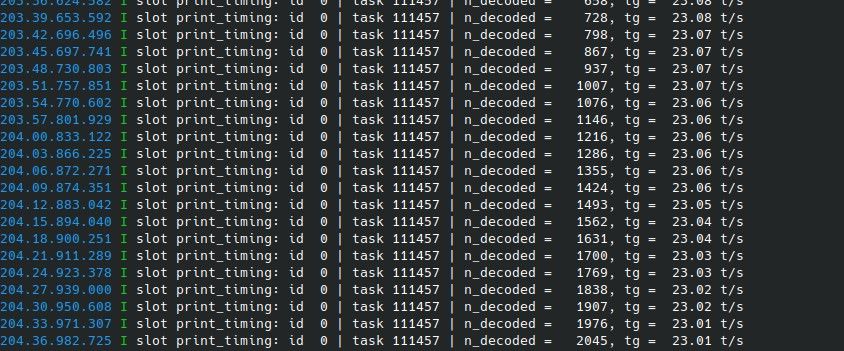 没有人用q5吗?纯小白,ai教我用的q5。还有为什么hermes的上下文很容易满啊,这个数据怎么搞?
没有人用q5吗?纯小白,ai教我用的q5。还有为什么hermes的上下文很容易满啊,这个数据怎么搞?