R9700到货,AI+Hermes部署llama.cpp+Qwen3.6-27B-Q4_K_M一次成功!
-
周六下午R9700到货,开始组装机器,快10年没装机了,偏这次又买了小机箱(有点后悔),结果弄到夜里快12点才装好,腰酸背痛,装完点亮了,就睡了。转天起来开始装Ubuntu 24.04.4,系统竟然也装了一上午,开始时安装程序反复退出,后来刷了最新的BIOS,没想到重启之后竟然直接进系统了。然后就是更新系统,安装ROCM等等一系列。然后安装Hermes,使用deepseek-v4-flash,在Hermes辅助下安装llama.cpp。特意告诉Hermes要浏览抡锤者论坛中关于AMD显卡的帖子,特别要参考
https://lcz.me/topic/353/7900-xtx-qwen3.6-27b-ubuntu-rocm-vulkan-mtp-64-128-256k-全部實測整理
和
https://lcz.me/topic/100/7900xtx-llama.cpp-qwen3.6-27b-turboquant-mtp-测试结果分享/56
这两个帖子的内容。在此感谢 CHIA AN YANG 和 David Zhang 两位大神,也特别感谢斑竹建立了这个论坛让我学到了很多知识。

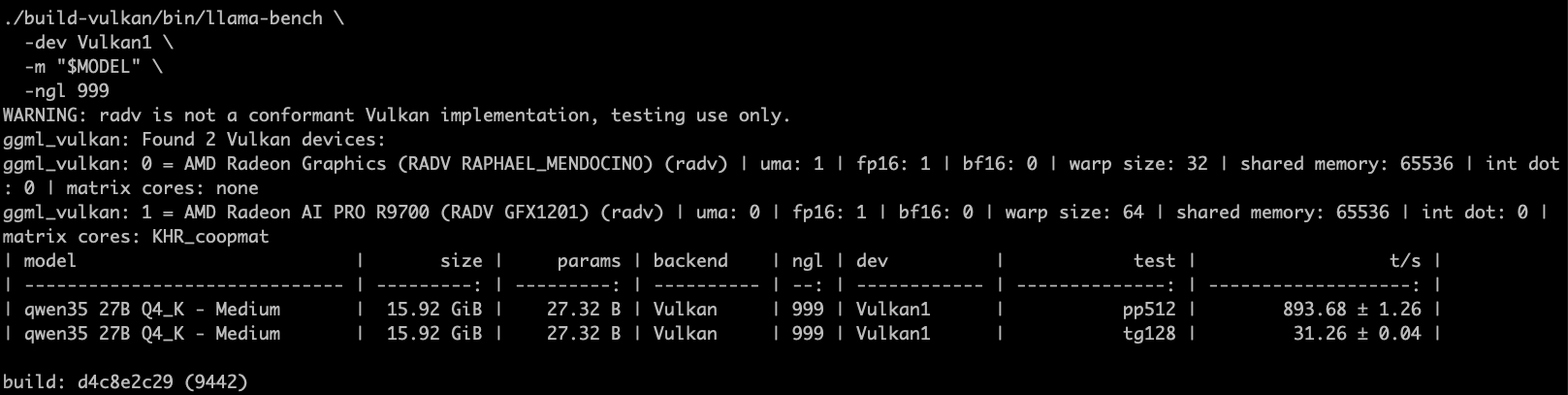
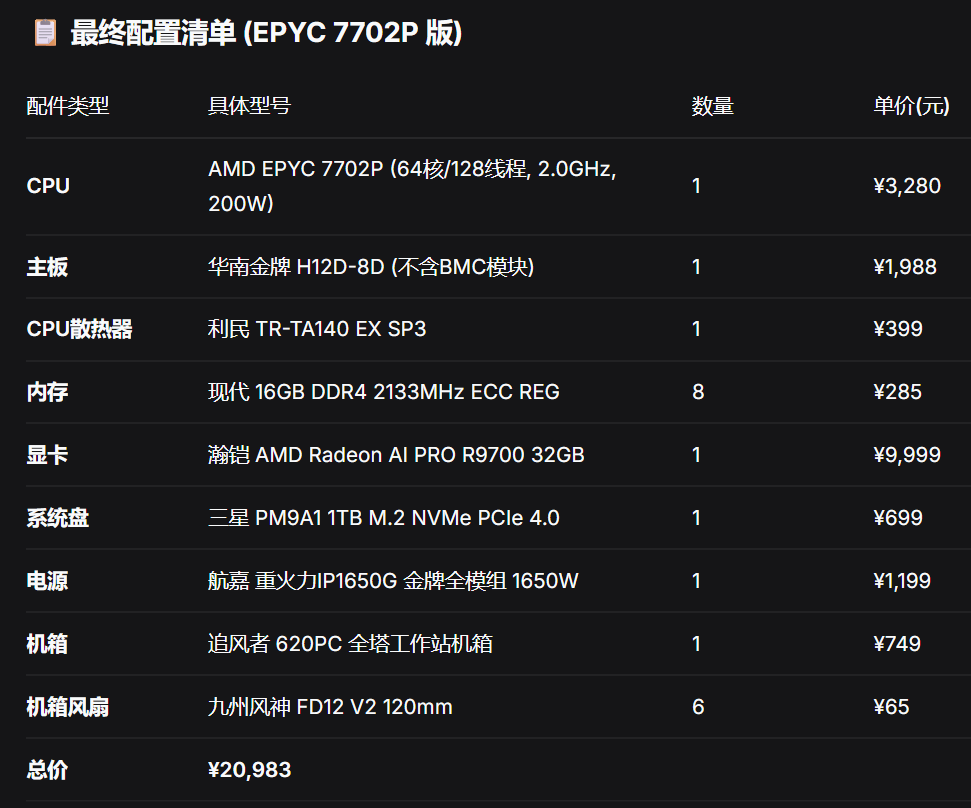
最后选定Qwen3.6-27B-Q4_K_M.gguf,使用Hermes自动配置,一次成功!硬件配置: 主板:MaxSun-Terminator-B850M-PRO CPU:AMD Ryzen 7 9700X 内存:金邦DDR5 5600 64GB SSD: 宏基GM7000 1TB+金邦 2TB 显卡:AMD Radeon AI PRO R9700 电源:Thermaltake SFX-850 机箱:机械大师C26 运行参数:/data/ai/apps/llama.cpp/build/bin/llama-server \ -m /data/ai/models/llm/Qwen3.6-27B-Q4_K_M.gguf \ -ngl 99 \ -fa 1 \ -c 131072 \ --cache-type-k q4_0 \ --cache-type-v q4_0 \ --spec-type draft-mtp \ --spec-draft-n-max 3 \ -ub 256 \ -np 1 \ --temp 0.7 \ --top-k 20 \
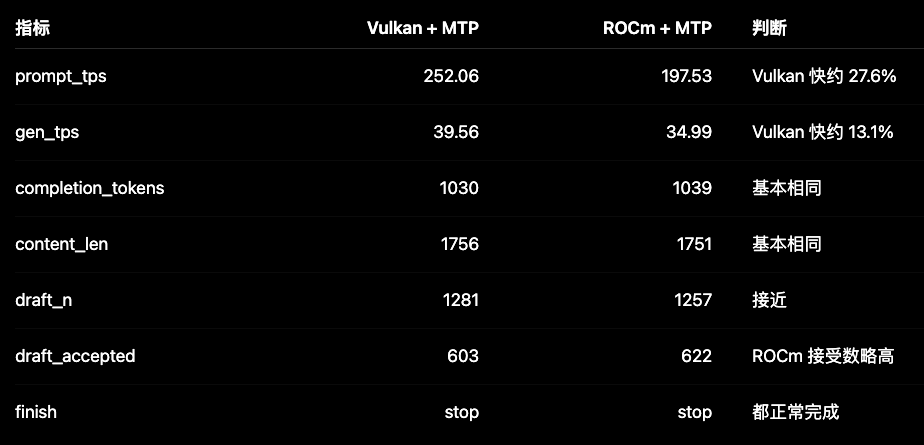
使用起来感觉和线上的deepseek-v4-flash没有太大区别,速度差不多。但是运行起来的风扇噪音真是太大了!但是比起电水壶烧开水还是差远了。我把电脑放脚下,身后就是电水壶,水烧起来的声音完全能盖住显卡风扇的声音,满载时也能。但是机箱散热不好,测试时显卡温度偏高。
调整了一下机箱风扇的位置,效果并不明显。小机箱空间太受限了!装机时就很费劲!
为了安全,把功耗限制到280W。
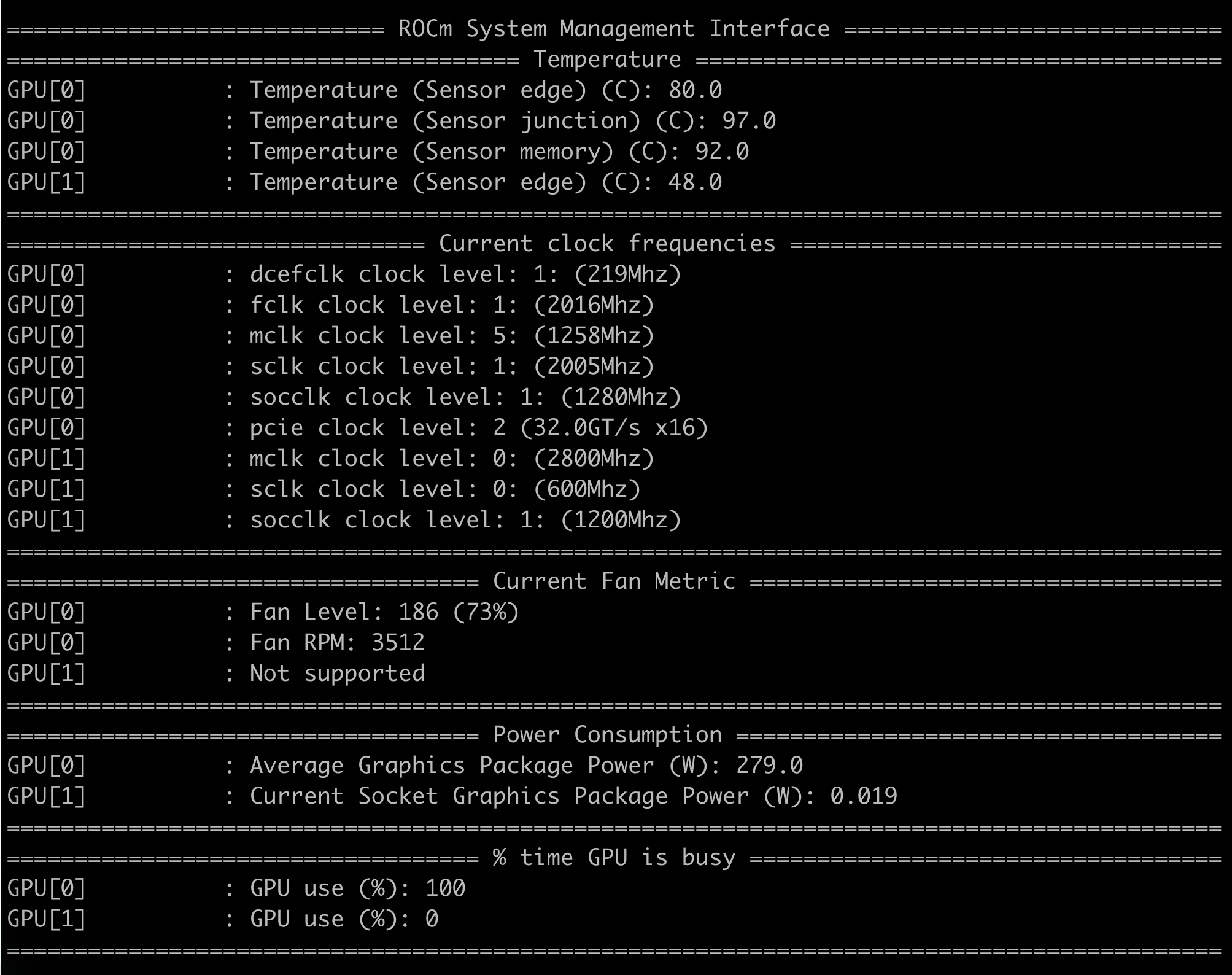
性能损耗约4%。

后来感觉温度还是偏高,风扇太吵,又限制到270W。

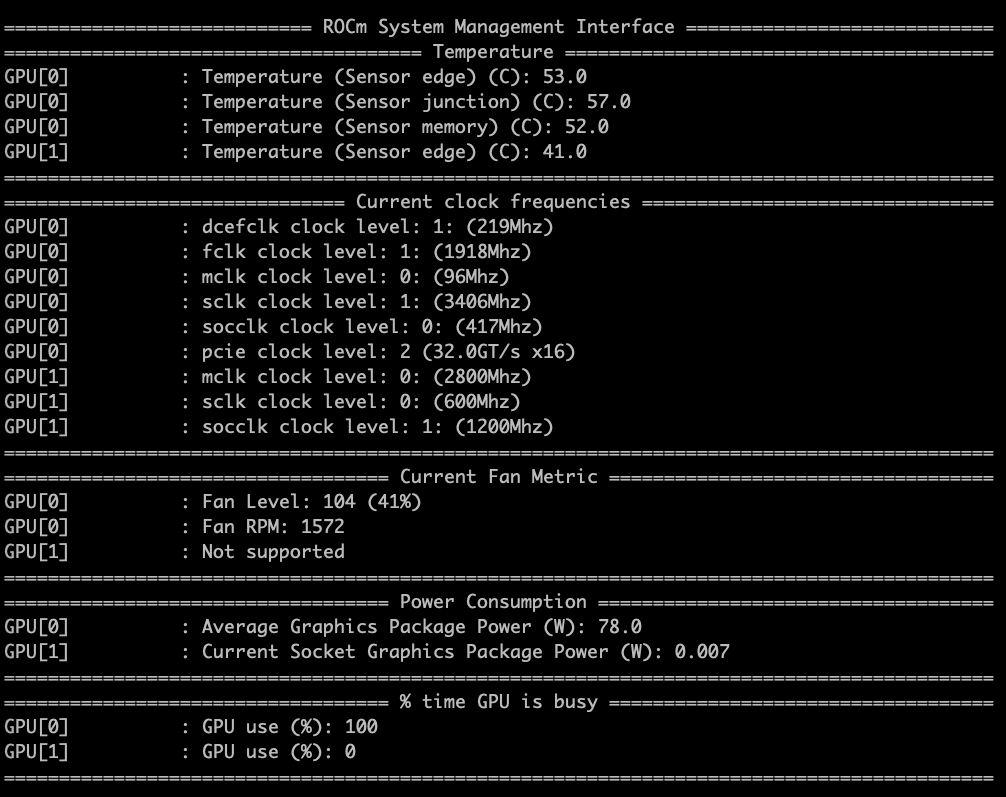
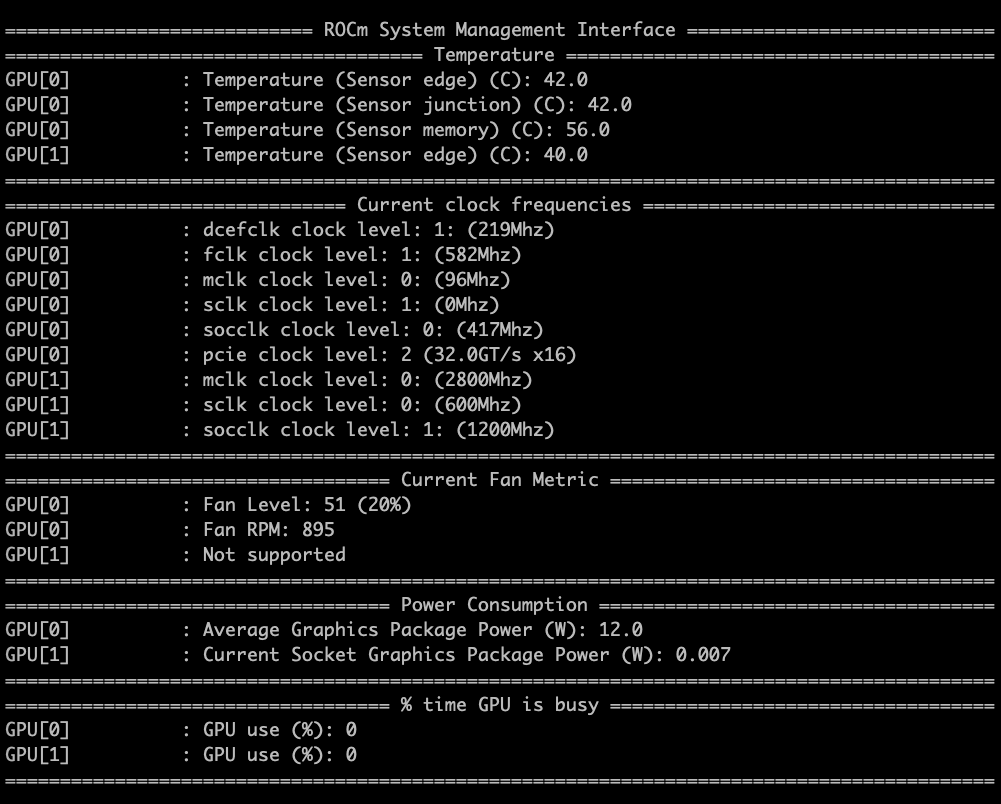
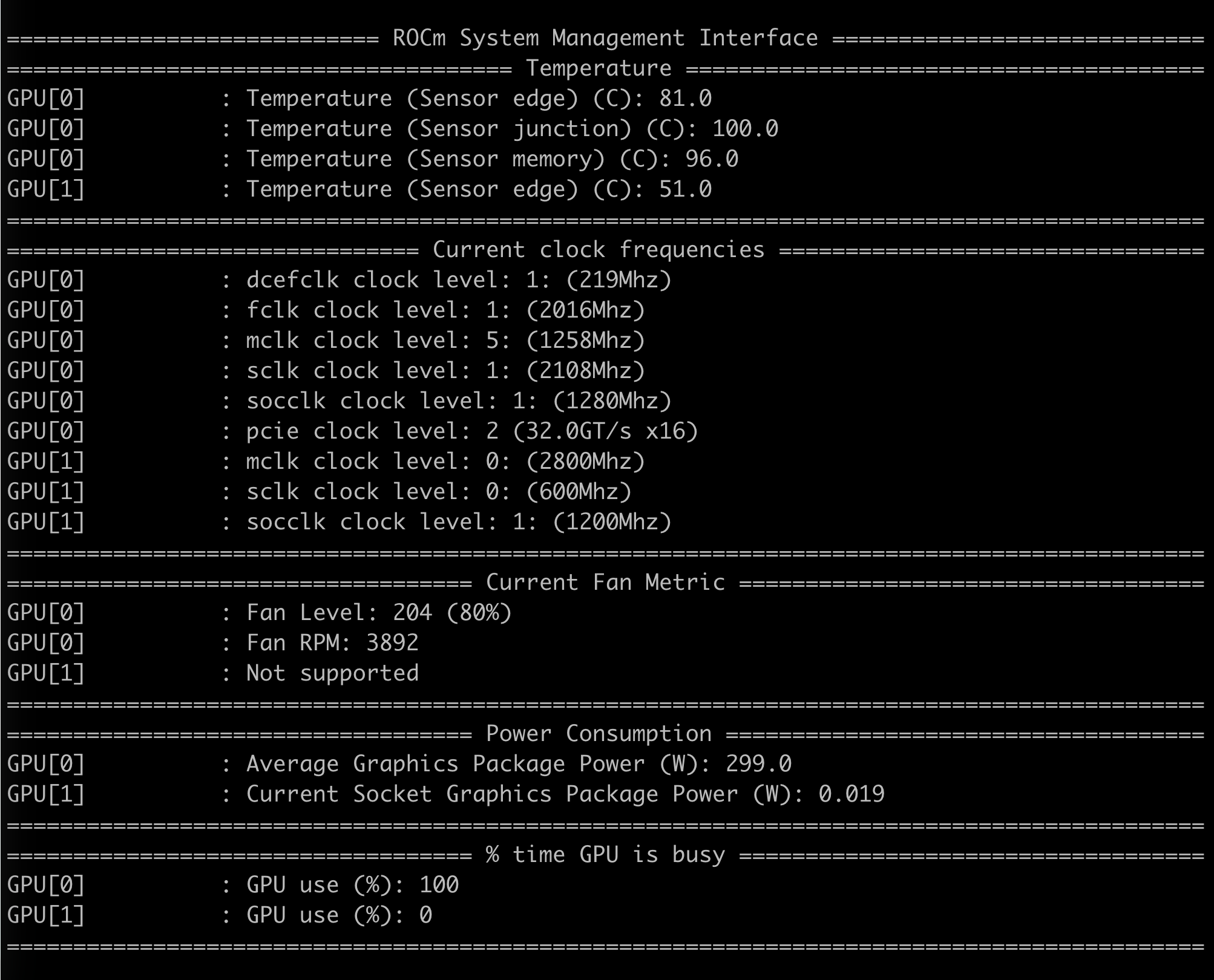
这是现在模型刚加载时的温度:
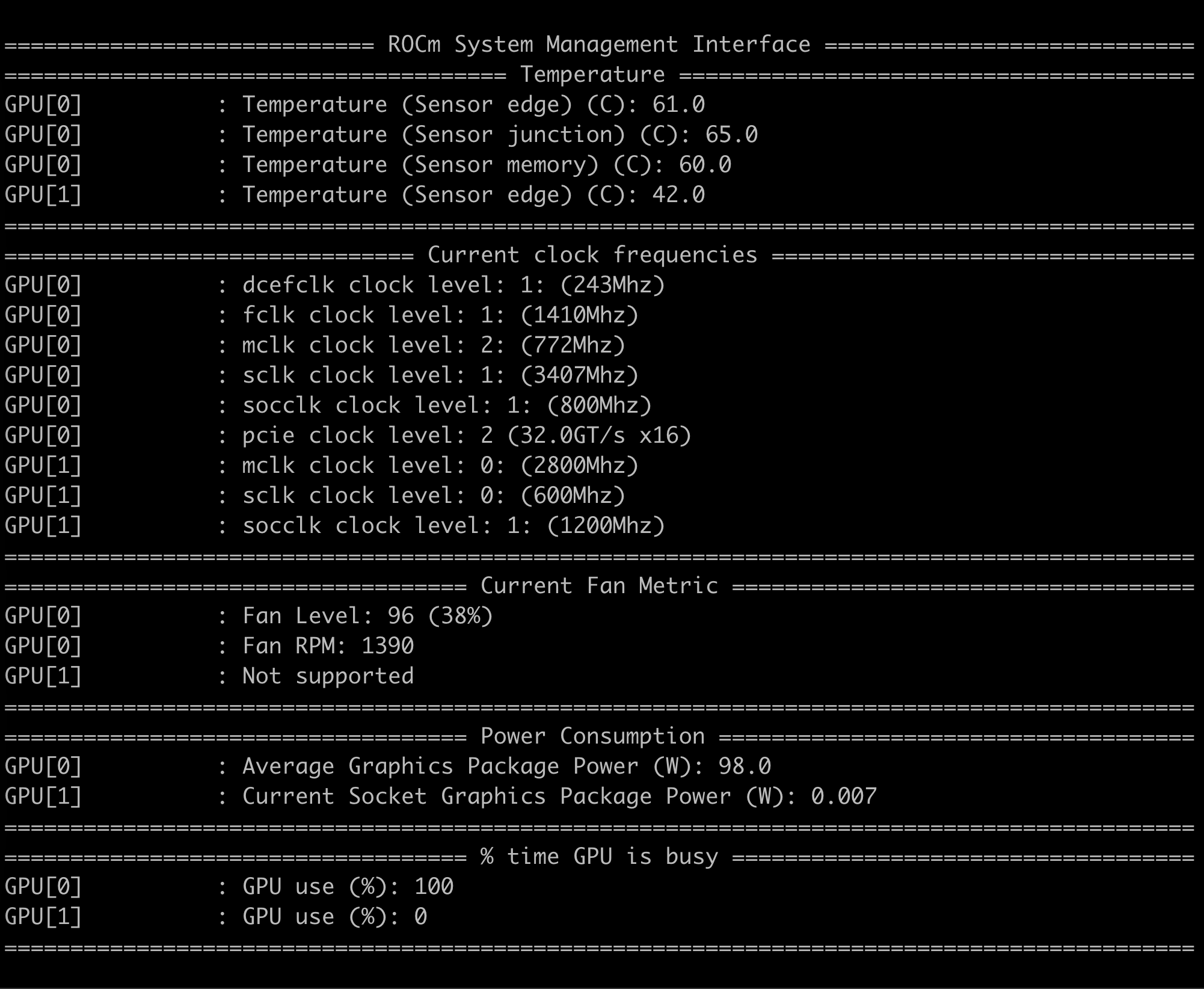
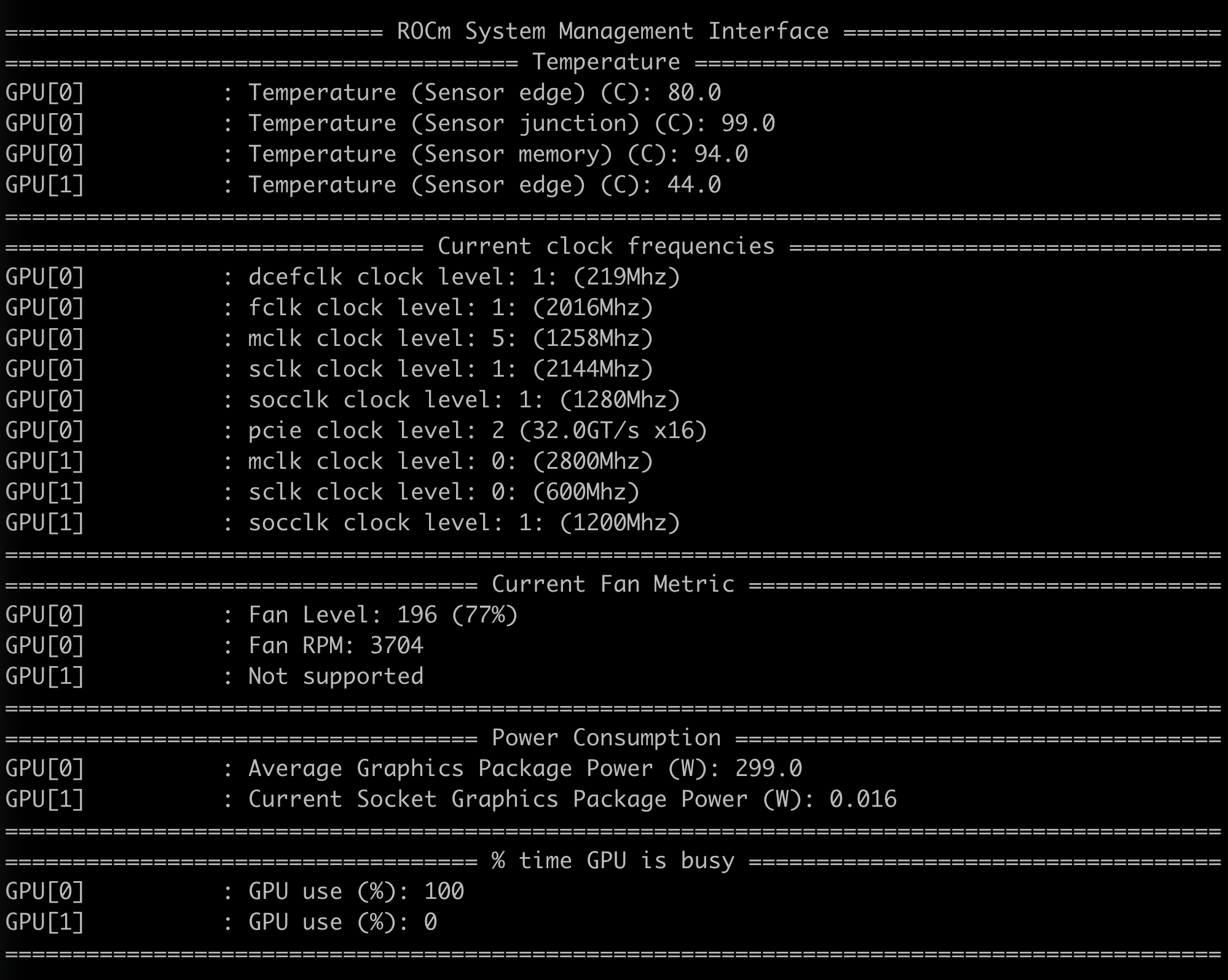
这是模型运行时的温度:
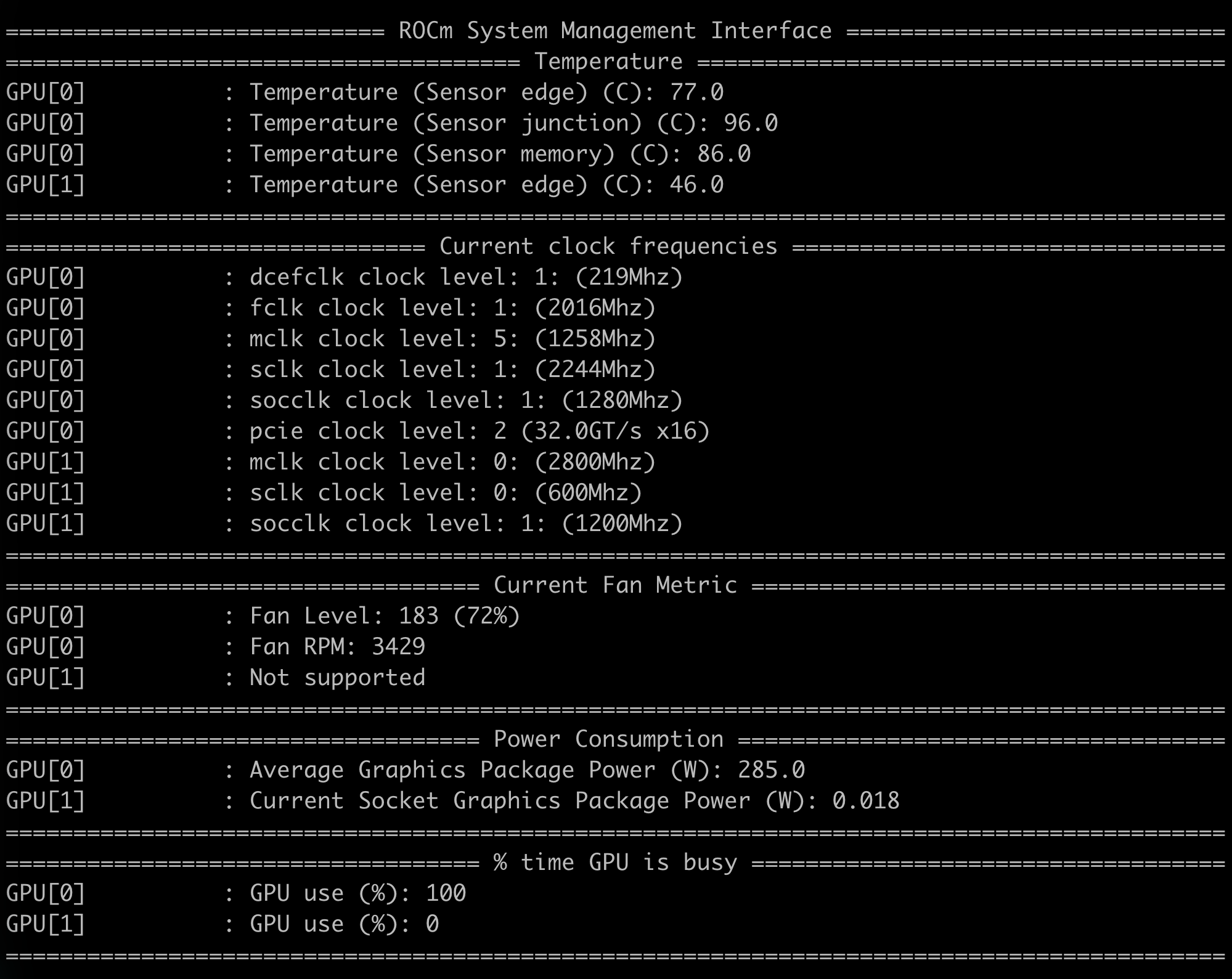
心得:
1、AMD显卡在Linux下的生态还是可以的,至少我这个没有什么Linux使用经验的人,在AI和Hermes的帮助下,也就是花了1天时间就把大模型跑起来了,所以对AMD显卡有顾虑的人我觉得可以放心一些了。
2、涡轮卡的噪音确实是很大,但是比电水壶的声音还是差一些,隔一堵墙,关上门,满载时的噪音也是听不见的。算是给对噪音敏感的人一些真实感受吧。
3、算是个经验教训——机箱尽量选大一些,利于散热通风,长期运行也更有安全保障,装机时也能顺利一些。这些是我的一些体会,没有什么经验贡献,再次感谢斑竹和论坛里的各位大神的无私分享。
-
@densha 24小时跑agent是可行的,R9700功耗控制比N卡好不少,几点参考:
-
功耗方面:R9700满载大概200-250W(跑推理时),待机很低(<30W),长期跑比3090/4090省电得多。电费方面一天大概2-3度电。
-
散热建议:建议调一下风扇曲线,让温度控制在70°C以下。R9700的VRAM温度比核心高10-15°C正常。如果不放心,可以把功耗限制在80%(
amdgpu.pp_power_profile或者用 corectrl),性能损失不到5%但温度能降10°C+。 -
稳定性:Linux下R9700跑 llama.cpp/Vulkan 后端很稳,连续跑几天没问题的。建议加个cron脚本每天凌晨重启一次Hermes进程清理context,避免长期运行的内存泄漏。
-
如果确实是做agent用的,推荐用screen/tmux托管,加个watchdog脚本:每30分钟检查一次Hermes进程是否还活着,挂了自动重启。这样万一崩了也能自我恢复。
-
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
周六下午R9700到货,开始组装机器,快10年没装机了,偏这次又买了小机箱(有点后悔),结果弄到夜里快12点才装好,腰酸背痛,装完点亮了,就睡了。转天起来开始装Ubuntu 24.04.4,系统竟然也装了一上午,开始时安装程序反复退出,后来刷了最新的BIOS,没想到重启之后竟然直接进系统了。然后就是更新系统,安装ROCM等等一系列。然后安装Hermes,使用deepseek-v4-flash,在Hermes辅助下安装llama.cpp。特意告诉Hermes要浏览抡锤者论坛中关于AMD显卡的帖子,特别要参考
https://lcz.me/topic/353/7900-xtx-qwen3.6-27b-ubuntu-rocm-vulkan-mtp-64-128-256k-全部實測整理
和
https://lcz.me/topic/100/7900xtx-llama.cpp-qwen3.6-27b-turboquant-mtp-测试结果分享/56
这两个帖子的内容。在此感谢 CHIA AN YANG 和 David Zhang 两位大神,也特别感谢斑竹建立了这个论坛让我学到了很多知识。
最后选定Qwen3.6-27B-Q4_K_M.gguf,使用Hermes自动配置,一次成功!硬件配置: 主板:MaxSun-Terminator-B850M-PRO CPU:AMD Ryzen 7 9700X 内存:金邦DDR5 5600 64GB SSD: 宏基GM7000 1TB+金邦 2TB 显卡:AMD Radeon AI PRO R9700 电源:Thermaltake SFX-850 机箱:机械大师C26 运行参数:/data/ai/apps/llama.cpp/build/bin/llama-server \ -m /data/ai/models/llm/Qwen3.6-27B-Q4_K_M.gguf \ -ngl 99 \ -fa 1 \ -c 131072 \ --cache-type-k q4_0 \ --cache-type-v q4_0 \ --spec-type draft-mtp \ --spec-draft-n-max 3 \ -ub 256 \ -np 1 \ --temp 0.7 \ --top-k 20 \使用起来感觉和线上的deepseek-v4-flash没有太大区别,速度差不多。但是运行起来的风扇噪音真是太大了!但是比起电水壶烧开水还是差远了。我把电脑放脚下,身后就是电水壶,水烧起来的声音完全能盖住显卡风扇的声音,满载时也能。但是机箱散热不好,测试时显卡温度偏高。
调整了一下机箱风扇的位置,效果并不明显。小机箱空间太受限了!装机时就很费劲!
为了安全,把功耗限制到280W。
性能损耗约4%。
后来感觉温度还是偏高,风扇太吵,又限制到270W。
这是现在模型刚加载时的温度:
这是模型运行时的温度:
心得:
1、AMD显卡在Linux下的生态还是可以的,至少我这个没有什么Linux使用经验的人,在AI和Hermes的帮助下,也就是花了1天时间就把大模型跑起来了,所以对AMD显卡有顾虑的人我觉得可以放心一些了。
2、涡轮卡的噪音确实是很大,但是比电水壶的声音还是差一些,隔一堵墙,关上门,满载时的噪音也是听不见的。算是给对噪音敏感的人一些真实感受吧。
3、算是个经验教训——机箱尽量选大一些,利于散热通风,长期运行也更有安全保障,装机时也能顺利一些。这些是我的一些体会,没有什么经验贡献,再次感谢斑竹和论坛里的各位大神的无私分享。
-
系统 于 取消固定此主题
-
@linghu007 显卡涨价了。
-
@linghu007 显卡涨价了。
@williamlouis 显卡日常价格就是10900,现在618奸商搞的。但我看了下CUP和内存反而降了,不过我看的是二手。显卡才是新的。
-
我们只能接受。生产力需要就入手。没项目就等等。