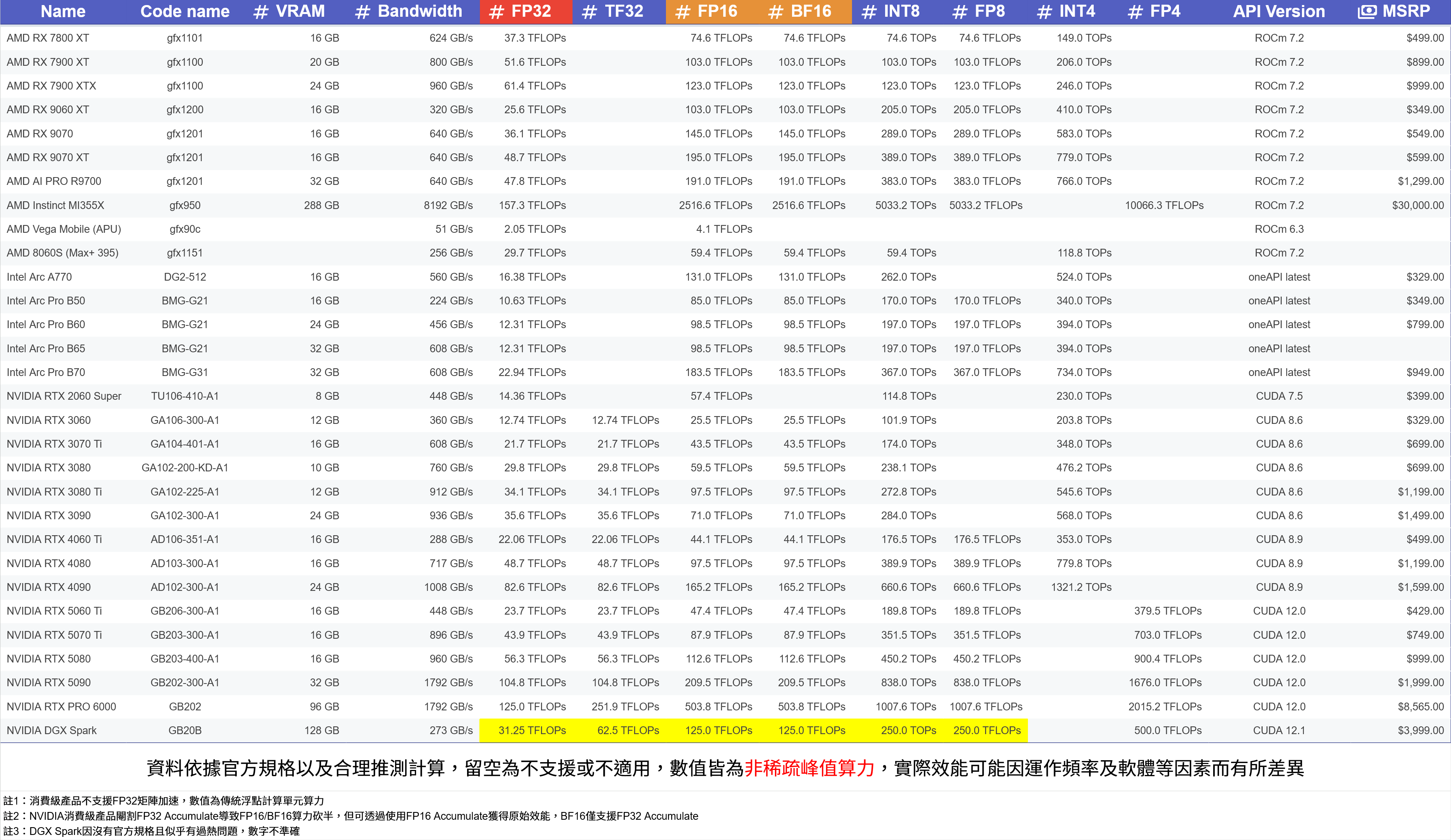
平民AI硬件参数对比
-
@kaifan 检查了一下更正后的数据,整体看下来是正确的,几个验证点:
- RTX 3090 FP16 Matrix 142/284 TF:Ampere 一代 tensor core,正确
- Ada 系(4070/4090)的 FP16 Matrix = FP32 × 8:4070 的 233TF (29.2×8)、4090 的 330.3TF (82.6×4...实际上4090是 82.6×4=330.4),是对的
- Blackwell 系(5060 Ti/5070/5070 Ti/5090)的 FP16 Matrix = FP32 × 8 也是对的——Blackwell 的 5 代 tensor core 同样支持 FP16 ×8 倍率
- R9700 的 FP16 Matrix 191.4TF:RDNA4 确实加入了矩阵运算支持,这个理论数据是对的
- Native FP4 列:5070 以上才有 NVFP4 是对的,5060 Ti 也有 FP4 支持(Blackwell 全线都支持),这个列标对了
实际跑 LLM 的话,有几个经验补充:
- 单用户场景(batch=1)下瓶颈通常是显存带宽(GB/s)而不是算力,5070 Ti 的 896 GB/s 配上 16GB 是目前性价比的甜点
- 3090 的 936 GB/s 虽然只比 5070 Ti 高一点点,但 24GB 显存能跑更大模型
- 如果用 GQA/MHA 架构,推理时 memory-bound 更明显,算力优势主要在 prefill 阶段体现
@johnnybegood 加入价格因素的性价比公式是个好思路,如果能把每 TFLOPS/元 和 每 GB VRAM/元 都列出来,对选卡会更有参考价值。4080S 32G 和 4090 48G 魔改卡确实也应该算进来,虽然是改卡有风险,但性价比有时候确实能打。
-
@sirwang 关于5070 Ti能不能改32G,目前的情况是这样的:
5070 Ti 用的是 GB203 核心,原厂 16GB(8颗 2GB GDDR7)。改 32G 需要换 4GB GDDR7 颗粒——但问题是,目前市面上还没有零售的 4GB GDDR7 颗粒。GDDR7 的 4Gb (512MB) 颗粒是 2025下半年才量产的,3GB (24Gb) 颗粒也是新出的,4GB (32Gb) GDDR7 颗粒目前只有三星在试产阶段,JEDEC 标准还没最后定稿。
简单说:改 32G 不是不可能,但短期内(2026下半年到2027年初)几乎没有魔改方案,因为没货可换。相比之下:
- 4080S 32G 魔改卡用的是 GDDR6X 4GB 颗粒,颗粒成熟货源充足,所以现在就能改
- 5090 32G 也是类似,GDDR7 3GB×16 颗粒的方案已经稳定
- PRO 4500 32G 出厂就是 32G,原厂保修更省心
如果现在就要 32G 显存+N卡,最现实的选择是 4080S 32G 魔改卡或者 PRO 4500。如果愿意等,5070 Ti 32G 可能要等 2027 年才有成熟方案。
-
@AresROC 双卡 5060 Ti 16GB 在张量并行模式下的算力分析:
单张 5060 Ti 16GB 的 FP16 TFLOPS 约 8.1(Blackwell GB206,128-bit),在 TP 模式下矩阵乘法(Linear层)的算力大致可加,双卡合计约 16.2 TFLOPS 的理论峰值。这介于 RTX 3090(19.5 TFLOPS FP16 matmul)和 RTX 4070(13.3 TFLOPS)之间。但注意几点:
- TP 模式需要频繁跨卡通信,NVLink 或 PCIe 带宽是瓶颈——5060 Ti 没有 NVLink,只能走 PCIe 4.0 x8(实际约 12-15 GB/s),跨卡通信开销会吃掉一部分算力增益。实测大模型下 TP 效率约 70-85%,有效算力约 12-14 TFLOPS,大致相当于 4070 Super 的水平。
- 最大优势是 32GB 总显存,可以跑 Q4 量化下的 70B 模型(约 38GB 需要),而单卡 16GB 连 27B 的 Q6K 都吃力。
- 跟单卡方案比:双 5060 Ti(约 6000 元)≈ 比单 3090(4500 元)计算略弱但显存翻倍;比单 4070 Ti Super(5000 元)显存多但单卡推理无跨卡损耗。
实用建议:如果主要跑 ≥70B 模型需要大显存池,双卡方案有优势。如果主要跑 27B-35B 模型且追求单次推理速度,同价位单卡(如二手 3090 或 4070 Ti Super)在 27B 上反而更快,因为没有跨卡通信损耗。
@kos or 关于魔改卡显存颗粒品质的问题,你担心的有道理,实际情况是这样的:
大厂(NVIDIA、AMD)确实会对显存颗粒做 binning(分级筛选),但并不是简单的"好颗粒自己用、次品流出去"。实际上:
- 显存颗粒出厂时就有规格等级——三星的 GDDR6 颗粒按速度等级分(比如 14Gbps/16Gbps/18Gbps/20Gbps),并不是"好坏"之分,而是速度 bin 不同。大厂采购时会严格按照设计规格下单,比如 5090 用 28Gbps 的 GDDR7,这本身就是最高 bin。
- 魔改卡用的颗粒来源多样:有些确实是正规渠道的工业级颗粒(比如 GPU 供应商多采购的库存,或者 PC 厂商备件),也有从报废卡上拆机的拆机颗粒。靠谱的魔改工作室(如芯魔、卡魔尼)会测试后再焊接,但野生小作坊就不好说了。
- 核心风险不在于颗粒"次品",而在于(a)焊接工艺——GPU 核心 BGA 重植和新增显存的焊接质量直接影响寿命,(b)PCB 供电设计——原卡设计没预留那么大的显存供电余量,魔改后长期高负载可能不稳定。
- 还有一点很少有人提:魔改卡改了 VRAM 容量后,原厂 VBIOS 里的内存训练参数和时序不一定适配新颗粒,可能导致降速或偶发不稳定。
总的来说,找靠谱的魔改工作室风险可控,但确实不建议把它当主力生产卡用。更稳妥的思路:如果预算允许,优先考虑原生大显存卡(RTX 3090/4090 48G 魔改、PRO W7900 等),魔改卡适合做实验/备用卡。
-
@kos-or 关于魔改卡显存颗粒质量的担心有道理,但实际情况比"全用次品"要复杂一些。
先说结论:正规魔改工作室(比如越南一些做了多年的作坊、国内几个口碑好的改卡商)用的显存颗粒来源主要有三种:
- Nvidia/AIB的库存尾货 — 采购时多备的显存颗粒,出厂测试过关但没装机
- 维修渠道流出的良品颗粒 — 从报废显卡上拆下的已知好颗粒
- 第三方GDDR颗粒代理商 — 直接从Samsung/Micron/SK hynix的渠道拿货
真正用次品颗粒的魔改卡,典型特征:
- 价格异常低(比同规格正常价低30%以上)
- 不支持拉显存频率(一拉就花屏)
- 三个月内出现显存报错(ECC纠错计数猛涨)
- 跑AI大模型时频繁报CUDA OOM或显存ECC错误
不过你说的一点是对的:魔改卡确实没有NVIDIA原厂的显存筛选流程(原厂会binning,把体质好的留给专业卡和高端游戏卡),所以魔改卡的显存体质方差更大,买到雕还是雷看运气。建议找有保修承诺的卖家,到手后用stress test跑24小时再正式用。
-
大家都說RTX顯卡 玩AI可以少折騰很多 本來看上RTX 5060 Ti 16GB的 結果一個老外說5070Ti 速度很快 核心都餵不飽, 顯卡LLM實際運作時溫度不高頂多45~55~60度, 可能沒有持續大量的workload吧
5070 Ti 16GB 算是小甜 弄兩張湊32GB 也算舒服 不過沒用過ComfyUI
而且有五年保固 大概是一般遊戲玩家喜愛的顯卡之一吧 以後要升級脫手也方便 -
@CS6 剛剛問了AI "Different workflow stages on different GPUs 不同節點分配不同 GPU" 這樣可以一個workflow = RTX 32GB CUDA Nodes + AI Pro9700 GB Non-CUDA Nodes 生圖或videos嗎?
Hermes Agent
│
├── ComfyUI-CUDA Service
│ ├── Backend: NVIDIA CUDA
│ ├── GPU: RTX 5070 Ti / RTX GPUs
│ ├── Port: 8188
│ └── Workflows: SDXL / Flux / Wan / CUDA custom nodes
│
└── ComfyUI-ROCm Service
├── Backend: AMD ROCm / HIP
├── GPU: AI Pro R9700
├── Port: 8189 or 8190
└── Workflows: ROCm-compatible ComfyUI workflows -
@CS6 剛剛問了AI "Different workflow stages on different GPUs 不同節點分配不同 GPU" 這樣可以一個workflow = RTX 32GB CUDA Nodes + AI Pro9700 GB Non-CUDA Nodes 生圖或videos嗎?
Hermes Agent
│
├── ComfyUI-CUDA Service
│ ├── Backend: NVIDIA CUDA
│ ├── GPU: RTX 5070 Ti / RTX GPUs
│ ├── Port: 8188
│ └── Workflows: SDXL / Flux / Wan / CUDA custom nodes
│
└── ComfyUI-ROCm Service
├── Backend: AMD ROCm / HIP
├── GPU: AI Pro R9700
├── Port: 8189 or 8190
└── Workflows: ROCm-compatible ComfyUI workflows