
来自RTX PRO 5000的碎碎念
-
最近入手了一张RTX PRO 5000,上机试用了几天。于是上来发一个零散的使用记录与心得。
个人拙见,如有错误欢迎指正。
1、购买理由
在5月涨价之前,相比较7.3万的rtx pro 6000 96GB,3.6万的rtx pro 5000 48GB完全没有任何性价比。
但随着这一轮涨价,pro6000的价格飙升到了10万以上,这时候只溢价2000的pro 5000 48GB就逐渐香了起来。在综合考虑能耗、噪音、稳定性等维度之后,最终摒弃了4090 48GB魔改版本,选择了国行的RTX PRO 5000。
2、硬件安装
特殊的涡轮卡
RTX PRO 5000是一个1.5槽散热+0.5槽输出接口的非标准显卡。接在普通的塔式机箱时,散热出口会被机箱pcie格栅挡掉一部分。同时,因为dp口靠上,所以dp口也是将将露出pcie挡板。于是,航空剪伺候,我去掉了一条pcie格栅。
DP接口也略有遮挡,但综合考虑之后我还是决定保留上面的pcie格栅,否则因为去掉太多,显卡固定螺丝位置的刚性会有所下降。
16pin注意事项
随卡附带一条双8pin转16pin转接线。需要注意的是,如果你之前的显卡用的是1分2的8pin接口,对于300W功率的RTX PRO 5000,峰值使用电流就接近单8pin的功率极限了。所以建议还是老老实实使用双8pin转16pin电源线。如果你的电源原生支持16pin的话,则更好。btw:不同品牌电源的8pin、16pin线不要混用。不同品牌,电源侧的针脚定义是有概率不一致的。 值得吐槽的是,即便是专业卡,16pin还是老样子,插入手感模糊,紧。没有锁定感,所以一定插到底。
3、实际测试
综合芯片的算力和显存大小,qwen3.6-27B运行Q6应该是最佳的甜点区间。使用Claude Code进行实际相同的编程任务测速。
启动参数:
-m ~/.local/models/Qwen3.6-27B-Q6_K.gguf \ --mmproj ~/.local/models/mmproj-BF16.gguf \ -ngl 99 \ --flash-attn on \ --cache-type-k q8_0 \ --cache-type-v q8_0 \ -c 262144 \ --port 8080 \ --host 0.0.0.0 \ --temp 0.6 \ --top-p 0.95 \ --repeat-penalty 1.05 \ --spec-type draft-mtp \ --spec-draft-n-max 2非MTP:prefill在1400t/s,decode速度在32t/s左右。
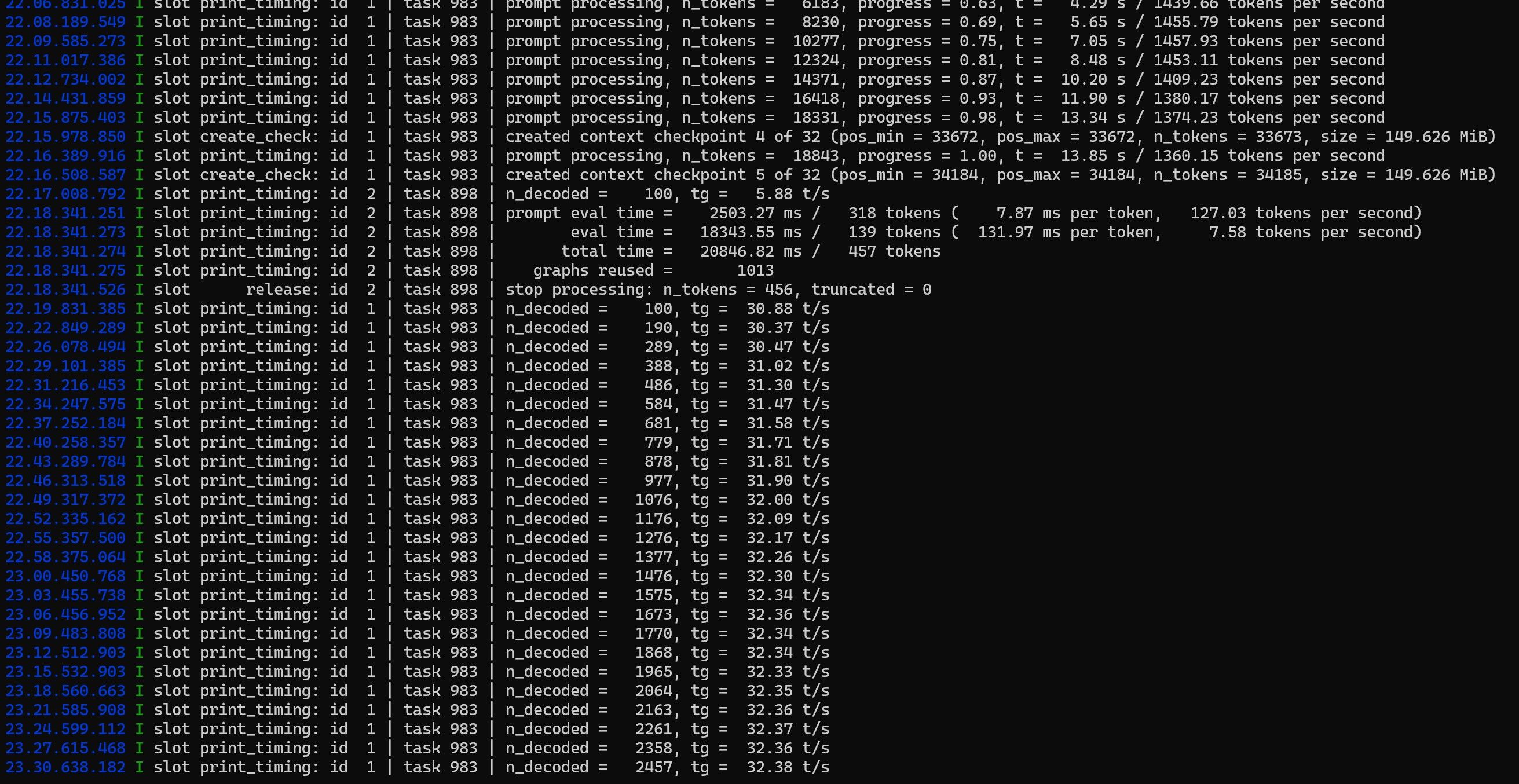
MTP x2:prefill在1400t/s,decode在51t/s左右。
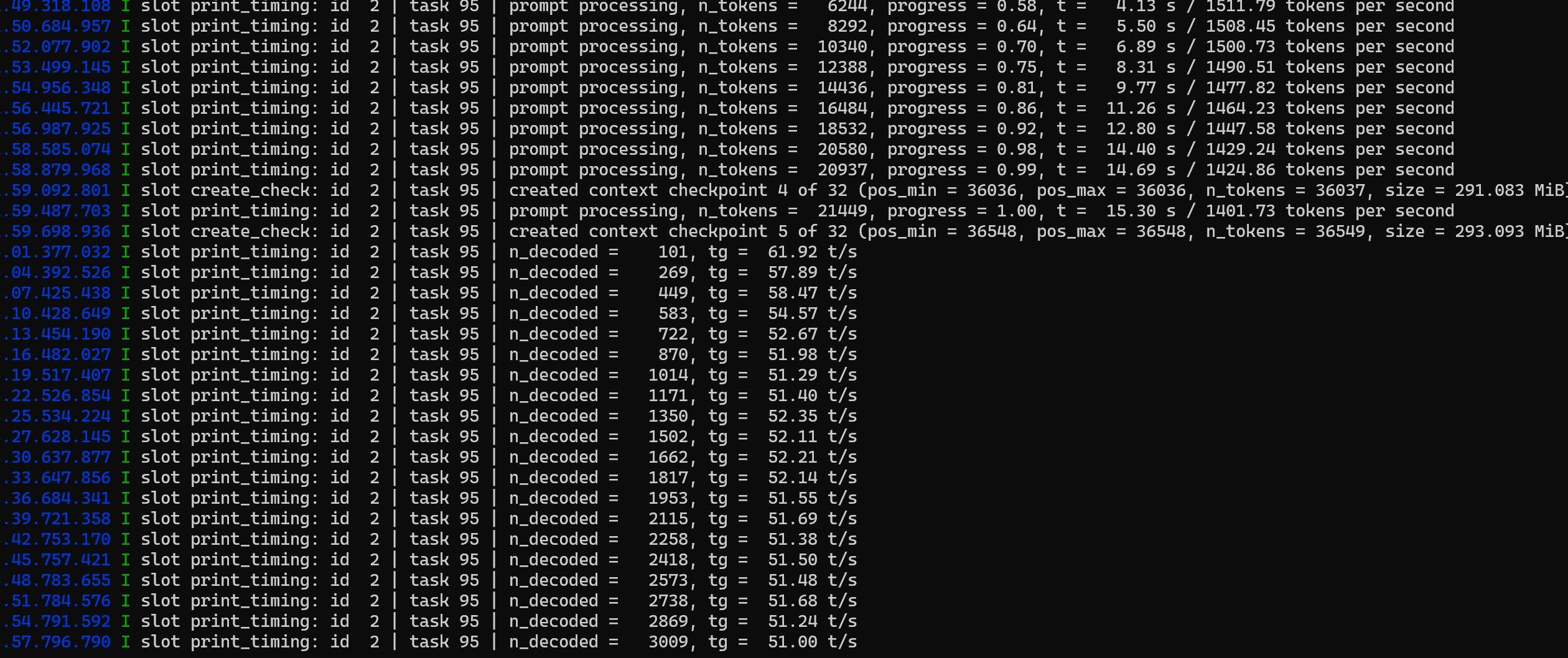
注意:实际使用过程中,随着上下文的膨胀,速度会有所下降。以及并不是所有请求MTP都能够命中生效,总体命中概率大概60%。
4、使用体验
噪音:典型的涡轮卡目标温度调教,核心温度会锁死85度。室温在28度左右的情况下,满载压在85度的转速大概是60%。噪音是完全被CPU风扇+机箱风扇掩盖的。
在跑qwen3.6-27B-nvfp4时,曾经崩溃过驱动导致死机。这时风扇会自动锁死100%,动静还是很大的。和戴森吸尘器有一拼。稳定性:同上,只在运行nvfp4时驱动崩溃自动重启过,目前还没排查出原因。已经用DDU全清了显卡驱动,然后重新安装了596.59,再观察观察。
5、个人思考
如果不考虑个人预算,只从单纯的AI硬件性价比来讲,目前PRO 5000和PRO 6000的价格结构才是合理的(6000大概是5000的2.5~3倍)。反过来思考,上个月7.3万的PRO 6000工作站版是真的非常有性价比(几乎可以理解为显存叠加,芯片性能白送)。
音视频是我之前不太擅长的领域,目前也在逐渐尝试,发现大场景,高动态的视频场景,48GB的显存+64GB内存还是远远不够。
但是世界上没有如果。所以只能是以优化、折腾管线、工作流来换价格了。 -
最近入手了一张RTX PRO 5000,上机试用了几天。于是上来发一个零散的使用记录与心得。
个人拙见,如有错误欢迎指正。
1、购买理由
在5月涨价之前,相比较7.3万的rtx pro 6000 96GB,3.6万的rtx pro 5000 48GB完全没有任何性价比。
但随着这一轮涨价,pro6000的价格飙升到了10万以上,这时候只溢价2000的pro 5000 48GB就逐渐香了起来。在综合考虑能耗、噪音、稳定性等维度之后,最终摒弃了4090 48GB魔改版本,选择了国行的RTX PRO 5000。
2、硬件安装
特殊的涡轮卡
RTX PRO 5000是一个1.5槽散热+0.5槽输出接口的非标准显卡。接在普通的塔式机箱时,散热出口会被机箱pcie格栅挡掉一部分。同时,因为dp口靠上,所以dp口也是将将露出pcie挡板。于是,航空剪伺候,我去掉了一条pcie格栅。DP接口也略有遮挡,但综合考虑之后我还是决定保留上面的pcie格栅,否则因为去掉太多,显卡固定螺丝位置的刚性会有所下降。
16pin注意事项
随卡附带一条双8pin转16pin转接线。需要注意的是,如果你之前的显卡用的是1分2的8pin接口,对于300W功率的RTX PRO 5000,峰值使用电流就接近单8pin的功率极限了。所以建议还是老老实实使用双8pin转16pin电源线。如果你的电源原生支持16pin的话,则更好。btw:不同品牌电源的8pin、16pin线不要混用。不同品牌,电源侧的针脚定义是有概率不一致的。 值得吐槽的是,即便是专业卡,16pin还是老样子,插入手感模糊,紧。没有锁定感,所以一定插到底。
3、实际测试
综合芯片的算力和显存大小,qwen3.6-27B运行Q6应该是最佳的甜点区间。使用Claude Code进行实际相同的编程任务测速。
启动参数:
-m ~/.local/models/Qwen3.6-27B-Q6_K.gguf \ --mmproj ~/.local/models/mmproj-BF16.gguf \ -ngl 99 \ --flash-attn on \ --cache-type-k q8_0 \ --cache-type-v q8_0 \ -c 262144 \ --port 8080 \ --host 0.0.0.0 \ --temp 0.6 \ --top-p 0.95 \ --repeat-penalty 1.05 \ --spec-type draft-mtp \ --spec-draft-n-max 2非MTP:prefill在1400t/s,decode速度在32t/s左右。
MTP x2:prefill在1400t/s,decode在51t/s左右。
注意:实际使用过程中,随着上下文的膨胀,速度会有所下降。以及并不是所有请求MTP都能够命中生效,总体命中概率大概60%。
4、使用体验
噪音:典型的涡轮卡目标温度调教,核心温度会锁死85度。室温在28度左右的情况下,满载压在85度的转速大概是60%。噪音是完全被CPU风扇+机箱风扇掩盖的。
在跑qwen3.6-27B-nvfp4时,曾经崩溃过驱动导致死机。这时风扇会自动锁死100%,动静还是很大的。和戴森吸尘器有一拼。稳定性:同上,只在运行nvfp4时驱动崩溃自动重启过,目前还没排查出原因。已经用DDU全清了显卡驱动,然后重新安装了596.59,再观察观察。
5、个人思考
如果不考虑个人预算,只从单纯的AI硬件性价比来讲,目前PRO 5000和PRO 6000的价格结构才是合理的(6000大概是5000的2.5~3倍)。反过来思考,上个月7.3万的PRO 6000工作站版是真的非常有性价比(几乎可以理解为显存叠加,芯片性能白送)。
音视频是我之前不太擅长的领域,目前也在逐渐尝试,发现大场景,高动态的视频场景,48GB的显存+64GB内存还是远远不够。
但是世界上没有如果。所以只能是以优化、折腾管线、工作流来换价格了。 -
@566656661 当然欢迎交流,以下是我的FP8参数,您可以看看是否有什么值得优化的
~/.local/venvs/vllm/bin/vllm serve ~/.local/models/Qwen3.6-27B-FP8 \ --port 8000 \ --max-model-len 262144 \ --gpu-memory-utilization 0.95 \ --kv-cache-dtype int8_per_token_head \ --reasoning-parser qwen3 \ --dtype auto \ --enable-auto-tool-choice \ --tool-call-parser qwen3_xml \ --served-model-name Qwen/Qwen3.6-27B -
@566656661 当然欢迎交流,以下是我的FP8参数,您可以看看是否有什么值得优化的
~/.local/venvs/vllm/bin/vllm serve ~/.local/models/Qwen3.6-27B-FP8 \ --port 8000 \ --max-model-len 262144 \ --gpu-memory-utilization 0.95 \ --kv-cache-dtype int8_per_token_head \ --reasoning-parser qwen3 \ --dtype auto \ --enable-auto-tool-choice \ --tool-call-parser qwen3_xml \ --served-model-name Qwen/Qwen3.6-27B不考慮坊間的nvfp4嘛? 這是blackwell架構的精髓, 模型權重至少會少個10%以上, 雖說特定任務benchmark下精度較低, 如果害怕精度損失的話可以繼續用其他坊間的fp8模型 (Qwen官方沒有坊間玩得花, 坊間其他不多不少都會有些性能或vram優化)
然後不是太懂要用int 8 token head, 這東東給30系用比較合適, 畢竟Ampere沒有fp8, 論精度跟性能fp8比較好吧
還有慣用的mtp跟用cu130 nightly (v 0.20, blackwell優化), cu129 latest (v 0.22)這些比較常規的
-
不考慮坊間的nvfp4嘛? 這是blackwell架構的精髓, 模型權重至少會少個10%以上, 雖說特定任務benchmark下精度較低, 如果害怕精度損失的話可以繼續用其他坊間的fp8模型 (Qwen官方沒有坊間玩得花, 坊間其他不多不少都會有些性能或vram優化)
然後不是太懂要用int 8 token head, 這東東給30系用比較合適, 畢竟Ampere沒有fp8, 論精度跟性能fp8比較好吧
還有慣用的mtp跟用cu130 nightly (v 0.20, blackwell優化), cu129 latest (v 0.22)這些比較常規的
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
不做视频生产力。压榨不压榨极限值没什么必要。够用就行了。我都是开功耗墙跑。这样噪音小了好多。
-
不做视频生产力。压榨不压榨极限值没什么必要。够用就行了。我都是开功耗墙跑。这样噪音小了好多。
-
感覺這不是壓不壓榨極限性能的問題, 而是這個性能好像連甜品位都還沒到的樣子
@566656661 看感觉尺度了。我的够用不是你的够用。得你感觉够用才是真够用。不是吗?
-
@566656661 看感觉尺度了。我的够用不是你的够用。得你感觉够用才是真够用。不是吗?
-
我非常懒。所以很少折腾自己不需要的东西。
-
 K kop wang 于 引用了 此主题
K kop wang 于 引用了 此主题
-
@b9704037 Q8或者FP8都测试了,显存是占满了,但是效率下降了。不开MTP,decode只有15t/s左右。MTP的话,因为显存占用更大,上下文挤占太多。FP8不开MTP只能开200k上下文。
-
系统 于 取消固定此主题

