来自RTX PRO 5000的碎碎念
-
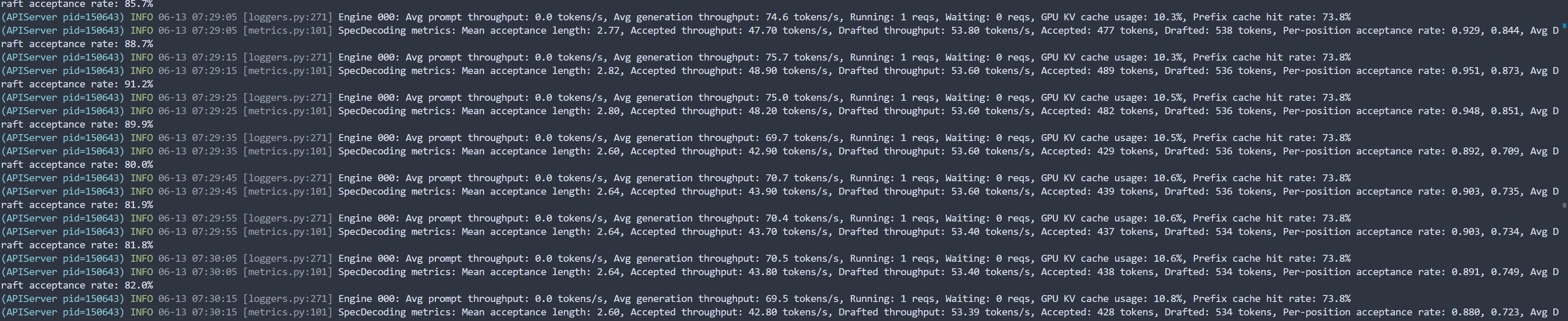
@566656661 当然欢迎交流,以下是我的FP8参数,您可以看看是否有什么值得优化的
~/.local/venvs/vllm/bin/vllm serve ~/.local/models/Qwen3.6-27B-FP8 \ --port 8000 \ --max-model-len 262144 \ --gpu-memory-utilization 0.95 \ --kv-cache-dtype int8_per_token_head \ --reasoning-parser qwen3 \ --dtype auto \ --enable-auto-tool-choice \ --tool-call-parser qwen3_xml \ --served-model-name Qwen/Qwen3.6-27B -
@566656661 当然欢迎交流,以下是我的FP8参数,您可以看看是否有什么值得优化的
~/.local/venvs/vllm/bin/vllm serve ~/.local/models/Qwen3.6-27B-FP8 \ --port 8000 \ --max-model-len 262144 \ --gpu-memory-utilization 0.95 \ --kv-cache-dtype int8_per_token_head \ --reasoning-parser qwen3 \ --dtype auto \ --enable-auto-tool-choice \ --tool-call-parser qwen3_xml \ --served-model-name Qwen/Qwen3.6-27B不考慮坊間的nvfp4嘛? 這是blackwell架構的精髓, 模型權重至少會少個10%以上, 雖說特定任務benchmark下精度較低, 如果害怕精度損失的話可以繼續用其他坊間的fp8模型 (Qwen官方沒有坊間玩得花, 坊間其他不多不少都會有些性能或vram優化)
然後不是太懂要用int 8 token head, 這東東給30系用比較合適, 畢竟Ampere沒有fp8, 論精度跟性能fp8比較好吧
還有慣用的mtp跟用cu130 nightly (v 0.20, blackwell優化), cu129 latest (v 0.22)這些比較常規的
-
不考慮坊間的nvfp4嘛? 這是blackwell架構的精髓, 模型權重至少會少個10%以上, 雖說特定任務benchmark下精度較低, 如果害怕精度損失的話可以繼續用其他坊間的fp8模型 (Qwen官方沒有坊間玩得花, 坊間其他不多不少都會有些性能或vram優化)
然後不是太懂要用int 8 token head, 這東東給30系用比較合適, 畢竟Ampere沒有fp8, 論精度跟性能fp8比較好吧
還有慣用的mtp跟用cu130 nightly (v 0.20, blackwell優化), cu129 latest (v 0.22)這些比較常規的
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
不做视频生产力。压榨不压榨极限值没什么必要。够用就行了。我都是开功耗墙跑。这样噪音小了好多。
-
不做视频生产力。压榨不压榨极限值没什么必要。够用就行了。我都是开功耗墙跑。这样噪音小了好多。
-
感覺這不是壓不壓榨極限性能的問題, 而是這個性能好像連甜品位都還沒到的樣子
@566656661 看感觉尺度了。我的够用不是你的够用。得你感觉够用才是真够用。不是吗?
-
@566656661 看感觉尺度了。我的够用不是你的够用。得你感觉够用才是真够用。不是吗?
-
我非常懒。所以很少折腾自己不需要的东西。
-
 K kop wang 于 引用了 此主题
K kop wang 于 引用了 此主题
-
@b9704037 Q8或者FP8都测试了,显存是占满了,但是效率下降了。不开MTP,decode只有15t/s左右。MTP的话,因为显存占用更大,上下文挤占太多。FP8不开MTP只能开200k上下文。
-
系统 于 取消固定此主题
-
-
@sirwang 咬牙又去了趟洗浴中心。真是好。这个选择真是值当!
-
 T Tony Wang 于 引用了 此主题
T Tony Wang 于 引用了 此主题