
3090 24G 跑QWOPUS 3.6 27B mtp 131K上下文 KV(Q8_0) 55TOK/S 智能开关思考- 最终配置,再也不折腾了(6月14日更新)
-
@stxpnet 你的配置很扎实,168K + MTP + IQ4_XS在3090上能稳定在22-23.5G显存占用,确实是很均衡的生产配置了。
关于 iGPU 开机占用 400MB 的问题,这不是 bug,是 Ubuntu 24.04 的 i915 驱动的正常行为:
-
这是 GTT 预留空间,不是实际内存占用:i915 驱动在初始化时会预分配一块 GTT(Graphics Translation Table)地址空间,这部分是虚拟地址映射,并不会全部占用物理内存。Ubuntu 24.04 因为默认启用了 simpledrm / efifb,会预留更大的一块的 framebuffer。
-
如果你真的想减少它,有几个方向:
- 进 BIOS 找 IGD Memory / DVMT Pre-Allocated:把这个值设到最低(通常是 64M 或 32M),而不是 Auto 或 256M/512M
- 加内核参数
video=efifb:off i915.modeset=0:禁用 efifb 可以让 i915 不预分配那么大的一块的 framebuffer。但注意这样做的话,在显示器插集显的情况下,启动画面和 tty 可能分辨率会比较低 - 最简单的方案:如果显示器是 DP/HDMI 接口的,直接插到 3090 上,用 NVIDIA 独显输出,集显完全不接显示器。这样 i915 驱动可能根本不会加载(或者加载但 framebuffer 占用极小),400MB 就完全省下来了
-
实际影响几乎为零:400MB 对于 16G x 4 = 64G 的总内存来说,占比不到 1%。除非你的 Docker/llama.cpp 正好差这 400MB 内存不然不用纠结。
总体来说你这个配置在 3090 上已经很标杆了,iq4_xs + q8_0 kv + mtp + 168k 的搭配很合理,可以安心投入生产了。
-
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
进 BIOS 找 IGD Memory / DVMT Pre-Allocated:把这个值设到最低(通常是 64M 或 32M),而不是 Auto 或 256M/512M 这个是正解。很懒只能这么回答了。
-
更新一下.6月9日 发现一个新的国人制作的加载器(BoFan-tunning/llama.cpp-MTP-TurboQuant).它的亮点:
 ,这个智能思考不就是我一直想要的吗?没想到这个人行动力这么强,直接给做出来了.
,这个智能思考不就是我一直想要的吗?没想到这个人行动力这么强,直接给做出来了.四个新特性体现在命令里: 1. TurboQuant 非对称 KV 压缩 — -ctk q8_0 -ctv turbo3。K 保持 q8_0 精度,V 压缩到 3bit,比旧命令的 q8_0+q8_0 省一半以上 KV 显存 [注意,这个选项可能只适合40 50系算力强,显存容量小的阉割版消费显卡] ,并不适合我的3090 24G(我的卡算力和显存容量 旗鼓相当) . 2. MTP 推测解码 — --spec-type mtp(新命名,记得修改命令),每步预测 3 个 token,2-5 倍吞吐 3. Vision 多模态 — --mmproj 保留,新分支修复了 MTP+视觉同时开启的崩溃问题 4. Jinja v10 模板 — 3.6_chat_template-v10.jinja,智能思考(短问题秒回、长问题深度推理)+ 9 项 Tool Calling 修复 非常酷,用过你就知道了. 再在IDE里面跟TRAE配置好,多步调用 爽飞. 这个文件直接在作者repo源码里面包含了。原本我是想用来测试一上TURBO QUANT3 权重的3.6 35B A3B MOE模型,但我试了之后总是报错,应该是格式不兼容.
最后我还是只能试:localweights/Qwen3.6-27B-MTP-IMAT-IQ4_XS-Q8nextn-GGUF
这个模型.
测试加载命令(直接用llama.cpp加载,我的cuda环境是12.4)
命令这里也挺玄学的,我在REDDIT见过,有的人说 K要用Q8,V要用Q4, 另外一些人说K要用Q4,V要用Q8
但是这个新的加载器,肯定是按作者意思啊.killall llama-server 2>/dev/null; sleep 3 cd /data/model2/bofan-llama.cpp/build/bin CUDA_SCALE_LAUNCH_QUEUES=4x \ ./llama-server \ -m /data/models/qwen3.6-27b-gguf/Qwen3.6-27B-MTP-IMAT-IQ4_XS-Q8nextn.gguf \ -c 220000 \ -ngl 9999 \ -fa on --metrics \ -ctk q8_0 -ctv turbo3 \ --spec-type mtp \ --spec-draft-n-max 3 \ --jinja \ --chat-template-file /data/model2/bofan-llama.cpp/3.6_chat_template-v10.jinja \ --temp 0.6 \ --min-p 0.05 --top_p 0.95 \ --mlock -np 1 -t 6 -tb 6 \ -b 2048 -ub 512 \ --host 0.0.0.0 --port 8025 \ --reasoning auto \ --reasoning-format deepseek --reasoning-budget 3072为了对比效果,尽量使用了一样的参数.
测试结果: 伟人6首诗.自动关闭了思考.25秒.速度70T/S

开启思考: 64秒, 74T/S,有点东西啊.

新开会话(不重启llama.cpp) 测试小乔: 19秒! 1000token输出.
强制开思考,31秒 58T/S,比之前那个要快(之前是45T/S左右)
换测一下俄罗斯方块吧,这个加载器 给我的感觉就是思考或预处理的时间略长,但是似乎受益于工具调用接口的改进,和TRAE的配合更好一些:
这个模型中途调用 的时候似乎喜欢用英文,可能是老外制作的缘故,对我来说正好可以学一下英语,所以无所谓,它最后总结的时候说中文就可以了.
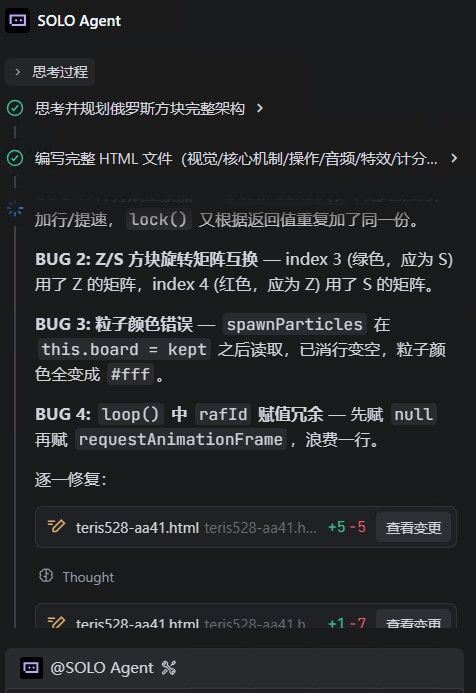
8分钟,改来改去做好了,但是形状不完美,这应该就是turbo3压缩导致的了. turbo3换取了显存,但精度也丢了 ,模型思考后过于自信.
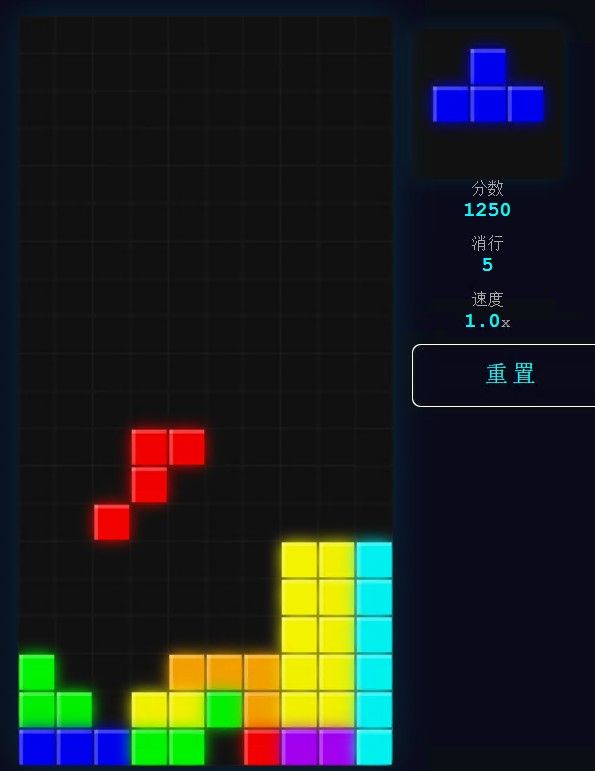
此时显存占用为23.229G. 我决定改一下参数:既然它编程有点缺陷,那我试试turbo4 吧,现在只把参数改成-ctv turbo4.
10个脑筋急转弯,强制它思考,评分还是85分,但速度从56秒减少到了37秒.
婚姻电视剧测试, 这种要分步的,提问字数少,为了质量还是要强制它思考.原来是85秒,现在减少到了68秒(总输出token增加了50多个,现在是4490)

后面我想跑一下中国象棋的编程任务 (这是最复杂的),但是中途直接干爆OOM了,估计是 batch size设置为2000的原因 ,如果剩余显存太少,而这边还在强制灌入长文本的话,框架无法处理,可能导致显存OOM。
这时我想还是回到KV CACHE双Q8量化吧。
问点文学问题热身:

整体感觉带不带思考都比较快。

工具调用我觉得比noonghunna的那个框架要好,我目前查看nvtop,显存已经到23.89G了.眼睁睁看着显存直接到24G 爆掉,不过拿着日志问智谱,又学到一个好经验.
-b 1024 -ub 512按智谱建议改这两个数值.重新加载,调小TRAE的上下文窗口,直接在原来那个窗口里面尝试修复BUG, 上下文召回非常慢. 最后看着快要爆OOM了,直接取消任务,重新开一个窗口:
查看一下cnchess609-346.html,这是个中国象棋的html游戏,现在请先修复红方墓地棋子每个都要占一行,导致UI被击穿,黑方墓地棋子无显示的BUG.一句话快速就修复了BUG. 再测,游戏基本OK了.
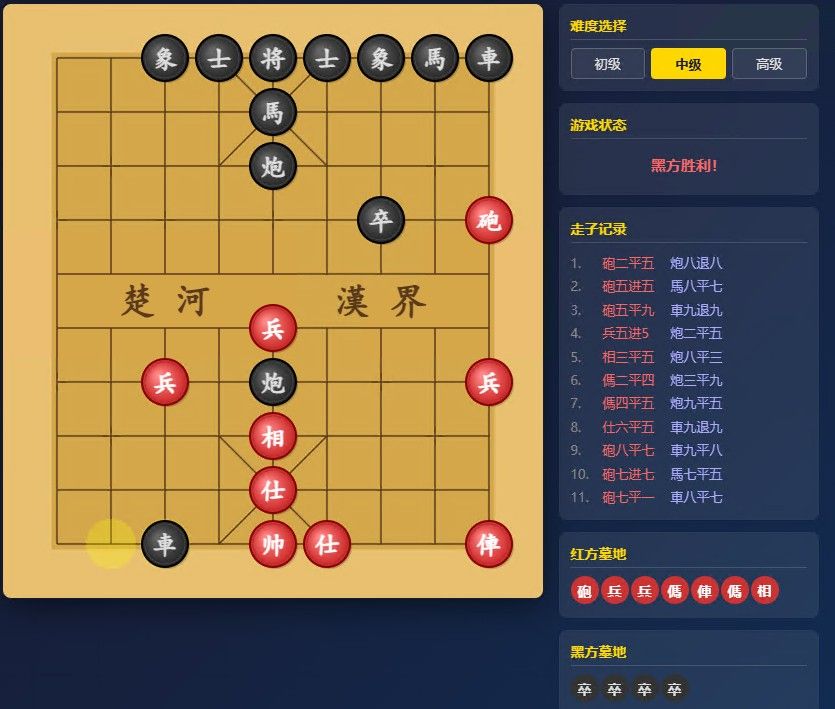
今天就测到这里了.我要先忙工作了,然后我心心念念的真实项目必须跑起来了.
以后的打算: 小项目,或者简单的跨2-3个文件的,都先用TRAE + 本地显卡尝试,这样最大限度节省TOKEN, 只有这套 152K 上下文 无法解决的问题,才把代码发给,线上前沿大模型,让它们解决. -
进 BIOS 找 IGD Memory / DVMT Pre-Allocated:把这个值设到最低(通常是 64M 或 32M),而不是 Auto 或 256M/512M 这个是正解。很懒只能这么回答了。
-
最终决定使用的配置(ubuntu 24.04, CUDA 12.4,按3090参数编译的bofan框架) :
killall llama-server 2>/dev/null; sleep 3 cd /data/model2/bofan-llama.cpp/build/bin CUDA_SCALE_LAUNCH_QUEUES=4x \ ./llama-server \ -m /data/models/qwen3.6-27b-gguf/Qwen3.6-27B-MTP-IMAT-IQ4_XS-Q8nextn.gguf \ -c 152000 \ 这个务必多多测试再确定一个合适的值,不要用于生产,防止爆显存导致影响工作进度 。 -ngl 9999 \ -fa on --metrics \ -ctk q8_0 -ctv q8_0 \ 编程任务才需要这个,如果你只是问答和驱动hermes跑简单任务,可以 关思考这两项改为Q4,上下文应该 可以 进一步拉高。 --spec-type mtp \ --spec-draft-n-max 3 \ --jinja \ --chat-template-file /data/model2/bofan-llama.cpp/3.6_chat_template-v10.jinja \ #这行非常重要它确保能使用自动思考功能. --temp 0.6 \ 编程任务的推荐值 --min-p 0.04 --top_p 0.95 \ --mlock -np 1 -t 6 -tb 6 \ -b 4096 -ub 512 \ 这两个参数,在首次写代码的时候,如果你估计产生的BUG不多的情况下,可以同时加倍甚至改成8192/2048,这样预填充速度会快很多的,从而加速任务. 但在上下文满的时候,OOM风险也会爆增,所以要自己权衡.在编程任务的时候务必紧盯NVTOP. --host 0.0.0.0 --port 8025 \ --reasoning auto \ --reasoning-format deepseek --reasoning-budget 3072跑一下论坛那个128K 测试, 跑完了显存占用23GB
用时60秒,比之前的框架的70秒 要快:
最后直接让它写个HTML来自评:

质量也是在线的.
这套配置还有可以打磨的地方,有需要请关注本帖, 过几天我再更新一下.
-
附我的HERMES解析出的bofan框架自动思考实现路径.
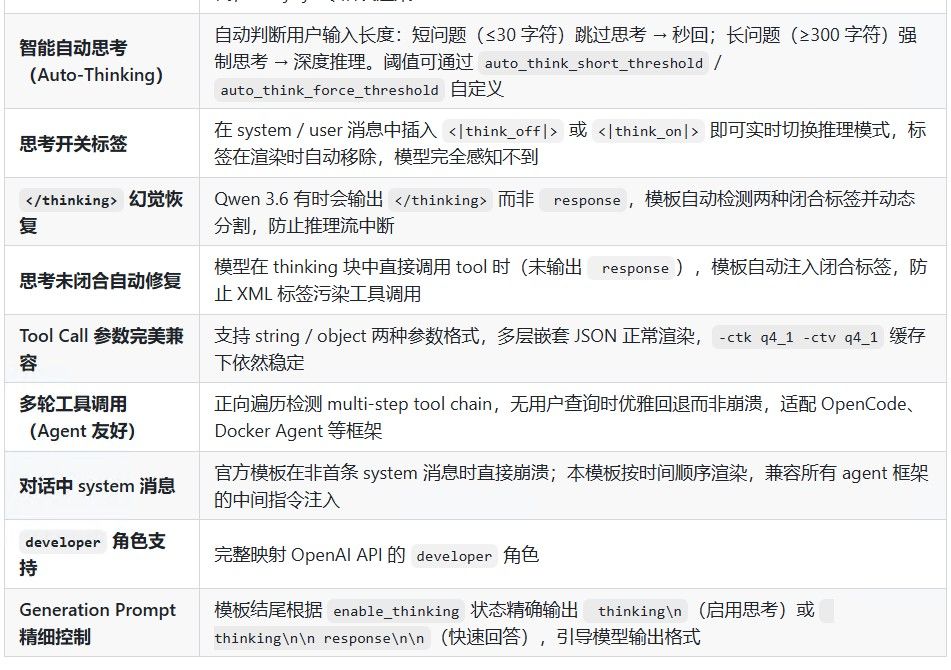
这个自动思考功能有三层控制: 第一层:默认阈值(模板内置) 短问题阈值: 30 字符 → ≤30 字符自动跳过思考,秒回 强制思考阈值: 300 字符 → ≥300 字符强制深度推理 中间区域(31~299): 维持 enable_thinking 默认值(true),走思考模式 第二层:API 调用时覆盖阈值 通过 chat_template_kwargs 传入自定义值: json { "messages": , "chat_template_kwargs": { "enable_thinking": true, "auto_think_short_threshold": 50, "auto_think_force_threshold": 500 } } 设为 {"enable_thinking": false} 可以完全关闭自动判断。 第三层:消息内嵌标签(最灵活,实时切换) 在 system prompt 或 user 消息中插入标签: <|think_off|> → 强行关闭思考(当前消息及后续) <|think_on|> → 强行开启思考 标签在渲染时自动移除,模型看不到。 实际效果流程: 用户问"你好" (2字) → 2 ≤ 30 → enable_thinking=false → 模板输出: \n\n (空思考块) → 模型跳过思考,直接回答 用户问"请详细解释Transformer架构中多头注意力的数学原理..." (长文) → 字数 ≥ 300 → enable_thinking=true → 模板输出: \n → 模型进入深度推理模式 当前你的启动命令里 --reasoning auto --reasoning-format deepseek 配合这个模板,llama-server 会自动解析 thinking 块分离显示。不需要改命令行参数,阈值调整通过 API 调用时的 chat_template_kwargs 传就行。最后让hermes来个总结吧(忽略我懒得改的模型名称):


-
我用vllm 双卡没有NVLINK
Prefill 4K 重复测量 (5 次)
run prompt_tokens ttft tok/s 1 3 836 2 776 ms 1 382 2 3 836 2 735 ms 1 403 3 3 834 2 665 ms 1 439 4 3 833 2 770 ms 1 384 5 3 838 2 772 ms 1 384 Decode 单流 重复测量 (4 次)
run prompt_tokens completion_tokens ttft decode tok/s 1 76 220 256 ms 66.2 2 79 220 278 ms 66.6 3 81 220 284 ms 66.7 4 80 220 284 ms 66.7 -
@c0aster 感谢分享,已经按照ik-llama实施,实测Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-Q4_K_M.gguf达到69t/s,已经能够满足生产力需求了
-
T terry 于 取消固定此主题
-
@c0aster https://github.com/ikawrakow/ik_llama.cpp 从这个项目自己编译的ik_llama,启动参数如下:
start "ik_llama - heretic-v2 27B" "%EXE%" ^
-m "J:\llama-b9370-bin-win-cuda-12.4-x64\models\1\Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-Q4_K_M.gguf" ^
--mmproj "J:\llama-b9370-bin-win-cuda-12.4-x64\models\1\Qwen3.6-27B-mmproj-BF16.gguf" ^
-ngl 99 -c 131072 --threads 12 --no-mmap ^
--flash-attn on ^
--cache-type-k q4_0 --cache-type-v q4_0 ^
--batch-size 512 --ubatch-size 256 ^
--merge-qkv --merge-up-gate-experts ^
--cache-ram 32768 ^
--spec-type mtp:n_max=4,p_min=0.0 ^
--jinja --chat-template-file "%TEMPLATE%" ^
--timeout 3600 --host 0.0.0.0 --port 8080 -
今天准备使用的参数如下:
#top-p 0.95 则尾部应该--min-p 0.01 将尾部噪音切除,否则可能造成循环! # 只开n-max 为2的话,长上下文稳定性应该好, k精度取q8_0获得较高的注意力精度 # 预留1024M空间,防止腾挪时发生显存爆炸 #bofan Qwopus3.6-27B-Coder-MTP-IQ4_XS killall llama-server 2>/dev/null; sleep 3 cd /data/model2/bofan-llama.cpp/build/bin CUDA_SCALE_LAUNCH_QUEUES=4x \ ./llama-server \ -m /data/model2/Qwopus3.6-27B-Coder-MTP-IQ4_XS.gguf \ -c 132000 \ -ngl 9999 \ -fa on --metrics --fit-target 1024 \ -ctk q8_0 -ctv turbo4 \ --spec-type mtp \ --spec-draft-n-min 2 \ --spec-draft-n-max 3 \ --jinja \ --chat-template-file /data/model2/chat_template-fixed-v20.jinja \ --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0.01 \ --mlock -np 1 \ -b 1024 -ub 1024 \ --host 0.0.0.0 --port 8025 \ --reasoning auto \ --reasoning-format deepseek --reasoning-budget 4096较复杂的俄罗斯方块多步生成 ,要10分钟左右,这个模型和参数似乎拥有并行修改错误代码的能力
生成 俄罗斯方块之后,再在WEB UI测试 半开放式问题。内容质量及速度都比较均衡:(平衡75T/S)

这个模型比较适合写程序代码,如果内容创作,建议使用qwen 3.6 27B V2 MTP原版
