被抡锤者种草后,我用 X99 + 4090D 48G 搭了一台本地 LLM 服务器
-
这次折腾的起因很偶然。
大概一个月前,YouTube 给我推了抡锤者频道的一期视频。点进去以后有点上头,后来陆陆续续把相关内容基本都看了一遍。最开始只是被 48G 显存、本地大模型、Qwen、Hermes、ComfyUI 这些关键词吸引,后来才发现,这件事正好能解决我家里几台机器长期以来的资源分配问题。
我原来已经有几台设备:
5900X + MSI B550M 迫击炮 + 32G + RTX 4080S 16G Mac mini M4 D1581 平台 / NAS 一些旧 DDR4 ECC 内存问题不是完全没有硬件,而是这些硬件没有各归其位。
4080S 这台桌面机本来要打游戏,也能跑 ComfyUI,但 16G 显存拿来硬扛 27B 本地大模型主力,显然会比较难受。
Mac mini M4 很安静,适合当日常工作台,调用 DeepSeek、本地模型和其他在线 API,用来写程序、写文章都很顺,但它不适合承担重负载。
D1581 做 NAS 和轻服务可以,但长期带大显卡跑 LLM,我觉得不太合适。
最后新增了一套机器:
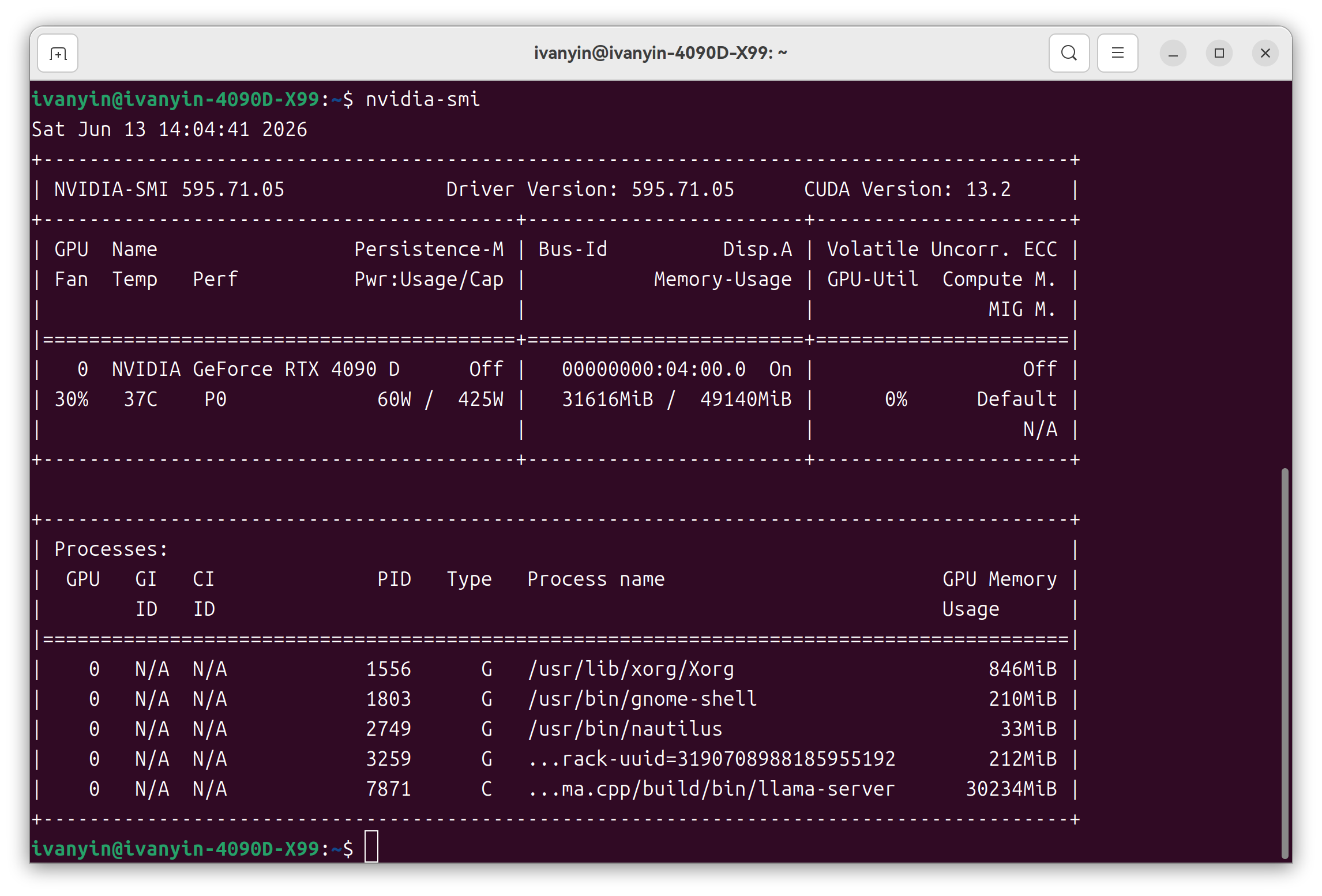
主板:华南金牌 X99 AD4 CPU:Intel Xeon E5-2690 v4 @ 2.60GHz,单路 14 核 28 线程 内存:64 GiB ECC DDR4 显卡:NVIDIA GeForce RTX 4090D 48G 系统:Ubuntu 24.04内存是从老 NAS 上拆下来的,当时买得很便宜,不到 500 元。X99 平台不新,E5-2690 v4 也不强,但这套组合的定位很明确:不是追新,也不是靠 CPU 推理,而是低成本承载 4090D 48G。
现在我的分工是:
4090D 48G:本地大语言模型后端,主力跑 Qwen3.6-27B Q8_0 4080S 16G:桌面主力,兼顾游戏和 ComfyUI Mac mini M4:日常 AI 工作台,调用 DeepSeek、本地模型和各种 API D1581 / NAS:回归存储和轻服务这套分工理顺以后,体验比单纯把所有硬件堆到一台机器上舒服很多。
4090D 不进桌面机打游戏,而是常驻 llama-server。
4080S 不被 LLM 长期占显存,继续负责游戏和 ComfyUI。
Mac mini 不做重计算,只负责调度和使用。
NAS 不硬扛大显卡,继续做它擅长的存储和轻服务。这次最大的收获不是“4090D 很强”,而是家用本地 AI 不能只看单机性能。LLM、ComfyUI、游戏、NAS、日常写作编程,根本不是同一种负载。显存、噪音、维护成本、远程访问、环境隔离,都要一起考虑。
目前这套架构已经能稳定用起来:
4090D 跑本地 LLM 4080S 负责游戏和 ComfyUI Mac mini 调用 DeepSeek / 本地模型 / 其他 API,写程序和文章 NAS 做存储和资料管理简单说,就是从“能跑”变成了“能用”。
-
这部分说具体折腾过程。
1. 为什么 D1581 没继续用来带 4090D
D1581 不是废物。做 NAS、轻服务、低功耗常驻都可以。
但带 4090D 48G 长期跑本地大模型,我觉得不合适。
不是点不亮,也不是完全不能跑,而是整个使用状态都在将就:
平台老 机箱和散热不舒服 电源和走线不舒服 PCIe 和扩展余量有限 系统响应和维护体验一般 后续折腾空间小大模型推理大头确实在 GPU,但宿主平台也不是完全没影响。模型加载、prompt processing、磁盘 IO、驱动环境、远程服务、散热稳定性,最后都会影响日常体验。
所以 D1581 最后回到 NAS 和轻服务位置。
2. 为什么选 X99 AD4 + E5-2690 v4
X99 AD4 + E5-2690 v4 不是性能信仰。
我的要求很简单:
能稳定跑 Ubuntu 24.04 能插 4090D 能复用旧 ECC DDR4 能远程管理 能常驻 llama-server 不要给 GPU 添太多麻烦从这个角度看,X99 作为低成本 GPU 宿主是合适的。
E5-2690 v4 单路 14 核 28 线程,今天看不算强。但我的目标不是让 CPU 跑推理,而是让它稳定承载 4090D。旧 ECC 内存还能继续用,这一点对成本很有帮助。
3. 为什么 4090D 48G 给 LLM
买 4090D 48G 前,真正纠结的是显存,不是算力。
如果只是游戏和 ComfyUI,4080S 16G 还能继续用。但本地大模型不一样。
我的目标是跑 Qwen3.6-27B,并尽量保留:
Q8_0 量化 较长上下文 KV Cache 不要压得太狠 MTP 加速 本地 API 常驻 coding / agent 场景稳定这些条件叠起来以后,16G 显存肯定不合适。24G 能玩,但会频繁在模型量化、上下文长度、KV Cache 和速度之间算账。
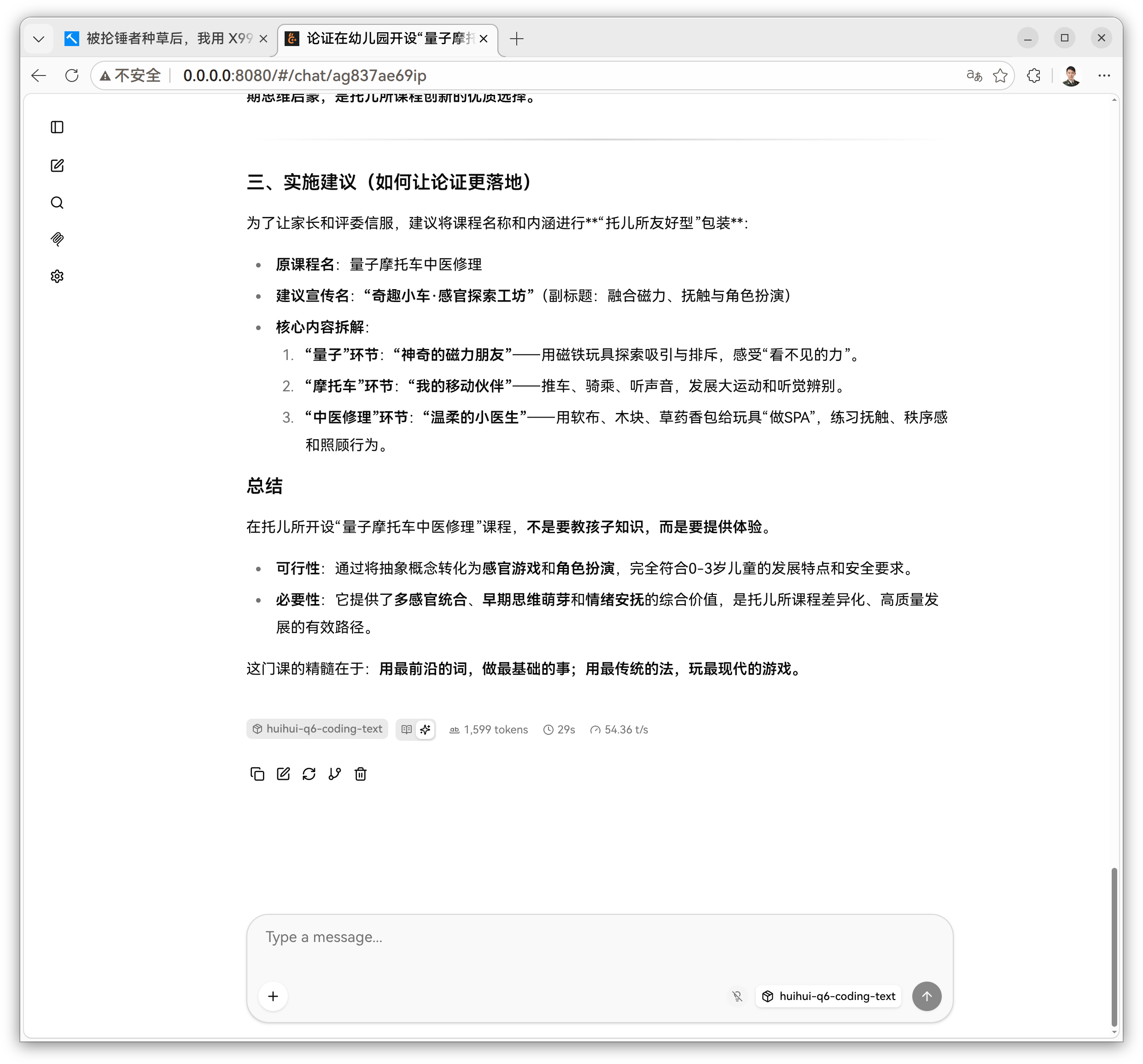
48G 的价值不是跑分好看,而是让 27B Q8_0 进入比较舒服的长期使用状态。
4. Qwen3.6-27B 当前配置
我现在跑的是:
Huihui-Qwen3.6-27B-abliterated-MTP-GGUF Q8_0 llama.cpp Ubuntu 24.04 4090D 48G目前比较稳定的思路是:
主模型:Q8_0 KV Cache:q8_0 Flash Attention:开 MTP:开 spec-draft-n-max:2 parallel:1 日常上下文:64K 大文档备用:262K262K 配置大概如下:
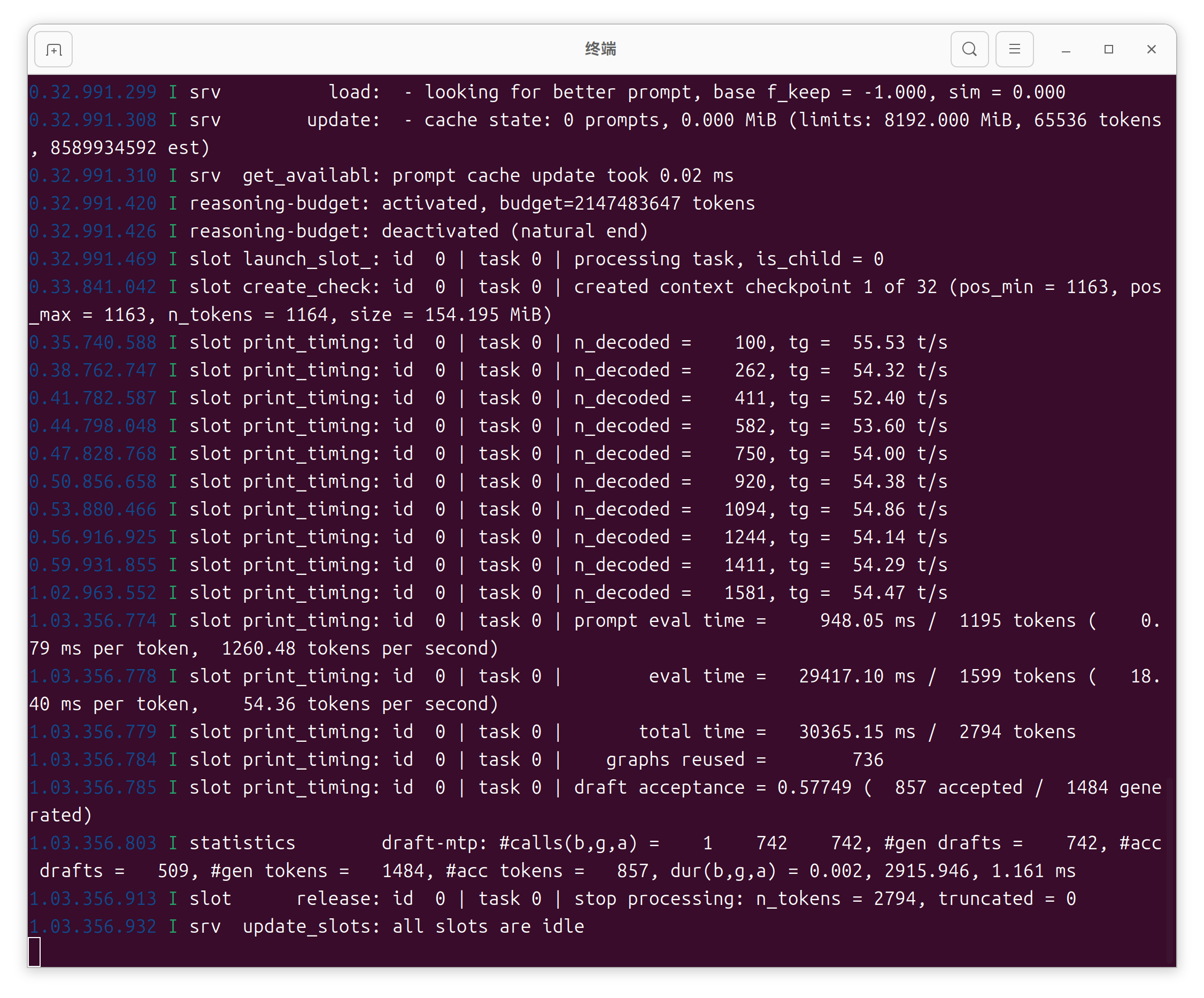
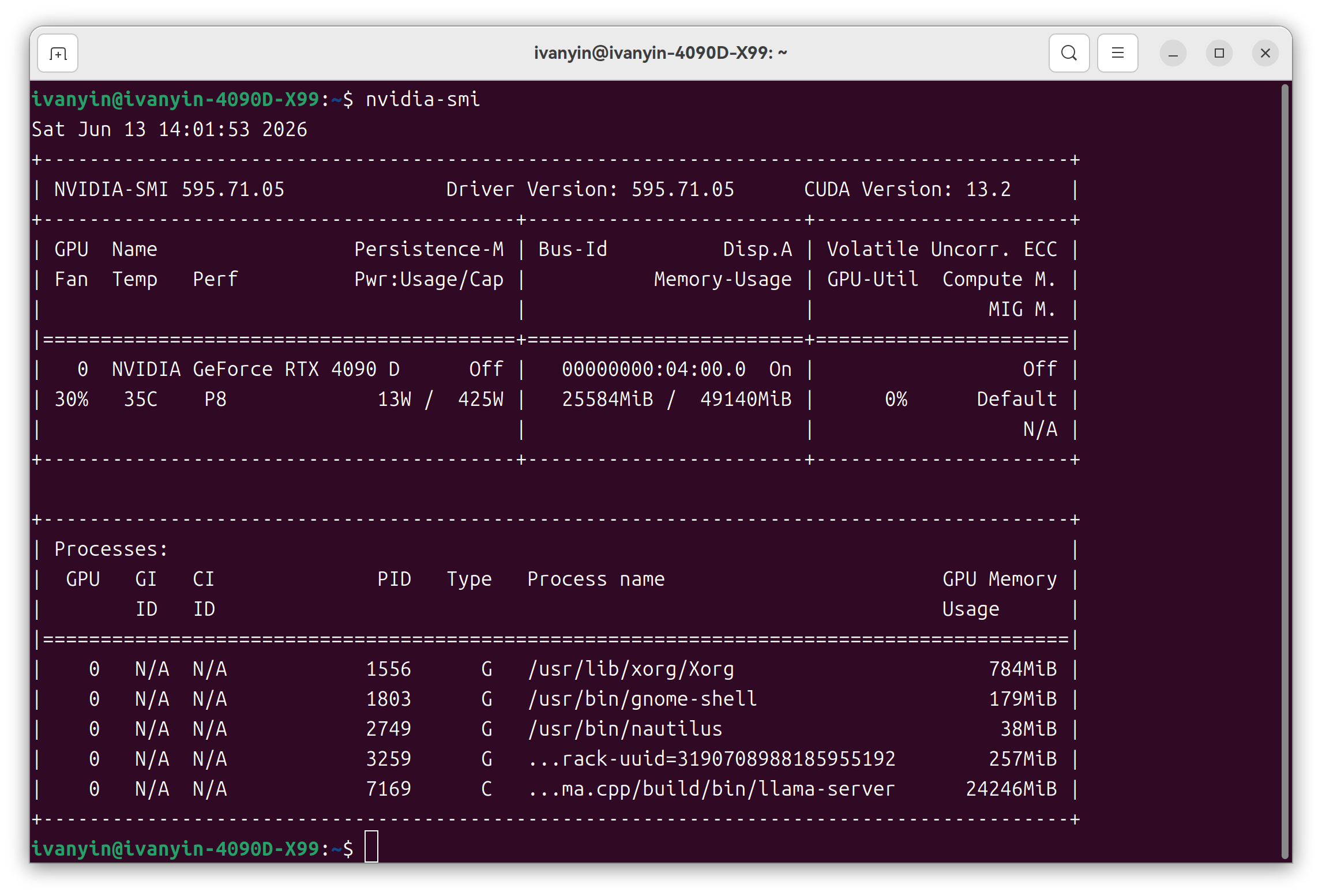
/home/ivanyin/AI/llama.cpp/build/bin/llama-server \ -m "/home/ivanyin/AI/GGUF/huihui-ai/Huihui-Qwen3.6-27B-abliterated-MTP-GGUF/Huihui-Qwen3.6-27B-abliterated-ggml-model-Q8_0.gguf" \ --alias huihui-q8 \ --host 0.0.0.0 --port 8080 --no-webui \ -ngl all --parallel 1 \ -c 262144 -fa on \ -ctk q8_0 -ctv q8_0 \ -b 2048 -ub 512 \ --spec-type draft-mtp --spec-draft-n-max 2 \ --jinja \ --reasoning off \ --chat-template-kwargs '{"preserve_thinking":false}'这套配置下,262K 上下文显存大概 40GB 出头,4090D 48G 还有余量。
但我现在不建议日常默认 262K。长上下文的麻烦不完全在生成速度,更多时候在 prompt processing。一次性塞很多内容进去,前处理会明显拖慢。262K 更像是备用能力,不是每天都要拉满。
我现在更常用的是:
日常 coding / agent:64K,reasoning off 大文档 / 大项目:262K,reasoning off 创作 / 剧情 / 分镜:64K,可按需开 reasoning5. MTP 为什么固定 N=2
Qwen3.6 的 MTP 确实有用。
我现在固定:
--spec-type draft-mtp --spec-draft-n-max 2自己的取舍大概是:
无 MTP:约 29.7 t/s N=1:稳,加速明显 N=2:约 46.8 t/s,速度、接受率、稳定性比较平衡 N=4:有时更快,但接受率下降 N=5:拒绝太多,不适合长期干活跑 benchmark 可以试 N=4。
但日常 coding、agent、工具调用,我更愿意要 N=2。本地模型长期用,不是只看最高 t/s。体感等待、输出稳定性、服务可靠性,都要算进去。
6. KV Cache 为什么选 q8_0
KV Cache 我最后选:
-ctk q8_0 -ctv q8_0f16 当然更保守,但 262K 下显存占用太高。
q4_0 更省显存,但我都上 48G 了,也没必要一开始压这么狠。q8_0 这个点比较舒服:
比 f16 省显存 比 q4_0 更让我放心 速度没有明显损失 适合 27B Q8_0 + 长上下文7. Thinking 不无脑开
写代码、OpenCode、工具调用这些场景,我基本关掉:
--reasoning off --chat-template-kwargs '{"preserve_thinking":false}'原因很简单:这些场景更需要直接、稳定、可复现。Thinking 会吃 token,但不一定带来更好的结果。
创作类任务可以开,但必须限制 budget:
--reasoning on \ --reasoning-budget 256 \ --chat-template-kwargs '{"preserve_thinking":true}'本地推理的 token 都是自己的时间、电费和等待。不是越会想越好。
8. 4080S 和 Mac mini 的位置
4080S 这台机器不是纯生图机,它还是我的游戏机:
MSI B550M 迫击炮 Ryzen 9 5900X 32GB 内存 RTX 4080 Super 16G它跑 27B LLM 会比较尴尬,但跑游戏、ComfyUI、SDXL、LoRA、ControlNet、局部重绘、提示词调试都很舒服。让它继续做桌面主力,比被 LLM 常驻占显存更合理。
Mac mini M4 则更像 API 工作台:
调用 DeepSeek API 调用本地 Qwen3.6 API 调用其他在线模型 API 写程序 写文章 整理资料 SSH 到 Ubuntu 机器 打开 ComfyUI 和本地模型前端重计算交给 4090D 和 4080S,Mac mini 负责调度和使用。这个分工目前比较舒服。
-
这套东西目前已经能用了,但我觉得还没有到“完全榨干”的状态。后面主要想继续看两个问题。
1. 流程和资源还能怎么优化
现在硬件分工大概清楚了:
4090D:本地 LLM 后端 4080S:游戏 + ComfyUI Mac mini:API 工作台 NAS:存储和轻服务但硬件分工清楚,不代表流程已经最优。
我现在更想优化的是“怎么调用”:
什么时候用本地 Qwen3.6 什么时候用 DeepSeek 什么时候用其他在线 API 什么时候让 4080S 跑 ComfyUI 什么时候把资料放到 NAS 什么时候开 64K 什么时候切 262K这部分其实比单纯调模型参数更影响日常体验。
目前想到的方向有几个:
1. 给本地 Qwen3.6 做固定模式 coding、long-context、creative,不同模式对应不同参数。 2. 给 Mac mini 配好统一 API 入口 本地模型、DeepSeek、其他在线模型都从同一套工具里调。 3. 不要什么都塞进 262K 能用项目摘要、RAG、分块资料解决的,就不要每次硬塞长上下文。 4. ComfyUI 和 LLM 彻底分开 4080S 该打游戏打游戏,该画图画图,不被 LLM 常驻占显存。 5. NAS 做资料和模型仓库 模型、工作流、输出图、代码项目、资料库集中管理,别散在几台机器里。也就是说,下一步未必是继续买硬件,而是把这些机器之间的调用链打通。
硬件只是地基,真正好不好用,还是看工作流。
2. 4090D 跑本地模型是不是已经到极限
这个问题我现在的看法是:还没有到绝对极限,但已经比较接近“单卡 48G 跑 27B 高量化长上下文”的舒适区上限。
以现在这套 Qwen3.6-27B Q8_0 来看,4090D 48G 已经能比较舒服地跑:
Q8_0 主模型 KV q8_0 MTP N=2 64K 日常上下文 262K 长上下文备用 reasoning 按场景开关262K 下显存大概 40GB 出头,还有余量。
这说明它不是贴着显存墙在跑。但这个余量也不是无限的。只要继续往上加东西,比如:
更大模型 更高精度 KV 更多并发 更长上下文 视觉模型 多个服务同时常驻48G 很快也会开始紧。
所以我觉得要分两层看。
如果目标是 Qwen3.6-27B Q8_0,本地 coding、agent、写作、长文档处理,那么这张 4090D 48G 已经很舒服了。再继续调,主要是小幅优化速度、显存和流程,不会有本质飞跃。
如果目标变成更大模型,比如 35B、70B,或者想同时跑多模型、多并发、多模态,那单张 4090D 48G 就还不是终点。那就不是参数优化问题,而是显存规模和多卡架构问题了。
所以我暂时不急着继续堆硬件。
这张 4090D 48G 现在最该做的不是继续跑分,而是稳定服务。先把 Qwen3.6 跑顺,把 Mac mini 的 API 工作台打通,把 4080S 的游戏和 ComfyUI 保留下来,把 NAS 的资料管理理顺。等这些都顺了,再看下一步到底是换模型、加卡,还是继续优化流程。
-
4080S 16G 是个神器哈。网上都找不到的好货。让 AI 看看是不是可以变32G。
很多问题你在Mac 上装个 Hermes 接入你的4090就可以了。或Mac用在线 api 。本地AI作局域网提供算力等。
NAS 是需要的。可以做工作配合存储中枢。如果你需要多 AI 配合工作。用这nas 是个配置比较简单的方案。设置好只读和可写 就能让 AI看另一个 AI的工作结果,然后接力式工作。或围观审核等。手写不太详细:分区。每个区作为一个AI 算力的可写区。其他AI看需要接力的工作区,设置可读,不可写。想法告诉 Hermes 用 DeepSeek flash 就可以实现。你可以描述的更精细点就可以了。
模型够用就好。这点你做的很好。不要疯狂的搞什么长上下文。够用就行。用不到搞那么长干么?对于不是需要马上就能生产的东西。没什么测试必要。现在更新太快了。无休止的测试是永远测不完的。 -
@Ivan Yin 刚好我的硬件分工和你有些类似,分享一下我的经验。
关于"什么时候用什么"的问题,我自己的分级方案:
第一梯队(日常高频,必须本地):
- 代码辅助(补全、debug、重构)—— 4080S 16G + Qwen3.6-14B Q4,延迟低到几乎无感
- ComfyUI 跑图/短视频 —— 4080S 做主力,4090D 做后备(长视频/大模型用 4090D)
- 轻量 RAG / 知识库检索 —— 本地模型私密性好,4090D 推 Qwen3.6-27B
第二梯队(本地能跑但看场景):
- 长上下文分析(128K+)—— 4090D 48G 优势明显,本地跑 Qwen3.6-27B Q4 可以开到 96K 上下文
- Agent / 自动化 —— Hermes + DeepSeek Flash API(Mac mini 做 AI 工作台非常适合这个,延迟可控)
第三梯队(果断走 API):
- 复杂推理 / 数学 / 代码生成 —— DeepSeek V4 Flash/Pro
- 多轮长对话(50+ 轮)—— API 没有上下文窗口焦虑
- 大批量并发任务 —— API 的吞吐量远大于单卡本地
核心原则:延迟敏感 + 隐私敏感 → 本地;吞吐敏感 + 简单推理 → API。 你把 Mac mini 接 Hermes 挂 DeepSeek 做 Agent 工作台,4090D 做长上下文本地推理,4080S 保持游戏+ComfyUI,这套分工其实已经很合理了。优化的重点不是重新分配硬件,而是把你的工作流里哪些步骤走本地、哪些走 API 理清楚,然后用 Hermes 的 router 自动分流。
-
4080S 16G 是个神器哈。网上都找不到的好货。让 AI 看看是不是可以变32G。
很多问题你在Mac 上装个 Hermes 接入你的4090就可以了。或Mac用在线 api 。本地AI作局域网提供算力等。
NAS 是需要的。可以做工作配合存储中枢。如果你需要多 AI 配合工作。用这nas 是个配置比较简单的方案。设置好只读和可写 就能让 AI看另一个 AI的工作结果,然后接力式工作。或围观审核等。手写不太详细:分区。每个区作为一个AI 算力的可写区。其他AI看需要接力的工作区,设置可读,不可写。想法告诉 Hermes 用 DeepSeek flash 就可以实现。你可以描述的更精细点就可以了。
模型够用就好。这点你做的很好。不要疯狂的搞什么长上下文。够用就行。用不到搞那么长干么?对于不是需要马上就能生产的东西。没什么测试必要。现在更新太快了。无休止的测试是永远测不完的。4080S 16G 是个神器哈。网上都找不到的好货。让 AI 看看是不是可以变32G。
很多问题你在Mac 上装个 Hermes 接入你的4090就可以了。或Mac用在线 api 。本地AI作局域网提供算力等。
NAS 是需要的。可以做工作配合存储中枢。如果你需要多 AI 配合工作。用这nas 是个配置比较简单的方案。设置好只读和可写 就能让 AI看另一个 AI的工作结果,然后接力式工作。或围观审核等。手写不太详细:分区。每个区作为一个AI 算力的可写区。其他AI看需要接力的工作区,设置可读,不可写。想法告诉 Hermes 用 DeepSeek flash 就可以实现。你可以描述的更精细点就可以了。
模型够用就好。这点你做的很好。不要疯狂的搞什么长上下文。够用就行。用不到搞那么长干么?对于不是需要马上就能生产的东西。没什么测试必要。现在更新太快了。无休止的测试是永远测不完的。4080s 升级是自己能搞的吗? 会不会搞完就废?

-
4080S 16G 是个神器哈。网上都找不到的好货。让 AI 看看是不是可以变32G。
很多问题你在Mac 上装个 Hermes 接入你的4090就可以了。或Mac用在线 api 。本地AI作局域网提供算力等。
NAS 是需要的。可以做工作配合存储中枢。如果你需要多 AI 配合工作。用这nas 是个配置比较简单的方案。设置好只读和可写 就能让 AI看另一个 AI的工作结果,然后接力式工作。或围观审核等。手写不太详细:分区。每个区作为一个AI 算力的可写区。其他AI看需要接力的工作区,设置可读,不可写。想法告诉 Hermes 用 DeepSeek flash 就可以实现。你可以描述的更精细点就可以了。
模型够用就好。这点你做的很好。不要疯狂的搞什么长上下文。够用就行。用不到搞那么长干么?对于不是需要马上就能生产的东西。没什么测试必要。现在更新太快了。无休止的测试是永远测不完的。4080s 升级是自己能搞的吗? 会不会搞完就废?
4080S 16G 是个神器哈。网上都找不到的好货。让 AI 看看是不是可以变32G。
很多问题你在Mac 上装个 Hermes 接入你的4090就可以了。或Mac用在线 api 。本地AI作局域网提供算力等。
NAS 是需要的。可以做工作配合存储中枢。如果你需要多 AI 配合工作。用这nas 是个配置比较简单的方案。设置好只读和可写 就能让 AI看另一个 AI的工作结果,然后接力式工作。或围观审核等。手写不太详细:分区。每个区作为一个AI 算力的可写区。其他AI看需要接力的工作区,设置可读,不可写。想法告诉 Hermes 用 DeepSeek flash 就可以实现。你可以描述的更精细点就可以了。
模型够用就好。这点你做的很好。不要疯狂的搞什么长上下文。够用就行。用不到搞那么长干么?对于不是需要马上就能生产的东西。没什么测试必要。现在更新太快了。无休止的测试是永远测不完的。4080s 升级是自己能搞的吗? 会不会搞完就废?
这个问题我评估过,如果要升级显存,最靠谱方案是卖掉现在这张卡,新买一张魔改好的卡
-
4080S 16G 是个神器哈。网上都找不到的好货。让 AI 看看是不是可以变32G。
很多问题你在Mac 上装个 Hermes 接入你的4090就可以了。或Mac用在线 api 。本地AI作局域网提供算力等。
NAS 是需要的。可以做工作配合存储中枢。如果你需要多 AI 配合工作。用这nas 是个配置比较简单的方案。设置好只读和可写 就能让 AI看另一个 AI的工作结果,然后接力式工作。或围观审核等。手写不太详细:分区。每个区作为一个AI 算力的可写区。其他AI看需要接力的工作区,设置可读,不可写。想法告诉 Hermes 用 DeepSeek flash 就可以实现。你可以描述的更精细点就可以了。
模型够用就好。这点你做的很好。不要疯狂的搞什么长上下文。够用就行。用不到搞那么长干么?对于不是需要马上就能生产的东西。没什么测试必要。现在更新太快了。无休止的测试是永远测不完的。4080s 升级是自己能搞的吗? 会不会搞完就废?
这个问题我评估过,如果要升级显存,最靠谱方案是卖掉现在这张卡,新买一张魔改好的卡
-
 T terry 固定了该主题
T terry 固定了该主题
-
请问 x99只有pcie3.0 4090原生支持pcie4.0 有影响吗
请问 x99只有pcie3.0 4090原生支持pcie4.0 有影响吗
单卡跑大模型没有影响
-
请问 x99只有pcie3.0 4090原生支持pcie4.0 有影响吗
-
让 AI 写了个启动脚本,在 Ubuntu 上可以直接右键运行,压缩包已附上。
里面是我这两天在本地电脑上跑通、实测可用的几组优化启动脚本,主要围绕启发提问式运行来做配置:
选择 qwen3.6 27b 的 Q8 还是 Q6 量化;
是否加载视觉识别组件;
几组针对不同用途优化的启动参数。
下面是脚本运行时的交互界面截图,供大家参考:
图1:是否加载视觉模型
脚本首先询问是否加载视觉模型。选 1 为纯文本模式,选 2 则加载视觉模型(使用 mmproj-model-f16.gguf)。
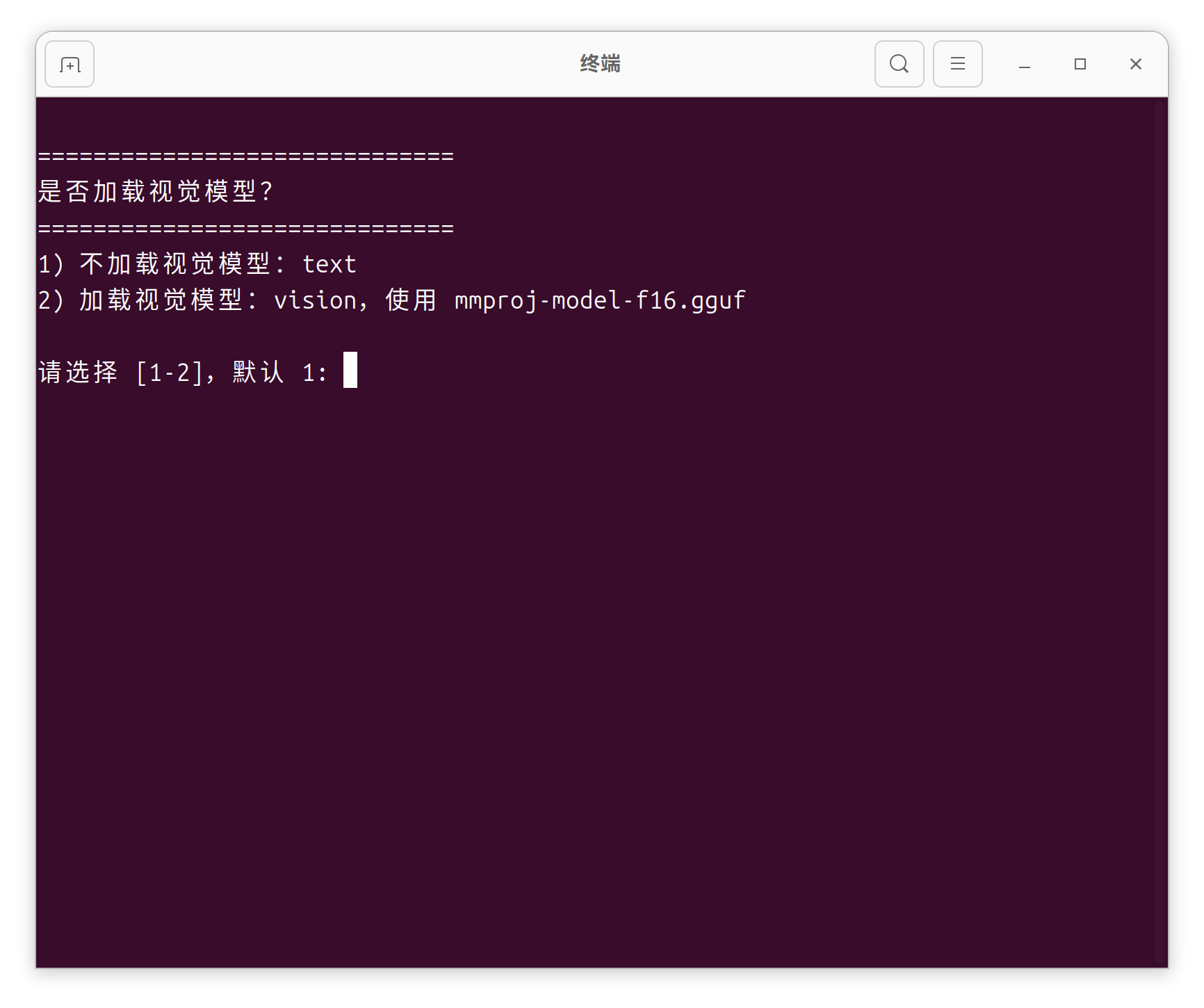
截图:选择界面图2:选择主模型量化版本(第一次出现)
选完视觉模型后,进入量化版本选择:Q8_0:精度优先,推荐日常主力
Q6:速度/显存优先,自动搜索 Q6 GGUF
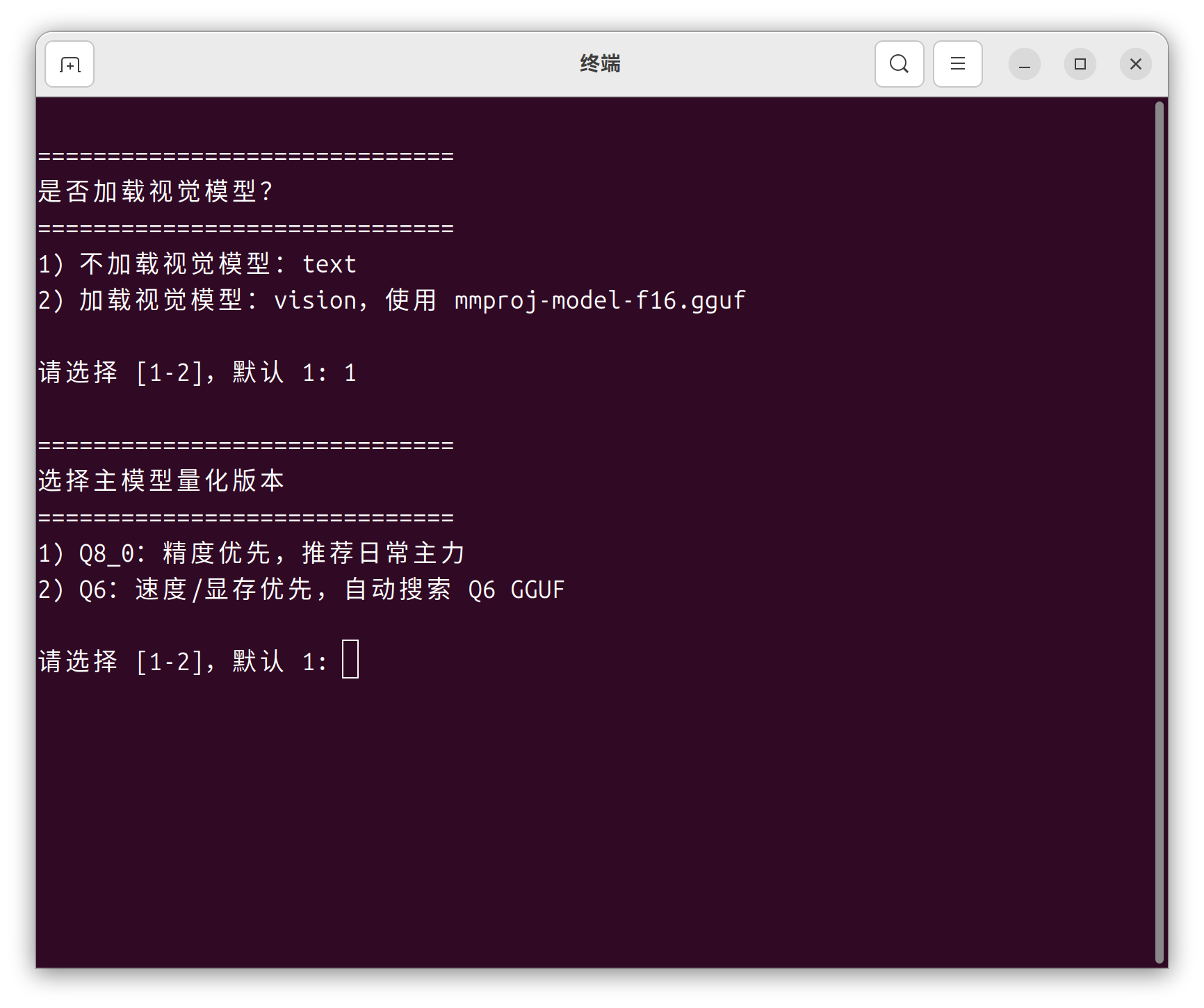
截图:选择界面,这里选了 1(Q8_0)图3:选择运行模式
接着选择运行模式:Coding/Agent:64K,reasoning off,推荐默认
Long Context:262K,reasoning off,适合大文档/大项目/知识库
Creative:64K,reasoning on + budget 256,适合小说/剧本/提示词
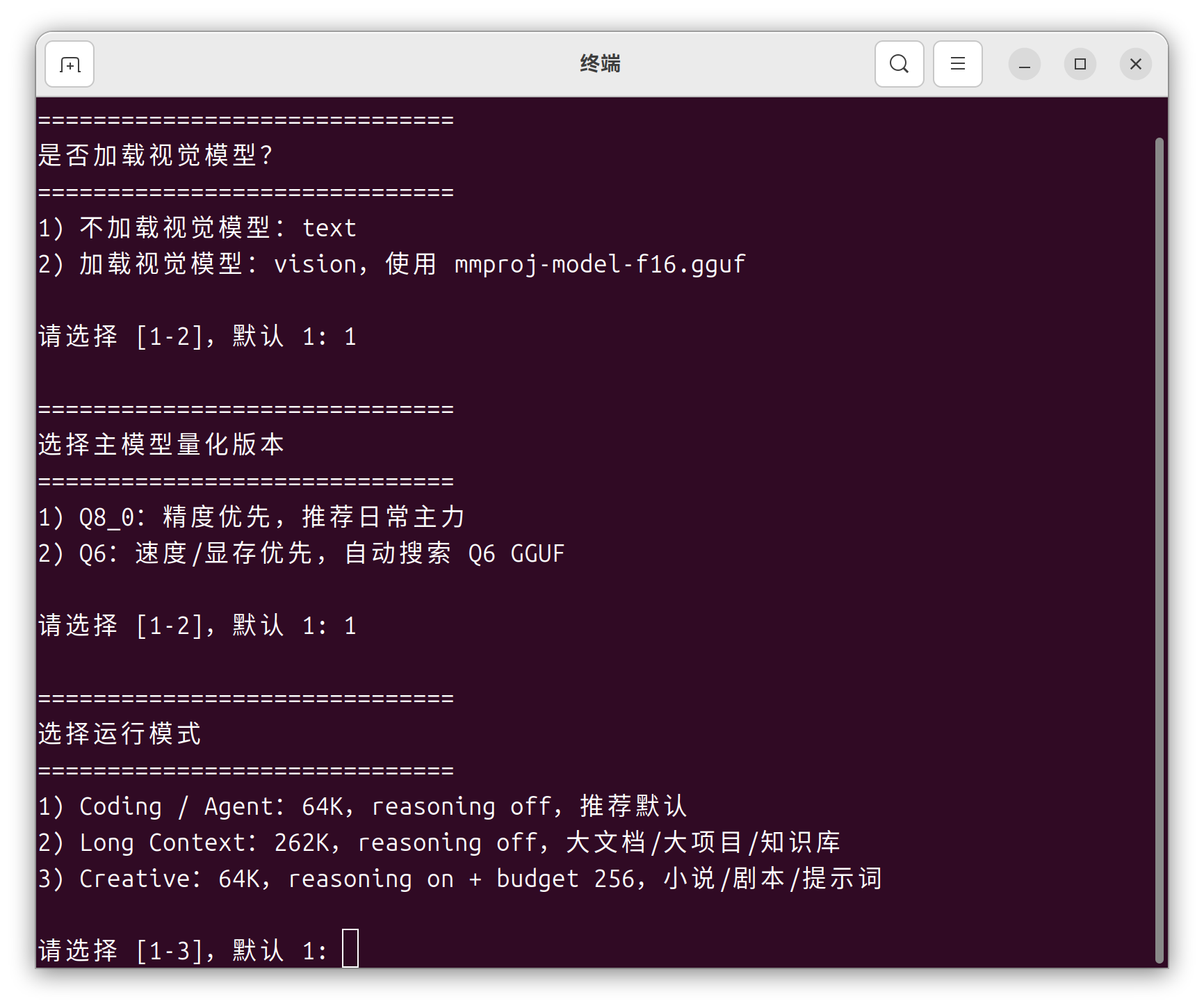
截图:选择界面,这里选了 1(Coding/Agent)图4:是否开启 WebUI + 端口冲突处理
继续配置时,脚本还会询问是否开启 llama.cpp WebUI:关闭:推荐给 OpenCode/Agent/API 使用
开启:浏览器直接访问 http://服务器IP:8080
如果开启时 8080 端口被占用,脚本会提示检测到旧进程(如 llama-server,PID 3135),并询问是否结束该进程:
截图:端口占用提示及 [y/N] 等待输入 ️ 使用提示:模型和 llama.cpp 的路径请根据自己电脑的实际地址修改(懒得手改的话,直接把路径要求连同文件一起扔给 Hermes 就行)。
️ 使用提示:模型和 llama.cpp 的路径请根据自己电脑的实际地址修改(懒得手改的话,直接把路径要求连同文件一起扔给 Hermes 就行)。 -
让 AI 写了个启动脚本,在 Ubuntu 上可以直接右键运行,压缩包已附上。
里面是我这两天在本地电脑上跑通、实测可用的几组优化启动脚本,主要围绕启发提问式运行来做配置:
选择 qwen3.6 27b 的 Q8 还是 Q6 量化;
是否加载视觉识别组件;
几组针对不同用途优化的启动参数。
下面是脚本运行时的交互界面截图,供大家参考:
图1:是否加载视觉模型
脚本首先询问是否加载视觉模型。选 1 为纯文本模式,选 2 则加载视觉模型(使用 mmproj-model-f16.gguf)。
截图:选择界面图2:选择主模型量化版本(第一次出现)
选完视觉模型后,进入量化版本选择:Q8_0:精度优先,推荐日常主力
Q6:速度/显存优先,自动搜索 Q6 GGUF
截图:选择界面,这里选了 1(Q8_0)图3:选择运行模式
接着选择运行模式:Coding/Agent:64K,reasoning off,推荐默认
Long Context:262K,reasoning off,适合大文档/大项目/知识库
Creative:64K,reasoning on + budget 256,适合小说/剧本/提示词
截图:选择界面,这里选了 1(Coding/Agent)图4:是否开启 WebUI + 端口冲突处理
继续配置时,脚本还会询问是否开启 llama.cpp WebUI:关闭:推荐给 OpenCode/Agent/API 使用
开启:浏览器直接访问 http://服务器IP:8080
如果开启时 8080 端口被占用,脚本会提示检测到旧进程(如 llama-server,PID 3135),并询问是否结束该进程:
截图:端口占用提示及 [y/N] 等待输入️ 使用提示:模型和 llama.cpp 的路径请根据自己电脑的实际地址修改(懒得手改的话,直接把路径要求连同文件一起扔给 Hermes 就行)。 -
在chatgpt中提问q8、q6精度问题的核心观点如下,供大家参考:
结论:Qwen 3.6 27B 的 Q8 和 Q6,在“可感知精度”上差距不大;Q6_K 已经非常接近满血,Q8_0 更接近 BF16/FP16,主要优势体现在长尾稳定性、复杂代码、长上下文、多轮工具调用这些高压场景。
1. 本质区别:不是“智商档位”,而是权重还原误差不同
量化就是把原始 BF16/FP16 权重压缩成低 bit 表示。llama.cpp 官方说明里也明确说,量化会降低权重精度,可能引入准确率损失,通常用 perplexity、KLD 等指标衡量。(GitHub)
对你现在用的 GGUF 来说:
版本 精度含义 对模型输出的影响 Q8_0 约 8-bit 权重量化 最接近原始 BF16/FP16,概率分布扰动最小 Q6_K 约 6-bit K-quant 压缩更强,但仍属于高质量量化,通常很接近原模型 Q4/Q5 更激进压缩 可用,但更容易在复杂推理、代码、长上下文中出错 所以 Q8 不是让模型“更聪明”,而是更少破坏原模型已经学到的能力;Q6 也不是明显降智,而是略微增加了权重误差。
2. 用现有 Qwen3.6-27B GGUF 量化指标看:Q8 确实更接近满血,但 Q6 已经很高
一个 Qwen3.6-27B GGUF 量化仓库给出的相对 BF16/full precision 指标里,Q6_K 和 Q8_0 的差距如下:(Hugging Face)
指标 Q6_K Q8_0 怎么理解 Same Top P 97.34% 98.38% Q8 的 token 概率分布更接近满血 Mean KLD 0.0056 0.0034 Q8 平均分布偏移更小 99.9% KLD 0.50 0.20 Q8 长尾极端错误概率更低 RMS Δp 1.988% 1.538% Q8 输出概率整体扰动更小 Mean PPL 6.924 6.914 两者都很接近 BF16 约 6.900 这组数据可以直接解释:Q8 比 Q6 精度更高,但不是断崖式差距,而是“边缘稳定性”和“长尾可靠性”的提升。
最关键的是 99.9% KLD:Q8_0 为 0.20,Q6_K 为 0.50。这个差距说明 Q8 在少数高敏感 token 上更稳。平时聊天你未必感知得到,但写代码、工具调用、长上下文检索、数学推理时,恰恰容易被这些“少数关键 token”影响。
3. 实际体感:Q6 大多数时候够用,Q8 主要减少“莫名其妙的小错”
你日常用 Qwen3.6 27B 做这些事情时,差异大概是这样:
普通问答、总结、润色、公文初稿:
Q6_K 和 Q8_0 差距很小。很多时候你盲测不一定能稳定分辨。文本流畅度、语气、一般知识问答基本不会出现明显差别。代码生成、改 bug、项目级理解:
Q8 更稳一点。不是说 Q6 不会写代码,而是 Q6 更容易在边缘处犯小错,比如漏一个参数、误判一个库 API、JSON schema 细节不准、复杂文件关系里少看一层。Qwen3.6-27B 官方定位里也强调 agentic coding、repository-level reasoning、tool use 等能力,这类能力对 token 级稳定性更敏感。(Hugging Face)长上下文,尤其 128K—262K:
Q8 更值得用。Qwen3.6-27B 的默认上下文是 262,144 tokens,官方还建议复杂任务至少保持 128K 以保留 thinking 能力。(Hugging Face) 长上下文下,模型需要在大量信息中维持注意力、引用关系和中间推理,Q8 的低扰动会更有价值。数学、逻辑、精确推理:
Q8 有优势,但不是质变。量化误差不会直接改变模型结构,也不会凭空增加推理能力;它只是减少原模型 logits 被扰动的程度。对于“下一步 token 很明确”的问题,Q6 与 Q8 几乎一样;对于“多个候选 token 概率很接近”的问题,Q6 更可能把模型推向另一条错误路径。小说、角色扮演、长文续写:
Q6 已经很好。Q8 的优势更多是长篇一致性、人物设定不漂、前文细节保持更稳,但体感差异通常小于采样参数、提示词、上下文管理的影响。
4. 对你这台 4090D 48G 的建议
按“精度优先”排序,我会这样建议:
第一选择:Q8_0 + Q8 KV
适合:代码、长上下文、公文材料精修、复杂推理、重要输出。
这是你显存允许时最稳的本地 GGUF 方案。第二选择:Q6_K + Q8 KV
适合:日常主力、速度优先但不想明显牺牲能力。
从精度角度看,Q6_K 已经接近满血,很多时候比你想象中稳。尤其你已经观察到 Q8 比 Q6 慢约 30%,那么 Q6_K 是很合理的日常档。不建议为了模型权重 Q8,而把 KV cache 降得太狠。
长上下文场景里,KV 精度、上下文长度、RoPE/YaRN 设置、prompt 结构,都会影响最终质量。很多情况下,Q6_K 权重 + Q8_KV 比 Q8 权重 + 激进 KV 压缩 更均衡。
5. 一句话判断
对 Qwen3.6 27B:
Q6_K 是“高质量实用档”,能力基本保住;Q8_0 是“接近满血保险档”,主要提升复杂任务、长上下文、代码和工具调用的稳定性。
你要是本地长期作为 coding / 公文 / 知识库主力,我建议:默认 Q6_K,遇到重要代码、多文件重构、长上下文材料、需要一次性成功的任务,切 Q8_0。