双AI Pro R9700 32g,Qwen 3.6 27b q4 KM q8 KV Ubuntu24 Hermes agent
-
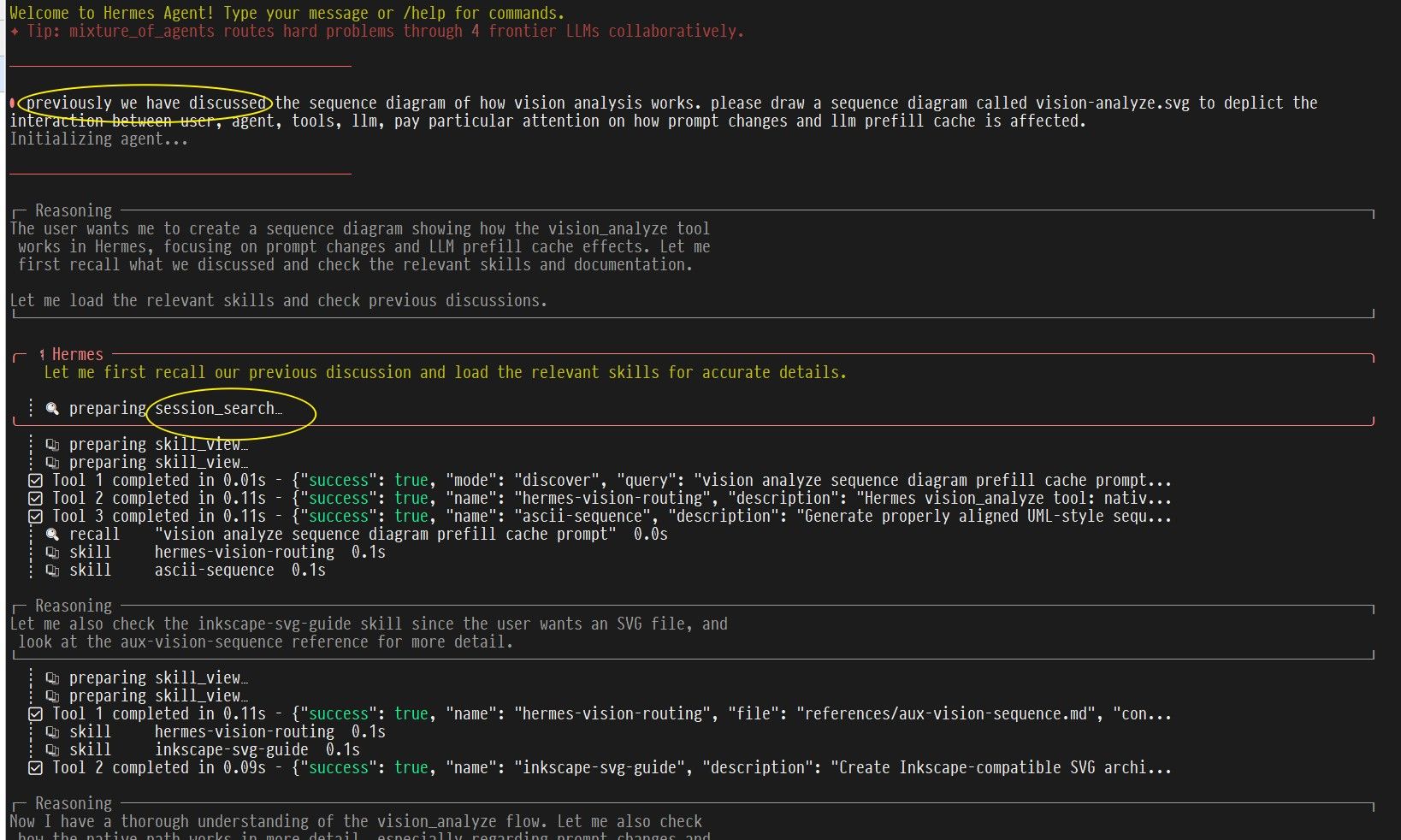
先说下感受,256k上下文,速度是真的慢,但是做研究真是很细。
同时偶然发现在线API虽快,但是比较粗糙,需要驾驭很好才行。
但是本地Qwen3.6,推理能力极强,工具调用,加上联网检索,最终效果挺好。
即使是模型和hermes都设置256k上下文,herems还会触发压缩,最终效果还是很够用的。
折腾了很多,Vllm和sglang搞不定,用了deepseek claude codex都搞不定,不是工具的问题,是我一点都不懂。只会说看看社区有什么成功的方案去尝试(我TM社区是啥都不知道)。
以下是llama cpp参数。问了AI 256k上下文,就是这个速度,不知道有没有好的优化方法。
硬件: 双 AMD Radeon AI Pro R9700(各 32GB VRAM)+ Intel Xeon E5-2686 v4
参数 值 说明 -mQwen3.6-27B-Q4_K_M.gguf标准版模型 -ngl99全部层卸载到 GPU -c262144262K 上下文(医疗文档长文本需要) -np1单并行槽(避免 OOM) --split-modelayer双卡按层切分(tensor 模式在 PCIe 瓶颈下更慢) --cache-type-k/vq8_0KV cache 精度,保持质量 --cache-ram0禁用跨请求 prompt cache(规避 crash) --no-cache-prompt— 禁用 prompt cache --mlock— 锁内存防 swap --defrag-thold0.1KV cache 碎片整理阈值 --reasoning off— 关闭 thinking 模式 -fa on— Flash Attention 性能基准
指标 数值 llama.cpp 版本 b9586 Decode 速度 ~24 tok/s(MTP版);~24 tok/s(标准版) Prefill 速度 ~562 tok/s(MTP版);~21 tok/s(标准版,短 prompt) tensor split 测试 19.4 tok/s(PCIe 瓶颈,不如 layer) -
先说下感受,256k上下文,速度是真的慢,但是做研究真是很细。
同时偶然发现在线API虽快,但是比较粗糙,需要驾驭很好才行。
但是本地Qwen3.6,推理能力极强,工具调用,加上联网检索,最终效果挺好。
即使是模型和hermes都设置256k上下文,herems还会触发压缩,最终效果还是很够用的。
折腾了很多,Vllm和sglang搞不定,用了deepseek claude codex都搞不定,不是工具的问题,是我一点都不懂。只会说看看社区有什么成功的方案去尝试(我TM社区是啥都不知道)。
以下是llama cpp参数。问了AI 256k上下文,就是这个速度,不知道有没有好的优化方法。
硬件: 双 AMD Radeon AI Pro R9700(各 32GB VRAM)+ Intel Xeon E5-2686 v4
参数 值 说明 -mQwen3.6-27B-Q4_K_M.gguf标准版模型 -ngl99全部层卸载到 GPU -c262144262K 上下文(医疗文档长文本需要) -np1单并行槽(避免 OOM) --split-modelayer双卡按层切分(tensor 模式在 PCIe 瓶颈下更慢) --cache-type-k/vq8_0KV cache 精度,保持质量 --cache-ram0禁用跨请求 prompt cache(规避 crash) --no-cache-prompt— 禁用 prompt cache --mlock— 锁内存防 swap --defrag-thold0.1KV cache 碎片整理阈值 --reasoning off— 关闭 thinking 模式 -fa on— Flash Attention 性能基准
指标 数值 llama.cpp 版本 b9586 Decode 速度 ~24 tok/s(MTP版);~24 tok/s(标准版) Prefill 速度 ~562 tok/s(MTP版);~21 tok/s(标准版,短 prompt) tensor split 测试 19.4 tok/s(PCIe 瓶颈,不如 layer) -
 T terry 固定了该主题
T terry 固定了该主题
-
@Brian 关于256K上下文的优化,我补充几点经验:
-
KV cache量化是关键 — 27B Q4_K_M本身的模型权重约15GB(双R9700 32G刚好放下),但256K上下文的KV cache会吃掉大量显存。你可以在llama.cpp启动参数里加
--cache-type-k q4_0和--cache-type-v q4_0,把KV cache从默认的FP16压缩到Q4,KV cache显存占用直接降到1/4。配合--no-kv-offload把KV cache放到系统内存,模型权重独占显存,速度损失没有想象中那么大。 -
双卡配置确认 — R9700实际就是W7900的变体,建议确认
--tensor-split参数是否正确分配了负载。可以用--verbose启动看显存分配是否均衡。 -
关于laobenxiong提到的关掉压缩 — 他说的有道理,Hermes的压缩用的是DeepSeek做摘要,确实会丢失细节。但关了压缩后,每次请求都要重新prefill完整的256K上下文,这是速度瓶颈的主要来源。你可以试试开prompt caching(llama.cpp的
--no-prompt-cache默认是关闭kv缓存复用的)。 -
Batch size微调 — 试试
--ubatch-size 512配合--batch-size 2048,对长上下文场景的吞吐有帮助。 -
另外双R9700跑27B 256K,速度不可能太快,这是物理限制——大概4-6 tok/s是正常的。如果追求响应速度,可以缩减到128K上下文,速度会翻倍。
-
-
最近请求性能(task 25136, ~71K tokens context)
| 阶段 | 速度 | |-----------------|-------------------------| | prompt 处理前期 | 1319 tok/s (16K tokens) | | prompt 处理中期 | 909 tok/s (49K tokens) | | prompt 处理后期 | 577 tok/s (71K tokens) | | 总 prompt 时间 | 123.87s / 71,419 tokens | | 生成速度 | 17.4 tok/s (稳定) |当前运行状态
| 指标 | GPU 0 | GPU 1 | |------------|----------------|----------------| | 温度 | 64°C | 66°C | | 功耗 | 205W / 300W | 193W / 300W | | VRAM | 27.67 GB (80%) | 27.04 GB (79%) | | GPU 利用率 | 100% | 100% | | SCLK | 3366 MHz | 2973 MHz | - 进程 PID: 1016915,已运行 ~4h - 模型文件: /home/gaopy/models/Qwen3.6-27B-Q4_K_M.gguf (约 16 GB) - 生成速度: 实测 ~17-22 tok/s (当前 71K context 时 17.4 tok/s) -
我用兩張V100 32G, qwen3.6 27B Q8模型可以到4x, reasoning模式關閉感覺智力略降, 所以雖然會拖慢一點, 我還是開著. 參數如下:
Environment=CUDA_DEVICE_ORDER=PCI_BUS_ID
Environment=CUDA_VISIBLE_DEVICES=0,1
ExecStart=llama-server
-m /opt/models/qwen3.6-27b-mtp/Qwen3.6-27B-UD-Q8_K_XL.gguf
--host 0.0.0.0
--port 9527
--alias qwen3.6-27b-ud-q8-xl
-ngl 999
--split-mode layer
--tensor-split 1,1
--ctx-size 400000
--parallel 2
--spec-type draft-mtp
--spec-draft-n-max 2
--chat-template-file /opt/models/qwen3.6-27b-mtp/chat_template.jinja
--cache-type-k q8_0
--cache-type-v q8_0
--flash-attn on
--batch-size 1024
--ubatch-size 256
--no-mmap
--cont-batching
--jinja
--metrics
--no-context-shift
--temp 0.15
--top-p 0.90
--top-k 40
--min-p 0.03
--repeat-last-n 512
--repeat-penalty 1.1
Restart=always
RestartSec=5[Install]
WantedBy=multi-user.target -
系统 取消固定了该主题