全站首发:RTX 3090 24G 无痛爽玩 华为最新开源KV cache格式 (每日更新总结,希望3090卡友进来讨论)
-
起因是在https://github.com/noonghunna/club-3090/ 看到有更新了.
当然,我最感兴趣的还是QWEN 27B .
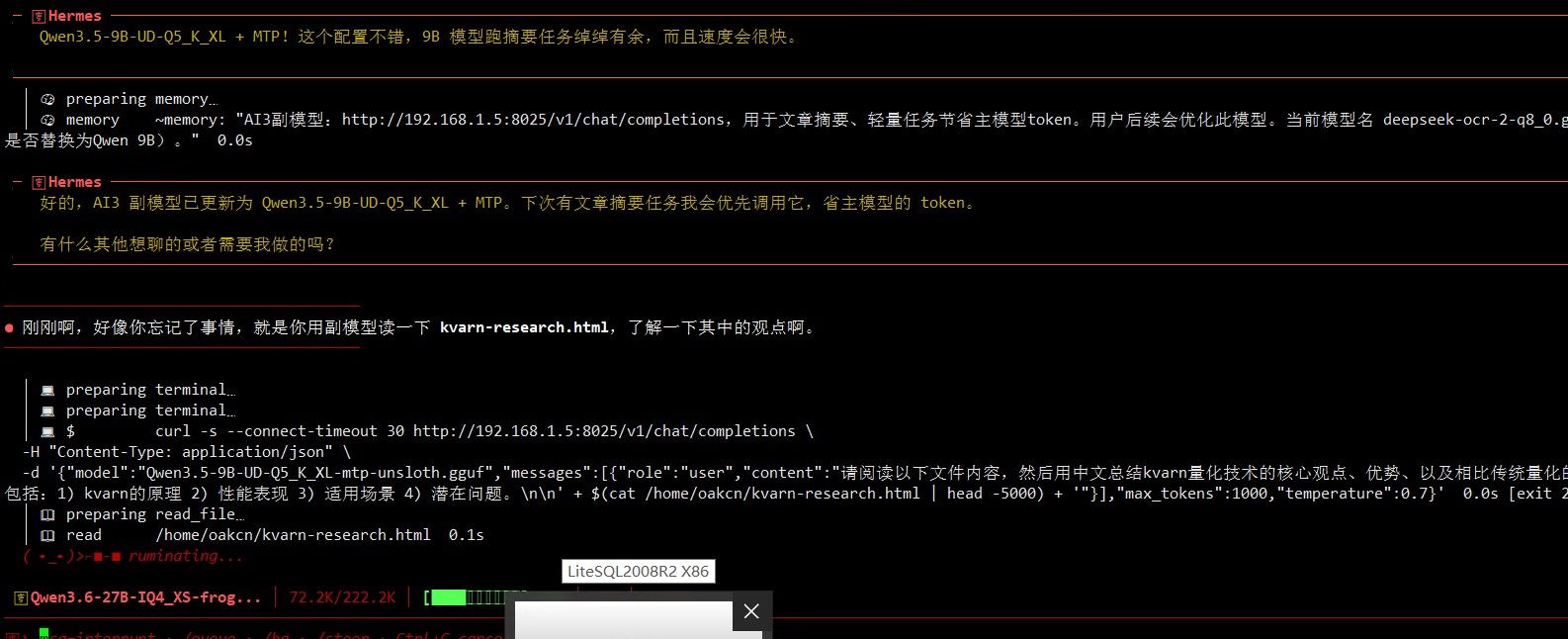
赶紧把提示词丢给Hermes让它干活.
先找了个 其它作者自称很均衡的27B MQO模型开刀( Qwen3.6-27B-MTP-MoQ-4.85.gguf 模型卡上说这是最均衡的,那就它吧.)
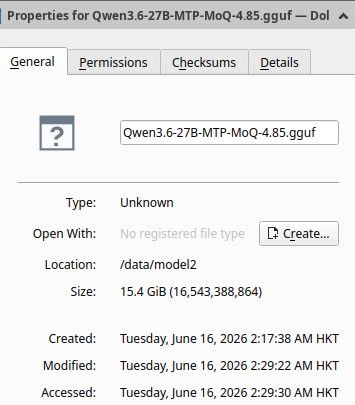
初始显卡占用大概为20.5GB
由于这次参数关闭了思维链,只好使用两步提示词:现在你是北京一所重点中学的高中语文特级教师,我有个语文试卷出题任务要交给你,你准备好了吗? 好,非常不错,就按你说的那些,请随机选取四大名著中的任意一部,再随机选一个章节,看你能回忆起来多少细节。用这些细节和原文制作一道高二语文的阅读理解题 (总分40分,要有判断题,填空题 ,有选择题 ,有问答题 ),要包含对考生文言文和阅读理解的考察,最后附上标准答案及评分指引。总耗时为63秒,产生了3300个左右的TOKEN. 速度大概52T/S
8.43.973.423 I slot print_timing: id 0 | task 805 | prompt eval time = 671.66 ms / 572 tokens ( 1.17 ms per token, 851.62 tokens per second)
8.43.973.425 I slot print_timing: id 0 | task 805 | eval time = 53959.12 ms / 2841 tokens ( 18.99 ms per token, 52.65 tokens per second)
8.43.973.425 I slot print_timing: id 0 | task 805 | total time = 54630.78 ms / 3413 tokens
8.43.973.426 I slot print_timing: id 0 | task 805 | graphs reused = 1927
8.43.973.427 I slot print_timing: id 0 | task 805 | draft acceptance = 0.49115 ( 1693 accepted / 3447 generated)然后我在千问在线版那里,将以前问过的那个问题创建一个分支,确保上下文纯净(公平,公正,公开,哈哈).
经过它2-3分钟的努力,给出的分数是:50分

还行,给它一次机会吧,(注意,我曾经试过让千问在线版去生成试题,也只能拿62分,咱也不是学文科的,搞不懂这些.)
先试跑一下俄罗斯方块试试 :
俄罗斯方块生成中,显存占用是20.4G(稳如老狗?) 结果Trae报502,应该是循环了,一看后台还在疯狂跑TOKEN.
看来我用了noonghunna的参数,却没有用和他相同的模型和镜像,导致翻车. 没事.加上min-p 0.01再试试.
用了3分钟,它生成了,但是有错误.玩起来比我之前那些27B生成 的俄罗斯方块要轻盈,但是不对称的L和Z形,旋转的时候明显错误,让它尝试修一下.
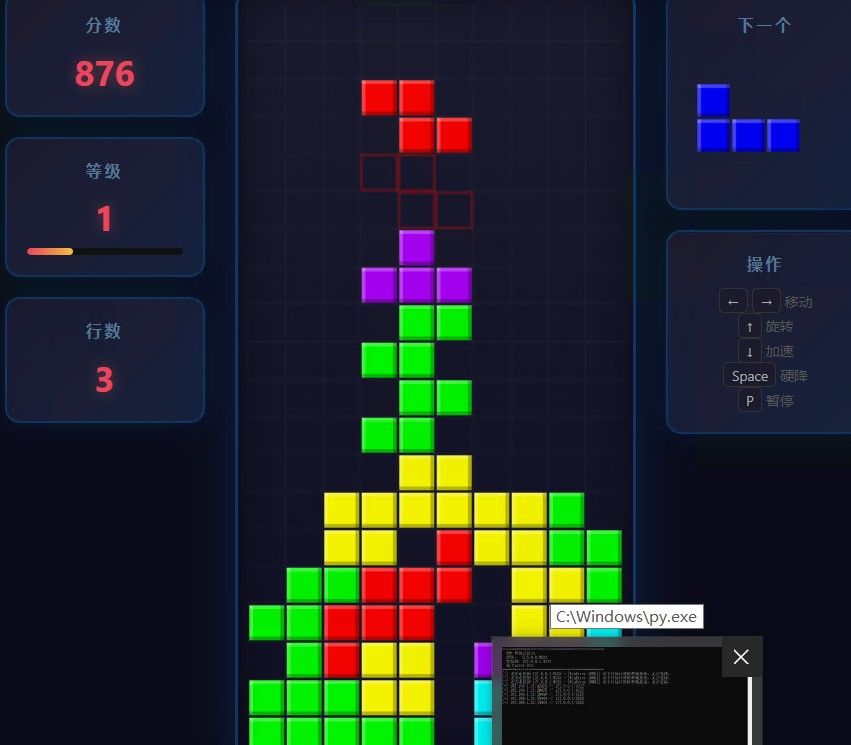
这个模型用一句话自己去脑补生成的俄罗斯方块,基本能玩,也不错,但是似乎这个题目测不出它的实力.
并且没有思考模式,开了等于没开.似乎被强制关闭了.无思考模式,单提示词,生成人机/双机 对战的中国象棋,用了13分钟(中间先删除600行,又补充了600行,怀疑我的提示词有问题), 但它这个 160K长上下文应该是 满血的. 中国象棋 没生成1000行左右,可能是因为我的提示词内部有矛盾
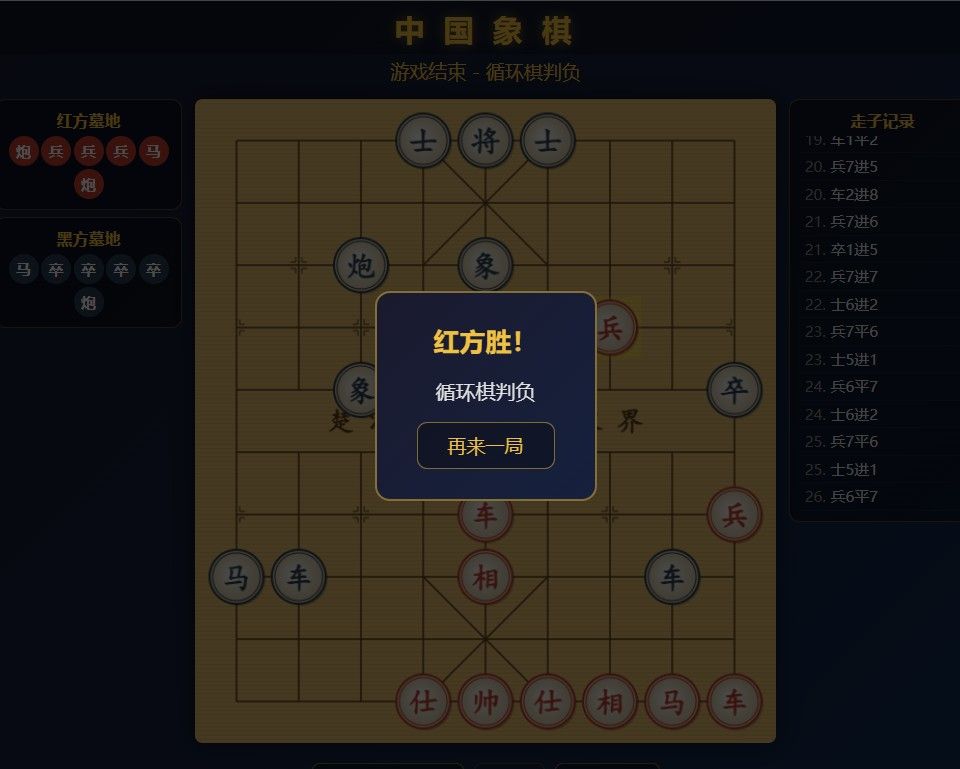
跑完这些去看后台,显存还是占用20.4G.
30.45.890.477 I slot print_timing: id 0 | task 14972 | prompt eval time = 1844.57 ms / 652 tokens ( 2.83 ms per token, 353.47 tokens per second)
30.45.890.479 I slot print_timing: id 0 | task 14972 | eval time = 9730.48 ms / 422 tokens ( 23.06 ms per token, 43.37 tokens per second)
30.45.890.480 I slot print_timing: id 0 | task 14972 | total time = 11575.05 ms / 1074 tokens后期的填充速度略低,只有353T/S
整体来说这个模型我给86分, 华为的新格式必须给95分.等下有空再测一下noonghunna的镜像吧.
-
上面所用的参数.
killall llama3-server 2>/dev/null; sleep 3 killall llama-server 2>/dev/null; sleep 3 export LD_LIBRARY_PATH=/data/model3/beellma616-kv.cpp/build/bin:$LD_LIBRARY_PATH /data/model3/beellma616-kv.cpp/build/bin/llama-server \ --host 0.0.0.0 --port 8025 \ -m /data/model2/Qwen3.6-27B-MTP-MoQ-4.85.gguf \ --spec-type draft-mtp \ --spec-draft-n-max 3 \ -ngl all \ --ctx-size 163840 \ -b 2048 -ub 512 \ -np 1 \ --kv-unified \ --cache-type-k kvarn4 \ --cache-type-v kvarn4 \ --flash-attn on \ --cache-ram 0 \ --no-host \ --jinja \ --reasoning off \ --temp 0.6 --top-k 20 --top-p 0.96 --min-p 0.01完美契合 Qwen3.6 的混合架构
Qwen3.6 系列本身采用了混合注意力机制。llama.cpp 近期通过 --swa-full 等参数,完美适配了这种架构
。社区测试表明,在重新评估 Qwen3.6-27B 时,开启 SWA 相关参数能完美解决长上下文下的显存泄漏和失效问题
补充一下,看增加这个参数有没有好效果,这个参数在beellama上无效,可能是千问自己幻想的.抱歉了. -
现在开始用noonghunna的配置和镜像 测试 Qwopus CODER 3.6 27B MTP Q 5 KM.
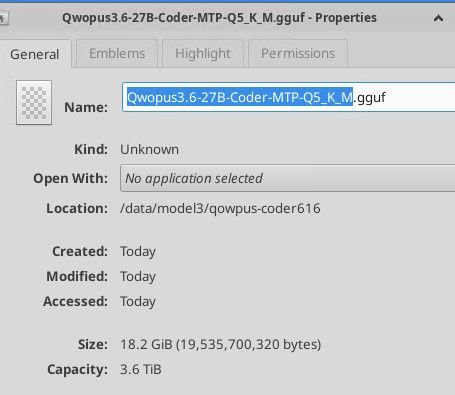 权重就达到了19.5G,比我平时用的都多了6GB啊? 增加的这部分体积能起到相应的效果吗?
权重就达到了19.5G,比我平时用的都多了6GB啊? 增加的这部分体积能起到相应的效果吗?
一开始直接上160K,问第二段时直接爆显存(根本原因可能是我那440M显存开机被占用了,下次重装系统一定安装server版 headless系统)
两段式生成文学试卷题,共花费59秒. 感觉比小模型要谨慎一些.
同样丢 给在线的千问打分(已经开了分支对话,避免其它污染干扰)
给出的分数是20分,这不稀奇,因为它是CODER模型,文学被削弱了是好事,说明编码能力可能被增强.
显存维持在22G左右(剩余1.9G)写俄罗斯方块用了3分钟,我玩了3分钟,基本无错.Q5权重 及coder优化 起到了相当的效果.
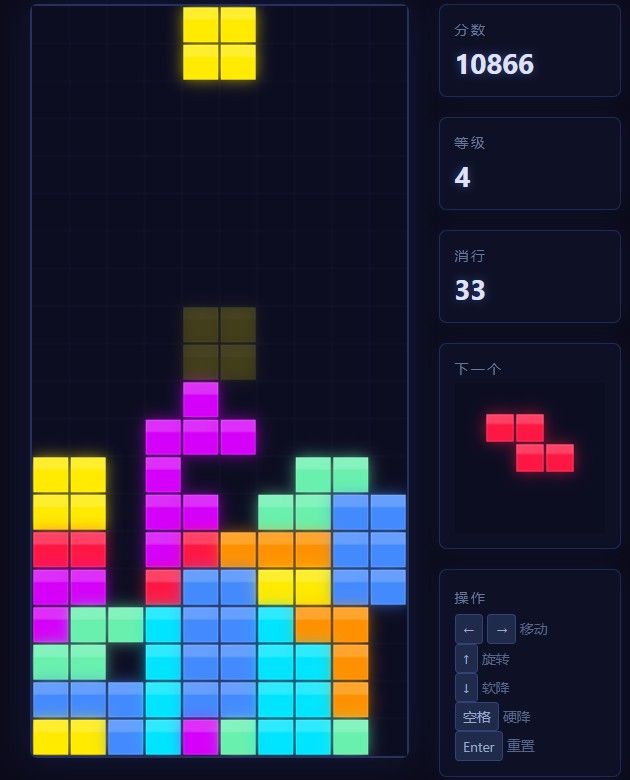
写完之后显存占用没变,显存管理挺优秀.

下面开始写中国象棋,我修改了一下提示词,防止需求内部矛盾导致后续 写了代码又大段大段删除.如果这个测试能完美,证明它的CODER能力确实有增强. 否则我还不如用unsloth的UD mtp模型呢.
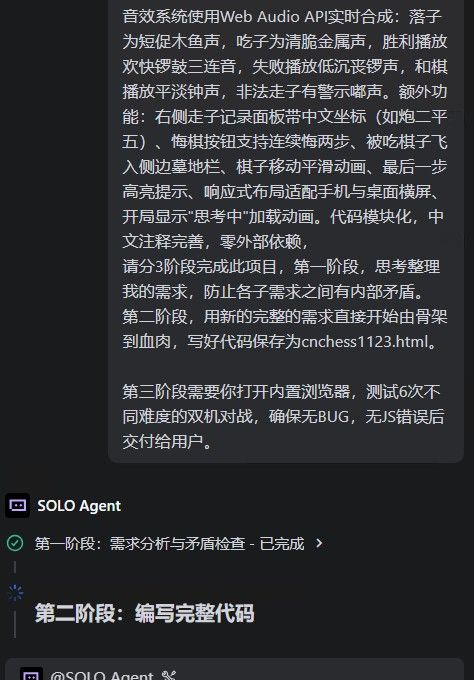
这个模型挺均衡的,给我显卡干到64度了,心疼显卡3秒钟.
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
现在开始用noonghunna的配置和镜像 测试 Qwopus CODER 3.6 27B MTP Q 5 KM.
权重就达到了19.5G,比我平时用的都多了6GB啊? 增加的这部分体积能起到相应的效果吗?
一开始直接上160K,问第二段时直接爆显存(根本原因可能是我那440M显存开机被占用了,下次重装系统一定安装server版 headless系统)
两段式生成文学试卷题,共花费59秒. 感觉比小模型要谨慎一些.
同样丢 给在线的千问打分(已经开了分支对话,避免其它污染干扰)
给出的分数是20分,这不稀奇,因为它是CODER模型,文学被削弱了是好事,说明编码能力可能被增强.
显存维持在22G左右(剩余1.9G)写俄罗斯方块用了3分钟,我玩了3分钟,基本无错.Q5权重 及coder优化 起到了相当的效果.
写完之后显存占用没变,显存管理挺优秀.
下面开始写中国象棋,我修改了一下提示词,防止需求内部矛盾导致后续 写了代码又大段大段删除.如果这个测试能完美,证明它的CODER能力确实有增强. 否则我还不如用unsloth的UD mtp模型呢.
这个模型挺均衡的,给我显卡干到64度了,心疼显卡3秒钟.
-
@stxpnet 我的显卡长期70+啊
-
@applejuice 温度?
-
可以多在reddit上搜索看一下,我昨晚看了,也有人在研究这个格式的kv cache了,对咱们这批老用户是个好消息.
我目前的体感是64K或者128K比较适合咱们这个卡. 开0.7的温度,和hermes聊天. 0.6的温度编程. 下面是各种kv cache 的分歧度. 及显存占用 ,二者都是越小越好. 但我还想到一层:
就是如果你的模型权重本身 是Q4的话,产生Q5或Q6级别的cache,可能会拖慢速度,因为它在原始权重中找不到对应的参数.要在KV CACHE里面找,可能拖慢速度. 所以有空可以试试Q5级别的权重.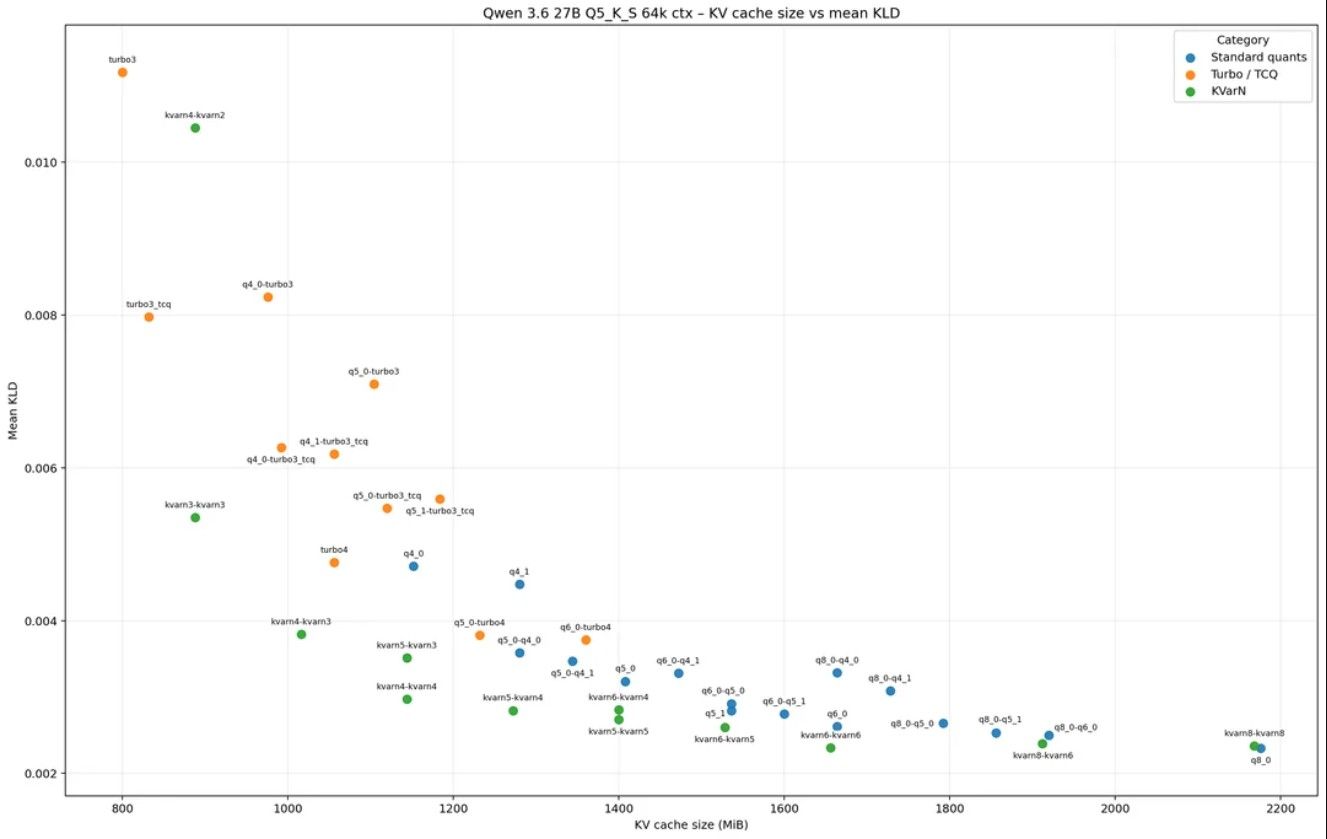
-
可以多在reddit上搜索看一下,我昨晚看了,也有人在研究这个格式的kv cache了,对咱们这批老用户是个好消息.
我目前的体感是64K或者128K比较适合咱们这个卡. 开0.7的温度,和hermes聊天. 0.6的温度编程. 下面是各种kv cache 的分歧度. 及显存占用 ,二者都是越小越好. 但我还想到一层:
就是如果你的模型权重本身 是Q4的话,产生Q5或Q6级别的cache,可能会拖慢速度,因为它在原始权重中找不到对应的参数.要在KV CACHE里面找,可能拖慢速度. 所以有空可以试试Q5级别的权重. -
,系统 取消固定了此主题
-
,5 566656661 引用了 此主题
-
现在开始用noonghunna的配置和镜像 测试 Qwopus CODER 3.6 27B MTP Q 5 KM.
权重就达到了19.5G,比我平时用的都多了6GB啊? 增加的这部分体积能起到相应的效果吗?
一开始直接上160K,问第二段时直接爆显存(根本原因可能是我那440M显存开机被占用了,下次重装系统一定安装server版 headless系统)
两段式生成文学试卷题,共花费59秒. 感觉比小模型要谨慎一些.
同样丢 给在线的千问打分(已经开了分支对话,避免其它污染干扰)
给出的分数是20分,这不稀奇,因为它是CODER模型,文学被削弱了是好事,说明编码能力可能被增强.
显存维持在22G左右(剩余1.9G)写俄罗斯方块用了3分钟,我玩了3分钟,基本无错.Q5权重 及coder优化 起到了相当的效果.
写完之后显存占用没变,显存管理挺优秀.
下面开始写中国象棋,我修改了一下提示词,防止需求内部矛盾导致后续 写了代码又大段大段删除.如果这个测试能完美,证明它的CODER能力确实有增强. 否则我还不如用unsloth的UD mtp模型呢.
这个模型挺均衡的,给我显卡干到64度了,心疼显卡3秒钟.
-
@stxpnet 平时我只要跑起来就 90度啊。。。