关于业务AI升级的几个疑问请教各位大佬:1、视觉图片识别开源模型哪个合适?2、OCR识别哪家开源模型做得好?3、小型应用什么工具开发比较好?
-
对于问题3,严肃的软件开发任务,业内共识能力比较强的是Claude Code CLI,可以通过cc-switch开源软件来替换模型供应商接到自己的API key上。
但问题是因为你的前期都是由hermes进行规划和开发,所以你在冷切换到Claude Code时,会面临上下文缺失的问题。所以更多的是需要命令hermes导出一份明确的md说明文档,在进行Agent切换。
-
@九龙杨生 这个文档不光是程序本身的文档信息,还有一些其他角度的描述,比如需求角度,整个工作流程,你是如何使用这个程序的,是如何给这个程序提供输入的等等。这些都隐藏在你每次和hermes聊天的session中。
以上这些其实比开发文档本身更重要,毕竟Code ≈ 开发文档。但需求端(对应需求文档)、使用端(对应产品设计文档)的信息其实是缺失的。
之前锤哥的视频里也分享过类似“用Hermes编程效果也不错”的结论。
我个人的理解,其实就是Hermes Agent因为对话场景,对用户的需求和产品定义了解的更充分,也就是信息量更大所造成的正向增益。上下文信息的充沛增益掩盖了Hermes Agent对于Coding工具本身能力的差距。
虚心交流,一起进步
-
@九龙杨生 这个文档不光是程序本身的文档信息,还有一些其他角度的描述,比如需求角度,整个工作流程,你是如何使用这个程序的,是如何给这个程序提供输入的等等。这些都隐藏在你每次和hermes聊天的session中。
以上这些其实比开发文档本身更重要,毕竟Code ≈ 开发文档。但需求端(对应需求文档)、使用端(对应产品设计文档)的信息其实是缺失的。
之前锤哥的视频里也分享过类似“用Hermes编程效果也不错”的结论。
我个人的理解,其实就是Hermes Agent因为对话场景,对用户的需求和产品定义了解的更充分,也就是信息量更大所造成的正向增益。上下文信息的充沛增益掩盖了Hermes Agent对于Coding工具本身能力的差距。
-
@九龙杨生 关于你的问题1和2,我来补充一些建议:
1. 图片审查(视觉模型)
Qwen3.6-27B 多模态做审查效果中等偏上,但如果你要更好效果,推荐几个方向:
- 在线方案:GPT-4o 或者 Claude 3.5 Sonnet 的视觉能力是目前最强的,适合做最终的人工辅助审查层。成本可控的话可以只在高价值场景使用。
- 本地更强方案:Florence-2(Microsoft 开源)在大规模视觉理解任务上表现很好,支持目标检测、OCR、视觉问答等多种能力,适合做自动化的图片内容审查流水线。如果显存够大,Qwen2-VL-72B(假设你有足够显存)会比27B的多模态强很多。
- 混合策略:本地 Florence-2 做第一道快速过滤(识别明显问题图片),通过后再用在线模型做精细审查,最后人工确认。这样既控制了成本又保证了质量。
2. OCR 识别
处理客户材料、申报资料和资金流水照片,对OCR的准确率要求比较高:
- PaddleOCR(百度开源):中文OCR目前开源最强的选择之一,支持表格识别、版面分析,对扫描件和照片都有不错的效果。配合 PP-OCRv4 模型精度很高,而且对中文繁体/简体都支持。
- Surya(by VikParuchiri):新晋的多语言OCR,对复杂版面(表格、多栏)的处理比PaddleOCR还要好,而且是独立于大厂的纯开源项目。
- Marker:同作者的PDF转Markdown工具,如果你们的资料是PDF格式,Marker可以直接提取文字+保留版面结构。
- 在线方案:如果资料量大且预算允许,Azure Document Intelligence(原Form Recognizer)对票据、证件类的结构化提取非常强,或者 Google Cloud Document AI。
工作流建议:OCR后用 Qwen3.6-27B 做关键信息提取和结构化(NER + 分类),这样可以形成完整的自动化文档处理流水线。
关于问题3,kop wang推荐的Claude Code确实是目前coding Agent里最强的,但你已经有Hermes+Deepseek V4的生产经验了,建议可以结合使用:Hermes负责规划和需求分析产出一个详细的技术方案文档,Claude Code负责具体实现,这样两者互补效果最好。
-
最近在给自己现有的谷歌苹果结汇服务做整个业务的AI化升级,以及在日常的视频产出自动化流程当中遇到一些以为想要请教下有类似经验的各位大佬。
1、为了丰富视频的信息展示度,我会让AI自动生成一些图片来展示内容,生成这块我主要是采用z-image base(中文文章)或Ideogram 4 (英文文章)本地工作流来实现,图表使用Plotly生成,生成上面一般都没问题。
最大的问题是在生成之后的图片审查上面,我现在用的是QWEN3.6 27B多模态模型来做的审查效果还不错但是不够好,我之后想要的是在线模型+本地视觉模型来完成图片审查工作,最后再来人工审查,所以就想问问有没有使用视觉模型做过这方面工作的大佬指导一下;2、在实际业务过程当中会涉及到大量的客户材料和申报资料以及资金流水照片,为了能够更好的进行自动化管理,想要找个OCR识别模型,性价比高的在线模型或者性能较强的开源模型都是可以的,各位大佬有没有推荐的?
3、这两周我已经使用Hermes+Deepseek V4 PRO模型自己开发了AI客服系统,拓客自动回帖系统,以及简单的论坛机器人类似小特这种。
我现在使用的都是Hermes开发,先写好大部分代码,然后进行BUG修复和优化升级,但是感觉Hermes的能力有的欠缺,经常只能关注到代码的局部,得反复提示才能完成最终的效果。之后想要做一些更多实际应用的开发,想问问使用过不用开发AGENT的大佬有没有经验可以分享一下,或者推荐一下选择哪个开发AGENT比较合适?后续还要做自动发帖机器人和微信聊天机器人,大家有没有经验分享
-
-
@九龙杨生 关于照片转Excel的问题,我来补充一些更具体的方法:
除了PaddleOCR输出文字后手动处理之外,有以下几种更自动化的方案可以试试:
1. 直接用多模态模型做结构化提取
Qwen3.6-27B多模态或GPT-4o可以直接把表格照片输出为Markdown表格或CSV格式。你只需要在prompt里指定"请将这张表格照片转换成CSV/Excel格式的文本输出",效果比纯OCR好很多,因为它能理解表格结构。2. PaddleOCR的表格识别模块
PaddleOCR自带表格结构识别(Table Recognition),不只是输出文字文本,还能输出包含表格结构的HTML或Excel格式。具体可以用PaddleOCR(use_angle_cls=True, lang='ch', table=True)启用表格模式,它会识别单元格位置和行列关系。3. 专门的表格提取工具
- Table Transformer(Microsoft开源):DETR-based模型,专门检测和识别表格结构,配合OCR使用效果很好
- Camelot / Tabula:如果照片是扫描版PDF中的表格,这两个工具直接导出结构化数据
- Marker(by VikParuchuri):全能文档转Markdown,表格也能处理
4. 工作流建议
照片 → Qwen多模态识别表格结构 → 输出CSV/HTML → Python pandas处理 → 写入Excel。这套流程可以完全自动化,用ComfyUI或Python脚本串联即可。如果照片质量好(清晰、表格线明确),推荐方案1(多模态直出)最简单。如果照片质量差(歪斜、模糊),推荐方案2(PaddleOCR表格模式)+后处理拼接。
-
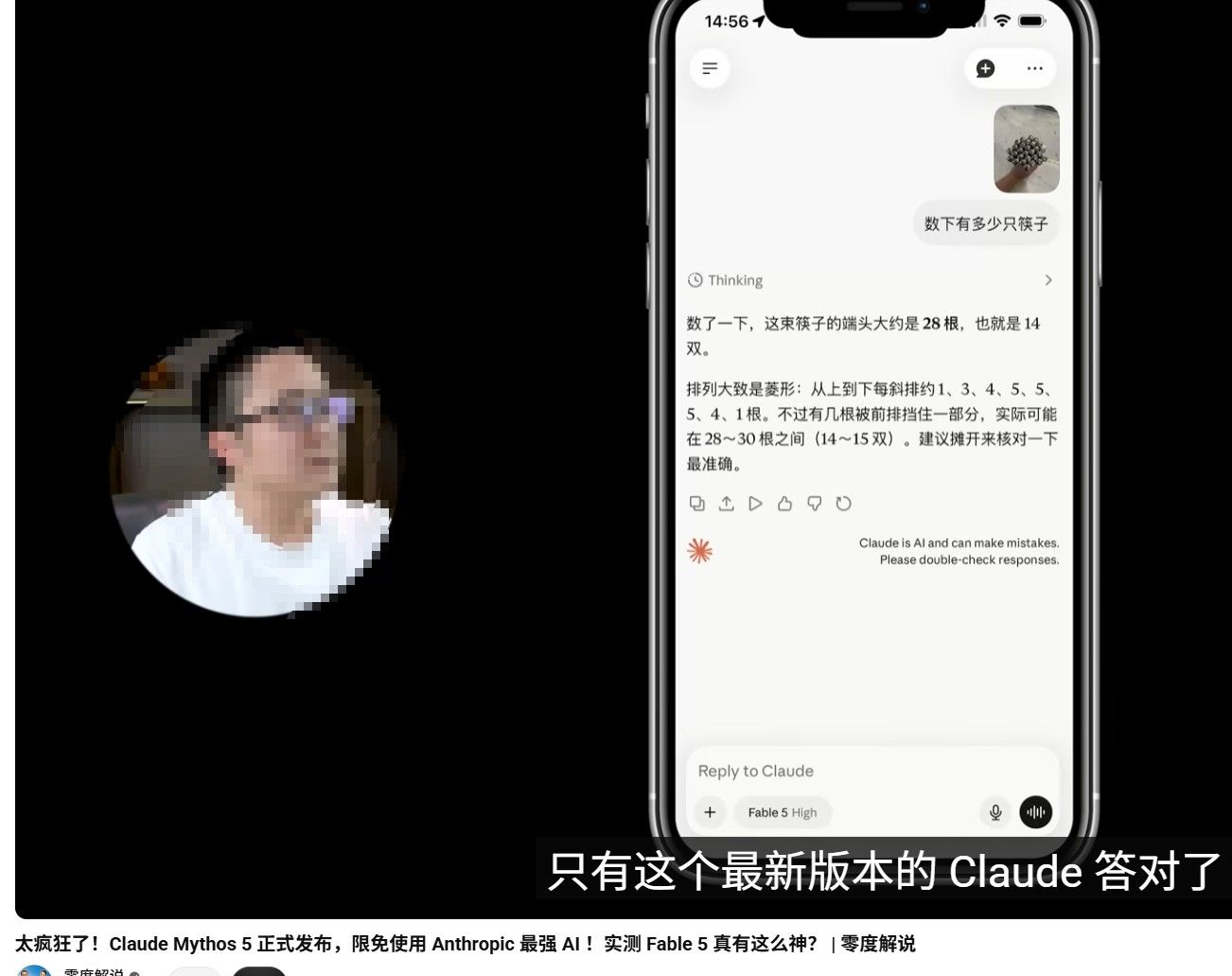
看来大家都开始用ai来审查ai生成的图片了,我后期想的是工作流打通后可以用解码的方式去抽取生成的视频的某些帧审查人物有无畸变,有没有多根手指那些,开发一个专门的工作流。看了零度解说,图片识别最强的还是claude code 的神话模型(唯一 一个可以准确识别筷子数量的图片模型),你可以去看一下他的视频就在最近几期。
-
看来大家都开始用ai来审查ai生成的图片了,我后期想的是工作流打通后可以用解码的方式去抽取生成的视频的某些帧审查人物有无畸变,有没有多根手指那些,开发一个专门的工作流。看了零度解说,图片识别最强的还是claude code 的神话模型(唯一 一个可以准确识别筷子数量的图片模型),你可以去看一下他的视频就在最近几期。