
受站长的激励,分享一下这10天都在comfyui做了些什么“大”制作
-
10天、18支视频:一人全栈AI漫画频道的完整踩坑记录
不涉及具体项目/频道名称,只聊创作层面的真实迭代过程。
时间线速览(基于文件系统时间戳)
6/22 10:08 EP02 完成 41文件 ← 最早完成的成品!(EP01实验太久,EP02先出来了) 6/23 00:03 EP03 完成 11文件 6/23 00:28 EP01 完成 9文件 ← EP01反而是第三支完成的 6/23 02:45 EP03_Rebuild 重建(质量不满意) 6/23 23:14 EP04 完成 55文件 ← 管线爆发:建立标准目录结构 6/24 20:26 EP05 完成 40文件 ← 新坑:VAE紫色杂讯 6/25 08:30 VAE修复 ep05_fix_vae_test.py 6/25 23:53 EP05_Rebuild 重建(质量不达标) 6/26 18:22 EP06 完成 17文件 ← 管线精简,1080p上采样 6/27 12:37 EP07 完成 27文件 ← 新增SFX音效、hook音频、缩略图 6/27 20:02 EP08 完成 26文件 6/28 10:34 EP08_Rebuild 重建 6/28 00:29 Illustrious模型测试(替代Animagine的候选) 6/30 12:04 EP10 完成 26文件 6/30 12:08 EP09 完成 26文件 6/30 19:53 EP11 完成 17文件
EP01:双引擎试错,烧¥50买认知
起步:想双线并进,WAN却直接翻车
6月21日晚上,creator子智能体开始构建EP01的工作流。最初的计划是WAN 2.2和LTX 2.3双线并行,creator profile里现在还留着当时的脚本:
submit_i2v_final.py (21:06) → WAN 2.2 API格式 submit_i2v_fix.py (21:05) → WAN 2.2 修复版 submit_i2v_v2.py (21:09) → WAN 2.2 迭代2 submit_i2v_v3.py (21:10) → WAN 2.2 迭代3 submit_i2v_v4.py (21:13) → WAN 2.2 迭代4一小时内出了5版脚本——不是因为正常迭代,而是WAN 2.2遇到了致命性故障:生成画面满屏紫色杂讯,完全不可用。
(最后发现,wan2.2,只要使用单Unet节点,100%会触发,有且只能用双Unet的模式)换了参数、换了prompt、换了CLIP编码器……5个版本全部翻车。紫色杂讯像病毒一样覆盖每一帧输出。这个bug后来在6/23的
submit_wan_i2v_fixed.py里才被修掉。被迫单线:LTX 2.3救场
(我一直都是让hermes agent给我按照机智罗的工作流做到完整的复制,但是deepseek一直在找借口绕路)
(后面新开了会话,让sonnet4.6来救场后,才遵循到我的要求来跑通了第一天的工作)
WAN不行,只能把全部希望押在LTX 2.3上。用的是
ltx-2-3-22b-distilled-Q4_K_M.gguf(Q4量化),CLIP:Gemma 3 12B GGUF。出图参数:8步、CFG 1.0。LTX的问题是:视频画面对prompt的遵从度低,生成的画面经常偏离脚本描述。为了得到一组勉强可用的画面,需要反复调整prompt重试。但至少——它能出图,不像WAN那样直接紫色糊脸。
成本
DeepSeek V4 Flash主要用于故事脚本拆解(把原文拆成分镜脚本)和prompt迭代(每次重试都要重新调prompt)。一晚上下来烧了大约¥50的API token。
后续:WAN 2.2在后面几集成功接手
EP01被迫只用LTX 2.3跑通后,没有放弃WAN。6/23凌晨修复了紫色杂讯bug(
submit_wan_i2v_fixed.py+submit_wan_i2v_xb.py),后续视频开始迭代到WAN 2.2作为主力。EP01的关键决策
做完EP01后确定了三个原则:
- 放弃视频生成路线做漫画——LTX生成的视频逐帧拆成漫画质量太差
- ComfyUI逐帧出图(用Animagine XL V3 + 自定义角色LoRA)作为主力
- 文本模型只负责拆脚本,画面和风格交给本地GPU
EP02-03:固定工作流 + 首次视频化尝试
标准参数确立
基础模型:Animagine XL V3 (SDXL动漫特化) LoRA: 自定义女性角色 LoRA @ 0.8 强度 分辨率: 1344×768 (16:9 漫画比例) 采样器: dpmpp_2m_sde + karras, 20步 CFG: 7 环境: 241节点 → 7900 XTX (ComfyUI :8188)这组参数成为后续所有视频的"标准配方"。
EP03视频化:WAN修复后首测
6月23日凌晨3:55-3:59,creator在241上跑了修复后的WAN 2.2对比实验:
端口8189 → WAN 2.2 I2V (fixed UMT5版 + XB版) 端口8188 → LTX 2.3 I2V (对比基线)输入都是
EP03_P01_FINAL.png。WAN的紫色杂讯bug终于在submit_wan_i2v_fixed.py里被修掉了。这次实验验证了:把静态漫画转成视频片段(作为视频的开场/高潮动效)是可行的,但整集都用视频生成不行。 后续视频开始从LTX逐步迁移到WAN。
EP04(6/23深夜):标准管线诞生
EP04是整个项目的分水岭。55个文件,第一次建立了完整的目录结构:
EP04/ 01_images/ ← ComfyUI静态漫画帧(P01-P12,含a/b变体) 02_scripts/ ← 生成脚本 03_prompts/ ← ComfyUI prompt JSON 04_tts/ ← 日语配音音频 05_i2v/ ← 图片转视频(WAN 2.2 I2V) 05_i2v_rife/ ← RIFE帧插值(补帧到60fps) 06_bgm/ ← 背景音乐 08_deliverables/← 最终交付文件同时也是第一次产出双语版本:JP(日语)和 EN(英语)各一套,含完整版和Shorts版。
这个目录结构成了后续所有EP的模板。
EP05(6/24-25):VAE紫色杂讯——又一个"紫色"bug
6月24日EP05完成初版。但出现了新的画面bug:VAEDecodeTiled导致的紫色块。
6月25日早上8:30,creator写了
ep05_fix_vae_test.py:修复 VAEDecodeTiled → 标准 VAEDecode,验证紫色块消失把ComfyUI工作流里的VAE解码器从分块模式(VAEDecodeTiled)切回标准模式(VAEDecode),紫色块消失。
但初版还有其他质量问题——6月25日晚上23:53完成了EP05_Rebuild(29个文件的重建版)。EP05还留下了
wrong/目录(废弃输出),说明当时在大量试错。EP06(6/26):管线精简 + 1080p上采样
文件数从EP04的55个降到17个——不是产出少了,是管线更成熟了,不再需要那么多中间产物。新增了
upscaled_1080p_full/和upscaled_1080p_short/,说明正式加入了AI超分辨率上采样环节。EP07(6/27上午):功能最丰富的一集
EP07新增了:
- SFX音效(
sfx/) - Hook音频(
tts_hook_jp.wav)——视频开头抓人的短音频 - 缩略图采样(
thumbnail_samples/)——给YouTube封面准备 - 发布版本文档(
ep07_publish_copy.md)——记录发布描述文案
EP08(6/27晚-6/28重建):效率冲刺
EP08一天内完成(27号20:02),但第二天(28号10:34)又Rebuild了。日产量达到2集。
Illustrious模型测试(6/28)
在
illustrious-test/目录下做了大量测试——Illustrious是另一个SDXL动漫模型,作为Animagine XL V3的替代候选。测试内容包括独奏(单人)、双人、inpaint等场景。EP02先于EP01完成?创作顺序的真相
文件时间戳揭示了有趣的事实:
EP02 → 6/22 10:08 (41文件,最早) EP03 → 6/23 00:03 EP01 → 6/23 00:28 (反而是第三支)EP01不是第一支完成的视频。EP01因为WAN故障+LTX试错消耗了最多时间,反而EP02和EP03先用成熟工作流跑完了。EP01到6月23日凌晨才最终交付——它是创作顺序上的起点,却是交付顺序上的第三名。
EP06:漫画感的觉醒
核心问题
AI直出的图缺少"漫画味"——没有气泡、拟声词、分镜节奏。
尝试在ComfyUI里直接出带气泡的图(prompt里写"speech bubble"),结果:气泡是画面的一部分,位置随机,文字乱码,经常盖在人脸上。
决策:AI出纯净图,后期手动加漫画元素
这是整个工作流的转折点。制作时间翻倍(2h→4h),但画面质量飞跃:
- 气泡不再盖人脸
- 文字不再是乱码
- 分镜有了真正的节奏感
EP07(6/26-27):工作流全面优化
6/27的系统性优化
在creator和dev profile的对话中确认了以下改动:
① 模型目录统一
之前模型散落两处(~/ComfyUI/models/和/mnt/models/ComfyUI/),导致加载失败和重复下载。全部归到/mnt/models/ComfyUI/。② 多卡分工
7900 XTX #1 :8188 → 主出图流程 7900 XTX #2 :8189 → 修复/Inpainting辅助 3080 Ti → 视频编码/后期③ 角色一致性升级
从"IPAdapter + 单参考图"升级到"IPAdapter + 多角度参考图库(正脸/侧脸/表情各一张)"。④ 漫画气泡方案定型
讨论了三路线:
- PanelForge集成 → 灵活但手动定位
- Inpainting融合 → 画质好但多一步出图
- Python后处理 → 快速、全自动、不费GPU
最终选Python后处理:AnimagineXL出图→MediaPipe检测人脸→计算气泡安全区→Pillow渲染→叠加。不用再跑一次ComfyUI,批次处理更快。
EP08+:效率飞轮
不再加新功能,全力提效:
- 脚本拆解prompt模板化(DeepSeek一次出合格分镜)
- ComfyUI JSON工作流固化(换prompt节点就出图)
- 后期步骤脚本化
单集制作时间:EP01的7h+ → EP08的2-3h。
技术参数附录
ComfyUI 静态出图(Animagine XL V3 + LoRA)
# EP05 batch static 脚本中的标准参数 width: 768 # 竖屏漫画比例 height: 1344 # 竖屏漫画比例 batch_size: 1 # 单张出图 seed: 202022 # 基础种子,每页+1 steps: 20 # 步数 cfg: 6.0 # CFG引导强度 sampler: dpmpp_2m_sde scheduler: karras denoise: 1.0LoRA强度未在脚本里写死(由ComfyUI workflow JSON控制),实际使用
female_lead_lora.safetensors @ 0.8。LTX 2.3 视频生成
# batch_submit_v5.py 中的参数 steps: 15 # LTX比静态图需要更多步 cfg: 1.0 # 视频模型CFG接近1 sampler: euler scheduler: sgm_uniform frame_rate: 24 # 目标24fps strength: 1.0 # img2video强度CLIP:
LTX-2.3/gemma-3-12b-it-Q4_K_M.gguf(GGUF量化)
UNet:LTX-2.3/ltx-2-3-22b-distilled-Q4_K_M.gguf(Q4量化)
VAE:LTX-2.3/LTX23_video_vae_bf16.safetensorsWAN 2.2 视频生成
(其实这两个都是复刻机智罗的工作流,但是在使用过程中慢慢的加入了自己的参数罢了)
# submit_i2v_v4.py / submit_wan_i2v_fixed.py CLIP: t5xxl_fp8_e4m3fn.safetensors VAE: Wan2.2/wan2.2_vae.safetensors UNet: Wan2.2/I2V/Wan2.2_I2V_Dasiwa-V10_Q4_High.gguf (Q4量化) 采样步数: 3 (轻量快速出视频) CFG: 1 分辨率: 624×624 → crop到16倍数RIFE 帧插值
EP05-Rebuild (失败方案): pass ×2: 81f → 161f → 321f 播放: 24fps = 13.4s/页 效果: 2.6x慢动作 ❌ 太慢 EP06(最终方案): pass ×1: 81f@16fps → 161f@24fps 播放: 24fps = 6.7s/页 效果: 1.3x微慢 ✅ 最佳RIFE配置:
clear_cache_after_n_frames: 10 # 防止显存泄漏 scale_factor: 1.0 # 不缩放(480×832→1080p交给后续upscale) input: 480×832 (ComfyUI直出) → output: 161f@24fps双卡负载分配(batch_submit_v5 交替模式)
jobs = [ ("http://192.168.0.241:8188/prompt", "P02.png"), # 卡1 ("http://192.168.0.241:8189/prompt", "P03.png"), # 卡2 ("http://192.168.0.241:8188/prompt", "P04.png"), # 卡1 ("http://192.168.0.241:8189/prompt", "P05.png"), # 卡2 ... ]交替分配让两张卡同时跑,并行出图翻倍效率。
标准EP管线目录
EP0X/ 01_images/ ← ComfyUI静态漫画帧 03_prompts/ ← ComfyUI workflow JSON 04_tts/ ← VoiceVox日语配音 05_i2v/ ← WAN 2.2 图片转视频片段 05_i2v_rife/ ← RIFE帧插值 (81f→161f) 06_bgm/ ← 背景音乐 08_deliverables/← 最终成品 upscaled_1080p/ ← AI超分到1080p *_full.mp4 ← 完整版 *_shorts.mp4 ← YouTube Shorts版 *_JP_*.mp4 ← 日语版 *_EN_*.mp4 ← 英语版成本
项目 费用 说明 DeepSeek V4 Flash API ~¥5-10/集(含其他迭代优化脚本之花费) 脚本拆解+prompt生成 EP01特殊成本 ~¥50 WAN试错+LTX反复调参 ComfyUI出图 免费 本地7900 XTX VoiceVox TTS 免费 开源 VoxCPM2声线转换 免费 自建(内网6843) RIFE帧插值 免费 本地GPU 1080p超分 免费 本地GPU
核心心得
1. 视频生成模型不适合做漫画
WAN 2.2和LTX 2.3都试了。结论:视频模型适合"运动的画面",漫画需要的是"高质量静态帧+叙事节奏"。方向性错误,¥50买了这个认知。
2. WAN的紫色杂讯bug拖了一整天
计划的双线策略被WAN的致命bug打乱了。5版脚本全部翻车,最终只能靠LTX 2.3单线跑通EP01。但好在bug后来修掉了,WAN在后面几集成功接手。
3. AI出图 + 人工后期 > 全AI一条龙
气泡和分镜交给AI → 乱码盖脸。AI只做"出纯净画面",排版/文字/节奏留给手动控制。这个分界线画清楚后,画面质量直接跳了一档。
4. 角色一致性是AI漫画的终极难题
LoRA + IPAdapter + 多角度参考图库——目前最稳定的方案。但依然做不到100%。这是整个工作流最耗精力的部分。
5. 多GPU是被逼出来的
(其实并不是,只是我TM拿到了劳动仲裁款,有钱身痒痒,看到坛里分享的优惠咨询,不买不开心)一张7900 XTX一天出不了18集的图。三张卡各司其职才能把周期压缩到一天2-3支。
基于creator/dev profiles的实际对话记录、ComfyUI工作流脚本和YouTube频道数据整理。
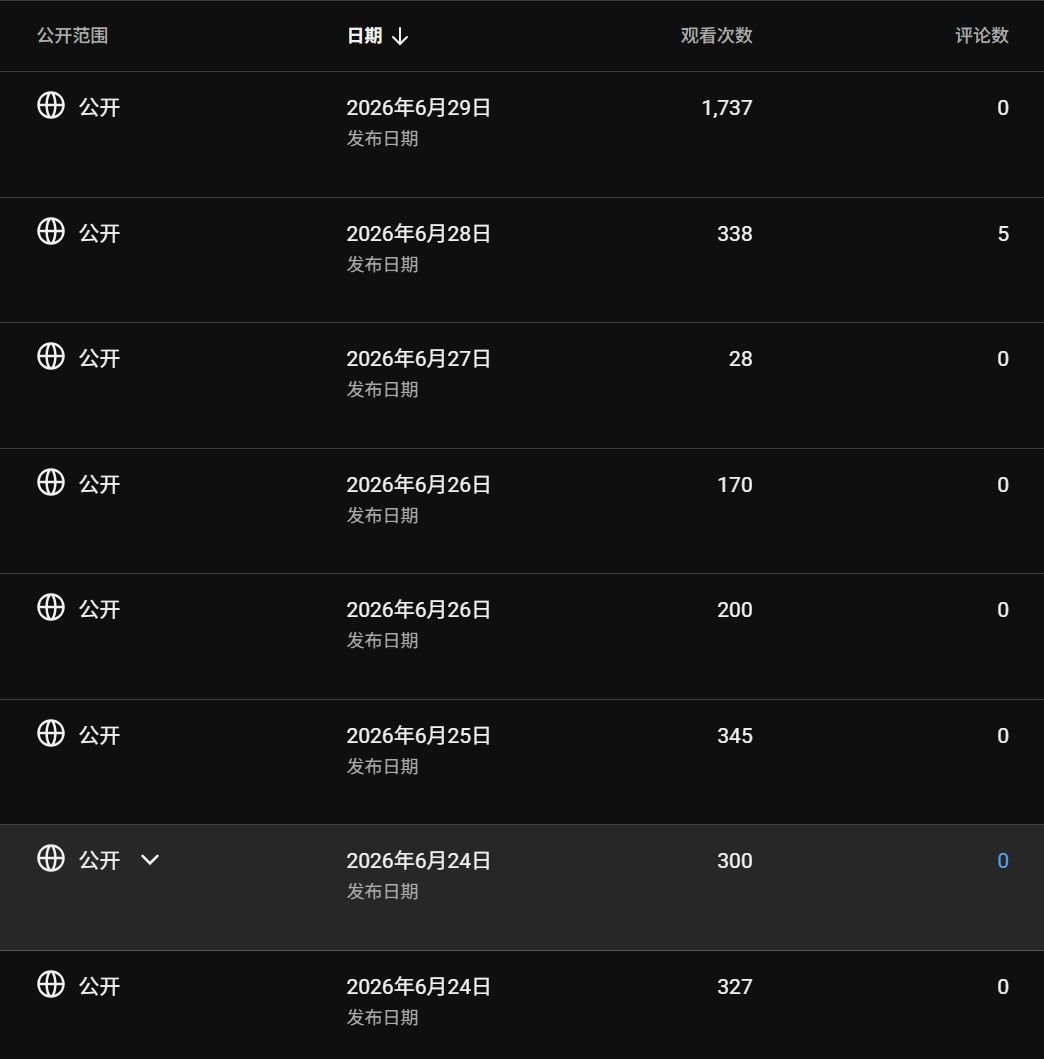
慢慢迭代优化后,频道第一次突破1000播放!
以上迭代思路受马斯克之:快速迭代敏捷开发所启发,不管黑猫好猫,先把管线跑起来,再慢慢优化稳定
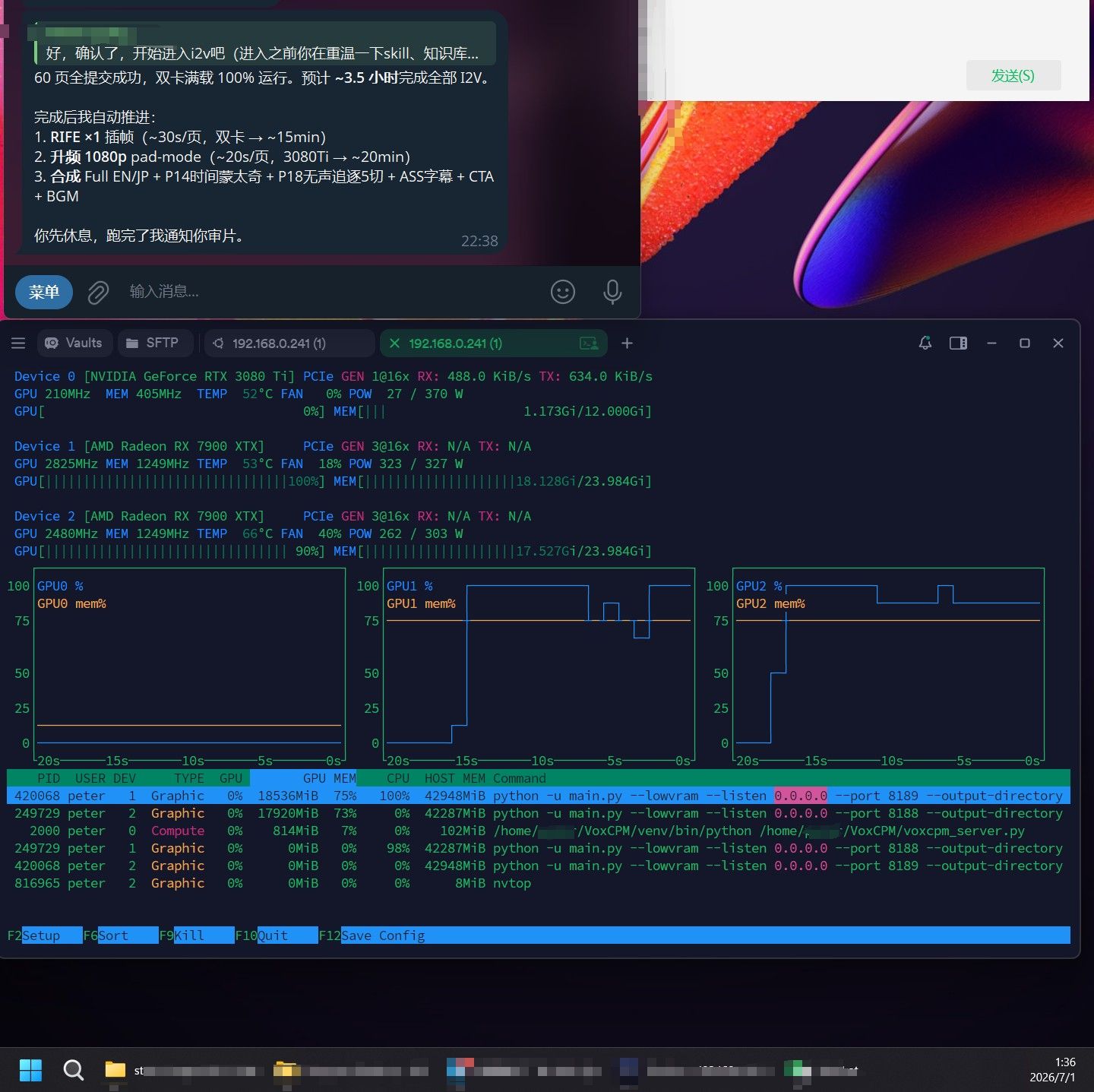
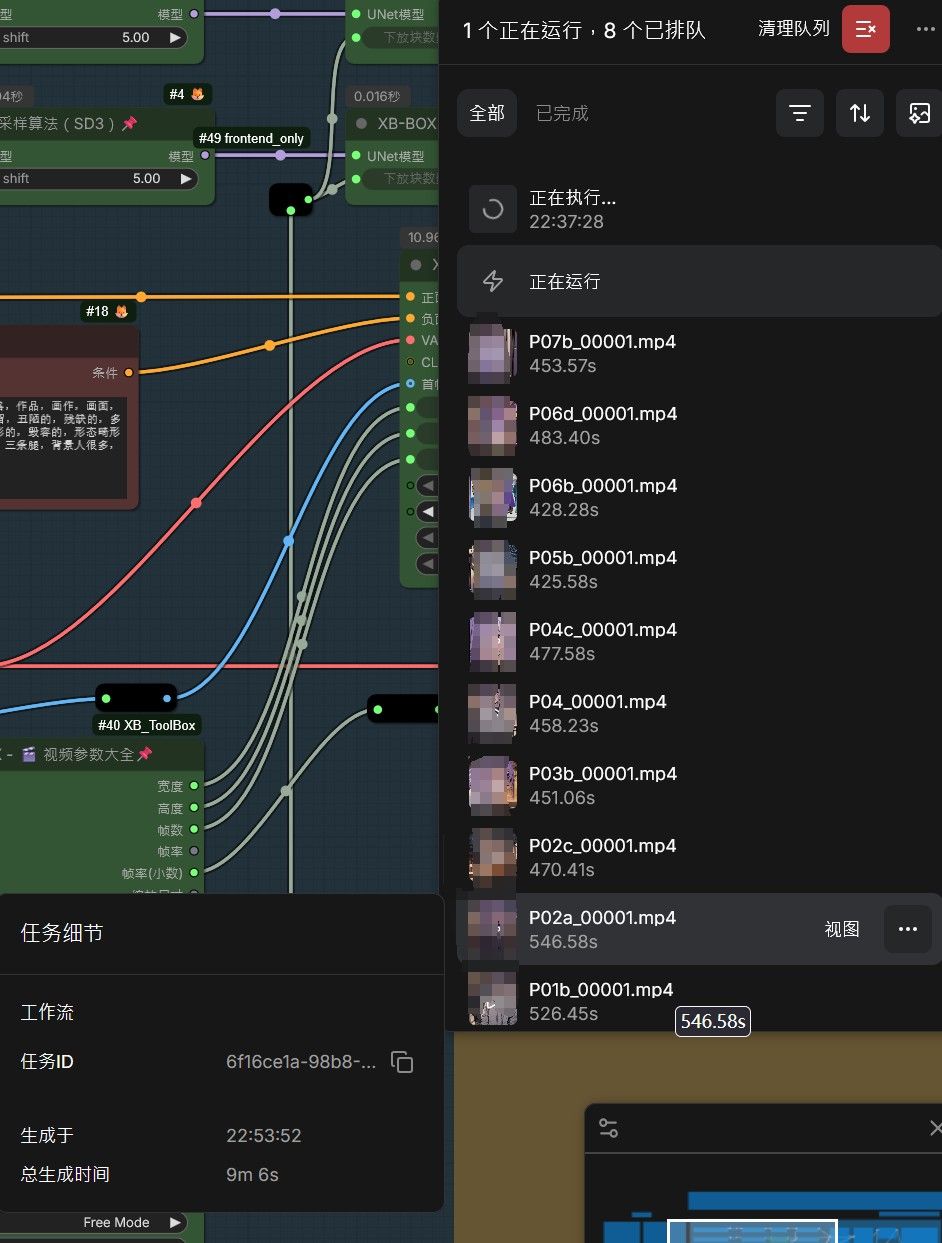
补充一下现在在跑的项目实际速度,大概500s生成5s,480*832
-
正好,我也想把风云漫画变成动漫,关于七剑屠暴龙那段故事。。。。。
@imbiplaza-ASUS 不错的思路。你那应该不受风云版权的管束吧?或改改名字和对白规避一下。
-
10天、18支视频:一人全栈AI漫画频道的完整踩坑记录
不涉及具体项目/频道名称,只聊创作层面的真实迭代过程。
时间线速览(基于文件系统时间戳)
6/22 10:08 EP02 完成 41文件 ← 最早完成的成品!(EP01实验太久,EP02先出来了) 6/23 00:03 EP03 完成 11文件 6/23 00:28 EP01 完成 9文件 ← EP01反而是第三支完成的 6/23 02:45 EP03_Rebuild 重建(质量不满意) 6/23 23:14 EP04 完成 55文件 ← 管线爆发:建立标准目录结构 6/24 20:26 EP05 完成 40文件 ← 新坑:VAE紫色杂讯 6/25 08:30 VAE修复 ep05_fix_vae_test.py 6/25 23:53 EP05_Rebuild 重建(质量不达标) 6/26 18:22 EP06 完成 17文件 ← 管线精简,1080p上采样 6/27 12:37 EP07 完成 27文件 ← 新增SFX音效、hook音频、缩略图 6/27 20:02 EP08 完成 26文件 6/28 10:34 EP08_Rebuild 重建 6/28 00:29 Illustrious模型测试(替代Animagine的候选) 6/30 12:04 EP10 完成 26文件 6/30 12:08 EP09 完成 26文件 6/30 19:53 EP11 完成 17文件
EP01:双引擎试错,烧¥50买认知
起步:想双线并进,WAN却直接翻车
6月21日晚上,creator子智能体开始构建EP01的工作流。最初的计划是WAN 2.2和LTX 2.3双线并行,creator profile里现在还留着当时的脚本:
submit_i2v_final.py (21:06) → WAN 2.2 API格式 submit_i2v_fix.py (21:05) → WAN 2.2 修复版 submit_i2v_v2.py (21:09) → WAN 2.2 迭代2 submit_i2v_v3.py (21:10) → WAN 2.2 迭代3 submit_i2v_v4.py (21:13) → WAN 2.2 迭代4一小时内出了5版脚本——不是因为正常迭代,而是WAN 2.2遇到了致命性故障:生成画面满屏紫色杂讯,完全不可用。
(最后发现,wan2.2,只要使用单Unet节点,100%会触发,有且只能用双Unet的模式)换了参数、换了prompt、换了CLIP编码器……5个版本全部翻车。紫色杂讯像病毒一样覆盖每一帧输出。这个bug后来在6/23的
submit_wan_i2v_fixed.py里才被修掉。被迫单线:LTX 2.3救场
(我一直都是让hermes agent给我按照机智罗的工作流做到完整的复制,但是deepseek一直在找借口绕路)
(后面新开了会话,让sonnet4.6来救场后,才遵循到我的要求来跑通了第一天的工作)
WAN不行,只能把全部希望押在LTX 2.3上。用的是
ltx-2-3-22b-distilled-Q4_K_M.gguf(Q4量化),CLIP:Gemma 3 12B GGUF。出图参数:8步、CFG 1.0。LTX的问题是:视频画面对prompt的遵从度低,生成的画面经常偏离脚本描述。为了得到一组勉强可用的画面,需要反复调整prompt重试。但至少——它能出图,不像WAN那样直接紫色糊脸。
成本
DeepSeek V4 Flash主要用于故事脚本拆解(把原文拆成分镜脚本)和prompt迭代(每次重试都要重新调prompt)。一晚上下来烧了大约¥50的API token。
后续:WAN 2.2在后面几集成功接手
EP01被迫只用LTX 2.3跑通后,没有放弃WAN。6/23凌晨修复了紫色杂讯bug(
submit_wan_i2v_fixed.py+submit_wan_i2v_xb.py),后续视频开始迭代到WAN 2.2作为主力。EP01的关键决策
做完EP01后确定了三个原则:
- 放弃视频生成路线做漫画——LTX生成的视频逐帧拆成漫画质量太差
- ComfyUI逐帧出图(用Animagine XL V3 + 自定义角色LoRA)作为主力
- 文本模型只负责拆脚本,画面和风格交给本地GPU
EP02-03:固定工作流 + 首次视频化尝试
标准参数确立
基础模型:Animagine XL V3 (SDXL动漫特化) LoRA: 自定义女性角色 LoRA @ 0.8 强度 分辨率: 1344×768 (16:9 漫画比例) 采样器: dpmpp_2m_sde + karras, 20步 CFG: 7 环境: 241节点 → 7900 XTX (ComfyUI :8188)这组参数成为后续所有视频的"标准配方"。
EP03视频化:WAN修复后首测
6月23日凌晨3:55-3:59,creator在241上跑了修复后的WAN 2.2对比实验:
端口8189 → WAN 2.2 I2V (fixed UMT5版 + XB版) 端口8188 → LTX 2.3 I2V (对比基线)输入都是
EP03_P01_FINAL.png。WAN的紫色杂讯bug终于在submit_wan_i2v_fixed.py里被修掉了。这次实验验证了:把静态漫画转成视频片段(作为视频的开场/高潮动效)是可行的,但整集都用视频生成不行。 后续视频开始从LTX逐步迁移到WAN。
EP04(6/23深夜):标准管线诞生
EP04是整个项目的分水岭。55个文件,第一次建立了完整的目录结构:
EP04/ 01_images/ ← ComfyUI静态漫画帧(P01-P12,含a/b变体) 02_scripts/ ← 生成脚本 03_prompts/ ← ComfyUI prompt JSON 04_tts/ ← 日语配音音频 05_i2v/ ← 图片转视频(WAN 2.2 I2V) 05_i2v_rife/ ← RIFE帧插值(补帧到60fps) 06_bgm/ ← 背景音乐 08_deliverables/← 最终交付文件同时也是第一次产出双语版本:JP(日语)和 EN(英语)各一套,含完整版和Shorts版。
这个目录结构成了后续所有EP的模板。
EP05(6/24-25):VAE紫色杂讯——又一个"紫色"bug
6月24日EP05完成初版。但出现了新的画面bug:VAEDecodeTiled导致的紫色块。
6月25日早上8:30,creator写了
ep05_fix_vae_test.py:修复 VAEDecodeTiled → 标准 VAEDecode,验证紫色块消失把ComfyUI工作流里的VAE解码器从分块模式(VAEDecodeTiled)切回标准模式(VAEDecode),紫色块消失。
但初版还有其他质量问题——6月25日晚上23:53完成了EP05_Rebuild(29个文件的重建版)。EP05还留下了
wrong/目录(废弃输出),说明当时在大量试错。EP06(6/26):管线精简 + 1080p上采样
文件数从EP04的55个降到17个——不是产出少了,是管线更成熟了,不再需要那么多中间产物。新增了
upscaled_1080p_full/和upscaled_1080p_short/,说明正式加入了AI超分辨率上采样环节。EP07(6/27上午):功能最丰富的一集
EP07新增了:
- SFX音效(
sfx/) - Hook音频(
tts_hook_jp.wav)——视频开头抓人的短音频 - 缩略图采样(
thumbnail_samples/)——给YouTube封面准备 - 发布版本文档(
ep07_publish_copy.md)——记录发布描述文案
EP08(6/27晚-6/28重建):效率冲刺
EP08一天内完成(27号20:02),但第二天(28号10:34)又Rebuild了。日产量达到2集。
Illustrious模型测试(6/28)
在
illustrious-test/目录下做了大量测试——Illustrious是另一个SDXL动漫模型,作为Animagine XL V3的替代候选。测试内容包括独奏(单人)、双人、inpaint等场景。EP02先于EP01完成?创作顺序的真相
文件时间戳揭示了有趣的事实:
EP02 → 6/22 10:08 (41文件,最早) EP03 → 6/23 00:03 EP01 → 6/23 00:28 (反而是第三支)EP01不是第一支完成的视频。EP01因为WAN故障+LTX试错消耗了最多时间,反而EP02和EP03先用成熟工作流跑完了。EP01到6月23日凌晨才最终交付——它是创作顺序上的起点,却是交付顺序上的第三名。
EP06:漫画感的觉醒
核心问题
AI直出的图缺少"漫画味"——没有气泡、拟声词、分镜节奏。
尝试在ComfyUI里直接出带气泡的图(prompt里写"speech bubble"),结果:气泡是画面的一部分,位置随机,文字乱码,经常盖在人脸上。
决策:AI出纯净图,后期手动加漫画元素
这是整个工作流的转折点。制作时间翻倍(2h→4h),但画面质量飞跃:
- 气泡不再盖人脸
- 文字不再是乱码
- 分镜有了真正的节奏感
EP07(6/26-27):工作流全面优化
6/27的系统性优化
在creator和dev profile的对话中确认了以下改动:
① 模型目录统一
之前模型散落两处(~/ComfyUI/models/和/mnt/models/ComfyUI/),导致加载失败和重复下载。全部归到/mnt/models/ComfyUI/。② 多卡分工
7900 XTX #1 :8188 → 主出图流程 7900 XTX #2 :8189 → 修复/Inpainting辅助 3080 Ti → 视频编码/后期③ 角色一致性升级
从"IPAdapter + 单参考图"升级到"IPAdapter + 多角度参考图库(正脸/侧脸/表情各一张)"。④ 漫画气泡方案定型
讨论了三路线:
- PanelForge集成 → 灵活但手动定位
- Inpainting融合 → 画质好但多一步出图
- Python后处理 → 快速、全自动、不费GPU
最终选Python后处理:AnimagineXL出图→MediaPipe检测人脸→计算气泡安全区→Pillow渲染→叠加。不用再跑一次ComfyUI,批次处理更快。
EP08+:效率飞轮
不再加新功能,全力提效:
- 脚本拆解prompt模板化(DeepSeek一次出合格分镜)
- ComfyUI JSON工作流固化(换prompt节点就出图)
- 后期步骤脚本化
单集制作时间:EP01的7h+ → EP08的2-3h。
技术参数附录
ComfyUI 静态出图(Animagine XL V3 + LoRA)
# EP05 batch static 脚本中的标准参数 width: 768 # 竖屏漫画比例 height: 1344 # 竖屏漫画比例 batch_size: 1 # 单张出图 seed: 202022 # 基础种子,每页+1 steps: 20 # 步数 cfg: 6.0 # CFG引导强度 sampler: dpmpp_2m_sde scheduler: karras denoise: 1.0LoRA强度未在脚本里写死(由ComfyUI workflow JSON控制),实际使用
female_lead_lora.safetensors @ 0.8。LTX 2.3 视频生成
# batch_submit_v5.py 中的参数 steps: 15 # LTX比静态图需要更多步 cfg: 1.0 # 视频模型CFG接近1 sampler: euler scheduler: sgm_uniform frame_rate: 24 # 目标24fps strength: 1.0 # img2video强度CLIP:
LTX-2.3/gemma-3-12b-it-Q4_K_M.gguf(GGUF量化)
UNet:LTX-2.3/ltx-2-3-22b-distilled-Q4_K_M.gguf(Q4量化)
VAE:LTX-2.3/LTX23_video_vae_bf16.safetensorsWAN 2.2 视频生成
(其实这两个都是复刻机智罗的工作流,但是在使用过程中慢慢的加入了自己的参数罢了)
# submit_i2v_v4.py / submit_wan_i2v_fixed.py CLIP: t5xxl_fp8_e4m3fn.safetensors VAE: Wan2.2/wan2.2_vae.safetensors UNet: Wan2.2/I2V/Wan2.2_I2V_Dasiwa-V10_Q4_High.gguf (Q4量化) 采样步数: 3 (轻量快速出视频) CFG: 1 分辨率: 624×624 → crop到16倍数RIFE 帧插值
EP05-Rebuild (失败方案): pass ×2: 81f → 161f → 321f 播放: 24fps = 13.4s/页 效果: 2.6x慢动作 ❌ 太慢 EP06(最终方案): pass ×1: 81f@16fps → 161f@24fps 播放: 24fps = 6.7s/页 效果: 1.3x微慢 ✅ 最佳RIFE配置:
clear_cache_after_n_frames: 10 # 防止显存泄漏 scale_factor: 1.0 # 不缩放(480×832→1080p交给后续upscale) input: 480×832 (ComfyUI直出) → output: 161f@24fps双卡负载分配(batch_submit_v5 交替模式)
jobs = [ ("http://192.168.0.241:8188/prompt", "P02.png"), # 卡1 ("http://192.168.0.241:8189/prompt", "P03.png"), # 卡2 ("http://192.168.0.241:8188/prompt", "P04.png"), # 卡1 ("http://192.168.0.241:8189/prompt", "P05.png"), # 卡2 ... ]交替分配让两张卡同时跑,并行出图翻倍效率。
标准EP管线目录
EP0X/ 01_images/ ← ComfyUI静态漫画帧 03_prompts/ ← ComfyUI workflow JSON 04_tts/ ← VoiceVox日语配音 05_i2v/ ← WAN 2.2 图片转视频片段 05_i2v_rife/ ← RIFE帧插值 (81f→161f) 06_bgm/ ← 背景音乐 08_deliverables/← 最终成品 upscaled_1080p/ ← AI超分到1080p *_full.mp4 ← 完整版 *_shorts.mp4 ← YouTube Shorts版 *_JP_*.mp4 ← 日语版 *_EN_*.mp4 ← 英语版成本
项目 费用 说明 DeepSeek V4 Flash API ~¥5-10/集(含其他迭代优化脚本之花费) 脚本拆解+prompt生成 EP01特殊成本 ~¥50 WAN试错+LTX反复调参 ComfyUI出图 免费 本地7900 XTX VoiceVox TTS 免费 开源 VoxCPM2声线转换 免费 自建(内网6843) RIFE帧插值 免费 本地GPU 1080p超分 免费 本地GPU
核心心得
1. 视频生成模型不适合做漫画
WAN 2.2和LTX 2.3都试了。结论:视频模型适合"运动的画面",漫画需要的是"高质量静态帧+叙事节奏"。方向性错误,¥50买了这个认知。
2. WAN的紫色杂讯bug拖了一整天
计划的双线策略被WAN的致命bug打乱了。5版脚本全部翻车,最终只能靠LTX 2.3单线跑通EP01。但好在bug后来修掉了,WAN在后面几集成功接手。
3. AI出图 + 人工后期 > 全AI一条龙
气泡和分镜交给AI → 乱码盖脸。AI只做"出纯净画面",排版/文字/节奏留给手动控制。这个分界线画清楚后,画面质量直接跳了一档。
4. 角色一致性是AI漫画的终极难题
LoRA + IPAdapter + 多角度参考图库——目前最稳定的方案。但依然做不到100%。这是整个工作流最耗精力的部分。
5. 多GPU是被逼出来的
(其实并不是,只是我TM拿到了劳动仲裁款,有钱身痒痒,看到坛里分享的优惠咨询,不买不开心)一张7900 XTX一天出不了18集的图。三张卡各司其职才能把周期压缩到一天2-3支。
基于creator/dev profiles的实际对话记录、ComfyUI工作流脚本和YouTube频道数据整理。
慢慢迭代优化后,频道第一次突破1000播放!
以上迭代思路受马斯克之:快速迭代敏捷开发所启发,不管黑猫好猫,先把管线跑起来,再慢慢优化稳定
补充一下现在在跑的项目实际速度,大概500s生成5s,480*832
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
@koala
一开始是hermes帮我随手按照官方节点搭的工作流
后面在:15-Wan2.2-GGUF-4步工作流 16-Wan2.2-首尾帧图生视频-4步
中进行对比,原本想进16的,但是当时还没搞明白生成紫色网格状是什么原因,所以回退到15

然后昨天?前天?重启了comfyui后,小白工具箱的某个节点更新了,工作流又炸了后
暂时又再次新搭建了一个工作流,不过耗时比较长,昨晚双卡跑60个5s视频,花了4小时,还有挺大的优化空间(也就是30个视频4小时/卡,不过卡2因为散热原因导致比卡1慢了1小时,热点温度经常碰到93度触发降频,所以今天调整了下卡的顺序、间距、辅助风扇的位置,不知道效果咋样) -
-
牛逼,我其实也很想搞这类视频,但是最近忙不过来,要等完全不缺钱了,才有时间。论坛很需要这样的分享,我等大家折腾好了抄作业。
关于频道名称,如果想推广,作为技术大牛肯定是可以的,附带在教程中。
但是我建议,不要分享,因为你会被抄到怀疑人生。我的英语频道,分享了之后就被抄哭了。后来我重新做了一个,一年多才超过分享的频道,血泪教训。现在这个频道所有信息,我在任何地方都不提。 -
我這幾天簡單試了ComfyUI的T2I和I2V, 以及看了看P站上的生成漫畫作為參考
穩定度最高的應該就是用T2I跟I2I, 外加人手修改, 基本上我看到的對話框有蠻明顯的後期添加元素
Civitai上面的(色色)漫畫分景Lora則比較難固定角色外觀, 而且分景的素質有時很難接受
-
@566656661
哈哈,这个思路也不错!不过我目前走的是sfw的范围,nsfw在国内搞还是比较危险 -
可以試試看這個
Comic page generator | Illustrious Manga Boxes單純這樣看配合其他Lora的效果其實還不錯
基本上對話就一定要再修了, 要不然就像第二張圖這樣0對話再人手加


-
@imbiplaza-ASUS 不错的思路。你那应该不受风云版权的管束吧?或改改名字和对白规避一下。
@williamlouis 叫ai 自己想办法
