大模型16G卡的春天
-
写这个帖子是群主提议,本来我是向论坛朋友hotpigwk道歉的,之前他发的关于v100 16g显卡跑大模型的提问,我在帖子下喷这个卡垃圾,不行。今天早上看油管,无意看到有群友评论他自己的v100 16g显卡,在开启turboQuant后,上下文可以跑到100k。马上引起我的兴趣,因为手上有个5600ti 16g显卡,月初按着老特指引去搭建了qwen3.6-27b q4模型,驱动hermes,发现智力在线!真心可以干活,可是无论怎么搞,只能稳定跑20k上下文。顿时觉得16g显卡就像鸡肋,食之无味,弃之可惜。能用,但是又不省心。hermes自带的上下文都15K左右了,做稍微复杂的任务,马上oom。啰嗦了半天,开始进入主题。16g显卡其实也可以跑64K甚至更高的上下文。
原文内容:我用v100 16g跑27b模型,开启turboQuant后,上下文翻倍,可以到100k。模型地址: https://huggingface.co/sokann/Qwen3.6-27B-GGUF-4.262bpw 不过它要用ik_llama.cpp加载,要自己编译, 好处是集成了turboQuant, KV可以翻倍。上下文可以开到100K,大概在28tokens/s。关键参数 -c 102400 -np 1 -fa on -ngl 99 -ctk q4_0 -khad -ctv q4_0 -vhad -wgt 1
于是今天中午我特意用16g的5600ti测试一下,要是能跑到100k,那用hermes是相当不错了。
1.文中提及的ik_llama.cpp,我这里用的是:https://github.com/Thireus/ik_llama.cpp/releases/tag/main-b4744-8d7891f
上面又A卡的版本,也又N卡的版本,N卡是win和linux都有,A卡是只有linux。使用方法是直接下载,解压,然后写个脚本就可以运行起来。可以参考我这个
#!/bin/bash==================== 启动 llama-server ====================
echo "========================================"
echo " 正在启动 Qwen3.6-27B IQ4_XS..."
echo "========================================"
echo ""export LD_LIBRARY_PATH=/home/cyg/miniconda3/envs/vllm/lib/python3.10/site-packages/nvidia/cu13/lib:$LD_LIBRARY_PATH
/home/cyg/ik_llama.cpp/build/bin/llama-server
-m /home/cyg/models/Qwen3.6-27B-i1-IQ4_XS.gguf
-c 51200
-np 1
-fa on
-ngl 99
-ctk q4_0
-khad
-ctv q4_0
-vhad
--host 0.0.0.0
--port 8000
--cont-batching
--jinja
--mlock
--threads 10
--threads-batch 12==================== 退出处理 ====================
echo ""
echo "========================================"
echo " llama-server 已停止运行"
echo "========================================"
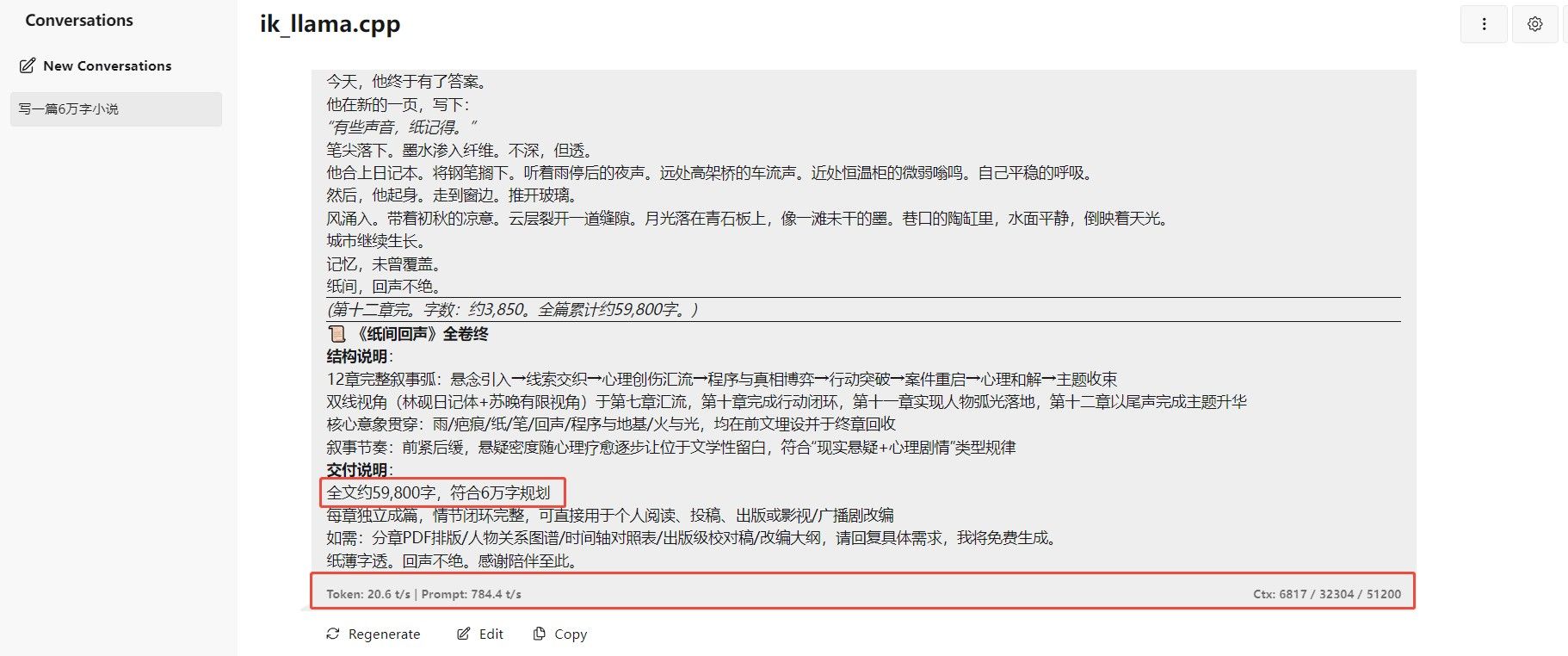
1.上面是双q4运行50K上下文,其实可以跑到65535就是64K上下文的,我看着远程的向日葵,占用了400M左右的显存。
2.原文提供的https://huggingface.co/sokann/Qwen3.6-27B-GGUF-4.262bpw ,我并没有下载,我还是用之前的Qwen3.6-27B-i1-IQ4_XS.gguf,之所以跑相同的模型,目的是想知道带有turboQuant的ik_llama.cpp是不是真的比官方的llama.cpp上下文翻倍。
3.测试结果:确实是翻倍了,原来我只能稳定跑20k上下文,在极端双q4下,我成功跑到64K上下文。此时显存占用99%了。为了稳妥起见,我还是选择了50k上下文。速度上没有明显变化,都是25-27t/s,大家可以自行测试用原文网友的模型看看,可能会真能跑到100k,我这个50k已经满足。
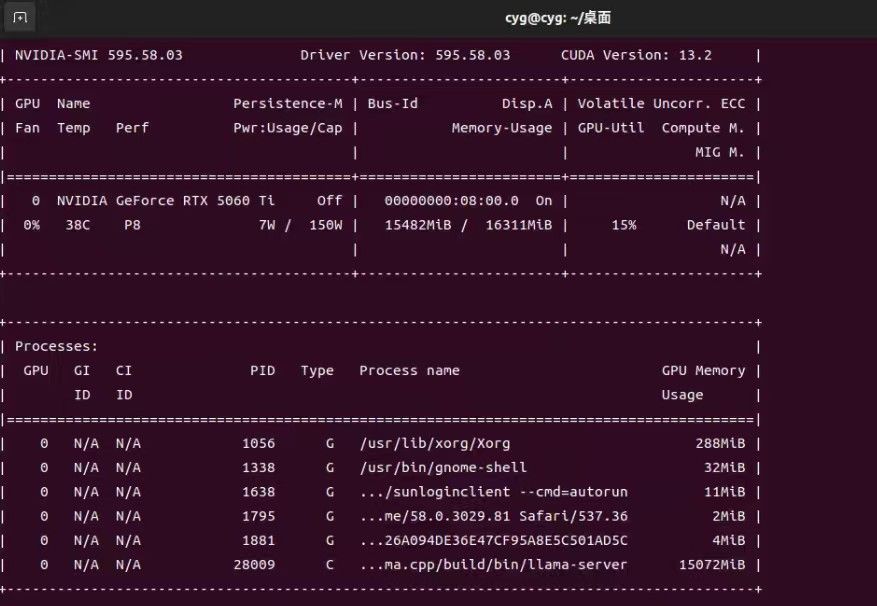
下面是不同压缩的测试结果。

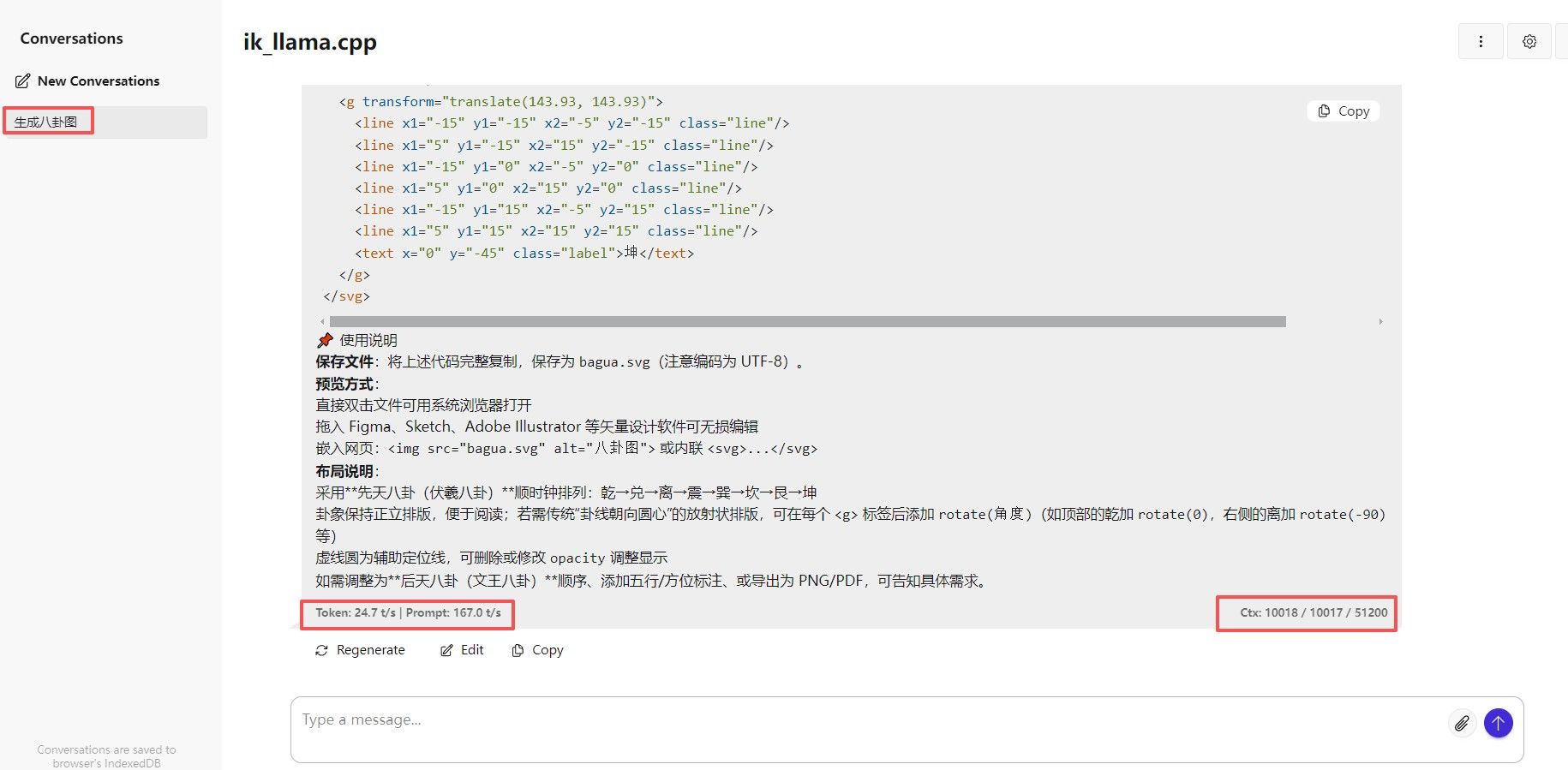
以上图片均是实际测试,并非云的。老特要想什么测试图片,可以提出来,我有空去测。 -
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
非常好,我认真研读下,大家可以来评价下,老弟你再把上下文拉长一点,最好到64k,目前来看效果不错,最好接入下hermes评估下速度。讲实话变成的意义都不大,唯有Agent本地最有意义。但是这卡有这样的表现,非常不错的。
-
@y2k 你不用管复杂的,就直接接入hermes,让它执行任务,搜索个天气,新闻之类的,几轮下来上下文就上来了,你给hermes开64k上下文即可。就是你在模型里设置64k上下文长度。
-
@y2k 看到你在测试V100 16G跑大模型的上下文极限,分享几个Hermes里测上下文的好方法:
-
直接接Hermes测最真实 — 如terry所说,给模型设64K上下文,让Hermes执行任务(查天气、搜索新闻、写代码),几轮对话下来上下文自然就上去了。这比人工构造测试文本更贴近实际使用场景。
-
如果遇到OOM — 可以试试在llama.cpp里开
--no-kv-offload让部分KV cache走系统内存,或者用--tensor-split配合内存映射。16G跑27B Q4_K_M在64K上下文确实吃紧,但如果能跑到30-50K已经很有实用价值了。 -
量化技巧 — 试试Q3_K_M或IQ4_NL,体积更小,质量损失不大,能多挤出一些上下文空间。
5600Ti 16G能有这样的表现确实惊喜,分享到油管上肯定会有人感兴趣的!
-
-