来交作业了,华南金牌X99套装+RTX3090Ti+RTX3060双卡装机完毕
-
折腾了几天,踩了无数坑:
1、windows10的电源一定要用卓越性能,不然GPU的频率根本跑不起来,会被限制到180w左右
2、cmake编译llama.cpp不要抄作业(反正我本人没搞定,自己编译的能跑但是最多不到10tokens/s),直接用官方https://github.com/ggml-org/llama.cpp/releases的版本,3090下Windows x64 (CUDA 12)
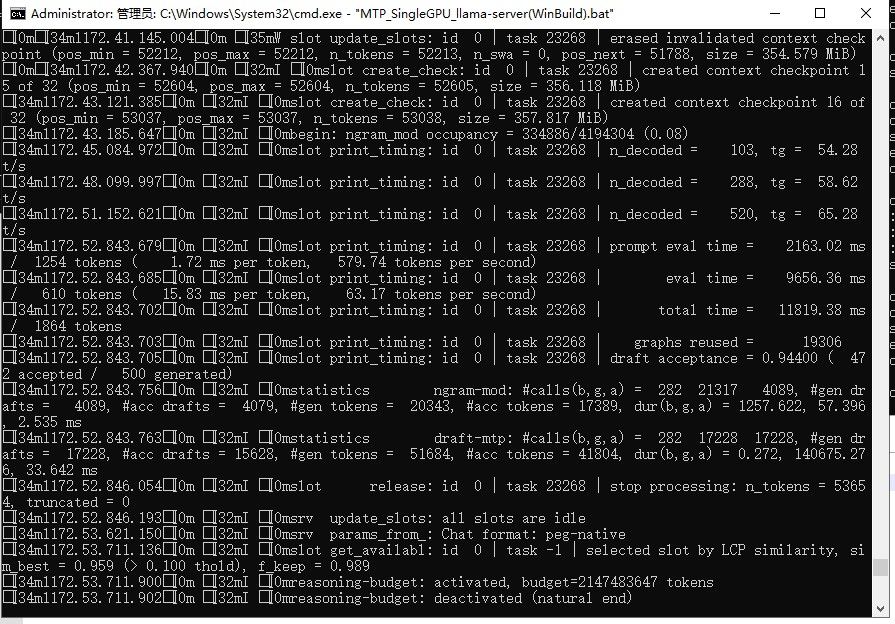
3、官方编译的版本能Qwen3.6 27B跑到35tokens/s,不过MTP没什么效果,我跑unsloth的MTP版本Qwen3.6 27B,也就只能跑到37tokens/s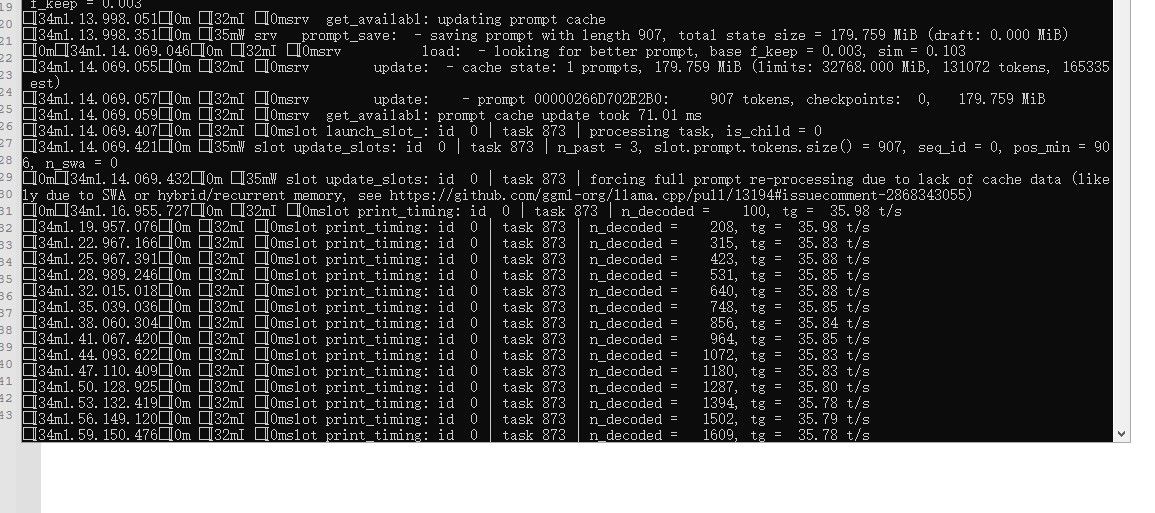
-
折腾了几天,踩了无数坑:
1、windows10的电源一定要用卓越性能,不然GPU的频率根本跑不起来,会被限制到180w左右
2、cmake编译llama.cpp不要抄作业(反正我本人没搞定,自己编译的能跑但是最多不到10tokens/s),直接用官方https://github.com/ggml-org/llama.cpp/releases的版本,3090下Windows x64 (CUDA 12)
3、官方编译的版本能Qwen3.6 27B跑到35tokens/s,不过MTP没什么效果,我跑unsloth的MTP版本Qwen3.6 27B,也就只能跑到37tokens/s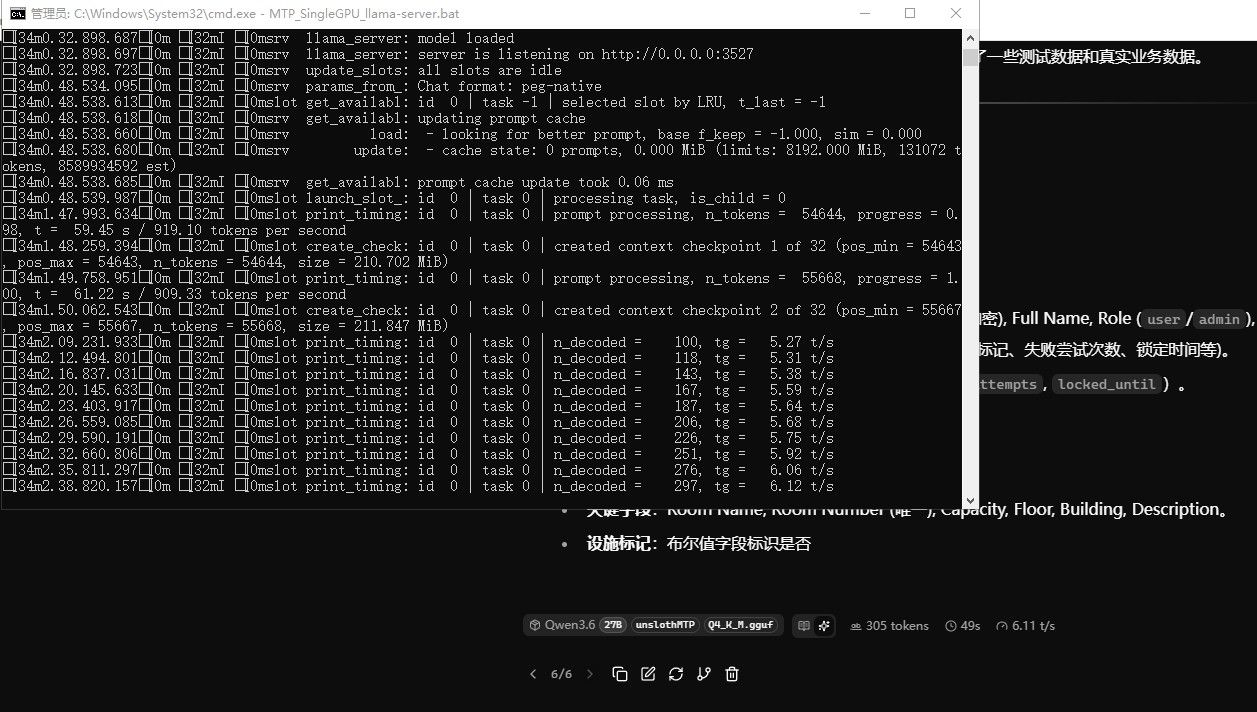
这是我自己编译的llama.cpp
同样的模型,同样的硬件,同样的启动脚本,差别简直了......
这是https://github.com/ggml-org/llama.cpp/releases/download/b9305/llama-b9305-bin-win-cuda-12.4-x64.zip的
哎~
-
折腾了几天,踩了无数坑:
1、windows10的电源一定要用卓越性能,不然GPU的频率根本跑不起来,会被限制到180w左右
2、cmake编译llama.cpp不要抄作业(反正我本人没搞定,自己编译的能跑但是最多不到10tokens/s),直接用官方https://github.com/ggml-org/llama.cpp/releases的版本,3090下Windows x64 (CUDA 12)
3、官方编译的版本能Qwen3.6 27B跑到35tokens/s,不过MTP没什么效果,我跑unsloth的MTP版本Qwen3.6 27B,也就只能跑到37tokens/s@joker_chang 你MTP没设置好, 你看看我的帖子
-
折腾了几天,踩了无数坑:
1、windows10的电源一定要用卓越性能,不然GPU的频率根本跑不起来,会被限制到180w左右
2、cmake编译llama.cpp不要抄作业(反正我本人没搞定,自己编译的能跑但是最多不到10tokens/s),直接用官方https://github.com/ggml-org/llama.cpp/releases的版本,3090下Windows x64 (CUDA 12)
3、官方编译的版本能Qwen3.6 27B跑到35tokens/s,不过MTP没什么效果,我跑unsloth的MTP版本Qwen3.6 27B,也就只能跑到37tokens/s -
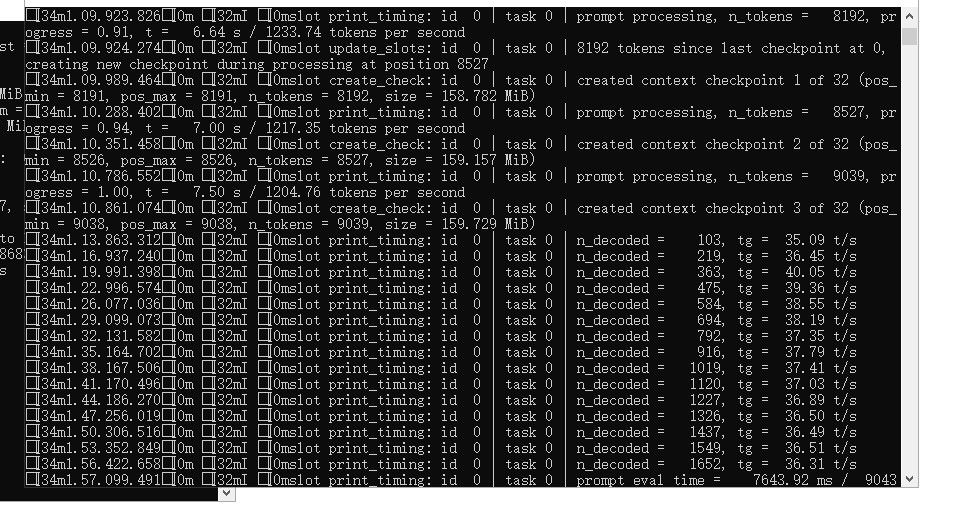
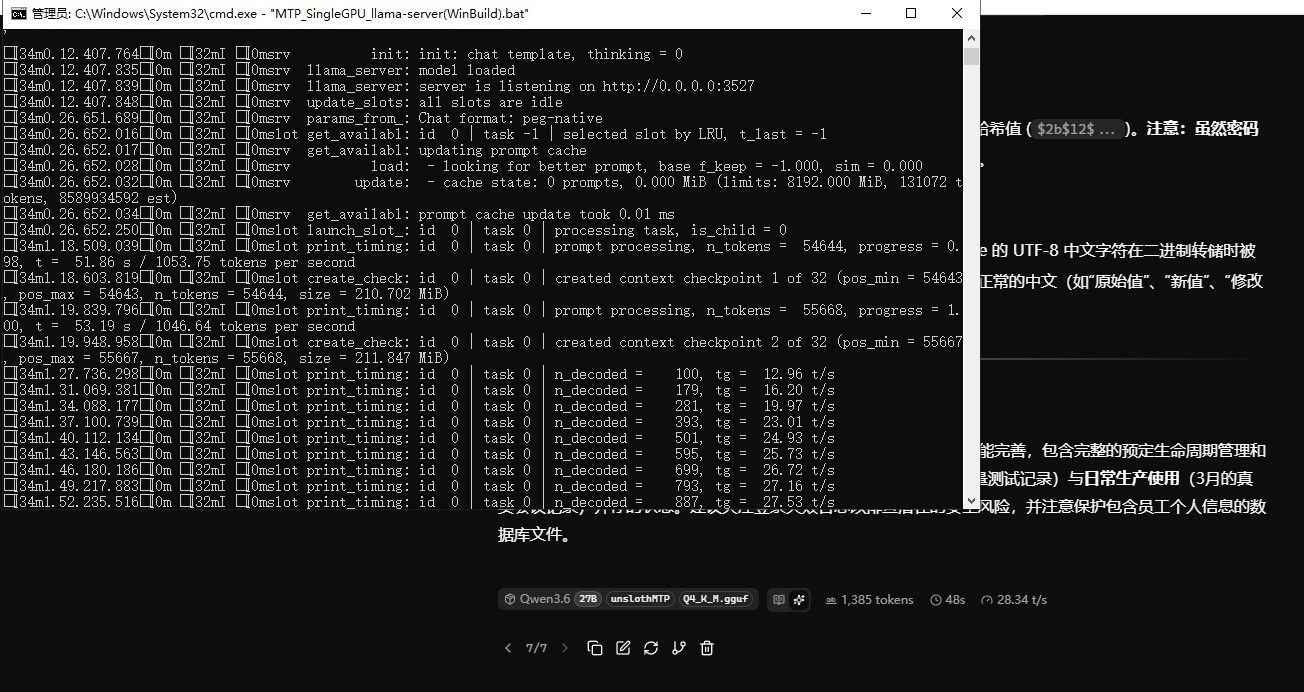
@joker_chang 3090跑qwen27b,mtp理论上应该55-60t/s。
你可以丢给AI让他帮你改一下启动代码。@rock-shi 经过论坛大神的指点(--ubatch-size 1024),和自己不断的折腾,能达到这个值了。
启动参数:
--host 0.0.0.0 ^
--port 3527 ^
--reasoning off ^
--n-gpu-layers -1 ^
--ctx-size 131072 ^
--batch-size 2048 ^
--ubatch-size 1024 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--spec-type draft-mtp,ngram-mod ^
--spec-draft-n-max 3 ^
--spec-ngram-mod-n-max 5 ^
--spec-ngram-mod-n-min 3 ^
--temp 0.7 ^
--parallel 1 -
@rock-shi 经过论坛大神的指点(--ubatch-size 1024),和自己不断的折腾,能达到这个值了。
启动参数:
--host 0.0.0.0 ^
--port 3527 ^
--reasoning off ^
--n-gpu-layers -1 ^
--ctx-size 131072 ^
--batch-size 2048 ^
--ubatch-size 1024 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--spec-type draft-mtp,ngram-mod ^
--spec-draft-n-max 3 ^
--spec-ngram-mod-n-max 5 ^
--spec-ngram-mod-n-min 3 ^
--temp 0.7 ^
--parallel 1将启动脚本和运行日志丢给云端大模型(Qwen3.7-Max)分析,被告知:
一、“日志显示 ngram-mod 的接受率为 0(#acc drafts = 0, #acc tokens = 0),但它仍占用了 16MB 显存和每次推理的检查开销。”
移除:
【
ngram-mod ^
--spec-ngram-mod-n-max 5 ^
--spec-ngram-mod-n-min 3
】二、启用 --kv-unified 以激活 idle slots 缓存
日志警告:【W srv init: --cache-idle-slots requires --kv-unified, disabling】三、增大 Host Prompt Cache 上限
当前仅 8192 MiB(默认值),对于 coding 场景(大量重复系统提示词/代码库前缀)过于保守。因此增加相关参数:【
--cache-ram 32768 ^
--kv-unified
】修订启动参数:
--reasoning off ^
--n-gpu-layers -1 ^
--ctx-size 131072 ^
--batch-size 2048 ^
--ubatch-size 1024 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--spec-type draft-mtp ^
--spec-draft-n-max 3 ^
--temp 0.7 ^
--parallel 1 ^
--cache-ram 32768 ^
--kv-unified感觉修改后,效果并不明显(没有提高也没有下降,正负值在1%上下)......
-
最近也是纠结,手上也是有一张 3060 12g 卡是直接出掉换7900xtx,还是上买一张3060 12g 来,但是换两张3060 主板要换,我的主板小板只有一张16x PCI槽,折腾成本也高,最近在看3090 24g 基本上差不多六千多,跑ComfyUI是我的需求,模型我直接走供应商还比较方便。