RTX 3080 20GB 上以 256k / ~45 tk/s 运行 Qwen3.6-35B-A3B-Q4-K-M(ubuntu)
-
我基本上是按照这个视频中的方法操作的:
https://www.youtube.com/watch?v=8F_5pdcD3HY
我没有 1:1 完全复制,而是以此为主要参考并根据我自己的机器进行了调整。我目前的配置:
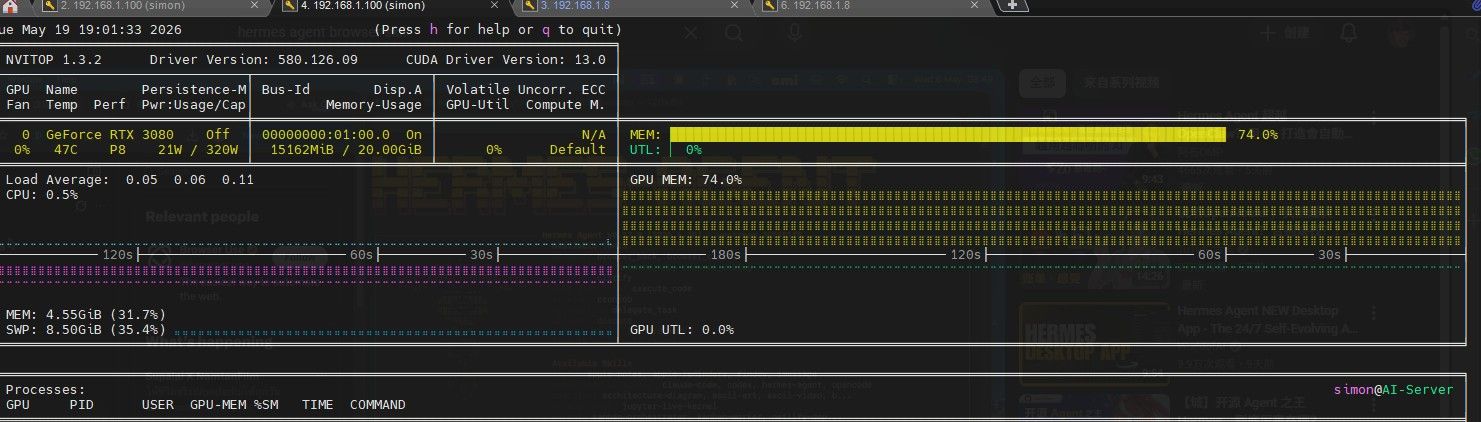
GPU: RTX 3080 20GB
RAM: 15 GB
CPU: i3-10100F
llama.cpp: turboquant 编译版本
https://github.com/TheTom/llama-cpp-turboquant模型 (Model): Qwen3.6-35B-A3B-UD-Q4_K_M.gguf
多模态组件 (mmproj): mmproj-F16.gguf
上下文 (Context): 256k
n-cpu-moe: 15
cache-type-k: turbo4
cache-type-v: turbo3
flash-attn: 开启
目前的结果:
在 256k 上下文下运行稳定
速度大约为 45 tok/s
模型加载时间约为 5 分钟
运行添加 mmproj 后,视觉功能也能正常工作
运行脚本:
#!/usr/bin/env bash
set -euo pipefailMODEL="/mnt/hdd_storage/models/llama.cpp/Qwen3.6-35B-A3B-UD-Q4_K_M.gguf"
SERVER="/mnt/hdd_storage/llama.cpp-turboquant/repo/build/bin/llama-server"
HOST="0.0.0.0"
PORT="9999"
CTX="262144"
THREADS="6"
THREADS_BATCH="6"
BATCH="256"
UBATCH="128"
GPU_LAYERS="99"
CPU_MOE="20"
PARALLEL="2"
CACHE_K="turbo4"
CACHE_V="turbo3"
MMPROJ="/mnt/hdd_storage/models/llama.cpp/mmproj-F16.gguf"
REASONING_MODE="${REASONING_MODE:-off}"exec "$SERVER"
--model "$MODEL"
--host "$HOST"
--port "$PORT"
-ngl "$GPU_LAYERS"
--n-cpu-moe "$CPU_MOE"
-c "$CTX"
-t "$THREADS"
-tb "$THREADS_BATCH"
-b "$BATCH"
-ub "$UBATCH"
-np "$PARALLEL"
--cache-type-k "$CACHE_K"
--cache-type-v "$CACHE_V"
--mmproj "$MMPROJ"
--flash-attn on
--no-warmup
--jinja
--reasoning "$REASONING_MODE"我尝试了运行不同27B模型量化参数但是都不能稳定跑长上下文任务,经常OOM,想说各位老大有没有什么办法。
-
我基本上是按照这个视频中的方法操作的:
https://www.youtube.com/watch?v=8F_5pdcD3HY
我没有 1:1 完全复制,而是以此为主要参考并根据我自己的机器进行了调整。我目前的配置:
GPU: RTX 3080 20GB
RAM: 15 GB
CPU: i3-10100F
llama.cpp: turboquant 编译版本
https://github.com/TheTom/llama-cpp-turboquant模型 (Model): Qwen3.6-35B-A3B-UD-Q4_K_M.gguf
多模态组件 (mmproj): mmproj-F16.gguf
上下文 (Context): 256k
n-cpu-moe: 15
cache-type-k: turbo4
cache-type-v: turbo3
flash-attn: 开启
目前的结果:
在 256k 上下文下运行稳定
速度大约为 45 tok/s
模型加载时间约为 5 分钟
运行添加 mmproj 后,视觉功能也能正常工作
运行脚本:
#!/usr/bin/env bash
set -euo pipefailMODEL="/mnt/hdd_storage/models/llama.cpp/Qwen3.6-35B-A3B-UD-Q4_K_M.gguf"
SERVER="/mnt/hdd_storage/llama.cpp-turboquant/repo/build/bin/llama-server"
HOST="0.0.0.0"
PORT="9999"
CTX="262144"
THREADS="6"
THREADS_BATCH="6"
BATCH="256"
UBATCH="128"
GPU_LAYERS="99"
CPU_MOE="20"
PARALLEL="2"
CACHE_K="turbo4"
CACHE_V="turbo3"
MMPROJ="/mnt/hdd_storage/models/llama.cpp/mmproj-F16.gguf"
REASONING_MODE="${REASONING_MODE:-off}"exec "$SERVER"
--model "$MODEL"
--host "$HOST"
--port "$PORT"
-ngl "$GPU_LAYERS"
--n-cpu-moe "$CPU_MOE"
-c "$CTX"
-t "$THREADS"
-tb "$THREADS_BATCH"
-b "$BATCH"
-ub "$UBATCH"
-np "$PARALLEL"
--cache-type-k "$CACHE_K"
--cache-type-v "$CACHE_V"
--mmproj "$MMPROJ"
--flash-attn on
--no-warmup
--jinja
--reasoning "$REASONING_MODE"我尝试了运行不同27B模型量化参数但是都不能稳定跑长上下文任务,经常OOM,想说各位老大有没有什么办法。
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
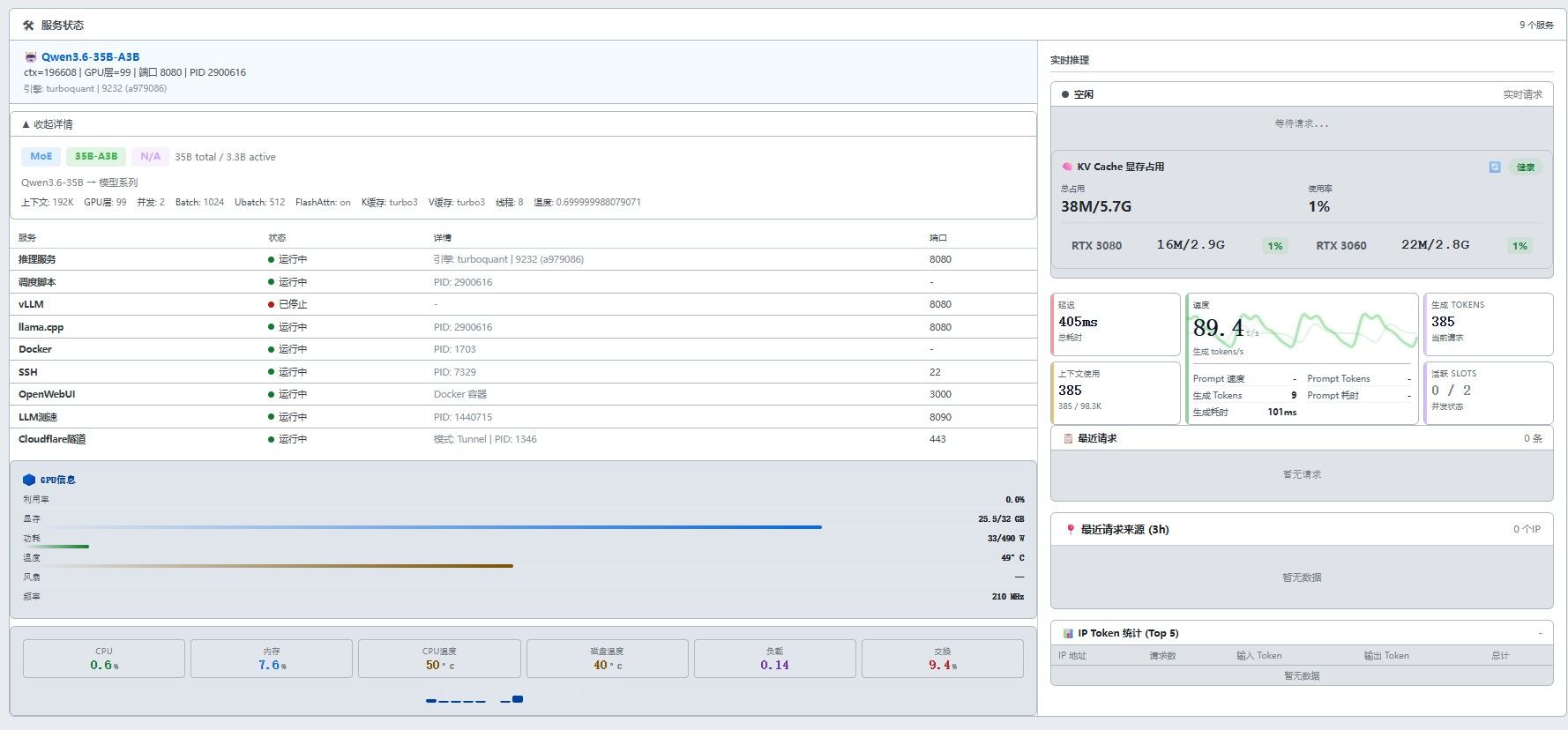
参数信息
Qwen3.6-35B-A3B-MXFP4_MOE-MTP.gguf
ctx=192K
ngl=99
并发=2
GPU=3080+3060
TS=70,30
K=turbo3
V=turbo3
dK=turbo3
dV=turbo3
MTP=2
b=1024
ub=512
FA=on
t=8
temp=0.7 -
参数信息
Qwen3.6-35B-A3B-MXFP4_MOE-MTP.gguf
ctx=192K
ngl=99
并发=2
GPU=3080+3060
TS=70,30
K=turbo3
V=turbo3
dK=turbo3
dV=turbo3
MTP=2
b=1024
ub=512
FA=on
t=8
temp=0.7 -
系统 于 取消固定此主题