
-
生成网页的效果在附件中,有需要的人可以参考下:
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>AI 硬件选型指南 · 正式版(2026年5月)</title> <style> :root { --bg: #0d1117; --card: #161b22; --border: #30363d; --text: #e6edf3; --text-dim: #8b949e; --accent: #58a6ff; --green: #3fb950; --yellow: #d29922; --red: #f85149; --purple: #bc8cff; --orange: #f0883e; --teal: #56d4dd; } * { margin: 0; padding: 0; box-sizing: border-box; } body { font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Helvetica, Arial, sans-serif; background: var(--bg); color: var(--text); line-height: 1.7; } .container { max-width: 1000px; margin: 0 auto; padding: 0 20px; } /* Header */ .header { border-bottom: 1px solid var(--border); padding: 30px 0 22px; text-align: center; background: linear-gradient(180deg, #0d1117 60%, transparent); } .header h1 { font-size: 30px; font-weight: 700; } .header p { color: var(--text-dim); margin-top: 6px; font-size: 14px; } .header .badges { margin-top: 10px; display: flex; justify-content: center; gap: 8px; flex-wrap: wrap; } .badge { display: inline-block; padding: 3px 14px; border-radius: 14px; font-size: 12px; border: 1px solid var(--border); background: #1c2128; color: var(--text-dim); } .badge.green { border-color: #238636; color: var(--green); background: #1a3f2b; } .badge.yellow { border-color: #9e6a03; color: var(--yellow); background: #3d2e00; } .section { padding: 32px 0; border-bottom: 1px solid var(--border); } .section:last-child { border-bottom: none; } h2 { font-size: 20px; font-weight: 600; margin-bottom: 18px; display: flex; align-items: center; gap: 8px; } /* Market Alert */ .alert { background: #3d2e00; border: 1px solid #9e6a03; border-radius: 10px; padding: 14px 18px; margin-bottom: 20px; font-size: 14px; } .alert strong { color: var(--yellow); } /* Tier Cards */ .tier-grid { display: flex; flex-direction: column; gap: 14px; } .tier-card { background: var(--card); border: 1px solid var(--border); border-radius: 10px; padding: 20px 22px; transition: border-color .15s; } .tier-card:hover { border-color: #484f58; } .tier-card .hdr { display: flex; align-items: center; justify-content: space-between; flex-wrap: wrap; gap: 8px; margin-bottom: 8px; } .tier-card .name { font-weight: 600; font-size: 16px; display: flex; align-items: center; gap: 8px; } .tier-card .dot { display: inline-block; width: 10px; height: 10px; border-radius: 50%; flex-shrink: 0; } .tier-card .price-tag { font-size: 13px; color: var(--text-dim); background: #1c2128; padding: 2px 12px; border-radius: 8px; } .tier-card .desc { font-size: 14px; color: var(--text-dim); margin-bottom: 10px; } .tier-card .tags { display: flex; flex-wrap: wrap; gap: 6px; } .tag { font-size: 12px; padding: 2px 10px; border-radius: 6px; background: #1c2128; border: 1px solid var(--border); color: var(--text-dim); } .tag.green { background: #1a3f2b; border-color: #238636; color: var(--green); } .tag.yellow { background: #3d2e00; border-color: #9e6a03; color: var(--yellow); } .tag.red { background: #3d1114; border-color: #ba3c3c; color: var(--red); } .tag.purple { background: #2a1454; border-color: #6e40c9; color: var(--purple); } .tag.teal { background: #003d42; border-color: #0098a1; color: var(--teal); } .tag.orange { background: #3d1e00; border-color: #a45a00; color: var(--orange); } .spec-grid { display: grid; grid-template-columns: repeat(auto-fill, minmax(170px, 1fr)); gap: 6px; margin-top: 10px; } .spec-grid .s { background: #1c2128; border-radius: 6px; padding: 6px 10px; font-size: 12px; } .spec-grid .s strong { display: block; color: var(--text-dim); font-weight: 500; font-size: 11px; } /* Tables */ .tbl { width: 100%; border-collapse: collapse; font-size: 13px; margin-top: 10px; } .tbl th, .tbl td { text-align: left; padding: 9px 12px; border: 1px solid var(--border); } .tbl th { background: #161b22; font-weight: 600; color: var(--text-dim); } .tbl tr:hover { background: #1c2128; } /* Know Items */ .know-list { display: flex; flex-direction: column; gap: 10px; } .know-item { background: var(--card); border: 1px solid var(--border); border-radius: 8px; padding: 14px 16px; } .know-item h3 { font-size: 14px; font-weight: 600; margin-bottom: 4px; } .know-item p { font-size: 13px; color: var(--text-dim); } /* Footer */ .footer { text-align: center; padding: 24px 0; color: var(--text-dim); font-size: 12px; border-top: 1px solid var(--border); } .badge-sm { display: inline-block; font-size: 11px; padding: 1px 8px; border-radius: 4px; margin-left: 6px; font-weight: 500; } .badge-sm.ok { background: #1a3f2b; color: var(--green); } .badge-sm.warn { background: #3d2e00; color: var(--yellow); } @media (max-width: 640px) { .tier-card .hdr { flex-direction: column; align-items: flex-start; } } </style> </head> <body> <div class="header"> <div class="container"> <h1>🖥️ AI 入门硬件选型指南</h1> <p>帮助新手选择合适的硬件体验本地 AI — 明确告知各档位的能/不能</p> <div class="badges"> <span class="badge green">✅ 数据经联网验证</span> <span class="badge yellow">⚠️ 价格为 2026年5月 参考价</span> <span class="badge">正式版 v1.0</span> </div> </div> </div> <div class="container"> <!-- ===== 市场预警 ===== --> <div class="section"> <div class="alert"> <strong>⚠️ 2026年 GPU 市场预警:</strong> NVIDIA 已确认全年游戏 GPU 产量削减 30-40%,AI 需求持续推高显卡价格。 RTX 5090 官方 MSRP $2,000,实际均价已达 <strong>$4,086</strong>。 内存(RAM)同步涨价。二手市场是当前最具性价比的选择。 </div> </div> <!-- ===== 四大路线 ===== --> <div class="section"> <h2>🚀 四大硬件路线</h2> <table class="tbl"> <thead> <tr><th>路线</th><th>代表硬件</th><th>核心优势</th><th>核心劣势</th></tr> </thead> <tbody> <tr><td style="color:var(--green);font-weight:600">N 卡独显</td><td>RTX 3060 / 3090 / 4090</td><td>生态最成熟,CUDA 一统天下</td><td>显存上限卡脖子</td></tr> <tr><td style="color:var(--red);font-weight:600">AMD 独显</td><td>7900XTX / R9700</td><td>性价比高,ROCm 在进步</td><td>生态仍有坑,不如 CUDA</td></tr> <tr><td style="color:var(--teal);font-weight:600">Apple Silicon</td><td>Mac M4 / M5</td><td>统一内存,MOE 大模型强</td><td>稠密模型弱,慢</td></tr> <tr><td style="color:var(--purple);font-weight:600">AI 小主机</td><td>DGX Spark / Strix Halo</td><td>开箱即用,不折腾</td><td>性价比低,生态待验证</td></tr> </tbody> </table> </div> <!-- ===== 各档位 ===== --> <div class="section"> <h2>📊 硬件档位详表 <span class="badge-sm ok">已验证</span></h2> <div class="tier-grid"> <!-- 16G 入门 --> <div class="tier-card"> <div class="hdr"> <span class="name"><span class="dot" style="background:var(--green)"></span> 16G 入门档(尝鲜级)</span> <span class="price-tag">¥1,500-3,000 / $200-400</span> </div> <div class="desc">纯新手第一次接触 AI,想试试水。千元级门槛。</div> <div class="tags"> <span class="tag green">✅ 小模型聊天 7B 以下</span> <span class="tag green">✅ SD 生图(小尺寸)</span> <span class="tag green">✅ 基础语音</span> <span class="tag red">❌ 不能正经干活</span> </div> <div class="spec-grid"> <div class="s"><strong>推荐</strong>RTX 3060 12G 二手 ~¥1,500 / RTX 4060 Ti 16G ~¥3,500</div> <div class="s"><strong>定位</strong>纯尝鲜,体验 AI</div> </div> </div> <!-- 24G 主力 --> <div class="tier-card" style="border-color:var(--yellow)"> <div class="hdr"> <span class="name"><span class="dot" style="background:var(--yellow)"></span> 24G 主力档 ⭐ 最推荐</span> <span class="price-tag">¥6,000-9,000 / $850-1,800</span> </div> <div class="desc">能正经干活,性价比最优解。本地 AI 的黄金分水岭。</div> <div class="tags"> <span class="tag green">✅ Qwen3.6-27B 稠密模型</span> <span class="tag green">✅ 编程、跑 Agent</span> <span class="tag green">✅ ComfyUI 480p 视频</span> <span class="tag green">✅ 画图基本够用</span> <span class="tag green">✅ 绝大多数 AI 日常</span> <span class="tag yellow">⚠ N 卡生态远优于 AMD</span> </div> <div class="spec-grid"> <div class="s"><strong>推荐</strong><b>RTX 3090 24G 二手 ~¥6,000</b> 👈 性价比之王</div> <div class="s"><strong>备选</strong>AMD 7900 XTX 24G ~¥5,500(曾低至 $700)</div> <div class="s"><strong>定位</strong>入门生产力,跑 27B 稠密模型</div> </div> </div> <!-- 32G 舒适 --> <div class="tier-card"> <div class="hdr"> <span class="name"><span class="dot" style="background:var(--orange)"></span> 32G 舒适生产力档 ⭐⭐</span> <span class="price-tag">¥8,000-18,000 / $1,100-2,500</span> </div> <div class="desc">27B-30B 稠密模型的甜点区,128K 上下文吃满。</div> <div class="tags"> <span class="tag green">✅ 27B~30B 稠密模型 128K 上下文</span> <span class="tag green">✅ ComfyUI 720p 视频(10多秒)</span> <span class="tag green">✅ 720p → 1080p/2K/4K 超分</span> <span class="tag green">✅ 人物畸变明显改善</span> <span class="tag red">❌ 魔改卡无保修</span> </div> <div class="spec-grid"> <div class="s"><strong>推荐</strong>RTX 4080S 32G 魔改 ~¥1.25w / AMD R9700 32G ~¥1.1w</div> <div class="s"><strong>定位</strong>舒适生产力,视频创作</div> </div> </div> <!-- 48G 终极 --> <div class="tier-card"> <div class="hdr"> <span class="name"><span class="dot" style="background:var(--red)"></span> 48G 终极生产力档(专业级)</span> <span class="price-tag">¥18,000-30,000 / $2,500-4,200</span> </div> <div class="desc">显存 > 算力。48G 比高算力小显存更重要。</div> <div class="tags"> <span class="tag green">✅ 60B+ 稠密模型量化版</span> <span class="tag green">✅ 超长上下文 256K+</span> <span class="tag green">✅ 1080p 原生视频生成</span> <span class="tag green">✅ 批量任务 / 多任务并行</span> <span class="tag red">❌ RTX 5090 不推荐(游戏溢价严重)</span> </div> <div class="spec-grid"> <div class="s"><strong>推荐</strong>RTX 4090 48G 魔改 <b>~¥1.8w($2,500)</b></div> <div class="s"><strong>备选</strong>RTX Pro5000 48G ~¥3.5w</div> <div class="s"><strong>不推荐</strong>RTX 5090 32G($4,086 实际均价,AI 不如 48G)</div> </div> </div> <!-- 96G 天花板 --> <div class="tier-card"> <div class="hdr"> <span class="name"><span class="dot" style="background:var(--purple)"></span> 96G 专业天花板档(工作站级)</span> <span class="price-tag">¥45,000-55,000 / $6,000-7,500</span> </div> <div class="desc">5万到7万的差距,换来的是生产力级别的跨越。</div> <div class="tags"> <span class="tag green">✅ 百 B 级别稠密模型(量化)</span> <span class="tag green">✅ 超长上下文 1M+ tokens</span> <span class="tag green">✅ 4K 原生视频生成</span> <span class="tag green">✅ 企业级批量任务</span> <span class="tag red">❌ Pro4500 算力落后,别碰</span> </div> <div class="spec-grid"> <div class="s"><strong>推荐</strong>RTX Pro6000 96G ~¥5w(性价比最高)</div> <div class="s"><strong>避坑</strong>Pro5000 72G 性价比一般,不如加钱上 Pro6000</div> </div> </div> </div> </div> <!-- ===== Mac + 小主机 ===== --> <div class="section"> <h2>🍎 Apple Silicon(统一内存路线)<span class="badge-sm ok">已验证</span></h2> <table class="tbl"> <thead> <tr><th>配置</th><th>统一内存</th><th>能跑什么</th><th>说明</th></tr> </thead> <tbody> <tr><td>M4 24G</td><td>24G</td><td>小模型聊天</td><td>入门级,和 16G N 卡同级</td></tr> <tr><td>M4 Pro 32G+</td><td>32G+</td><td>MOE 中等模型</td><td>共享内存优势显现</td></tr> <tr><td>M4 Max 128GB</td><td>128G</td><td>MOE 30B-60B ~16 tok/s</td><td>实测 WizardLM-2 8x22B 4bit</td></tr> <tr><td style="color:var(--teal);font-weight:700">M5 Max 128G</td><td>128G</td><td>MOE 60B-120B</td><td>大模型终极方案(待更多 benchmark)</td></tr> </tbody> </table> <div style="margin-top:10px;display:flex;flex-wrap:wrap;gap:6px"> <span class="tag green">✅ MOE 大模型 Mac 杀手锏</span> <span class="tag red">❌ 稠密模型弱,老旧硬件不推荐</span> <span class="tag yellow">⚠ DGX Spark 推理 ≈ Apple 3 年前水平</span> </div> <h2 style="margin-top:28px">🖥️ AI 小主机实测对比 <span class="badge-sm ok">已验证</span></h2> <div class="tier-grid"> <div class="tier-card" style="border-color:var(--green)"> <div class="hdr"> <span class="name"><span class="dot" style="background:var(--green)"></span> NVIDIA DGX Spark</span> <span class="price-tag">$4,699(涨后价)</span> </div> <div class="desc">GB10 SoC(20 ARM + Blackwell GPU),128GB LPDDR5x(273GB/s),4TB SSD。支持 NVFP4,峰值 1 petaFLOP。</div> <div class="tags"> <span class="tag green">✅ 可跑 200B 模型(4-bit)</span> <span class="tag green">✅ CUDA 生态完整</span> <span class="tag green">✅ CES 2026 更新后性能 +2.5x</span> <span class="tag red">❌ "for the money it's slow"</span> <span class="tag red">❌ 三块二手 3090 组 DIY 比它快</span> </div> </div> <div class="tier-card" style="border-color:var(--red)"> <div class="hdr"> <span class="name"><span class="dot" style="background:var(--red)"></span> AMD Strix Halo 小主机</span> <span class="price-tag">$1,400 - $3,399</span> </div> <div class="desc">16核 Zen5 + RDNA 3.5(40 CU),128GB LPDDR5x,NPU 85 TOPS。ROCm 7.1.1 带来 5.4x ComfyUI 提升。</div> <div class="tags"> <span class="tag green">✅ 多品牌可选(PELADN/X+/GPD/Corsair/ASRock)</span> <span class="tag green">✅ X+ XRIVAL 96GB < $1,500 性价比极高</span> <span class="tag green">✅ 128B 参数模型官方支持</span> <span class="tag yellow">⚠ ROCm 生态仍有坑</span> </div> </div> </div> </div> <!-- ===== GPU 实时行情 ===== --> <div class="section"> <h2>📈 GPU 实时行情表(2026年5月)<span class="badge-sm ok">联网验证</span></h2> <table class="tbl"> <thead> <tr><th>型号</th><th>显存</th><th>官方 MSRP</th><th style="color:var(--yellow)">实际参考价</th><th>备注</th></tr> </thead> <tbody> <tr><td>RTX 5090</td><td>32G</td><td>$2,000</td><td style="color:var(--red);font-weight:600">~$4,086(¥3w)</td><td>AI 需求严重溢价,不推荐</td></tr> <tr><td>RTX 4090</td><td>24G</td><td>$1,599</td><td>$2,000+(¥1.5w+)</td><td>紧俏,5090 替代品</td></tr> <tr><td style="color:var(--green);font-weight:600">RTX 4090 48G 魔改</td><td>48G</td><td>-</td><td><b>$2,500(¥1.8w)</b></td><td>性价比最高的 48G 方案</td></tr> <tr><td>RTX 4080S 32G 魔改</td><td>32G</td><td>-</td><td>~$1,700(¥1.25w)</td><td>魔改无保修</td></tr> <tr><td style="color:var(--green);font-weight:600">RTX 3090 二手</td><td>24G</td><td>$1,499(原)</td><td><b>$850-950(¥6,000-7,000)</b></td><td>🔥 性价比之王</td></tr> <tr><td>RTX 3060 12G 二手</td><td>12G</td><td>$329(原)</td><td>~$200(¥1,500)</td><td>入门尝鲜首选</td></tr> <tr><td>RTX 4060 Ti 16G</td><td>16G</td><td>$499</td><td>$500+(¥3,500+)</td><td>16G 显存新卡入门</td></tr> <tr><td>AMD 7900 XTX</td><td>24G</td><td>$999</td><td><b>$700-1,000</b></td><td>曾低至 $700,性价比高</td></tr> <tr><td>RTX Pro6000 96G</td><td>96G</td><td>-</td><td>~$7,000(¥5w)</td><td>工作站天花板</td></tr> <tr><td>RTX Pro5000 48G</td><td>48G</td><td>-</td><td>~$4,200(¥3w)</td><td>贵但正规</td></tr> </tbody> </table> <div style="margin-top:10px;font-size:13px;color:var(--text-dim)"> 💡 价格数据来源:Tom's Hardware、TechSpot、Reddit r/LocalLLaMA、Hacker News。均为 2026年5月参考价,实际以市场为准。 </div> </div> <!-- ===== LLM 推理性能 ===== --> <div class="section"> <h2>⚡ LLM 推理性能参考 <span class="badge-sm warn">估算值</span></h2> <div class="tier-grid"> <div class="tier-card"> <div class="hdr"><span class="name">RTX 3090 24G 单卡</span></div> <div class="tags"> <span class="tag">Qwen 3-27B Q8: ~12.5 tok/s</span> <span class="tag">32B 模型 Q4: ~20+ tok/s</span> <span class="tag yellow">二手 ¥6,000-7,000</span> </div> </div> <div class="tier-card"> <div class="hdr"><span class="name">RTX 4090 24G</span></div> <div class="tags"> <span class="tag">32B 模型: ~30-40 tok/s</span> <span class="tag">72B 模型 Q4: ~15-20 tok/s</span> <span class="tag red">¥1.5w+ 溢价严重</span> </div> </div> <div class="tier-card"> <div class="hdr"><span class="name">RTX 5090 32G</span></div> <div class="tags"> <span class="tag">32B-AWQ: ~65 tok/s (vLLM, 400W)</span> <span class="tag">Gemma 3 12B: 85 tok/s (Ollama)</span> <span class="tag red">¥3w 实际均价,不值</span> </div> </div> <div class="tier-card"> <div class="hdr"><span class="name">Mac M4 Max 128GB</span></div> <div class="tags"> <span class="tag">WizardLM-2 8x22B MLX 4bit: 16.5 tok/s</span> <span class="tag">M4 Pro 集群 32B: ~18 tok/s</span> <span class="tag teal">MOE 大模型强项</span> </div> </div> <div class="tier-card"> <div class="hdr"><span class="name">DGX Spark 128GB</span></div> <div class="tags"> <span class="tag">200B 模型 4-bit: 可用但慢</span> <span class="tag red">"for the money it's slow" — 评测</span> <span class="tag red">3×3090 组 DIY > Spark</span> </div> </div> </div> </div> <!-- ===== 核心知识 ===== --> <div class="section"> <h2>💡 核心知识点</h2> <div class="know-list"> <div class="know-item"> <h3>📐 显存为什么重要?</h3> <p>显存 = 模型能塞进去的大小。16G = 小模型聊天,24G = 中大模型干活。显存不够不是慢,是根本跑不了。</p> </div> <div class="know-item"> <h3>🖥️ 操作系统优先级</h3> <p><strong>Linux 🥇</strong> — 兼容性最好,AI 工具原生支持<br> <strong>Windows 🥈</strong> — 整合包一键安装,入门最简单<br> <strong>macOS 🥉</strong> — 开箱即用,但 AI 生态远不如 Linux/Windows</p> </div> <div class="know-item"> <h3>🛡️ 显卡选购铁律</h3> <p><strong>生态 > 显存 > 算力&带宽</strong><br>NVIDIA >>> AMD > Apple >> Intel</p> </div> <div class="know-item"> <h3>🔑 24G 是分水岭</h3> <p>16G 是玩具,能玩但不能正经用。24G 才能真正跑 27B 级别的稠密模型。</p> </div> <div class="know-item"> <h3>🧠 2026年买卡策略</h3> <p>GPU 涨价+减产背景下:<b>二手 3090 ¥6,000</b> 是当前性价比最优解。预算充足上 4090 48G 魔改 ¥1.8w。5090 游戏溢价严重,不建议为 AI 购买。</p> </div> </div> </div> <!-- ===== 配套硬件 ===== --> <div class="section"> <h2>🔧 配套硬件选购</h2> <div class="know-list"> <div class="know-item"> <h3>🧠 内存(RAM)<span class="badge-sm warn">2026年也在涨价</span></h3> <p><strong>容量 > 带宽 > 频率</strong> · DDR3/4/5 差距不大 · 16G 起步,32G 舒适,48G+ 充裕</p> </div> <div class="know-item"> <h3>⚙️ CPU</h3> <p>8 核心以上够用。CPU 只负责搬运数据,真正计算在 GPU 上。省下的钱加到显卡上。</p> </div> <div class="know-item"> <h3>🔌 主板</h3> <p>PCIE 3/4/5 差距不大(实测 < 2%)。</p> </div> <div class="know-item"> <h3>💾 硬盘(SSD)</h3> <p>SATA SSD 就够了,NVMe 加载更快。512G 起步,1T 舒适。</p> </div> </div> </div> </div> <div class="footer"> <div class="container"> AI 硬件选型指南 · 正式版 v1.0 · 数据验证日期 2026年5月<br> 价格数据来源:Google Custom Search 联网验证 · 价格为参考价,以实际市场为准 </div> </div> </body> </html>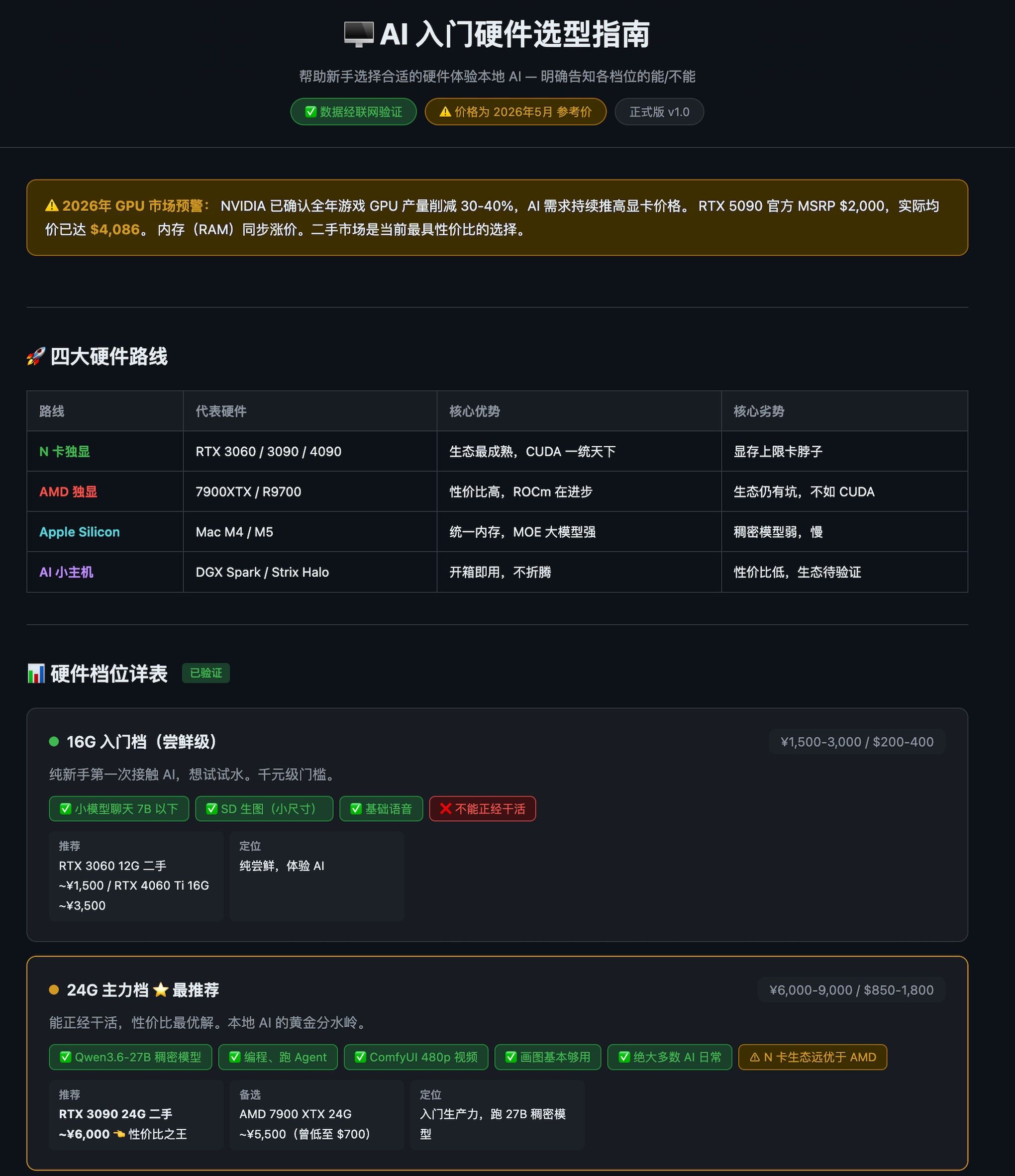
今天16点发布的视频,这是Hermes整理的网页,用户新手小白选择显卡,我感觉基本靠谱,但是有些细节也不行,主要用于展示技术流程。复制到本地,新建一个txt文件,粘贴进去,然后修改文件后缀名为html即可看到效果。 -
RTX3090
git clone https://github.com/TheTom/llama-cpp-turboquant
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Releasellama-cli -m d:\llama.cpp\models\Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf -ngl 99 --no-mmap --mlock --cache-type-k turbo4 --cache-type-v turbo3 --ctx-size 262144 --flash-attn on
Write me a poem
[ Prompt: 187.8 t/s | Generation: 127.0 t/s ]请问这个速度是正常吗?35B 的千问有那么快吗?
-
RTX3090
git clone https://github.com/TheTom/llama-cpp-turboquant
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Releasellama-cli -m d:\llama.cpp\models\Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf -ngl 99 --no-mmap --mlock --cache-type-k turbo4 --cache-type-v turbo3 --ctx-size 262144 --flash-attn on
Write me a poem
[ Prompt: 187.8 t/s | Generation: 127.0 t/s ]请问这个速度是正常吗?35B 的千问有那么快吗?
-
@Sam-Hsu 看了下,现在还是这个价…… 那两家京东自营的公司主体我去查了,也是发包给代工厂的,主体是靠关系拿业务的。问了自营的客服,出问题也不是无脑换新的。非自营的都是2万2、2万3,也都是华强北的,不知道有没有必要额外多花这5000。
-
 T terry 于 引用了 此主题
T terry 于 引用了 此主题
-
RTX3090
git clone https://github.com/TheTom/llama-cpp-turboquant
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Releasellama-cli -m d:\llama.cpp\models\Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf -ngl 99 --no-mmap --mlock --cache-type-k turbo4 --cache-type-v turbo3 --ctx-size 262144 --flash-attn on
Write me a poem
[ Prompt: 187.8 t/s | Generation: 127.0 t/s ]请问这个速度是正常吗?35B 的千问有那么快吗?
-
./llama.cpp/build/bin/llama-server
-m ./models/Qwen3.6-27B-Q4_K_M.gguf
--host 0.0.0.0
--port 8081
--ctx-size 131072
--parallel 1
--cache-type-k q8_0
--cache-type-v q8_0
--flash-attn on
--mlock
--reasoning-budget 07900XTX完全可以跑通,而且体感良好
-
-
看到里面说RTX 6000 PRO 才 4.5W-5.5W。 我想问下在哪里可以搞到这么便宜的啊。
-
看到里面说RTX 6000 PRO 才 4.5W-5.5W。 我想问下在哪里可以搞到这么便宜的啊。
@Chuyao-Chen 骗子哪里
-
看到里面说RTX 6000 PRO 才 4.5W-5.5W。 我想问下在哪里可以搞到这么便宜的啊。
@Chuyao-Chen
阉割版的RTX 6000D 84GB 是这个价格 -
@pilipala 注册资本都很低,用2年没了,你卡坏了,找京东,你是和京东购买的,它必须保你,你不要管京东怎么处理,它会想办法搞定的。2.2我真没看到,淘宝都2.4,京东第三方2.58
-
T terry 于 将此主题从 LLM讨论区 移至此处
-
./llama.cpp/build/bin/llama-server
-m ./models/Qwen3.6-27B-Q4_K_M.gguf
--host 0.0.0.0
--port 8081
--ctx-size 131072
--parallel 1
--cache-type-k q8_0
--cache-type-v q8_0
--flash-attn on
--mlock
--reasoning-budget 07900XTX完全可以跑通,而且体感良好
-
RTX3090
git clone https://github.com/TheTom/llama-cpp-turboquant
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Releasellama-cli -m d:\llama.cpp\models\Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf -ngl 99 --no-mmap --mlock --cache-type-k turbo4 --cache-type-v turbo3 --ctx-size 262144 --flash-attn on
Write me a poem
[ Prompt: 187.8 t/s | Generation: 127.0 t/s ]请问这个速度是正常吗?35B 的千问有那么快吗?
@VS-Studio 很正常,我的amd小主机,780m跑他都有30多 t/s。
