RTX3080 20g,qwen3.6 27B 45-50T/S 35B多模态256K 110T/S
-
我的编译总是出问题。后来看了build.md,用Visual Studio 17 2022,一次编译成功,命令是cmake -B build -G "Visual Studio 17 2022" -DCMAKE_BUILD_TYPE=Release -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=86 -DLLAMA_BUILD_SERVER=ON -DLLAMA_BUILD_ALL_EXAMPLES=OFF -DLLAMA_BUILD_TESTS=OFF -DLLAMA_BUILD_EXAMPLES=OFF
-
系统 取消固定了该主题
-
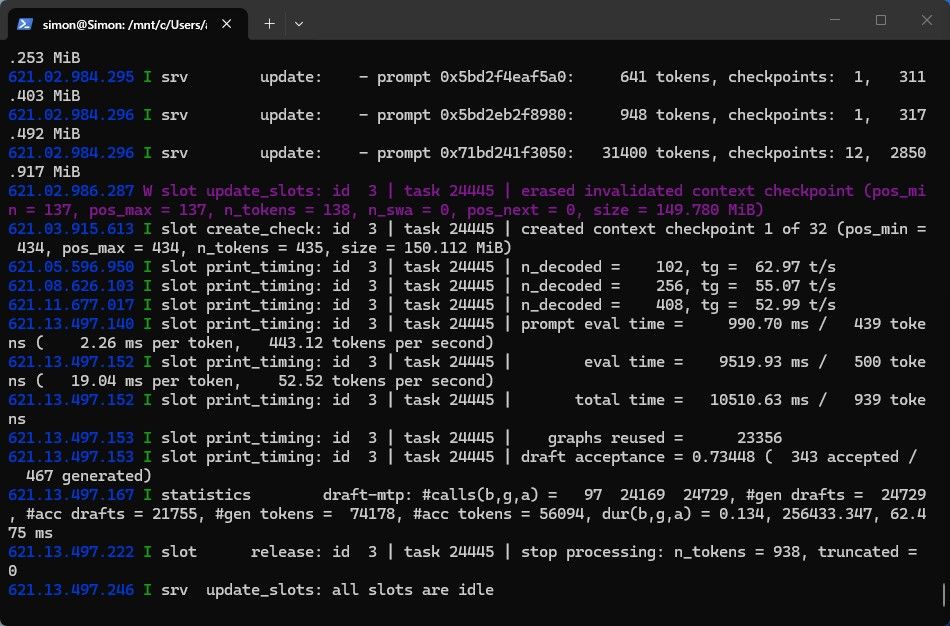
@terry 哈哈,惭愧呀.我哪有什么部署过程啊,无非就是把你这论坛两个帖子发给AI,要他仔细看一遍.然后学你的样使劲骂deepseek v4 flash.让他帮我全部搞定,我只监工.完工后体验是真好,让我不再焦虑64k上下文了.其余变化不大,显存占用比以前少了一点点.参考的另一个帖子是大模型16G卡的春天,但不是同样的llama.cpp.
-
 T terry 固定了该主题
T terry 固定了该主题
-
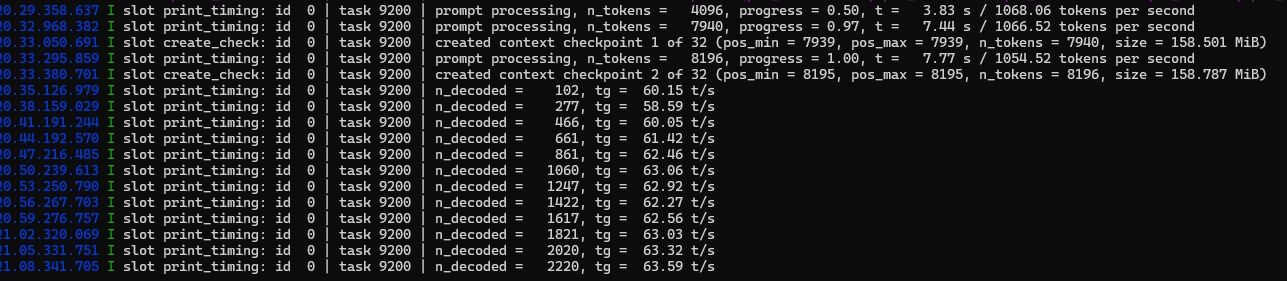
以我这次的折腾,单卡跑27B MTP长期稳定极限是120K上下文,也很容易触发上下文压缩的,不知道有没有大神有解决方法,
我刚才豆包了一下,原来可以将模型权重分别载入两张卡,这样还是有意义啊,但是我主板第二PCIE是3.0的,这就很尴尬了,NVLINK能买到估计也不便宜
-
@vosrock 3080好像没有nvlink
nvlink 现在都在1100+-我就是为了nvlink 多付3000-4000
因为 huananzhi 单路x99 pcie3.0 距离都不适用nvlink...
有点超预算所以有点后悔@applejuice 他说的3090,3090可以nvlink,个人感觉透出产出比不高,没实践过