-
TLDR:新手不要碰DGX Spark(GB10)
DGX Spark的芯片SM121最初的设计是一个 游戏APU和AI 两吃产品,并且跳票了超过一年多(出处:https://youtu.be/o8FL3nVDM5M?si=byA9yR5k0U8MTAI5)。因为游戏APU是需要Windows for Arm的适配,而微软那个屎山Bug巨多无比。所以等不及了,只能先开卖DGX Spark。SM121芯片和NV专业芯片设计有很多区别,导致生态和支持一直有问题(被NV论坛诟病很多),这么小众的产品(而且还是和半成品),你不能指望NV会让团队花很多精力去修正生态问题。 -
版主您好:
1、“抡锤者”每一个视频我都追更、看过,这是目前我最喜爱的AI相关频道,没有之一。
2、首先声明,我只是个自己瞎琢磨一年多的老人(50+),只用过4060卡玩本地,和API用openrouter,主要是写长篇小说。我不是大款,更不是有钱,但就是喜欢玩,所以今天的提问,请千万不要误会、不要喷,谢谢大家。
3、我想本地部署 DeepSeek-V4-Flash,如果可以为了学习自己训练和微调那就最好(纯粹是向往,目前不会),这样既有安全性,也不怕资源消耗。
4、另外就是本地运行Qwen3.6 27b本地跑Hermes,然后就是通过本地部署,做AI音视频画图。所以,我想请问:
1、买 ASUS Ascent GX10 ( NVIDIA DGX Spark)合适么?或者买两台串联?
2、我知道两台 ASUS Ascent GX10 ,可以放 DeepSeek-V4-Flash ,但不知道视频生成怎么样?
3、我从你这里知道,视频生成用 5090 (32G)是极好的。因为目前一块5090的价格和一个ASUS Ascent GX10 (NVIDIA DGX Spark)价格差不多,而买5090我要配一台新机,价格大约5W,这个价格不如我花6W买两台ASUS Ascent GX10 ,然后连接我的老机器。所以特地请教您,请不要笑话

-
我觉得你如果预算够的话肯定上6000不后悔啊,你不算老人(我也50岁瞎折腾两个月了)我也准备搞一台洋垃圾x99-2696v3-ddr3配3090本地跑跑玩,目前手里有台MACmini丐版跑在线模型已经上瘾了哈哈

-
先说说我的需求:我老婆那边有个成形了的做手作玩具的xhs账号,需要“文/图生图”持续产出可能会有版权纠纷的手作玩具图片,图生视频放到笔记里打造爆款,以及图生建模给到她的上游供应链打印模具。我这边用claude code氛围开发的也有两条线:1是上班时期自己想抽空做的个项目,目前已经出了一版正在迭代;还有一个自制的手游app需求也基本上厘清了也在排队;另外社交网络上也有固定自己设计打造的IP尝试做漫画或动画。所以基本上就是claude code/Trae和ComfyUI是硬需求,另外hermes也在玩票,想看能不能固化一些流程。
自己原来有一台9950x + 4090 + 192G内存的台式机,运行ComfyUI生图还行,大量生视频确实力不从心。之前也是想过用DGX Spark来搞定ComfyUI和智能体的推理大模型,就在Gemini,GPT和Grok和豆包都问过同样的一组问题。把自己的实际需求和当前已有的设备统统写进提示词,也是很有意思,看各大知名ai在线给我营业:从DGX vs M3Ultra Studio的Studio胜,然后被gemini推荐RTX Pro系列,到又换MacStudio vs RTX Pro5000/6000各大知名ai又给我营业了几轮,大部分是RTX Pro胜。
然后开始关注这个频道,看完了UP的每期视频和之前老特说的每期视频,下定决心了入的RTX Pro。
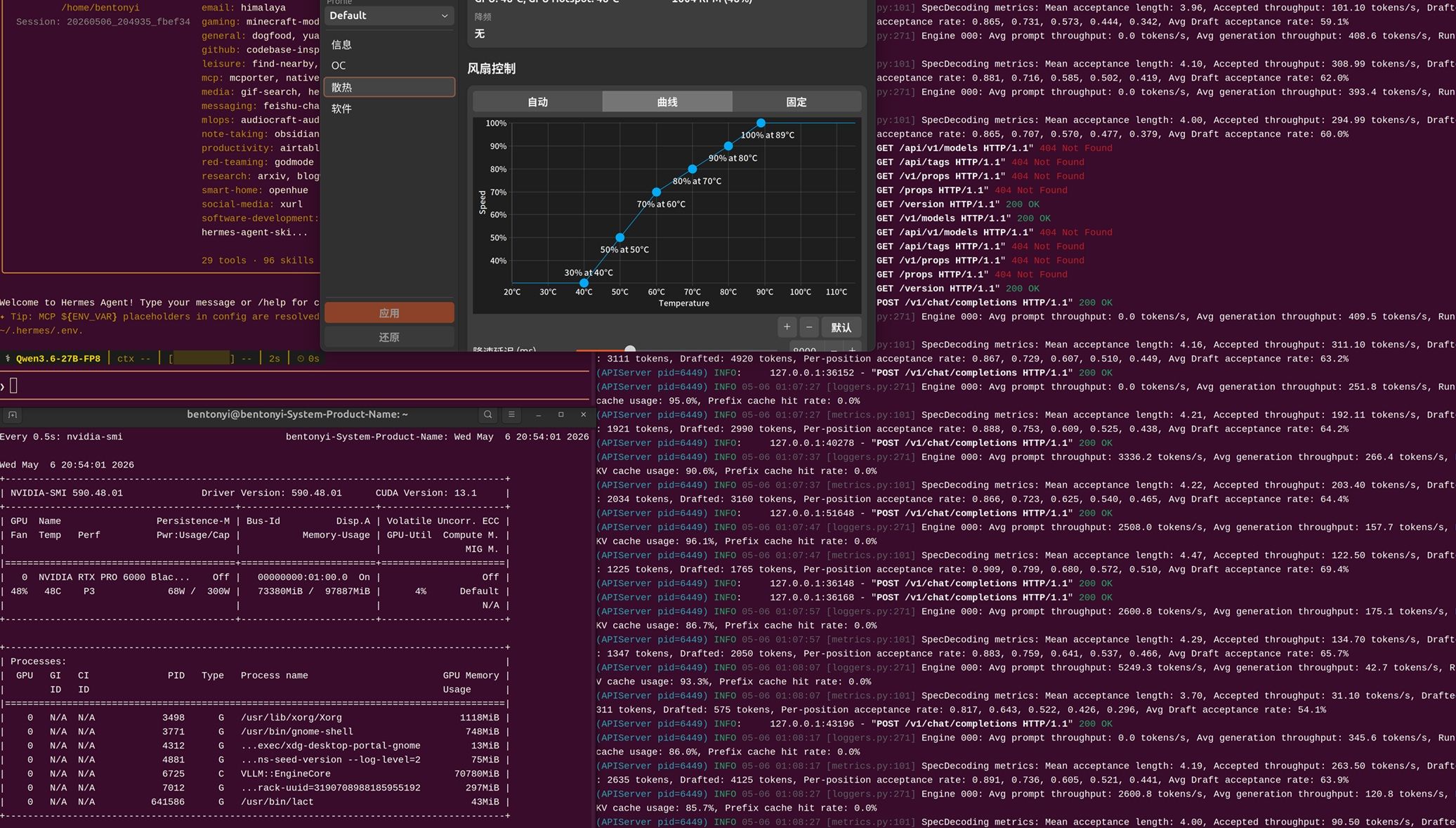
之前在win下面一直用lms试吃,ollama生产(qwen3.6:27b_q8_0上下文256k能到35~38t/s)。系统换到Linux之后ollama确实快了一些。但是在各ai的强烈推荐下,Linux下的生产环境SGLang>vLLM>>llama.cpp>ollama。于是先是尝试docker安装了SGLang,捣鼓了2个晚上装了2次回复都是乱码(后来在论坛发现有人说SGLang框架推理qwen3.6-27b-fp8就是有乱码,要坐等框架更新)。于是开始尝试vLLM,才有了上面的图。运行参数如下:
vllm serve /home/bentonyi/.cache/modelscope/hub/models/Qwen/Qwen3.6-27B-FP8
--trust-remote-code
--quantization fp8
--max-model-len 262144
--enable-auto-tool-choice
--max-num-seqs 32
--tool-call-parser qwen3_coder
--reasoning-parser qwen3
--speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":4}'
--host 0.0.0.0
--port 8000
设置猜字的mtp并发为4的时候,有效token速度可以超过400t/s。本地的hermes速度能达到接近之前用minimax2.7新手包套餐的在线速度,终于可用了。
另:涡轮版本的RTX Pro风扇策略偏静音,不调的情况下工作温度在85~88℃范围。图中的温控工具是LACT,按此设置重度连续工作1小时不会上80℃。省流版:用心写一组提示词,把自己的需求现状和担心的点告诉知名ai众,让它们在线给你营业,然后交叉验证各ai的回答,往往能解决90%以上的问题。

-
先说说我的需求:我老婆那边有个成形了的做手作玩具的xhs账号,需要“文/图生图”持续产出可能会有版权纠纷的手作玩具图片,图生视频放到笔记里打造爆款,以及图生建模给到她的上游供应链打印模具。我这边用claude code氛围开发的也有两条线:1是上班时期自己想抽空做的个项目,目前已经出了一版正在迭代;还有一个自制的手游app需求也基本上厘清了也在排队;另外社交网络上也有固定自己设计打造的IP尝试做漫画或动画。所以基本上就是claude code/Trae和ComfyUI是硬需求,另外hermes也在玩票,想看能不能固化一些流程。
自己原来有一台9950x + 4090 + 192G内存的台式机,运行ComfyUI生图还行,大量生视频确实力不从心。之前也是想过用DGX Spark来搞定ComfyUI和智能体的推理大模型,就在Gemini,GPT和Grok和豆包都问过同样的一组问题。把自己的实际需求和当前已有的设备统统写进提示词,也是很有意思,看各大知名ai在线给我营业:从DGX vs M3Ultra Studio的Studio胜,然后被gemini推荐RTX Pro系列,到又换MacStudio vs RTX Pro5000/6000各大知名ai又给我营业了几轮,大部分是RTX Pro胜。
然后开始关注这个频道,看完了UP的每期视频和之前老特说的每期视频,下定决心了入的RTX Pro。
之前在win下面一直用lms试吃,ollama生产(qwen3.6:27b_q8_0上下文256k能到35~38t/s)。系统换到Linux之后ollama确实快了一些。但是在各ai的强烈推荐下,Linux下的生产环境SGLang>vLLM>>llama.cpp>ollama。于是先是尝试docker安装了SGLang,捣鼓了2个晚上装了2次回复都是乱码(后来在论坛发现有人说SGLang框架推理qwen3.6-27b-fp8就是有乱码,要坐等框架更新)。于是开始尝试vLLM,才有了上面的图。运行参数如下:
vllm serve /home/bentonyi/.cache/modelscope/hub/models/Qwen/Qwen3.6-27B-FP8
--trust-remote-code
--quantization fp8
--max-model-len 262144
--enable-auto-tool-choice
--max-num-seqs 32
--tool-call-parser qwen3_coder
--reasoning-parser qwen3
--speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":4}'
--host 0.0.0.0
--port 8000
设置猜字的mtp并发为4的时候,有效token速度可以超过400t/s。本地的hermes速度能达到接近之前用minimax2.7新手包套餐的在线速度,终于可用了。
另:涡轮版本的RTX Pro风扇策略偏静音,不调的情况下工作温度在85~88℃范围。图中的温控工具是LACT,按此设置重度连续工作1小时不会上80℃。省流版:用心写一组提示词,把自己的需求现状和担心的点告诉知名ai众,让它们在线给你营业,然后交叉验证各ai的回答,往往能解决90%以上的问题。
-
版主您好:
1、“抡锤者”每一个视频我都追更、看过,这是目前我最喜爱的AI相关频道,没有之一。
2、首先声明,我只是个自己瞎琢磨一年多的老人(50+),只用过4060卡玩本地,和API用openrouter,主要是写长篇小说。我不是大款,更不是有钱,但就是喜欢玩,所以今天的提问,请千万不要误会、不要喷,谢谢大家。
3、我想本地部署 DeepSeek-V4-Flash,如果可以为了学习自己训练和微调那就最好(纯粹是向往,目前不会),这样既有安全性,也不怕资源消耗。
4、另外就是本地运行Qwen3.6 27b本地跑Hermes,然后就是通过本地部署,做AI音视频画图。所以,我想请问:
1、买 ASUS Ascent GX10 ( NVIDIA DGX Spark)合适么?或者买两台串联?
2、我知道两台 ASUS Ascent GX10 ,可以放 DeepSeek-V4-Flash ,但不知道视频生成怎么样?
3、我从你这里知道,视频生成用 5090 (32G)是极好的。因为目前一块5090的价格和一个ASUS Ascent GX10 (NVIDIA DGX Spark)价格差不多,而买5090我要配一台新机,价格大约5W,这个价格不如我花6W买两台ASUS Ascent GX10 ,然后连接我的老机器。所以特地请教您,请不要笑话
@Fangbo-Da 我觉得把你真的没有必要折腾,DeepSeek-V4-Flash 这个模型精度就不高。你先买个云端的玩几天你再想想你用什么模型吧,模型决定设备。 这个云端模型我也不知道你用的是什么, 反正我是OLLAMA CLOUD ,全是满血免费大模型,那个顺手用那个。
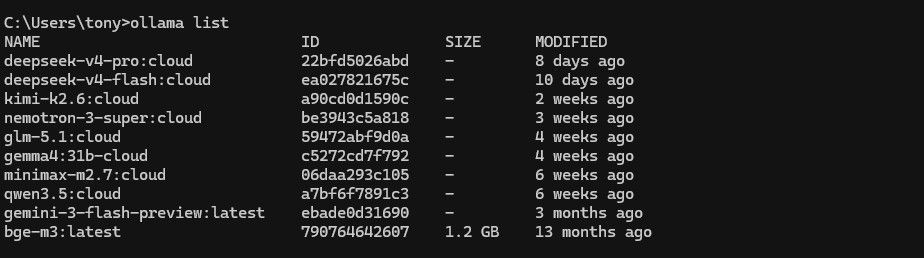
你这个需求OLLAMA CLOUD 一个月20美金 的订阅我觉得就够了,最差你也感受一下到底要用什么模型。你偏要做视频,你就买个5090最好了,直接出视频。
这里是OLLAMA 的模型列表 https://ollama.com/search
DGX SPARK 就是做了一个小模型的定位填补,因为这些小模型很少有云端提供服务。 -
@Fangbo-Da 我觉得把你真的没有必要折腾,DeepSeek-V4-Flash 这个模型精度就不高。你先买个云端的玩几天你再想想你用什么模型吧,模型决定设备。 这个云端模型我也不知道你用的是什么, 反正我是OLLAMA CLOUD ,全是满血免费大模型,那个顺手用那个。
你这个需求OLLAMA CLOUD 一个月20美金 的订阅我觉得就够了,最差你也感受一下到底要用什么模型。你偏要做视频,你就买个5090最好了,直接出视频。
这里是OLLAMA 的模型列表 https://ollama.com/search
DGX SPARK 就是做了一个小模型的定位填补,因为这些小模型很少有云端提供服务。 -
我觉得你如果预算够的话肯定上6000不后悔啊,你不算老人(我也50岁瞎折腾两个月了)我也准备搞一台洋垃圾x99-2696v3-ddr3配3090本地跑跑玩,目前手里有台MACmini丐版跑在线模型已经上瘾了哈哈
-
TLDR:新手不要碰DGX Spark(GB10)
DGX Spark的芯片SM121最初的设计是一个 游戏APU和AI 两吃产品,并且跳票了超过一年多(出处:https://youtu.be/o8FL3nVDM5M?si=byA9yR5k0U8MTAI5)。因为游戏APU是需要Windows for Arm的适配,而微软那个屎山Bug巨多无比。所以等不及了,只能先开卖DGX Spark。SM121芯片和NV专业芯片设计有很多区别,导致生态和支持一直有问题(被NV论坛诟病很多),这么小众的产品(而且还是和半成品),你不能指望NV会让团队花很多精力去修正生态问题。 -
 T terry 于 将此主题从 AI硬件 移至此处
T terry 于 将此主题从 AI硬件 移至此处