
交作业,关于 Intel B70 PRO 的压力测试。
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
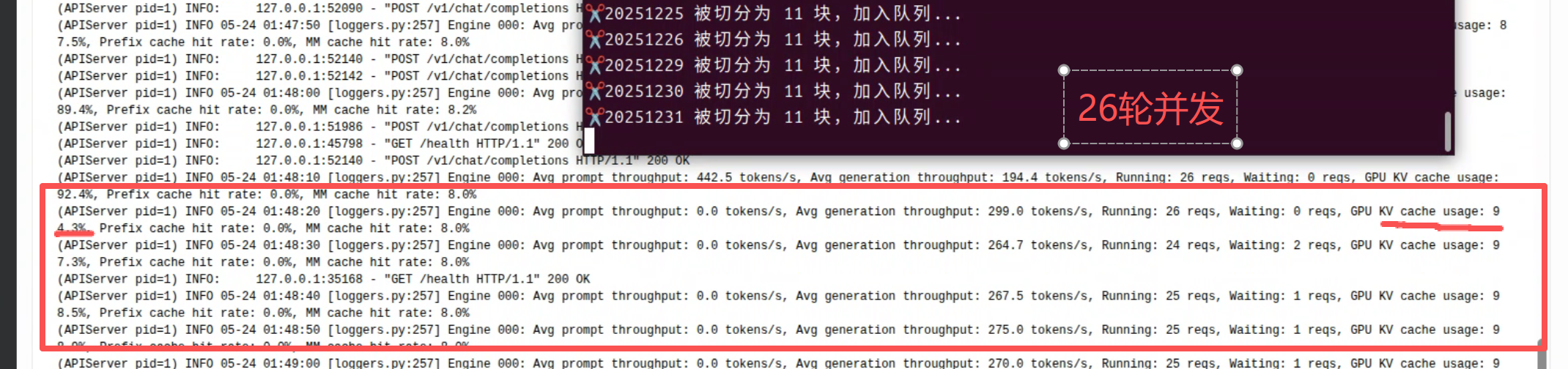
@sirwang 你问到为什么并发从16加到26后token吞吐量会上下剧烈跳动(299降到十几个),这个现象的本质是KV Cache内存争抢。
B70 32G显存跑Qwen3.6-27B时,每个并发请求都要占用一段KV Cache空间。Q4_K_M的27B模型,单个请求的KV Cache大约占 0.5-1GB(取决于context长度)。16并发时总KV Cache约8-16GB,显存还有余量;但到26并发时,KV Cache总量逼近甚至超过可用显存,vLLM/llama.cpp的调度器就会频繁做cache eviction和recomputation——排到你的请求就快(cache命中),排不到就要等别人释放cache,token就只能慢慢出。
你朋友说16-20并发最合适,道理就在这个临界点:低于16时显存充裕但浪费算力,高于20时cache thrashing的代价超过并发收益。实际调参建议:
- 观察显存占用:跑的时候watch nvidia-smi,看memory-usage%在26并发时是否接近100%且持续抖动。如果在95%以上剧烈波动,就是cache thrashing。
- 短context可以加并发:如果每个请求的输入/输出长度很短(几百token),单个请求的KV Cache占用小,可以尝试24-30并发。
- 调max-num-seqs下限:设 --max-num-seqs 18,让调度器主动限制并发量,比让它在26并发时被动thrashing要快得多。
- 启用vLLM的prefix caching(如果用的vLLM):加 --enable-prefix-caching,多个相似请求共享KV Cache前缀,显著降低cache压力。
简单说:你的硬件能力曲线不是线性的——16并发跑N tokens/秒,26并发可能反而因为thrashing降到只有1.2N。找自己硬件的甜蜜点才是关键。
-
-
@applejuice 这不是期待intel的会有更多深挖的东西嘛,哇哈哈哈。我还在深挖。
-
系统 于 取消固定此主题
 大哥来踩坑
大哥来踩坑