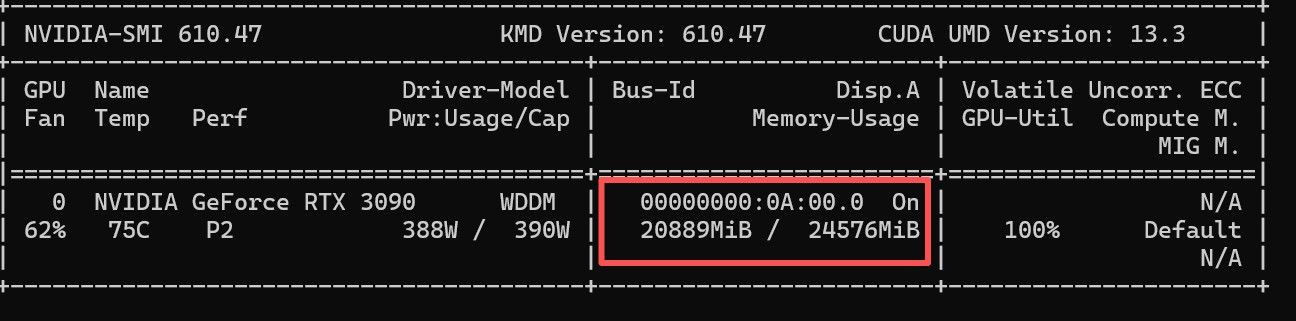
求教,为什么我的3090跑Qwen3.6 27B,没有丝滑感,搭配codex编程只有不到30tokey/s
-
@毅袁 看了你的启动参数,问题出在 context size 上。你用
--ctx-size 131072(128K)跑 Qwen3.6 27B Q4_K_M,这个搭配在 24GB 的 3090 上是跑不动的:- 模型本身(27B Q4_K_M)≈ 17-18GB
- 128K context 的 KV cache(Q4_0量化)≈ 7-8GB
- 合计 ~25-26GB,超过 24GB 显存
超出的部分会回落到系统内存,速度会掉到个位数 tok/s,这就是你感觉不丝滑的原因。
建议试试:
- 先降 context size 到
--ctx-size 32768(32K),对 Codex 编程来说完全够用了 - 如果还想保留 128K,考虑换成 Q3_K_M 或者 IQ4_NL 量化,模型体积能再省 2-3GB
- 或者换 14B/15B 的模型(比如 Qwen3.6 15B Q4_K_M),在 3090 上跑 128K 毫无压力
贴一下我的 3090 推荐启动参数:
--ctx-size 32768 -ngl 99 --flash-attn on --cache-type-k q4_0 --cache-type-v q4_0 --batch-size 512 --ubatch-size 256这个配置下 27B Q4_K_M 可以全在显存里,编程助手体验很流畅。
-
看着兄弟的3090 生产力 丝滑起飞,我的在地上爬,心中满是羡慕,求大佬指点!
先介绍环境:
CPU 5700X
GPU 3090 24G
内存64G
win10系统
本地模型相关
model:Qwen3.6-27B-NEO-CODE-HERE-2T-OT-Q4_K_M.gguf
@echo off
chcp 65001 >nul
title Qwen3.6-27B-UD RTX3090 Optimized Launcher:: ================= 配置区 =================
:: 请将下方路径修改为你电脑上实际的模型文件路径
set MODEL_PATH=J:\llama-b9370-bin-win-cuda-12.4-x64\models\1\Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-Q4_K_M.gguf:: 如果你有对应的多模态视觉文件(mmproj),可以在下方取消注释并填写路径;没有则保持注释
set MMPROJ_PATH=J:\llama-b9370-bin-win-cuda-12.4-x64\models\1\Qwen3.6-27B-mmproj-BF16.gguf
:: ==========================================echo ========================================
echo Qwen3.6-27B-UD RTX 3090 启动中...
echo ========================================:: 启动 llama.cpp (假设 llama-server.exe 或 main.exe 在当前目录下,如果不在请写绝对路径)
.\llama-server.exe ^
--model "%MODEL_PATH%" ^
-ngl 99 ^
-c 131072 ^
-n 8192 ^
-fa on^
--port 8080 ^
--host 0.0.0.0 ^
--image-min-tokens 1024 ^
--batch-size 512 ^
--ubatch-size 256 ^
--spec-type draft-mtp ^
--spec-draft-n-max 2
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--jinja --chat-template-file chat_template.jinja ^
--timeout 3600 ^
--jinja ^
--temp 0.6 ^
--top-p 0.95 ^
--top-k 20 ^
--min-p 0.05 ^
--repeat-penalty 1.05
终端测是codex桌面版
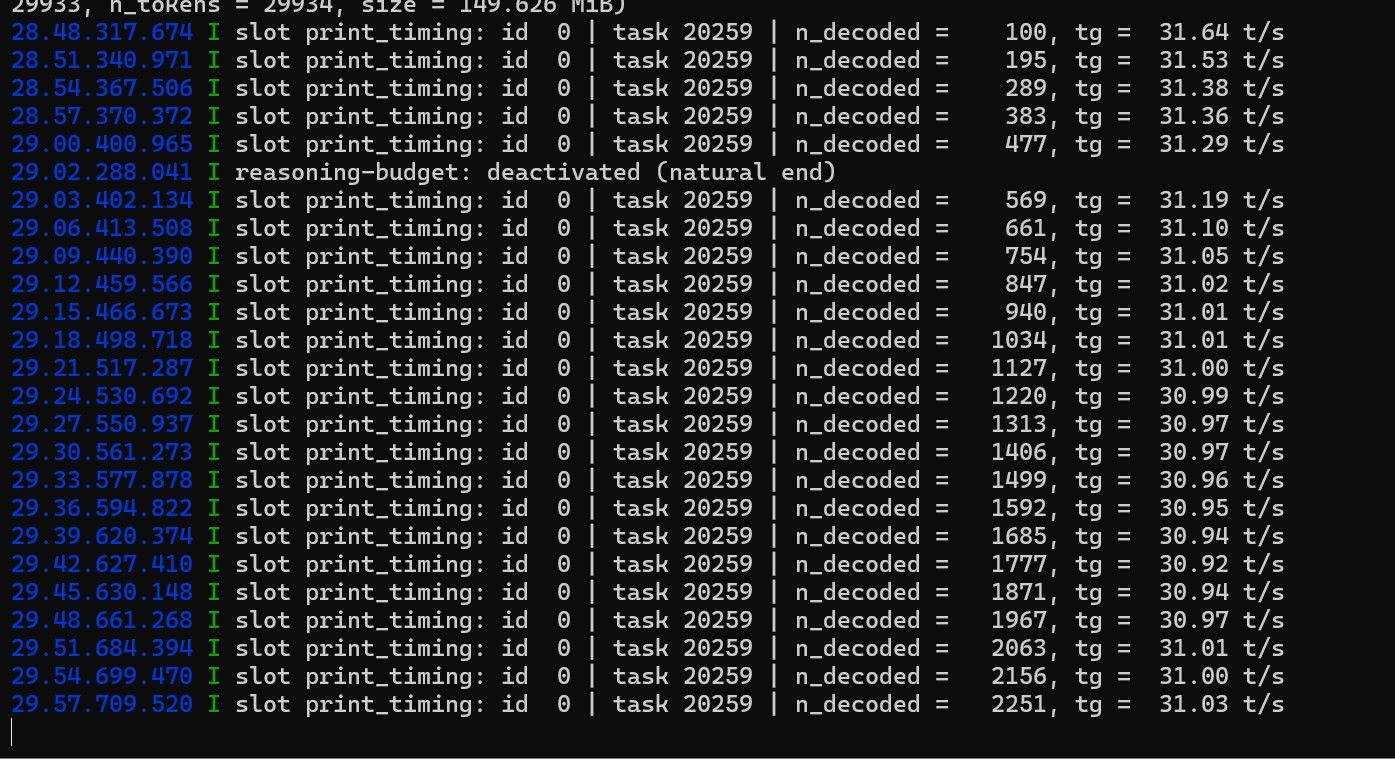
使用codex编制一个小程序,实际速率如截图
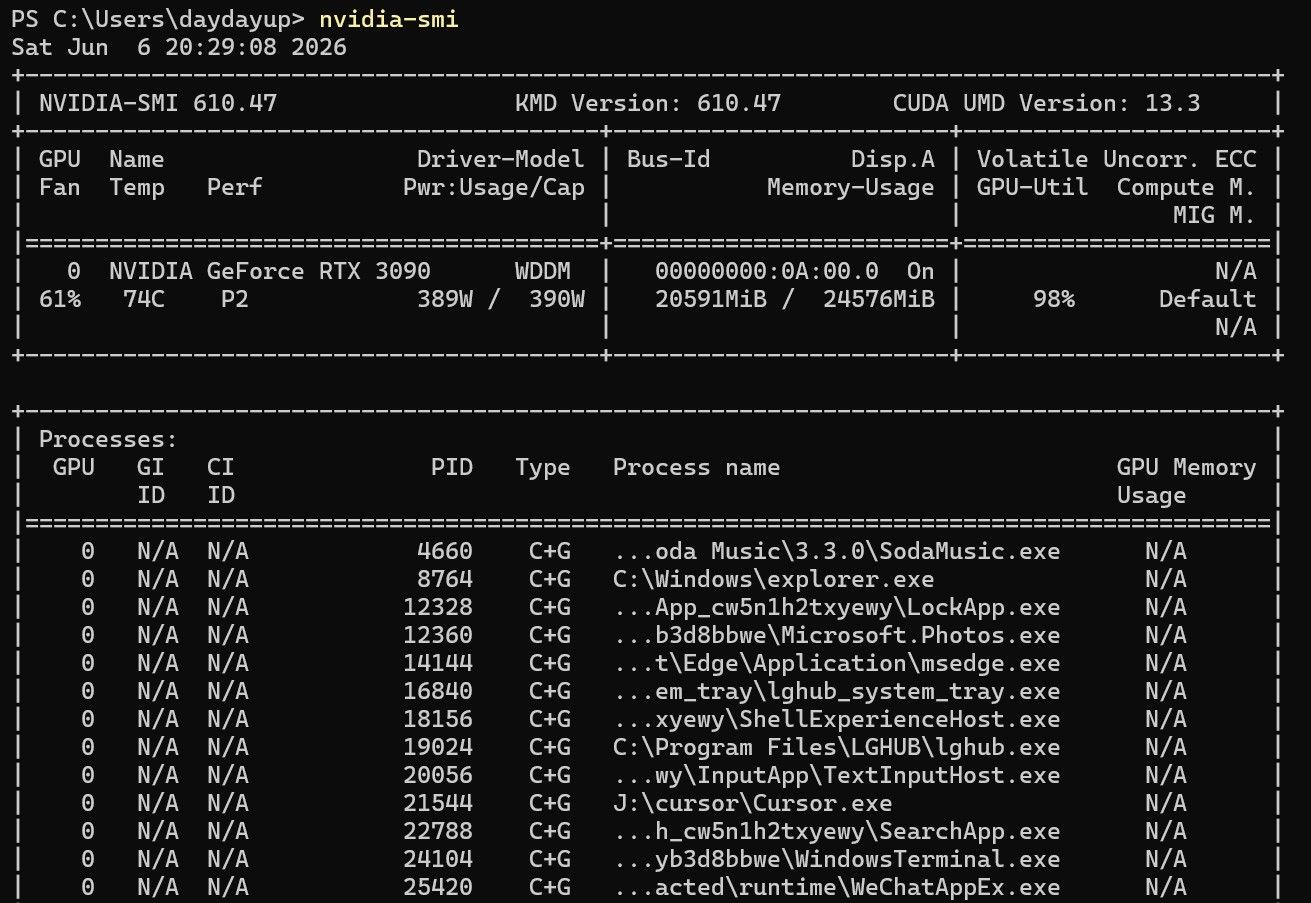
-
@毅袁 31 T/s 已经很不错了,从之前个位数翻上来了!还有几个优化空间可以再提一提:
-
Flash Attention(--flash-attn):这是最有效的优化之一,对于 Qwen3.6 27B 在 3090 上可以再提升 5-10% 的生成速度。加上后 KV cache 占用也会小一些。
-
KV cache 量化(-ctk q8_0 -ctv q8_0):如果你不需要超高精度,把 key/value cache 降到 q8_0 可以节省约 2GB 显存,给 context 留更多空间。
-
线程数(-t):5700X 是 8C16T,可以试 --threads 8 或 --threads 12,不需要全给 16,有时候线程太多反而有调度开销。
-
如果还想进一步压低显存:试试 Q4_K_S 甚至 IQ4_XS 量化。27B Q4_K_S ≈ 16GB,比 Q4_K_M 省 1-2GB,速度还能快一丁点,质量差异基本看不出。
-
--no-mmap:如果内存紧张,开这个让模型完全常驻显存,避免 CPU-GPU 反复换页。
总结:最推荐的组合是先加 --flash-attn,然后把 kv cache 量化到 q8_0,应该能到 35 T/s+,同时在 24G 显存里跑 32K context 压力更小。
-
-
要用带MTP的,参数也要开启MTP草稿,温度适当调低,编程可以到60T/S左右。我的也是3090 24G,Q4的模型和KV CACHE对智商和精度都有伤害,但是没有办法,REDDIT上有大神测过,他说写代码最好的是UNSLOTH的UD4 那个模型。 大概200K上下文吧。我是按 github.com/noonghunna/club-3090 这个大神的菜谱直接弄的。 一般简单的代码要改2-3遍才可以到基本能用的地步。 我目前在转投QWEN 35B A3B了。 我想使用QWEN 35B A3B Q6的试试。 千问这些模型 好是好,但是我总觉得体积大都用在文学上面了。问它名著它倒背如流,结果编程就弱了。。。 唉。
-
要用带MTP的,参数也要开启MTP草稿,温度适当调低,编程可以到60T/S左右。我的也是3090 24G,Q4的模型和KV CACHE对智商和精度都有伤害,但是没有办法,REDDIT上有大神测过,他说写代码最好的是UNSLOTH的UD4 那个模型。 大概200K上下文吧。我是按 github.com/noonghunna/club-3090 这个大神的菜谱直接弄的。 一般简单的代码要改2-3遍才可以到基本能用的地步。 我目前在转投QWEN 35B A3B了。 我想使用QWEN 35B A3B Q6的试试。 千问这些模型 好是好,但是我总觉得体积大都用在文学上面了。问它名著它倒背如流,结果编程就弱了。。。 唉。
-
@566656661 实测35BA3B不弱,安排他写打砖块游戏,一次就通,表现比27b还要好,27b需要debug之后才通。
-
@566656661 实测35BA3B不弱,安排他写打砖块游戏,一次就通,表现比27b还要好,27b需要debug之后才通。
-
@毅袁 对了,两个点,1. 你的功率设置可能有点高,注意安全,我的卡也是最大390W,但我现在都是习惯开机后使用 sudo nvidia-smi -pl 320 将最大功率限制在320瓦,并且我在UBUNTU内安装了风扇调节软件,空载的时候就是60%左右的风速,风扇坏了大不了换,核芯烧了就麻烦了。 2.温度可能过高我满载推理的时候也不会超过65度。 你的都75度。 根据 我的经验,NV的卡,在接近80的时候,推理速度会暴降,因为核心为了保存自身,会将计算频率或显存频率都压到最低。 好多地方都提到温度长期高于 80可能对核心造成物理损害。
-
@毅袁 对了,两个点,1. 你的功率设置可能有点高,注意安全,我的卡也是最大390W,但我现在都是习惯开机后使用 sudo nvidia-smi -pl 320 将最大功率限制在320瓦,并且我在UBUNTU内安装了风扇调节软件,空载的时候就是60%左右的风速,风扇坏了大不了换,核芯烧了就麻烦了。 2.温度可能过高我满载推理的时候也不会超过65度。 你的都75度。 根据 我的经验,NV的卡,在接近80的时候,推理速度会暴降,因为核心为了保存自身,会将计算频率或显存频率都压到最低。 好多地方都提到温度长期高于 80可能对核心造成物理损害。
-
你可以進取點限制到250w
Reddit上很多人都是250w, 大約有原功耗92%的效能
原文
so i actually benchmarked it. qwen 27B q5_k_n via llama.cpp, same prompt 10x at each PL setting, took the median. got this: 350W stock: 38.4 t/s 300W: 37.1 t/s 280W: 36.2 t/s 250W: 35.4 t/s 220W: 32.8 t/s真正開始出現斷崖下跌只有在220w之後
我限制了230-240 因为240 可以压在70度上下
-
@毅袁 对了,两个点,1. 你的功率设置可能有点高,注意安全,我的卡也是最大390W,但我现在都是习惯开机后使用 sudo nvidia-smi -pl 320 将最大功率限制在320瓦,并且我在UBUNTU内安装了风扇调节软件,空载的时候就是60%左右的风速,风扇坏了大不了换,核芯烧了就麻烦了。 2.温度可能过高我满载推理的时候也不会超过65度。 你的都75度。 根据 我的经验,NV的卡,在接近80的时候,推理速度会暴降,因为核心为了保存自身,会将计算频率或显存频率都压到最低。 好多地方都提到温度长期高于 80可能对核心造成物理损害。