
洋垃圾的回乡路 —— 2x3090 + X99 + 2x2680v4
-
以下大部分是比较罗嗦的流水账,技术内容在分割线后。
前阵子入坑了本地AI。手上有两张3090,但是自己用的机器机箱、电源只够跑一张。而且平时要打打游戏,用Adobe系列软件,需要占用显卡,来回释放显存也很麻烦。想着再配一台电脑吧,但是看了看现在内存、SSD的价钱,还是算了吧。
后来看了牢特视频,了解到了洋垃圾的世界。果断某东搜索华南金牌,到官方店下单了一整套X10X99套餐,带两个U,4x32G ECC拆机条,一个2TB长城NVME,总共6000(机箱散热器这些重的大的东西就没买了)。说实话玩洋垃圾似乎有点小贵,但是比起在美国装新机器还是便宜太多了,而且将来淘汰下来还可以跑我那一堆乱七八糟的docker服务。虽然美国Aliexpress也有X99套装,但是买着感觉就是不如京东旗舰店放心。又花了700元子运到了美国,大概一个星期就到了。
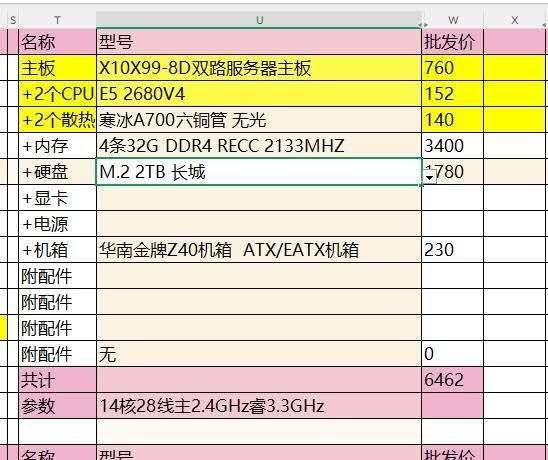
两个洋垃圾当年不远万里离开了北美机房温柔乡,被送到了深圳冰冷的仓库里,现在终于回到了家乡的温暖怀抱。我把几年前挖矿用的开放式机架和两个电源废物利用,给他搭了个窝...


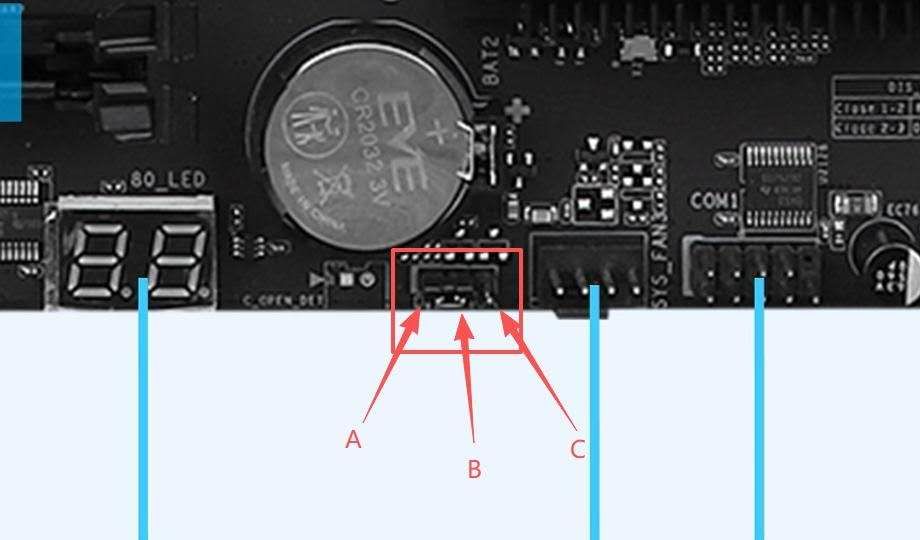
装机一切都算顺利,只是到最后就是不POST,主板报"Ad"码。售后小哥跟我一起排查了一遍,4条内存8个插槽排列组合搞了一遍也没点亮屏幕。最后发现是因为显示器接的是HDMI,主板上有个3针跳帽负责切换显示模式。插在AB上面是VGA,把它给换到BC上面屏幕就成功亮了... 华南金牌东西是挺好的,就是说明书完全没用,不知道将来会不会对其他人有所帮助。
接下来就是装Ubuntu,装各种必要的软件,然后就是跑分了。
================================分割线================================
直接跑Github上 club-3090 的懒人包,以前我都是跑单卡的,现在终于能跑双卡了。用的是vllm,AutoRound INT4 量化,FP8 KV,MTP n=3,262K上下文。
两张卡我都按推荐的限制到了290W。用的是最新的595驱动,13.2 CUDA。
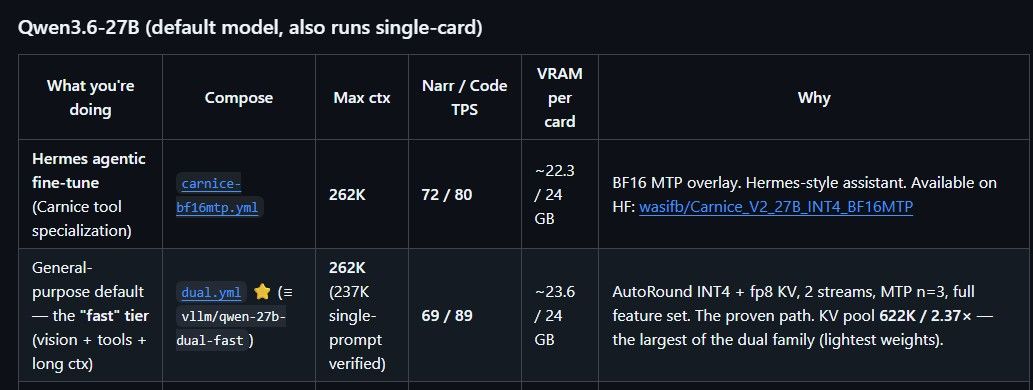
========== NARRATIVE (prompt=65 chars, max_tokens=1000) ========== === warmups (3) === warm-1 wall= 19.64s ttft= 184ms toks=1000 wall_TPS= 50.91 decode_TPS= 51.40 warm-2 wall= 19.46s ttft= 188ms toks=1000 wall_TPS= 51.39 decode_TPS= 51.89 warm-3 wall= 19.02s ttft= 188ms toks=1000 wall_TPS= 52.58 decode_TPS= 53.10 === measured (5) === run-1 wall= 19.03s ttft= 146ms toks=1000 wall_TPS= 52.56 decode_TPS= 52.97 run-2 wall= 19.25s ttft= 187ms toks=1000 wall_TPS= 51.94 decode_TPS= 52.45 run-3 wall= 20.46s ttft= 145ms toks=1000 wall_TPS= 48.88 decode_TPS= 49.23 run-4 wall= 19.59s ttft= 193ms toks=1000 wall_TPS= 51.06 decode_TPS= 51.57 run-5 wall= 18.44s ttft= 143ms toks= 972 wall_TPS= 52.70 decode_TPS= 53.11 === summary [narrative] (n=5) === wall_TPS mean= 51.43 std= 1.57 CV= 3.0% min=48.88 max=52.70 decode_TPS mean= 51.86 std= 1.59 CV= 3.1% min=49.23 max=53.11 TTFT mean= 163ms std= 25ms min=143ms max=193ms PP tok/s mean= 1.00 std= 1.37 CV=136.9% min=0.00 max=2.50 ========== CODE (prompt=78 chars, max_tokens=800) ========== === warmups (3) === warm-1 wall= 10.25s ttft= 152ms toks= 691 wall_TPS= 67.39 decode_TPS= 68.41 warm-2 wall= 7.23s ttft= 183ms toks= 478 wall_TPS= 66.11 decode_TPS= 67.82 warm-3 wall= 8.92s ttft= 183ms toks= 556 wall_TPS= 62.36 decode_TPS= 63.67 === measured (5) === run-1 wall= 7.08s ttft= 186ms toks= 466 wall_TPS= 65.81 decode_TPS= 67.58 run-2 wall= 11.91s ttft= 185ms toks= 784 wall_TPS= 65.85 decode_TPS= 66.89 run-3 wall= 11.79s ttft= 184ms toks= 771 wall_TPS= 65.41 decode_TPS= 66.45 run-4 wall= 11.58s ttft= 188ms toks= 746 wall_TPS= 64.43 decode_TPS= 65.49 run-5 wall= 12.38s ttft= 185ms toks= 800 wall_TPS= 64.61 decode_TPS= 65.59 === summary [code] (n=5) === wall_TPS mean= 65.22 std= 0.67 CV= 1.0% min=64.43 max=65.85 decode_TPS mean= 66.40 std= 0.88 CV= 1.3% min=65.49 max=67.58 TTFT mean= 186ms std= 2ms min=184ms max=188ms PP tok/s mean= 2.50 std= 1.77 CV=70.7% min=0.00 max=5.00综合的看就是写作文能跑到50多T/s,写码大概65+T/s。虽然感觉已经很够用了,但是离项目上描述的69/89还有一定的距离,具体还要再多跑一下多调试一下。
-
以下大部分是比较罗嗦的流水账,技术内容在分割线后。
前阵子入坑了本地AI。手上有两张3090,但是自己用的机器机箱、电源只够跑一张。而且平时要打打游戏,用Adobe系列软件,需要占用显卡,来回释放显存也很麻烦。想着再配一台电脑吧,但是看了看现在内存、SSD的价钱,还是算了吧。
后来看了牢特视频,了解到了洋垃圾的世界。果断某东搜索华南金牌,到官方店下单了一整套X10X99套餐,带两个U,4x32G ECC拆机条,一个2TB长城NVME,总共6000(机箱散热器这些重的大的东西就没买了)。说实话玩洋垃圾似乎有点小贵,但是比起在美国装新机器还是便宜太多了,而且将来淘汰下来还可以跑我那一堆乱七八糟的docker服务。虽然美国Aliexpress也有X99套装,但是买着感觉就是不如京东旗舰店放心。又花了700元子运到了美国,大概一个星期就到了。
两个洋垃圾当年不远万里离开了北美机房温柔乡,被送到了深圳冰冷的仓库里,现在终于回到了家乡的温暖怀抱。我把几年前挖矿用的开放式机架和两个电源废物利用,给他搭了个窝...
装机一切都算顺利,只是到最后就是不POST,主板报"Ad"码。售后小哥跟我一起排查了一遍,4条内存8个插槽排列组合搞了一遍也没点亮屏幕。最后发现是因为显示器接的是HDMI,主板上有个3针跳帽负责切换显示模式。插在AB上面是VGA,把它给换到BC上面屏幕就成功亮了... 华南金牌东西是挺好的,就是说明书完全没用,不知道将来会不会对其他人有所帮助。
接下来就是装Ubuntu,装各种必要的软件,然后就是跑分了。
================================分割线================================
直接跑Github上 club-3090 的懒人包,以前我都是跑单卡的,现在终于能跑双卡了。用的是vllm,AutoRound INT4 量化,FP8 KV,MTP n=3,262K上下文。
两张卡我都按推荐的限制到了290W。用的是最新的595驱动,13.2 CUDA。
========== NARRATIVE (prompt=65 chars, max_tokens=1000) ========== === warmups (3) === warm-1 wall= 19.64s ttft= 184ms toks=1000 wall_TPS= 50.91 decode_TPS= 51.40 warm-2 wall= 19.46s ttft= 188ms toks=1000 wall_TPS= 51.39 decode_TPS= 51.89 warm-3 wall= 19.02s ttft= 188ms toks=1000 wall_TPS= 52.58 decode_TPS= 53.10 === measured (5) === run-1 wall= 19.03s ttft= 146ms toks=1000 wall_TPS= 52.56 decode_TPS= 52.97 run-2 wall= 19.25s ttft= 187ms toks=1000 wall_TPS= 51.94 decode_TPS= 52.45 run-3 wall= 20.46s ttft= 145ms toks=1000 wall_TPS= 48.88 decode_TPS= 49.23 run-4 wall= 19.59s ttft= 193ms toks=1000 wall_TPS= 51.06 decode_TPS= 51.57 run-5 wall= 18.44s ttft= 143ms toks= 972 wall_TPS= 52.70 decode_TPS= 53.11 === summary [narrative] (n=5) === wall_TPS mean= 51.43 std= 1.57 CV= 3.0% min=48.88 max=52.70 decode_TPS mean= 51.86 std= 1.59 CV= 3.1% min=49.23 max=53.11 TTFT mean= 163ms std= 25ms min=143ms max=193ms PP tok/s mean= 1.00 std= 1.37 CV=136.9% min=0.00 max=2.50 ========== CODE (prompt=78 chars, max_tokens=800) ========== === warmups (3) === warm-1 wall= 10.25s ttft= 152ms toks= 691 wall_TPS= 67.39 decode_TPS= 68.41 warm-2 wall= 7.23s ttft= 183ms toks= 478 wall_TPS= 66.11 decode_TPS= 67.82 warm-3 wall= 8.92s ttft= 183ms toks= 556 wall_TPS= 62.36 decode_TPS= 63.67 === measured (5) === run-1 wall= 7.08s ttft= 186ms toks= 466 wall_TPS= 65.81 decode_TPS= 67.58 run-2 wall= 11.91s ttft= 185ms toks= 784 wall_TPS= 65.85 decode_TPS= 66.89 run-3 wall= 11.79s ttft= 184ms toks= 771 wall_TPS= 65.41 decode_TPS= 66.45 run-4 wall= 11.58s ttft= 188ms toks= 746 wall_TPS= 64.43 decode_TPS= 65.49 run-5 wall= 12.38s ttft= 185ms toks= 800 wall_TPS= 64.61 decode_TPS= 65.59 === summary [code] (n=5) === wall_TPS mean= 65.22 std= 0.67 CV= 1.0% min=64.43 max=65.85 decode_TPS mean= 66.40 std= 0.88 CV= 1.3% min=65.49 max=67.58 TTFT mean= 186ms std= 2ms min=184ms max=188ms PP tok/s mean= 2.50 std= 1.77 CV=70.7% min=0.00 max=5.00综合的看就是写作文能跑到50多T/s,写码大概65+T/s。虽然感觉已经很够用了,但是离项目上描述的69/89还有一定的距离,具体还要再多跑一下多调试一下。
-
对了,说到Ubuntu,这里也有个坑,我这套配置现在没法装26.04,U盘安装时菊花一直转,症状可以参考这个帖子:https://askubuntu.com/questions/1567178/ubuntu-26-04-installer-freezes-at-get5-cdrom-resolute-main-amd64-packages-on-o
里面提供的解决方法是装完server版再手动加desktop,我直接改装24.04了。
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
一样硬件

但是这个东西放在房间不得热死?双路cpu 好像会有延迟?
@applejuice 地下室,随便它怎么叫唤我也听不到,延迟的事情我得研究一下。
-
有地下室真好 我放在房间外面 整个空间都可以感觉热气
@applejuice 话说你跑大模型大概能到多少TPS呢,我看你之前的作业,只有烤机,没有写跑分
-
@applejuice 话说你跑大模型大概能到多少TPS呢,我看你之前的作业,只有烤机,没有写跑分
@applejuice 话说你跑大模型大概能到多少TPS呢,我看你之前的作业,只有烤机,没有写跑分
VLLM, 上面那张限制230w,下面那张限制240w
vLLM 启动参数 (docker-compose.yml)
--model /models/heretic-gptq-int4 --served-model-name qwen3.6-27b-heretic --quantization gptq_marlin --dtype float16 --tensor-parallel-size 2 --max-model-len 262144 --gpu-memory-utilization 0.9 # via ~/vllm/.env: GPU_MEM_UTIL=0.9 - 之前设置0.932 但是用下来显存到了23.4x, 所以我把它降下来 --max-num-seqs 2 --max-num-batched-tokens 8192 --kv-cache-dtype fp8_e5m2 --trust-remote-code --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder --enable-prefix-caching --enable-chunked-prefill --disable-custom-all-reduce --host 0.0.0.0 --port 8000测试结果 NVLINK
测试项目 数值 首响应时间 TTFT(短 prompt,冷启动) 163 ms 总响应时间(10 tokens) 293 ms Prefill 1K 1,991 tok/s Prefill 4K 2,036 tok/s Prefill 16K 1,985 tok/s Decode(单流) 69.3 tok/s 50K prompt 冷启动 TTFT 25.06 秒 50K prompt 缓存命中 TTFT 0.69 秒 缓存加速比 36.5× 没有NVLINK
Prefill 4K 重复测量 (5 次)
run prompt_tokens ttft tok/s 1 3 836 2 776 ms 1 382 2 3 836 2 735 ms 1 403 3 3 834 2 665 ms 1 439 4 3 833 2 770 ms 1 384 5 3 838 2 772 ms 1 384 mean=1 398, median=1 384, min=1 382, max=1 439. σ ≈ 22 tok/s (1.6% 变化) — 极稳,退化是稳态而非瞬态。
Decode 单流 重复测量 (4 次)
run prompt_tokens completion_tokens ttft decode tok/s 1 76 220 256 ms 66.2 2 79 220 278 ms 66.6 3 81 220 284 ms 66.7 4 80 220 284 ms 66.7 -
@applejuice 话说你跑大模型大概能到多少TPS呢,我看你之前的作业,只有烤机,没有写跑分
VLLM, 上面那张限制230w,下面那张限制240w
vLLM 启动参数 (docker-compose.yml)
--model /models/heretic-gptq-int4 --served-model-name qwen3.6-27b-heretic --quantization gptq_marlin --dtype float16 --tensor-parallel-size 2 --max-model-len 262144 --gpu-memory-utilization 0.9 # via ~/vllm/.env: GPU_MEM_UTIL=0.9 - 之前设置0.932 但是用下来显存到了23.4x, 所以我把它降下来 --max-num-seqs 2 --max-num-batched-tokens 8192 --kv-cache-dtype fp8_e5m2 --trust-remote-code --reasoning-parser qwen3 --enable-auto-tool-choice --tool-call-parser qwen3_coder --enable-prefix-caching --enable-chunked-prefill --disable-custom-all-reduce --host 0.0.0.0 --port 8000测试结果 NVLINK
测试项目 数值 首响应时间 TTFT(短 prompt,冷启动) 163 ms 总响应时间(10 tokens) 293 ms Prefill 1K 1,991 tok/s Prefill 4K 2,036 tok/s Prefill 16K 1,985 tok/s Decode(单流) 69.3 tok/s 50K prompt 冷启动 TTFT 25.06 秒 50K prompt 缓存命中 TTFT 0.69 秒 缓存加速比 36.5× 没有NVLINK
Prefill 4K 重复测量 (5 次)
run prompt_tokens ttft tok/s 1 3 836 2 776 ms 1 382 2 3 836 2 735 ms 1 403 3 3 834 2 665 ms 1 439 4 3 833 2 770 ms 1 384 5 3 838 2 772 ms 1 384 mean=1 398, median=1 384, min=1 382, max=1 439. σ ≈ 22 tok/s (1.6% 变化) — 极稳,退化是稳态而非瞬态。
Decode 单流 重复测量 (4 次)
run prompt_tokens completion_tokens ttft decode tok/s 1 76 220 256 ms 66.2 2 79 220 278 ms 66.6 3 81 220 284 ms 66.7 4 80 220 284 ms 66.7 @applejuice 好像跟我这code成绩差不多,但你功耗低很多,明天我跑一下试试
-
@applejuice 好像跟我这code成绩差不多,但你功耗低很多,明天我跑一下试试
@applejuice 好像跟我这code成绩差不多,但你功耗低很多,明天我跑一下试试
测了3090 300w 跟250w 只差5-10%
230w 跟 250w 好像也只有5%的样子所以限制230w-250w = 差不多就有90% 的效率
-
K koala 于 引用了 此主题




