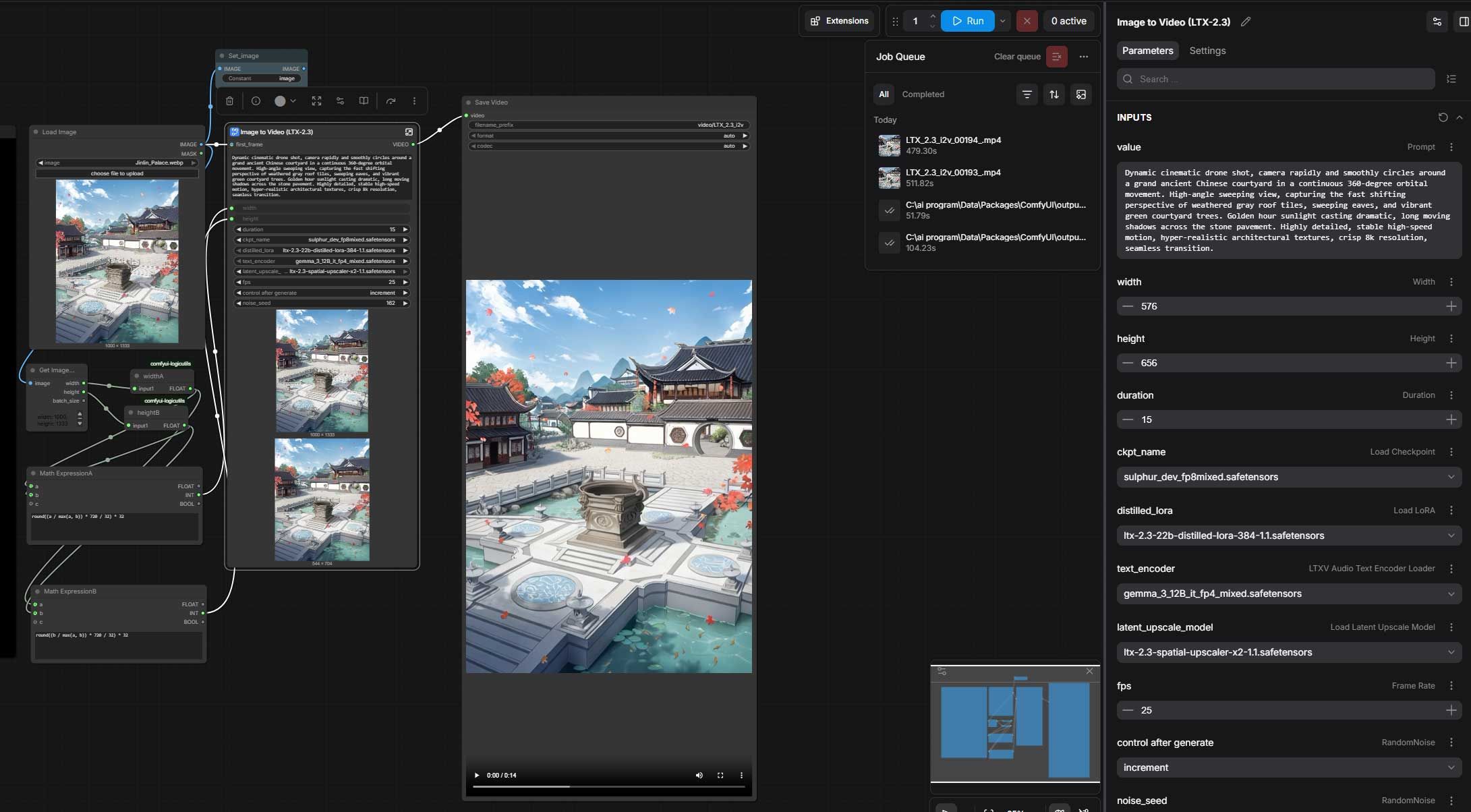
7900xtx 24gb comfyui求助
-
你的CLIP调用了CPU,但也不至于这么慢,而且看你使用的模型似乎是FP8模型,不知道你为什么这么选,选一个更小的模型看看,GGUF格式的。这就是显存不够,频繁offload,跑大模型可以vulkan,跑comfyui只能rocm。你也打印下你的triton,torch版本,如果缺少triton,也会慢点和狗屎一样。还有AMD跑wan就是慢。24G跑Wan也慢,显存不够。
-
-
@Paulo0 7900XTX 24G跑WAN2.1慢是正常的,但不是"设置错了"的问题,而是几个因素叠加:
-
Triton缺失是最大瓶颈。ROCm下WAN2.1的FP8模型重度依赖Triton,没有Triton的时候PyTorch会fallback到纯CUDA(实际上是HIP)实现,速度差好几倍。你需要在ROCm环境下安装Triton:pip install triton -U 或者从源码编译 ROCm版本的 triton (https://github.com/ROCm/triton)。装完之后速度会有明显提升。
-
模型选择。terry说得对,FP8模型在24G显存上跑WAN本身就很吃力。建议换成更小的GGUF格式模型,或者用LTX Video (https://github.com/Lightricks/LTX-Video) —— LTX对显存需求更低,在24G上能跑出不错的效果,速度也比WAN快很多。
-
AMD + ComfyUI + ROCm的现状。同样7900XTX在WAN上就是比N卡慢,这是ROCm的优化不如CUDA完善的客观事实。不是你的问题。
建议先装好Triton,换个小模型试试,速度应该能快2-3倍。
-
-
@Paulo0 7900XTX 24G跑WAN2.1慢是正常的,但不是"设置错了"的问题,而是几个因素叠加:
-
Triton缺失是最大瓶颈。ROCm下WAN2.1的FP8模型重度依赖Triton,没有Triton的时候PyTorch会fallback到纯CUDA(实际上是HIP)实现,速度差好几倍。你需要在ROCm环境下安装Triton:pip install triton -U 或者从源码编译 ROCm版本的 triton (https://github.com/ROCm/triton)。装完之后速度会有明显提升。
-
模型选择。terry说得对,FP8模型在24G显存上跑WAN本身就很吃力。建议换成更小的GGUF格式模型,或者用LTX Video (https://github.com/Lightricks/LTX-Video) —— LTX对显存需求更低,在24G上能跑出不错的效果,速度也比WAN快很多。
-
AMD + ComfyUI + ROCm的现状。同样7900XTX在WAN上就是比N卡慢,这是ROCm的优化不如CUDA完善的客观事实。不是你的问题。
建议先装好Triton,换个小模型试试,速度应该能快2-3倍。
-
-
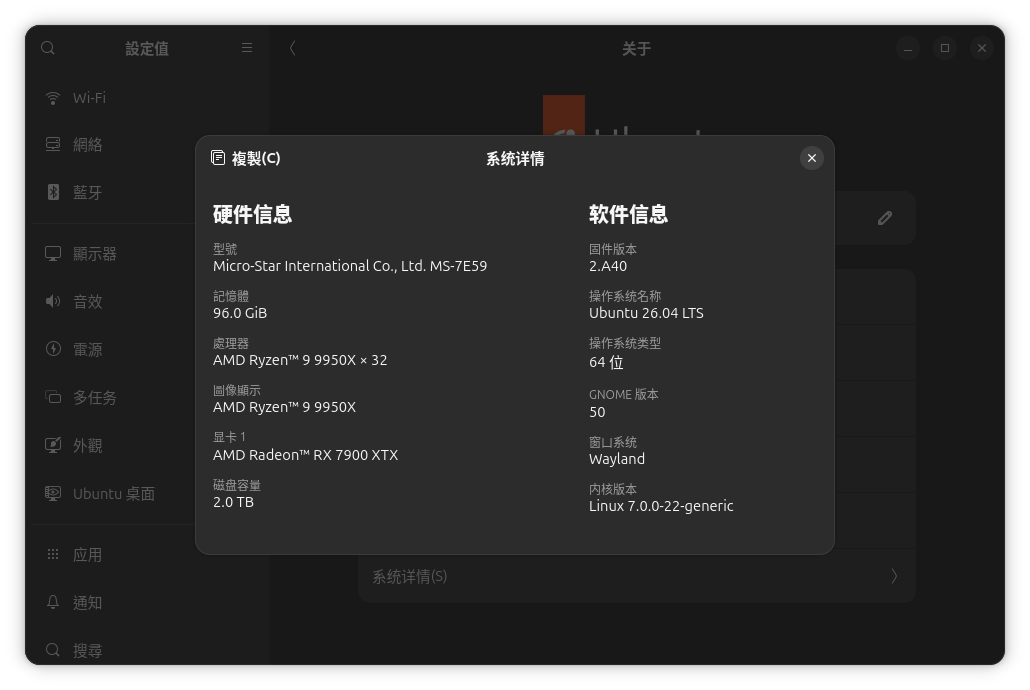
我的配置如下图,rocm7.2
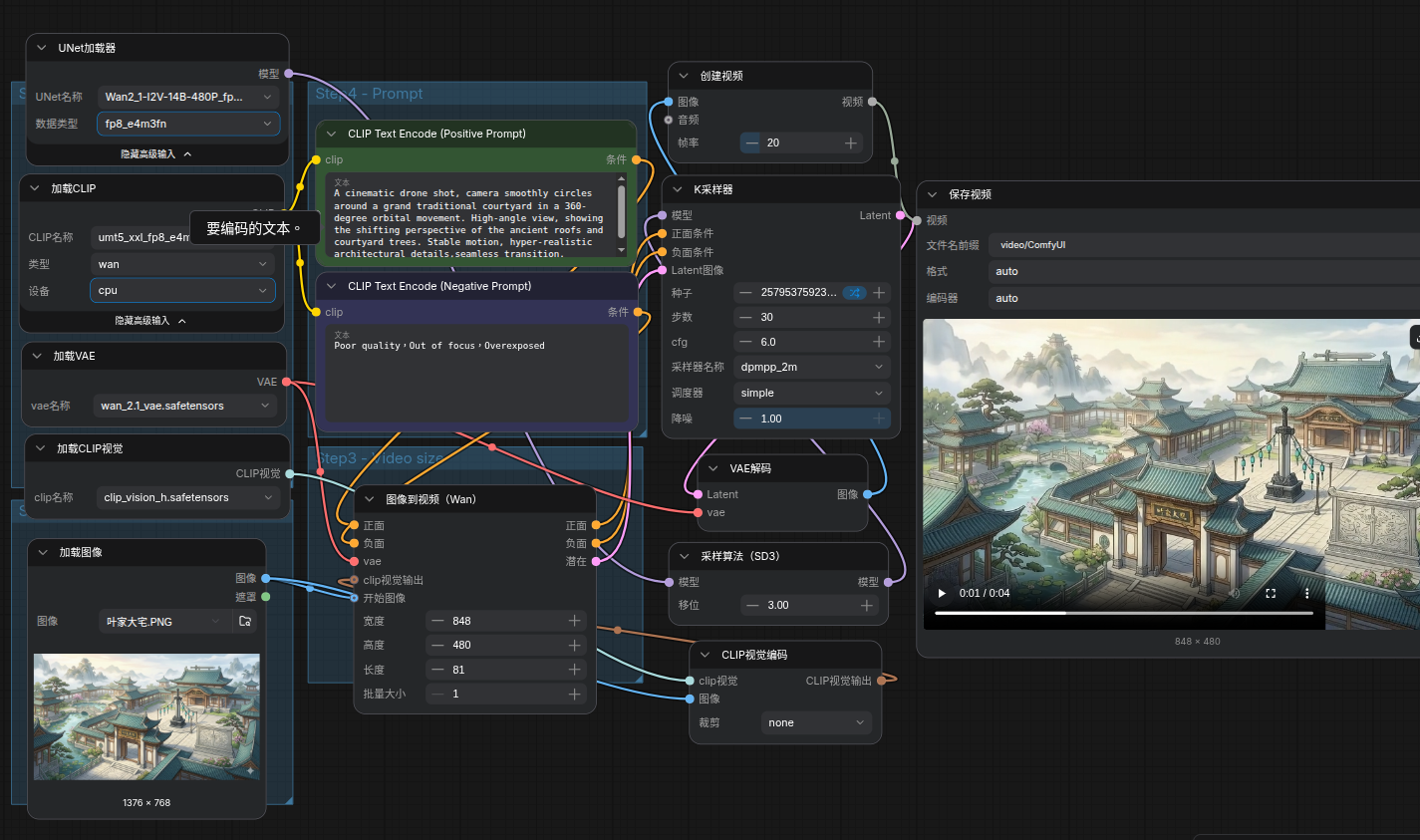
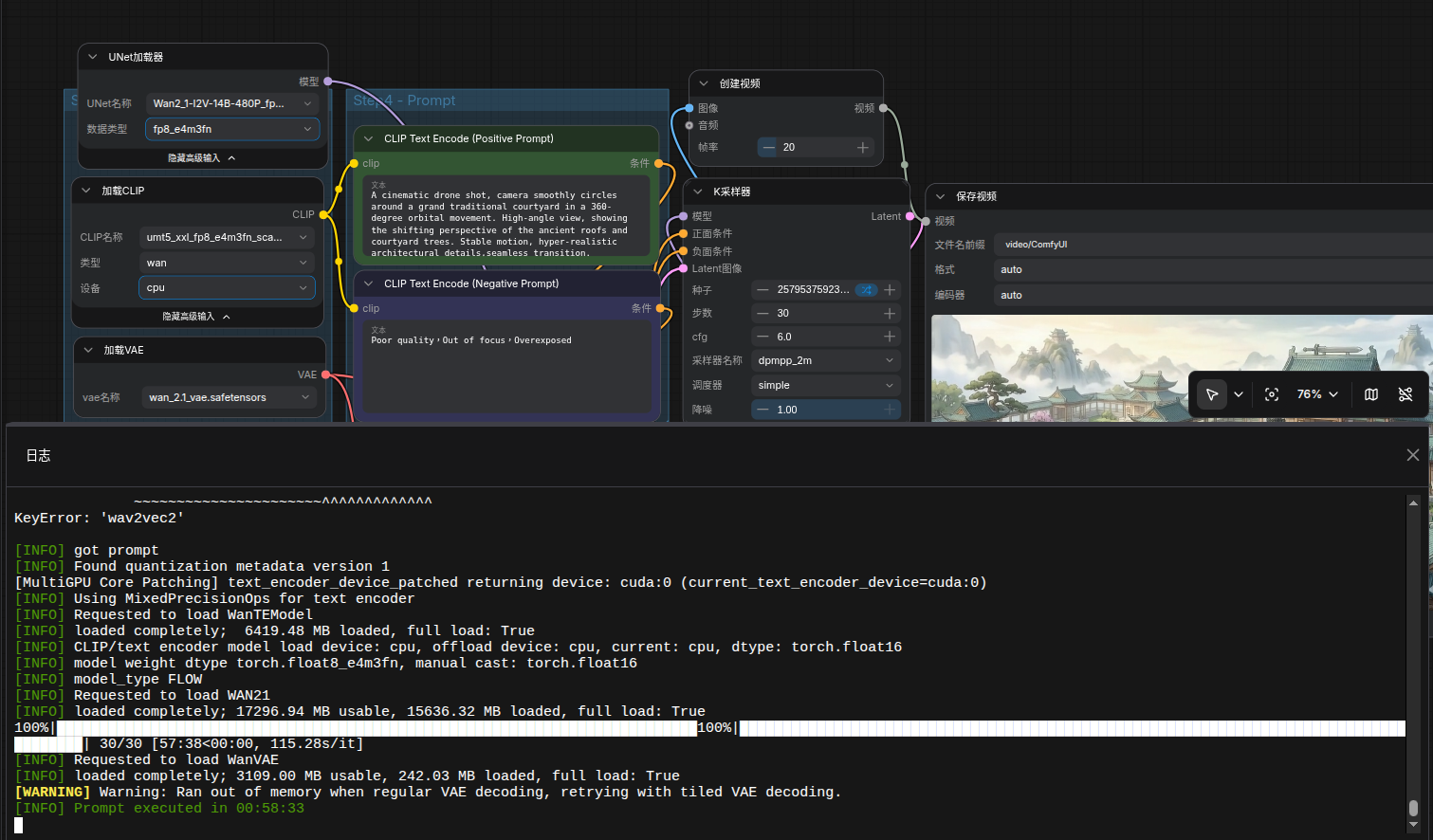
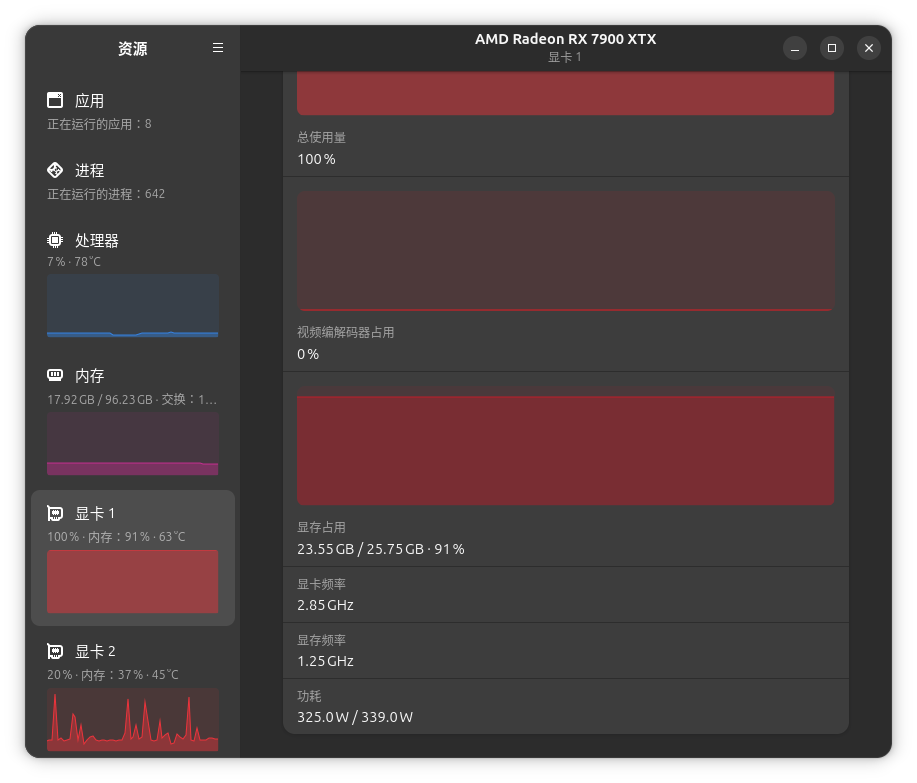
渲染一段4秒480p的图生视频用了58分钟,显卡也是全力在跑的,为什么那么慢呢?我是刚刚接触Ubuntu系统的小白,请教各位大神我是不是哪里设置错了。