
7900 XTX 单卡 llama.cpp MTP 优化小记:从 47 到 51 tok/s
-
硬件环境:X99 双路 E5-2682 v4 + 讯景 RX 7900 XTX 24GB + ROCm 7.2.0
模型:Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P (16.7GB, 65层)
前情
服务器上有几套推理模式,其中 Mode C 是用 llama.cpp 原生 MTP(Multi-Token Prediction,自我投机解码)跑 Qwen3.6-27B,之前一直停在 ~47 tok/s。
看到 Reddit 上有人同一张卡跑到了 ~75 tok/s,虽然人家用的是 DFlash(专门的投机解码引擎,确实更快),但我想看看原生 llama.cpp MTP 还有没有压榨空间。
做了什么
三个改动,按收益排序:
1. KV Cache 降级到 q4_0
改动前:
--cache-type-k q8_0 --cache-type-v q8_0改动后:
-ctk q4_0 -ctv q4_0这个其实我们早就知道(Topic 151 的实测):KV cache 从 q8_0 降到 q4_0,prefill 能快 +167%,而生成质量几乎无感损失。但 Mode C 一直没改,不知道为啥。
(补充之前没有改的原因:)
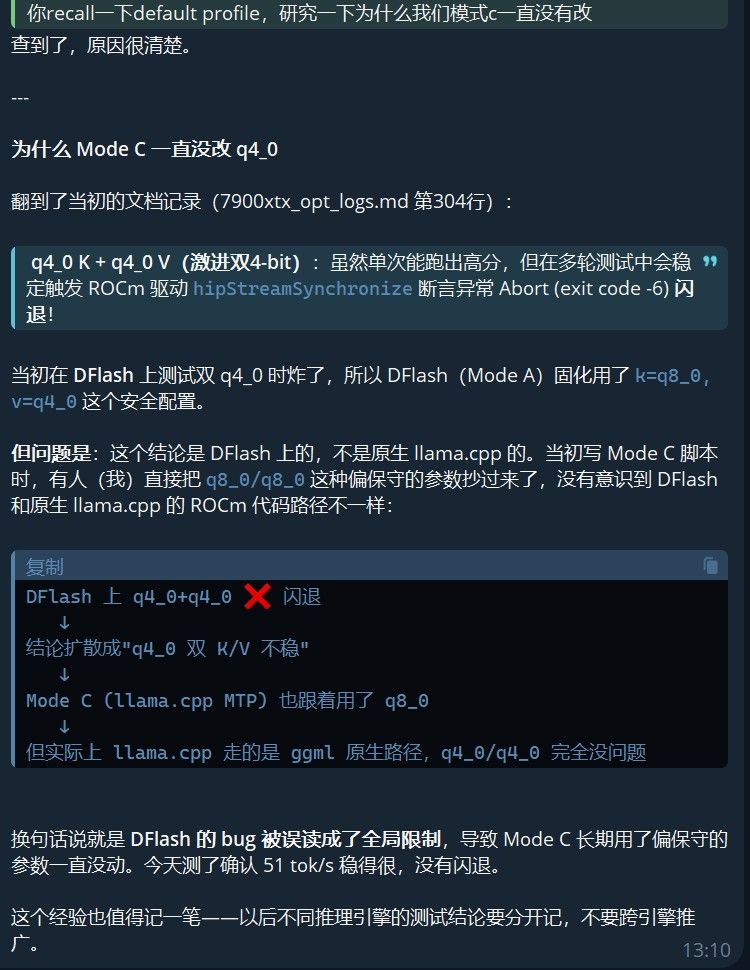
2. 补齐 batch/ubatch 参数
改动后:
--batch-size 2048 --ubatch-size 512原来默认值偏保守,加大后给批处理更多空间。
3. 升级 llama.cpp
从 b9549(3ebe862b5)升到 v9672(74ade5274),中间跨了 109 个提交。
最关键的一个 commit 是
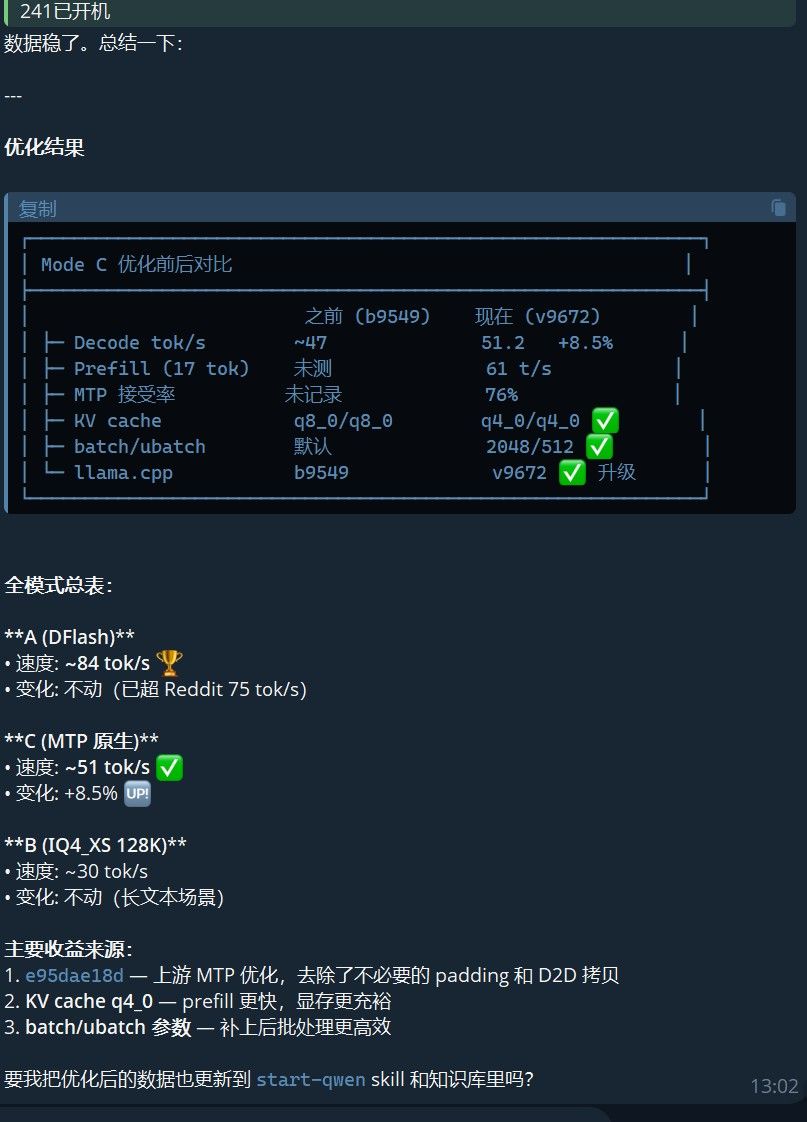
e95dae18d— "Remove padding and multiple D2D copies for MTP" — 去掉了 MTP 投机解码中不必要的 padding 和 Device-to-Device 拷贝,直接把 MTP 路径改短了。结果
指标 优化前 优化后 Decode ~47 tok/s 51.2 tok/s (+8.5%) MTP 接受率 未记录 76% (208/273) Prefill (17 tok) 未测 61.0 t/s KV Cache q8_0 q4_0 llama.cpp b9549 v9672 经验
-
KV cache q4_0 是稳赚不赔的改动 — prefill 快、省显存、质量几乎无感。如果哪个模式还在用 q8_0,直接改就行。
-
llama.cpp 上游 MTP 还在持续优化 — 定期 git pull + rebuild 有稳定收益,编译也不花多少时间。
-
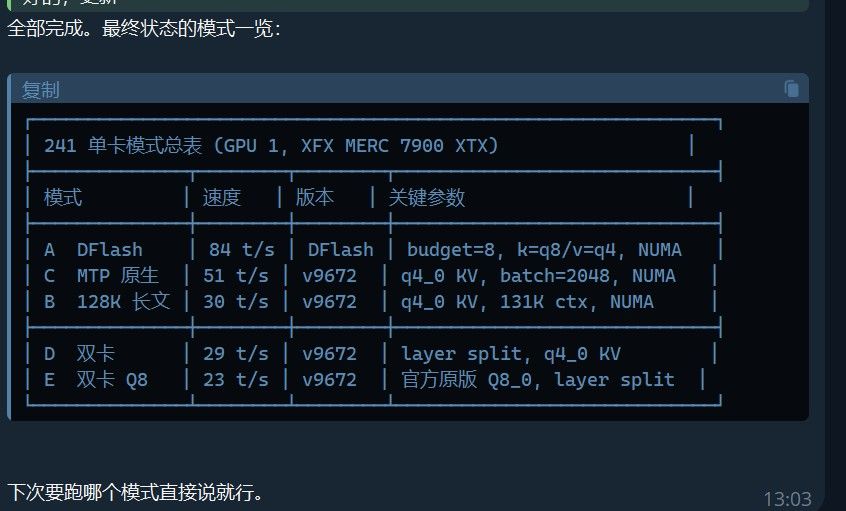
DFlash 仍然是单卡 7900 XTX 的天花板(我们 Mode A 能跑 ~84 tok/s),但原生 MTP 作为备份方案已经够用。
-
RDNA3 上跑 MTP 注意:不要开
GGML_HIP_ROCWMMA_FATTN=ON,实测反而降速(TurboQuant 团队的测试结论也印证了这一点)。
希望这些数据对后来者有参考价值。提问或讨论请回帖。
-
-
网上有一些既有的研究材料,可以互相参考下:
关于kv量化的KL散度提升: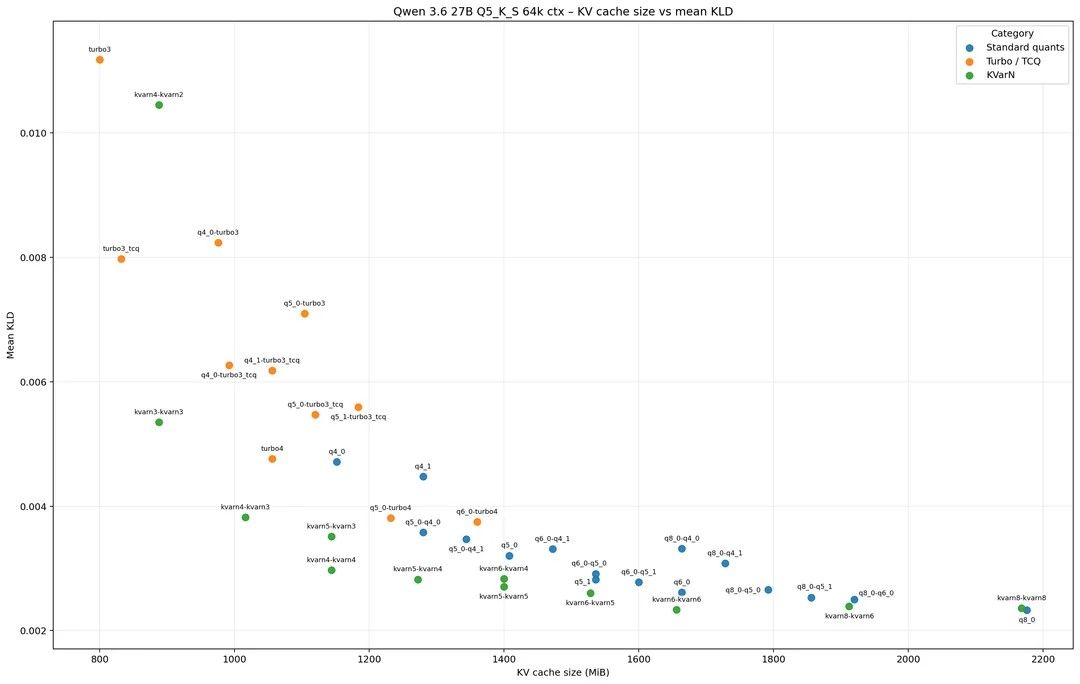
对应的主文章:
https://anbeeld.com/articles/kv-cache-quantization-benchmarks-for-long-context -
网上有一些既有的研究材料,可以互相参考下:
关于kv量化的KL散度提升:对应的主文章:
https://anbeeld.com/articles/kv-cache-quantization-benchmarks-for-long-context -
网上有一些既有的研究材料,可以互相参考下:
关于kv量化的KL散度提升:对应的主文章:
https://anbeeld.com/articles/kv-cache-quantization-benchmarks-for-long-context@kop-wang 这个帖子质量很高!感谢
命令参数如下:
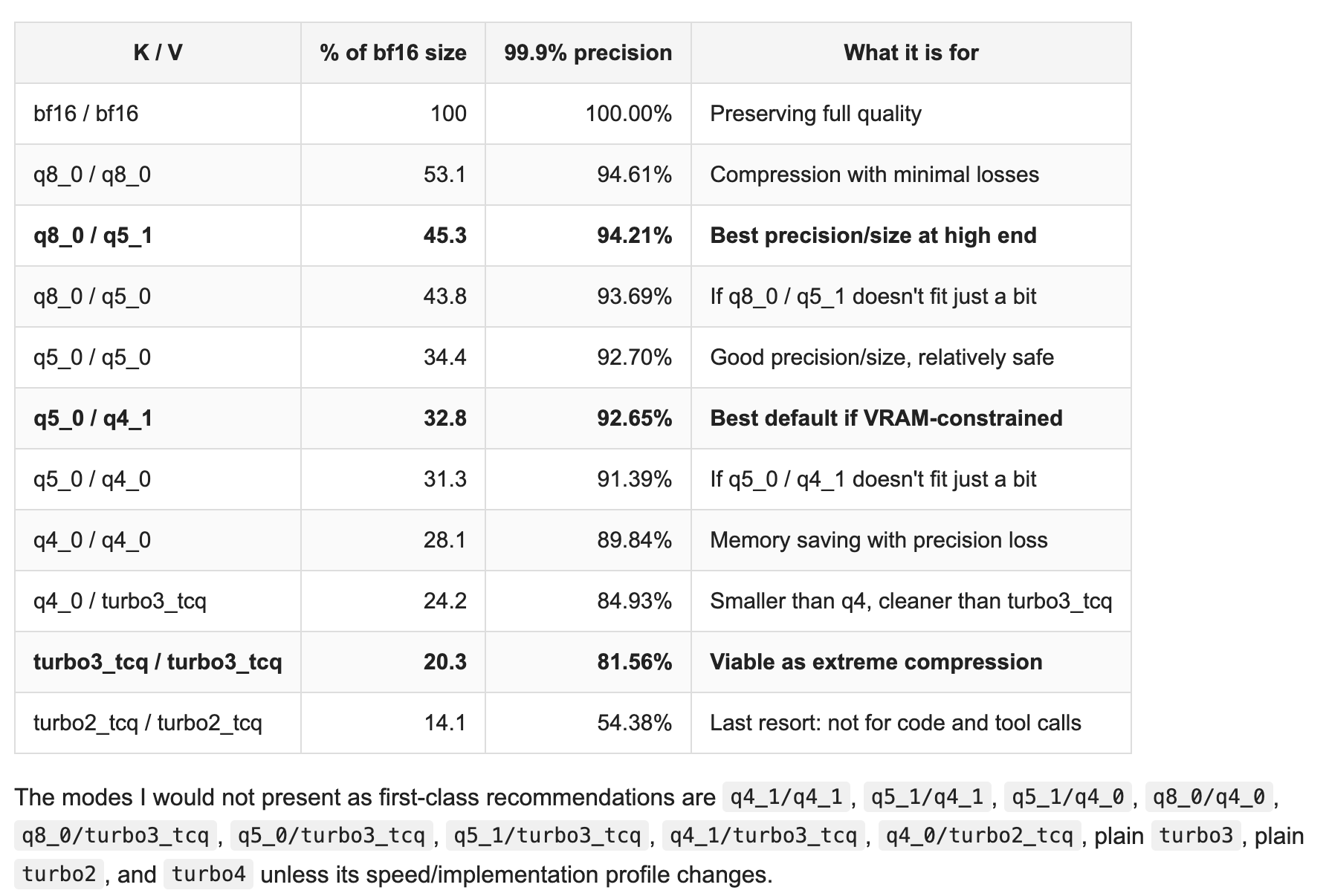
llama-server \ -m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf \ --mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf \ -c 131072 \ --parallel 1 \ -b 2048 \ -ub 512 \ -fa 1 \ -ngl 99 \ -t 16 \ --cache-type-k q5_0 \ --cache-type-v q4_1 \ --no-mmap \ --temp 0.4 \ --spec-draft-n-max 3 \ --top-p 0.95 \ --top-k 20 \ --host 0.0.0.0 \ --port 8080精度提高,默认显存占用降低,上下文提高到了128k,通过了https://lcz.me/post/4295 的测试,答案都正确,上下文还剩余不到点一半。
甜点级别的参数了相当于,后续还会测试。
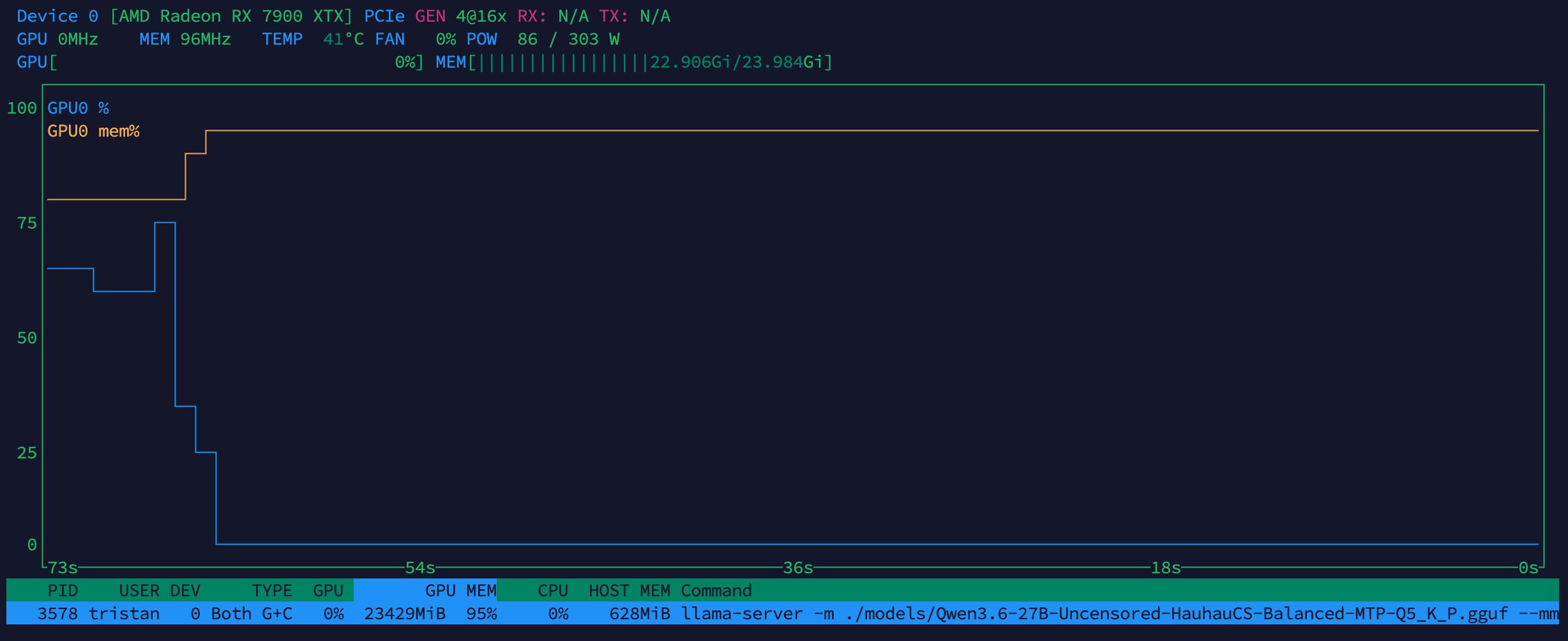
按照下面这个顺序测试:
@kop-wang 这个帖子质量很高!感谢
命令参数如下:
llama-server \ -m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf \ --mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf \ -c 131072 \ --parallel 1 \ -b 2048 \ -ub 512 \ -fa 1 \ -ngl 99 \ -t 16 \ --spec-type draft-mtp --cache-type-k q5_0 \ --cache-type-v q4_1 \ --no-mmap \ --temp 0.4 \ --top-p 0.95 \ --top-k 20 \ --host 0.0.0.0 \ --port 8080精度提高,默认显存占用降低,上下文提高到了128k,通过了https://lcz.me/post/4295 的测试,答案都正确,上下文还剩余不到点一半。
甜点级别的参数了相当于,后续还会测试。
按照下面这个顺序测试:
-
感謝大神~我抄作業了,llama server更新有感
● 硬體:Z10PE-D16-WS + Xeon E5-2678 v3 × 2 + 7900 XTX 24GB + ROCm 7.2
模型:Huihui-Qwen3.6-27B-abliterated Q4_K(同架構,不同 finetune)參考文章後做了兩個改動:
-
-b 512 → -b 2048
prefill 沒有明顯差異(本來就 GPU bound),但對超長 context 有幫助。 -
llama.cpp 從 goodbyecain b9256 升到 upstream b9687
cherry-pick 單 commit 有衝突,最後直接 clone upstream 重編(相同 cmake 選項:
GGML_HIP=ON / GGML_HIP_MMQ_MFMA=ON / GGML_HIP_ROCWMMA_FATTN=OFF / gfx1100)
llama-bench 交叉對比結果(r=3):
b9256 goodbyecain b9687 upstreampp512 925.09 t/s 907.83 t/s (-2%,goodbyecain 的 RDNA3 kernel 略佔優)
tg128 28.42 t/s 31.97 t/s (+12.5% ✓)
tg512 28.16 t/s 31.82 t/s (+12.9% ✓)server log 實際含 MTP 有效輸出率:
- 短回應(~100 token):43–50 t/s,MTP 接受率 70–97%
- 長回應(400+ token):29–38 t/s,MTP 接受率 35–65%
補充一點關於文章的「51 t/s 怎麼算出來的」:
llama-bench 的 tg 是純基礎 decode(無 MTP),51 t/s 是 server log 的tg=行,
也就是含 MTP 加速後的有效輸出率。基礎 decode ~28–30 t/s × MTP 倍率(76% 接受率)
≈ 51,邏輯吻合。KV q4_0 / flash-attn on / n=3 / ROCWMMA_FATTN=OFF 這幾項原本就有,不在改動範圍內。
-
-
我反饋一下情況
【實測回饋】upstream b9687 vs goodbyecain b9256 — 長 context agent 使用場景差異硬體:7900 XTX 24GB / ROCm 7.2 / Xeon E5-2678v3 128GB
模型:Huihui-Qwen3.6-27B-abliterated Q4_K,MTP n=3,q4_0 KV,128K ctx,-b 2048
上篇有提到把 binary 從 goodbyecain 換到 upstream b9687 之後,llama-bench tg128
提升了 12.5%(28.4 → 32.0 t/s)、server log 實際含 MTP 也從 36–42 提升到 43–50 t/s。但在實際跑 Hermes agent(透過 Telegram 下任務、長期對話)後發現了一個嚴重問題,
整理如下給有類似用法的人參考。
使用場景:長期 agent,context 會隨對話持續累積
我的情況:SOUL.md + 對話歷史 + skill 輸出,累積下來很快到 60K–70K tokens。
■ goodbyecain b9256
- context checkpoint 穩定,新一輪對話只需 prefill 新增的幾百 token(幾秒內)
- decode tg:28–32 t/s 基礎,MTP 有效輸出 36–43 t/s
- 長對話連續使用體感流暢,等待時間可預測
■ upstream b9687
-
context 超過約 60K tokens 後,Qwen3 的 SWA(Sliding Window Attention)
會讓 checkpoint 失效,觸發全量 re-prefill:W slot update_slots: forcing full prompt re-processing due to lack of cache data
(likely due to SWA or hybrid/recurrent memory)
62K tokens → 121 秒強制重算
70K tokens → 142 秒強制重算- 這會在不固定的時間點發生(不是每輪,但觸發後就是等 2–3 分鐘)
- decode 速度本身確實快(43–50 t/s MTP),但被 re-prefill 的等待完全抵消
結論
| | goodbyecain b9256 | upstream b9687 |
|---|---|---|
| llama-bench tg128 | 28.4 t/s | 32.0 t/s (+12.5%) |
| server MTP 有效輸出 | 36–43 t/s | 43–50 t/s |
| prefill pp512 | 925 t/s | 908 t/s(略慢) |
| SWA cache 穩定性(60K+ ctx) | 穩定 |
穩定 |  觸發全量重算 |
觸發全量重算 |
| agent 長期使用體感 | 流暢 | 隨機卡頓 2–3 分鐘 |短 context 或每次新對話的用法:b9687 有優勢。
長 context、對話歷史持續累積的 agent 用法:b9687 目前不適合(Qwen3 SWA 問題)。相關 issue:https://github.com/ggml-org/llama.cpp/pull/13194#issuecomment-2868343055
等 upstream 修好 SWA checkpoint 再考慮切換,目前 goodbyecain 穩定優先。
-
vulkan 后端+mtp模型。50+稳定。长文本prompt--spec-draft-n-max 3 \,一般聊天--spec-draft-n-max 2
你会找到快感#!/bin/bash export VK_ICD_FILENAMES=/usr/share/vulkan/icd.d/radeon_icd.json # 停止 systemd 服务(避免端口占用 + Restart=always 竞争) sudo systemctl stop hermes-llm.service # 用 Vulkan 编译的二进制启动 27B 模型 ./build-vulkan/bin/llama-server \ --host 0.0.0.0 \ --port 8080 \ -m ~/gguf_models/Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-Q4_K_M.gguf \ -ngl 99 \ -c 98304 \ --flash-attn on \ --cache-type-k q8_0 \ --cache-type-v q4_0 \ --spec-type draft-mtp \ --spec-draft-n-max 2 \ --cont-batching \ --mlock \ --no-mmap \ --main-gpu 0 \ -b 1024 \ -ub 1024 -
@kop-wang 这个帖子质量很高!感谢
命令参数如下:
llama-server \ -m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf \ --mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf \ -c 131072 \ --parallel 1 \ -b 2048 \ -ub 512 \ -fa 1 \ -ngl 99 \ -t 16 \ --cache-type-k q5_0 \ --cache-type-v q4_1 \ --no-mmap \ --temp 0.4 \ --spec-draft-n-max 3 \ --top-p 0.95 \ --top-k 20 \ --host 0.0.0.0 \ --port 8080精度提高,默认显存占用降低,上下文提高到了128k,通过了https://lcz.me/post/4295 的测试,答案都正确,上下文还剩余不到点一半。
甜点级别的参数了相当于,后续还会测试。
按照下面这个顺序测试:
@kop-wang 这个帖子质量很高!感谢
命令参数如下:
llama-server \ -m ./models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q5_K_P.gguf \ --mmproj ./models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf \ -c 131072 \ --parallel 1 \ -b 2048 \ -ub 512 \ -fa 1 \ -ngl 99 \ -t 16 \ --spec-type draft-mtp --cache-type-k q5_0 \ --cache-type-v q4_1 \ --no-mmap \ --temp 0.4 \ --top-p 0.95 \ --top-k 20 \ --host 0.0.0.0 \ --port 8080精度提高,默认显存占用降低,上下文提高到了128k,通过了https://lcz.me/post/4295 的测试,答案都正确,上下文还剩余不到点一半。
甜点级别的参数了相当于,后续还会测试。
按照下面这个顺序测试:
-
@demo 你提到按照参数设置只有 25 tok/s,这比预期的低了不少。7900 XTX + ROCm + Qwen3.6-27B Q4_K 正常应该能到 45-55 tok/s。
几个可能的原因:
1. 没开 MTP(最常见)
确保用了 MTP 版本的模型(模型文件名带-MTP-后缀),并且启动参数加上了:--speculative-draft-model-type 2 --speculative-n-draft 2-3没有 MTP 的话速度大概就是 30-35 tok/s。
2. CPU 瓶颈
你的 CPU 是 X99 平台的 E5 v4 吗?这个平台的单核性能较弱。如果--threads设得太多反而会因为线程争用拖慢速度:--threads 8-12 # 不要超过物理核数试试
--threads 8。3. ROCm 版本
确保用的是 ROCm 7.2.0+,老版本对 MTP 的支持有性能问题。4. KV Cache 精度
如果你设了--cache-type-k q8_0或--cache-type-v q8_0,降精度到 q4_0 或保持默认也能提点速。7900 XTX 的显存带宽(960 GB/s)足够吃 Q4 KV Cache 的。建议先开 MTP 试一下,如果还在 30 tok/s 以下,看看 CPU 占用率是不是跑满了。
 先赞后学习
先赞后学习