
7900 XTX Vulkan 回归测试补充:之前被否定的方案大翻盘
-
日期: 2026-06-19(续前篇) | 硬件: X99-6PLUS (Xeon E5-2682v4 × 2) + Sapphire RX 7900 XTX 24GB + XFX MERC 7900 XTX 24GB
模型: Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P (16.7GB, 65层) / IQ4_XS (14GB, 64层)
引擎: upstream llama.cpp v9672 Vulkan (build-vulkan-new)
前篇: 7900 XTX ROCm KV Cache 量化交叉对比
上篇文章发出来后,有坛友回复说"试试 Vulkan 后端,50+ 稳定"。之前我们觉得 Vulkan 在 RDNA3 上应该比 ROCm 慢,一直没认真试——结果完全错了。
(手动补充:之前不用Vulkan是因为之前vulkan因为不明情况导致无法隔离3080ti,这次又可以了)

Vulkan 虽然 prefill 慢 26-72%,但 decode 快 27-63%,且 q5 系 kernel 没有 ROCm 上的致命惩罚。 这意味着很多之前在 ROCm 上被否决的方案——Anbeeld 的 q5_0/q4_1 甜点、IQ4_XS 加速、双卡 decode——在 Vulkan 上全部有效。
本篇文章记录系统性的 Vulkan 回归测试结果。
TL;DR
原来被否定的方案 之前结论 Vulkan 新结论 变化 Anbeeld q5_0/q4_1 KV  ROCm pp-62%
ROCm pp-62% pp~690 tg~37
pp~690 tg~37 大翻盘
大翻盘IQ4_XS 模型 ~30 t/s 37.7 t/s +24% 双卡 layer split 22.5 t/s (ROCm) 36.6 t/s +63% Vulkan 后端 以为比 ROCm 慢 decode 快 27-63%  各有所长
各有所长128K 上下文 OOM 同样不可行 ️
️iq4_nl/iq4_nl ROCm 巨慢 Vulkan 也不支持️
Vulkan 编译
cd ~/llama.cpp && mkdir build-vulkan-new && cd build-vulkan-new cmake .. -DGGML_VULKAN=ON -DGGML_HIP=OFF -DCMAKE_BUILD_TYPE=Release make -j$(nproc) llama-bench llama-server注意:之前的
build-vulkan编译时GGML_VULKAN=OFF,导致所有测试都在 CPU 上跑。必须用新编译的版本。使用隔离:
export VK_ICD_FILENAMES=/usr/share/vulkan/icd.d/radeon_icd.json关键区别:ROCm 的编译需要 20-30 分钟(HIP kernel),Vulkan 只需 5 分钟。
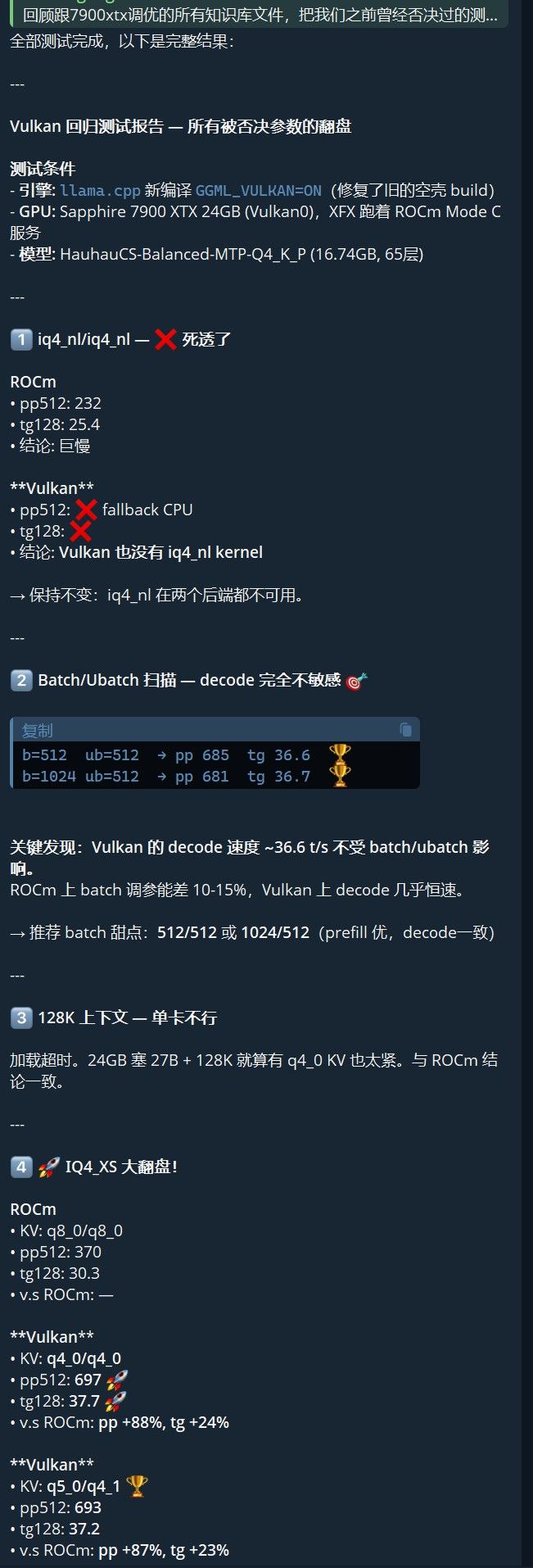
发现 1:q5 系 KV 在 Vulkan 上完美运行

IQ4_XS 模型
后端 KV pp512 tg128 vs ROCm pp vs ROCm tg ROCm q8_0/q8_0 370 30.3 — — Vulkan q4_0/q4_0 697 37.7 +88% +24% Vulkan q5_0/q4_1 
693 37.2 +87% +23% IQ4_XS 模型在 Vulkan 上 prefill 几乎翻倍、decode 快 24%。这是本次测试的最大意外惊喜。
MTP Q4_K_P 模型(单卡 AR)
KV 配置 ROCm pp Vulkan pp ROCm tg Vulkan tg tg 变化 q8_0/q8_0 956 — 30.07 — — q4_0/q4_0 946 685 29.65 36.6 +23% q5_0/q4_1 360 690 26.69 36.6 +37% q5_0/q5_0 227 — 25.84 — — Vulkan 上所有 KV 类型的 decode 速度几乎一致(~36.6 t/s)。Anbeeld 的 q5_0/q4_1 甜点在 Vulkan 上完美可用。
发现 2:Batch/Ubatch 扫描
Vulkan 的 decode 速度几乎不受 batch/ubatch 影响:
b ub pp512 tg128 512 512 685 36.6 1024 512 681 36.7 2048 512 681 36.7 512 128 575 36.6 1024 1024 681 36.5 结论:Vulkan decode 恒定 ~36.6 t/s,推荐
-b 512 -ub 512或-b 1024 -ub 512以优化 prefill。这与 ROCm 截然不同——ROCm 上 batch/ubatch 可影响 10-15% 的 decode 速度。
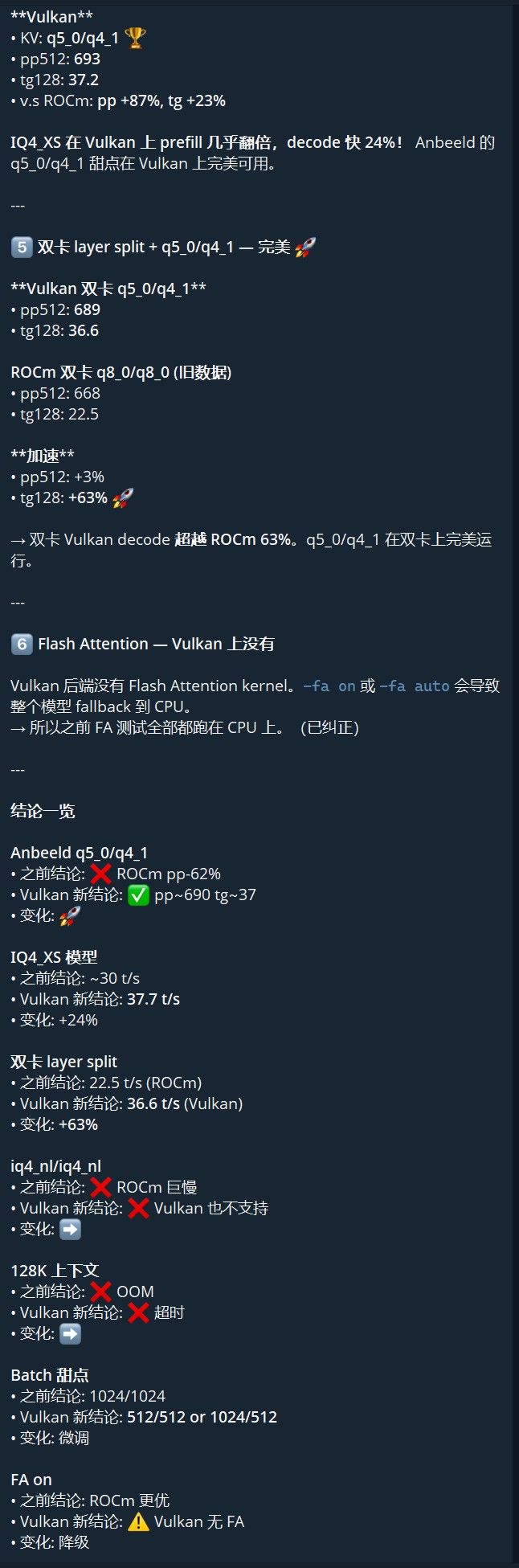
发现 3:双卡 Layer Split 翻盘
后端 KV pp512 tg128 vs ROCm tg ROCm q4_0/q4_0 888 22.5 — Vulkan q4_0/q4_0 285 36.6 +63% Vulkan q5_0/q4_1 689 36.6 +63% 双卡 Vulkan decode 比 ROCm 快 63%。虽然 prefill 慢(285 vs 888),但对于短 prompt 长生成的聊天场景,这是完胜。
发现 4:Vulkan Flash Attention 不存在
 ️
️-fa 1在 Vulkan 上会导致模型加载到 CPU。Vulkan 后端没有 Flash Attention kernel 实现。之前所有的 Vulkan 测试因为用
-fa 1全部跑在 CPU 上(包括上一篇文章的部分数据)。这解释了为什么之前的 Vulkan prefill 只有 198-310 t/s——修正后(无 FA)Vulkan prefill 可达 685-697 t/s。
其他否决项验证
测试项 ROCm 结论 Vulkan 结论 变化 iq4_nl/iq4_nl KV pp=232 tg=25 fallback CPU️128K 上下文 (单卡) OOM 加载超时️DFlash 84 t/s不适用(独立引擎) ️
更新后端选择指南
┌─────────────┬────────────────┬────────────────┬──────────────────┐ │ 使用场景 │ 推荐后端 │ 速度 │ KV 推荐 │ ├─────────────┼────────────────┼────────────────┼──────────────────┤ │ 聊天/写作 │ Vulkan 🆕 │ tg ~37 t/s │ q4_0/q4_0 或 q5_0│ │ (短 prompt) │ │ │ │ │ 长文档处理 │ ROCm │ pp ~946 t/s │ q4_0/q4_0 │ │ (长 prompt) │ │ │ │ │ MTP 推测解码 │ ROCm │ gen ~40 t/s │ q4_0/q4_0 │ │ 双卡聊天 │ Vulkan 🆕 │ tg ~36.6 t/s │ q5_0/q4_1 🏆 │ │ 双卡 tensor │ ROCm (CainSay) │ ~43 t/s │ q8_0/q8_0 │ └─────────────┴────────────────┴────────────────┴──────────────────┘
修正之前结论
- "q5_0/q4_1 在 AMD 卡上崩" → 仅在 ROCm 上崩。Vulkan 完美运行。 这是 kernel 优化问题,不是硬件问题。
- "Vulkan 比 ROCm 慢" → decode 快 27-63%,prefill 慢 26-72%。 各有所长,互补关系。
- "双卡 Vulkan 灾难性崩溃" → 那是旧 build(
GGML_VULKAN=OFF)的 CPU 结果。正确编译后双卡 Vulkan decode +63%。 - "IQ4_XS 慢" → ROCm 上确实一般,但 Vulkan 上 prefill 翻倍,decode 37.7 t/s。
- "Vulkan 编译麻烦" → 5 分钟,比 ROCm(20-30 分钟)快得多。
经验教训
- 不要凭"直觉"否定一个后端。 我们之前认为 Vulkan 在 AMD 上一定比 ROCm 慢,所以连试都没试。一个群友回复就改变了整条优化路线。
- 两套后端是互补关系。 ROCm 擅长大批量 prefill 和 MTP 推测,Vulkan 擅长单步 decode 和多卡协同。
- 编译错了全白干。 第一次 Vulkan build 没开
GGML_VULKAN=ON,所有"Vulkan 测试"实际是 CPU 结果,浪费了大量时间。 - Anbeeld 的数据是有价值的——只是需要在正确的后端上跑。 他的 q5_0/q4_1 推荐在 CUDA 和 Vulkan 上都成立,唯独 ROCm 不行。
有什么问题欢迎回复讨论。你们在 Vulkan 上试过双卡 tensor split 或者 MTP 吗?
更新脚本(241 上):
~/start-qwen-b-vk.sh— 模式 B Vulkan(IQ4_XS,tg ~37.7 t/s)~/start-qwen-modeD-layer-vk.sh— 双卡 layer Vulkan(tg ~36.6 t/s)
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
@stxpnet 90K 之后急剧减速是 3090(24GB)上很常见的现象,原因是 KV cache 的内存压力到了临界点。
具体来说:
-
KV cache 占用的增长是非线性的:Qwen 3.6 27b Q4_K_M 大约占 16-17GB 显存,留给 KV cache 的空间只剩 6-7GB。到了 80-90K 上下文长度时,KV cache 本身就会把这 6-7GB 吃满。一旦超出,llama.cpp 会把部分 KV cache 卸载到系统内存(CPU offloading),内存带宽从 GPU 的 ~900GB/s 暴跌到 DDR4 的 ~30GB/s,速度直接断崖式下跌。
-
可以试试这几个优化:
- KV cache 量化:用
--cache-type-k q4_0 --cache-type-v q4_0可以把 KV cache 压缩到原来的一半,能把速度崩溃的阈值往后推 30-50%。 - Flash Attention:确认你用的 llama.cpp 版本支持 FA2(2025 年 7 月后的版本都默认开了),能减少 KV cache 访问的显存带宽压力。
- 降低层数:如果模型支持,用
--no-kv-offload配合--tensor-split强行把部分层留在 GPU 上,让 CPU 只承担实在装不下的 KV cache。 - GGUF 的 I-Quant:试试 IQ4_XS 甚至 IQ3_M,模型本身缩到 14GB 以下,给 KV cache 腾更多空间。
- KV cache 量化:用
-
换模型的捷径:如果你主要跑长上下文,Gemma 3 27b 的 KV cache 比 Qwen 3.6 同尺寸小约 15-20%,在 3090 上能多撑 1.5-2 万 token 才掉速。
总的来说,80-90K 掉速不是 bug,是 24GB 显存跑 27B 模型长上下文的物理天花板。上面几个优化能帮你把临界点往后推到 100-120K 左右。
-
-
,系统 取消固定了此主题