apple m5max 128G适不适合跑AI本地大模型?文生图 文生视频 跑代码编程适合吗?
-
给你个参考, M5pro
1, Qwen3.6 35b A3b, 64K上下文, prefill 1300+ , decode 50+, 很流畅.
2, Qwen3.6 27b+MTP, 64K上下文, prefill 300+, decode 13, 基本不可用.
3, 1024*1024 文生图, 大概10-20秒一张, SD, Flux, zImage 都在这个范围内.
4, 视频就别想了.M5max GPU核心数量和显存带宽都是 M5 pro 的一倍, 我认为原则上应该有 50%以上的提升. 你可以自己测算一下.
另外 M5max 128G 怎么也得4万rmb以上了.
-
给你个参考, M5pro
1, Qwen3.6 35b A3b, 64K上下文, prefill 1300+ , decode 50+, 很流畅.
2, Qwen3.6 27b+MTP, 64K上下文, prefill 300+, decode 13, 基本不可用.
3, 1024*1024 文生图, 大概10-20秒一张, SD, Flux, zImage 都在这个范围内.
4, 视频就别想了.M5max GPU核心数量和显存带宽都是 M5 pro 的一倍, 我认为原则上应该有 50%以上的提升. 你可以自己测算一下.
另外 M5max 128G 怎么也得4万rmb以上了.
@Tony-Wang 性能可以直接查出来的,这也是低sku硬件的优势之一吧XD https://omlx.ai/compare
对应的,GB10系硬件的性能:https://spark-arena.com/leaderboard
虚心交流,一起进步
-
@Tony-Wang 性能可以直接查出来的,这也是低sku硬件的优势之一吧XD https://omlx.ai/compare
对应的,GB10系硬件的性能:https://spark-arena.com/leaderboard
-
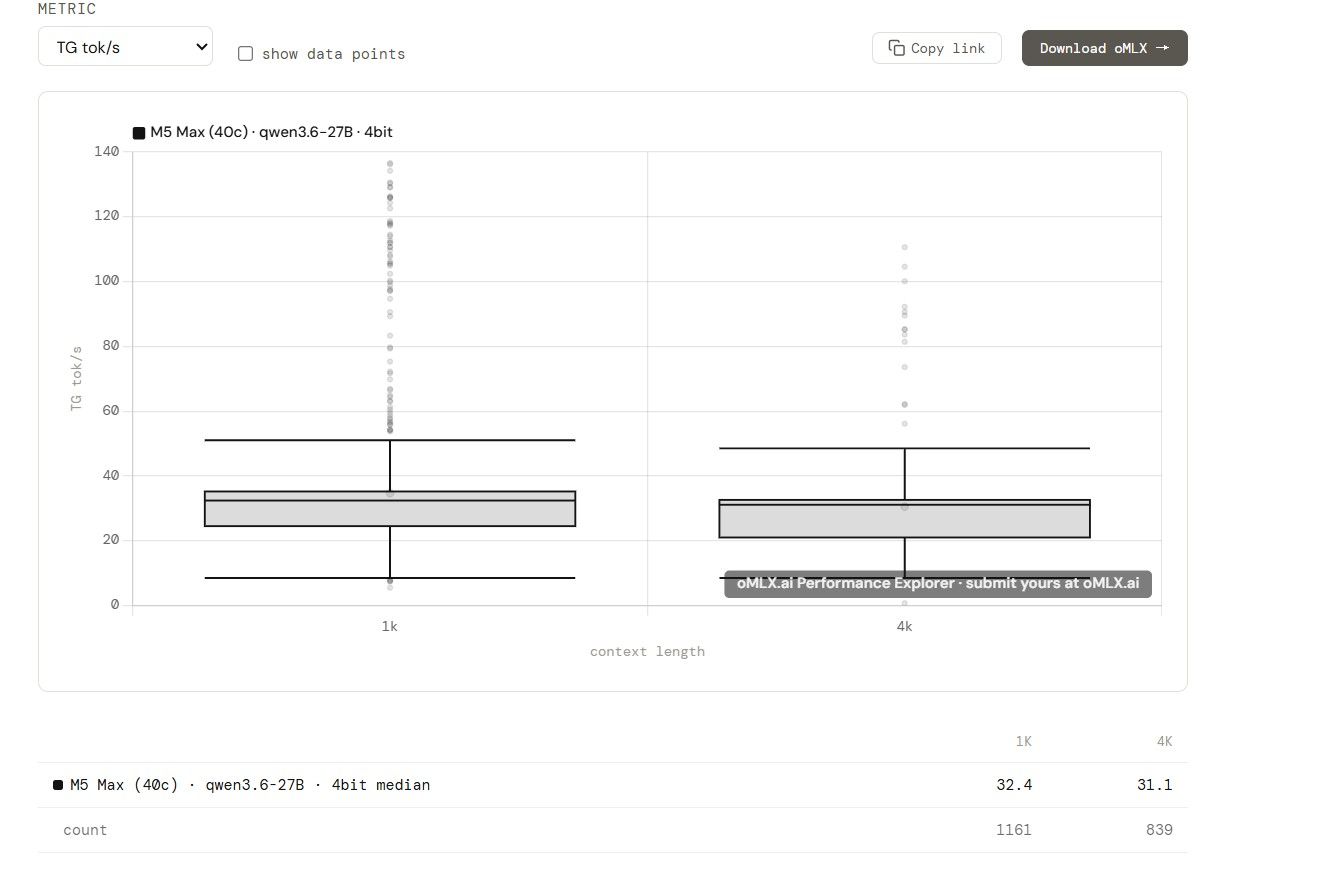
嗯, 我查了一下 M5max (40c) 和M5pro (20c) , qwen 3.6 27b 4bit, 4K上下文:
prefill 分别是 843:463 , 提升差不多 82%.
decode 分别是 31:17, 提升也是差不多 82%