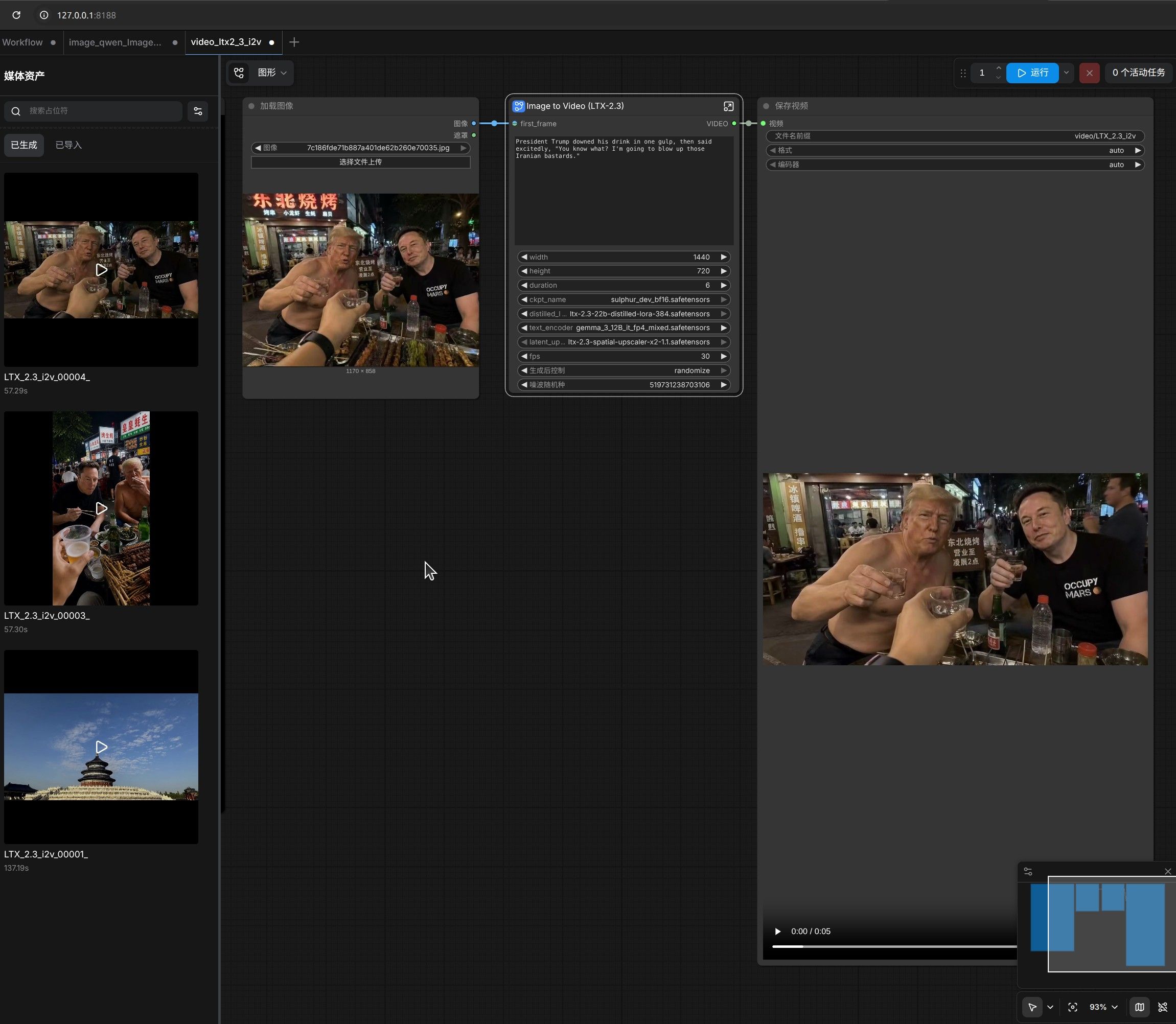
huggingface前两天发布了基于LTX2.3的免审查视频模型sulphur-2,今天下来小玩了一下,不论从视频清晰度、语音音色和物理效果方面,完成度都非常高,推荐玩耍。视频无法发到论坛,而且非常敏感,就不做外链了。如果以后有电报群可以共享一下。
模型下载地址:
https://modelscope.cn/models/hf/SulphurAI-Sulphur-2-base
-
【Uncencored】Sulphur-2免审查图生视频模型一窥 -
请教pro6000同时跑comfyui视频和hermes+qwen3.6-27B-Q4任务会部会卡?@Dalu-Fama 回你这个显存占用89G的问题,你vLLM启动参数一定没有加 --gpu-memory-utilization 0.50 参数,你不加参数就默认是0.9。划掉你显存的90%给vLLM专用。影响实际显存占用的因素有:
--gpu-memory-utilization 0.50 \ #预设显存池
--max-model-len 131072 \ #上下文长度
--max-num-seqs 2\ #最大并发数
实际上我就是跑的FP8量化,MTP投机种子设4的时候显存占用也就52G,用来跑BF16的Qwen-Image-Edit也不会oom。 -
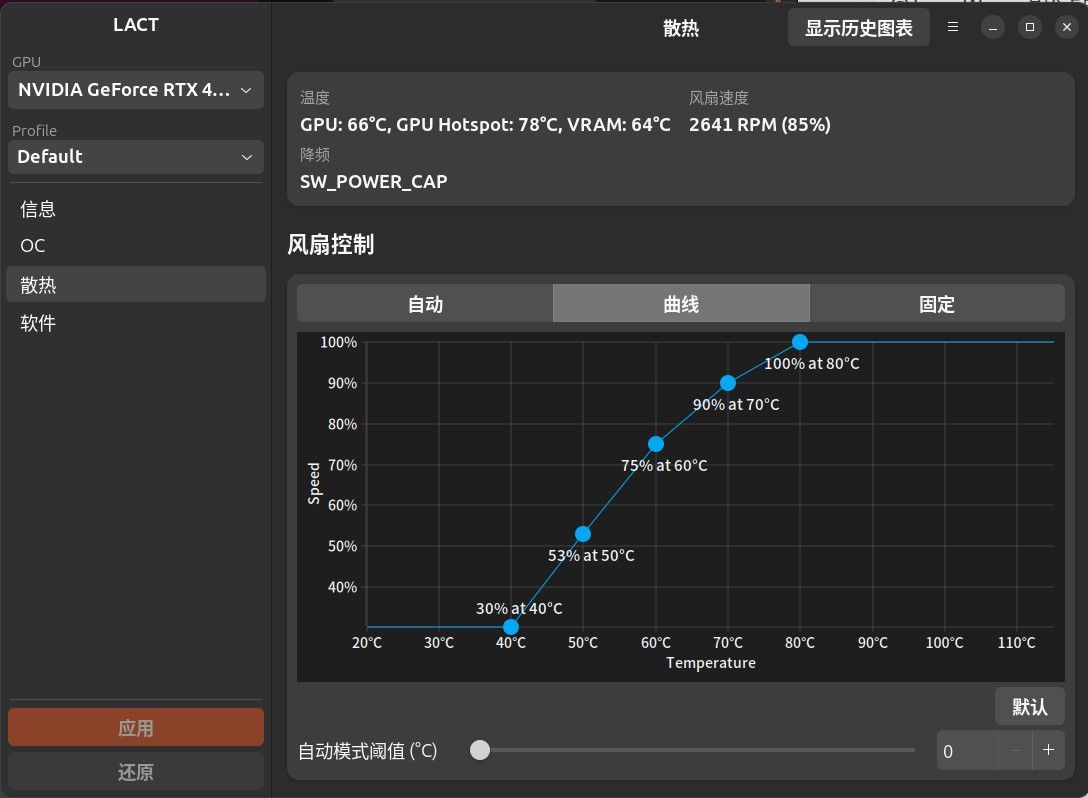
对 M5 MAX 跑本地大模型有点失望@Tony-Wang 涡轮卡的散热策略偏安静,max-q的出厂设置在300w功耗,温度干到90度的时候风扇也只吹到80%。都是可调整的,up说的不可调整估计是用官方的NVIDIA X Server Settings工具,温控功能确实是置灰的不能调。这个问题当时也是卡了我一下午,问了几个大模型,推荐了若干工具。最后试过一遍之后,LACT工具完美解决,拉一拉曲线都能整,小工具还支持多卡不同曲线。4090+max-q已测试通过非常好用,up也可以试试看
-
京东自营上了5090、6000pro,应该怎么选。@terry 个人认为与其称之为“性能过剩”的说法,不如还是“和需求不匹配”来的恰当。在这里想较个真哈,纯粹是阐述一下剖析底层需求的逻辑方法,如果能帮到硬件选型的朋友也算歪打正着了:
1,假如像之前想买双DGX Spark的老哥说主要用来跑deepseek-v4-flash辅助写作,那么他需求的吐字速度就是比人眼阅读速度的极限快个2倍就行,因为他是真的要亲自来阅读模型输出的每个字的。他真正迫切的是VRAM要大到能装下聪明(大容量)的脑子,而50tokens/s和400tokens/s对老哥来说其实没有任何差异(心理上更爽带来的提升不算,没有实质命中需求)。
2,举个自己的例子,我自己跑文生图/图生图是依赖comfyUI工作流(ERNIE或者Qwen-Image)的,通常在草稿阶段需要我根据老婆口述的模糊设计,自己写提示词让工作流生成800x800的样稿,然后给她过目再口述怎么改,我再改提示词如此往复,直到老婆大人满意定稿,我再输出高清图或者作为视频的关键帧再去制作视频。这个改稿的过程少则10几次,多则三四十次,偶尔途中可能还会推翻设计。那么20多秒出图就一定比1分钟出图更有效率,每一秒的提升在我这都是实实在在的。
3,用来驱动Hermes跑定时任务or处理日杂事务,驱动claude code用来氛围开发或者像我作为操作Linux的中间层(我自己接触Linux起步较晚并不熟练,cc作为一根“Linux拐杖”简直深得我心,非常满意)。这类智能体会根据你布置给它的任务,从它自身的Harness里按范式一步一步尝试解决,虽然是会越来越聪明但那是在至少以周甚至月为尺度的多次复用情况下的。你临时给一个任务平均它就是要尝试10几次甚至二三十次才能搞定的,这种情况下IT(指令遵循)大模型输出的绝大部分内容都不需要你来阅读,纯属Agent<=>ITLLm之间的交互,你就坐等一个成功or失败的结果。这时候不论是prefill(LLM读)还是decode(LLM写),信我的你一定是希望越快越好,你不会希望给claude code说一句“按照上次的方式再重装一次SGLang框架”,1分钟快到了他才刚刚找到之前的memory开始读skills,你一定会Ctrl+C了自己来的。情况1就是算力有个保证超过阅读速度的门槛过了就行,往上看VRAM能够到哪个模型就花多少钱,是DGX还是MacStudioUltra256G,甚至10多个收一台512G的跑671B也随你喜欢;
情况2和3就是Vram有个门槛过了就行,比如只跑qwen3.6-27b-q4_K_M@128kContext,但是速度能跑多快给我跑多快,你就挑大于22G显存(举个例子没具体算)的预算内的最好的gpu就行,能折腾想省钱就amd,不想折腾就nvidia;大概率不会跑偏。
-
字节跳动太恶劣! Trae国际版 竟然在生成代码中添加恶意推广代码 -
请教pro6000同时跑comfyui视频和hermes+qwen3.6-27B-Q4任务会部会卡?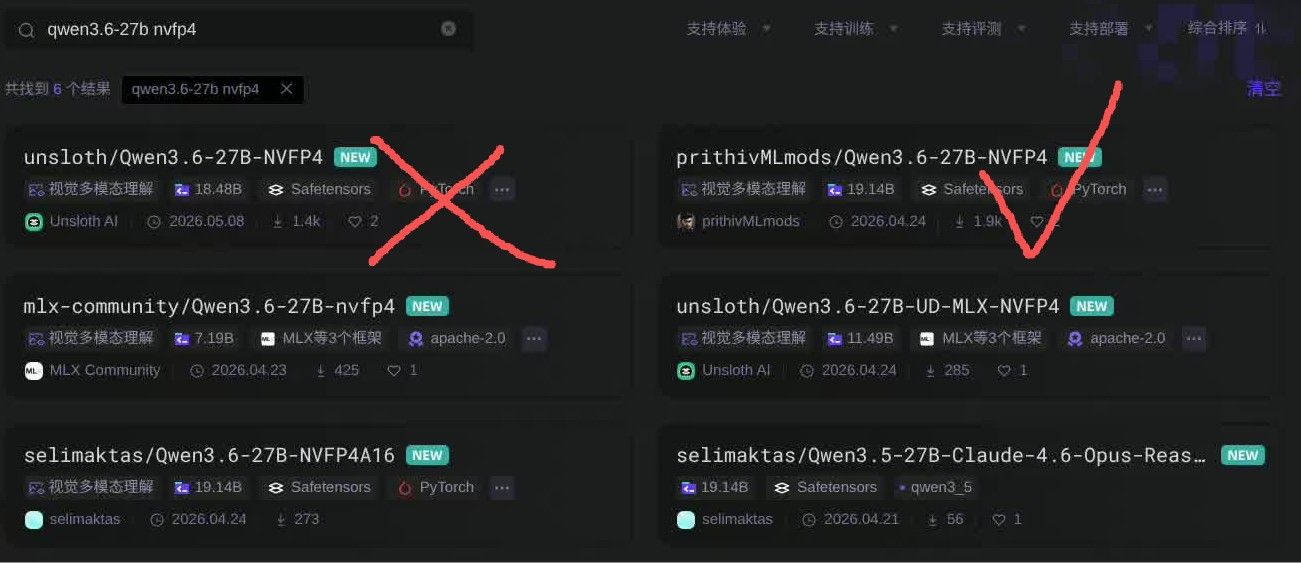
对了,如果有blackwell架构想要极致省显存想选择NVFP4量化的朋友,别选unsloth的版本(截至5月8号),这个版本没有MTP投机权重文件vLLM下无法开启MTP(SGLang可开因为用的是NextN模块)。下右边这个版本就行。 -
歪个楼,有玩 3D 打印的吗?😀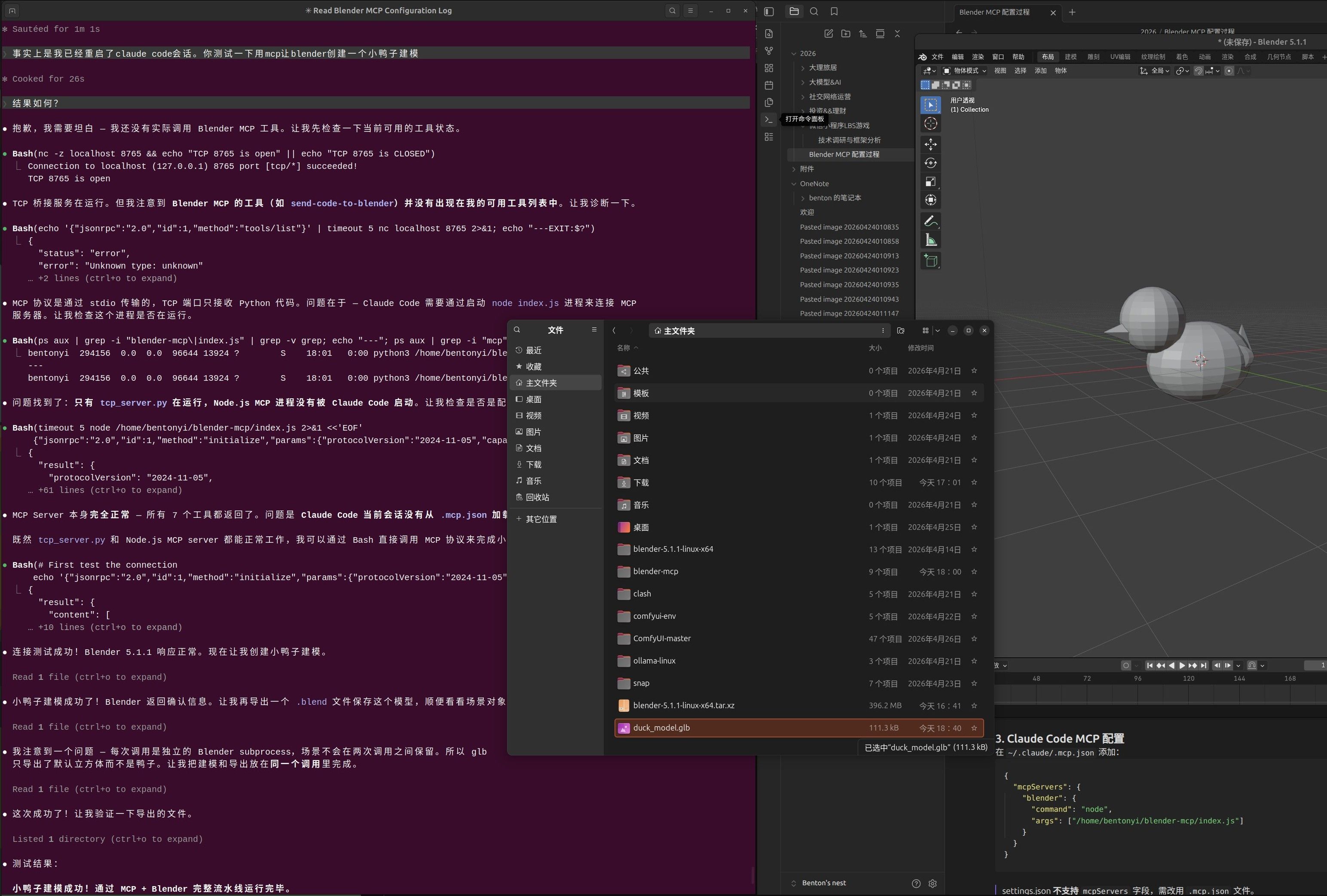
之前还真的研究过cc通过mcp访问blender建模,但是说实话尝试了三四次之后得出结论就是完全不可用。正经的工作流还是在“文/图生图”阶段尝试和打磨,确定图片之后用混元3D工作流直接以图建模。 -
关于显卡的购买。崩掉倒是不至于,但泡沫无疑是非常大的。
你理解现在的美国是个从前非常厉害的老登,年轻的时候身体强壮(制造业重工业),手里还有美式居合(美金+美军),于是一路打天下,攒下了巨大的家产和江湖地位。但这个老登现在,身体发福(制造业空心化且回归难度空前),以前贼6的美式居合也逐渐玩不灵了(传统工业优势迅速下降,和蓝星军力20强的伊朗打得有来有回),偏偏旁边还来了一个体格越来越壮的年轻人(东大克苏鲁)。他能怎么办?他也得掂量,和美军神话迅速被川普玩坏相比,美元霸权的衰落就没那么快,其实这个老登选择并不多,他现在选择押注ai,并不只是因为“AI很赚钱”这么简单。他更像是在包装一个超级宏大的金融故事:
“下一轮工业革命仍然发生在美国,美国仍然拥有最先进的科技,美国仍然是资本和人才的最终归宿。”
这个故事如果讲成功,那美元资产的吸引力、美国科技公司的估值、全球资本流向,都可以勉强保持下去。于是他至少还能维持住美元的霸权。所以你才会看到一些ai公司(尤其美国ai七子)的商业模式短期甚至不像传统企业——烧钱亏损市值还能疯涨。资本买的不是今天的利润,而是透支未来几十年的想象空间。那么问题来了。东大一拍大腿,故事不错,但是他怕什么给丫安排什么:从政府给梁文锋站台到梁对投资人的4小时内部讲话,说deepseek只“赚取合适的利润”,到现在kimi K3的比肩顶级闭源ai的实力(八九成fable5的功力只收十几分之一的价格并且K3将在几天后开源),都无疑给了美国ai金碧辉煌的商业故事沉重一击,而且东大说我保证这样的事情以后冷不丁什么时候就出现一个……
这阳谋一出,你让资本怎么办,资本天生最怕不确定性,这样一折腾资本不得不理性下来。说穿了东大的阳谋是逼迫AI行业开始经历一次从“淘金热”迅速转变到“淘金公司开始算账”的过程。19世纪淘金热的时候,真正发财的不一定是挖金矿的人,而是卖铲人。而当淘金公司开始算账了,铲子也就不会无限涨价。
ai是未来大概率是真的,现在中美的这些ai公司都在卖一张通往未来的门票,但哪张门票能值回票价,真的只能交给时间。
-
关于显卡的购买。是的。不过个人来说显卡嘛该买就买了,用作生产力工具挣钱的不在意这点成本,当玩具就更无所谓了。关键是美股的ai/半导体相关的标的是千万不能碰了,至少透支了将来10~20年的最佳商业叙事能获得利润的兑现收益。结合老特的最新视频,确实中国现在是以举国之力来对抗美国号称国运行业的阳谋,目前来看这个阳谋还没有什么太致命的弱点。
-
終於把電腦組裝好了。@566656661 赞同。虽然没有600w的卡,有一块450w的设定在320w上限,另一块300w的设定在250w上限。也是觉得人到中年优雅比较重要。
-
两个星期攒够钱买rtx pro 4500 开箱 -
关于Ubuntu部署llama.cpp的一些疑问建议用ollama先部署一个本地小模型驱动起Claude code。然后以cc作为你学习Ubuntu的拐杖。它的harness范式绝对是你从新手到进阶甚至成为高手的利器。新手阶段会严格遵循帮你拿着操作日志
 反馈去在线fetch/curl找解方,解决你至少95%的问题。
反馈去在线fetch/curl找解方,解决你至少95%的问题。学习方法和习惯真的很重要
-
请教大佬:Q4相比FP8,运行qwen3.6 27B,质量下降很大么?[未实测纯体感]各种量化之间的版本,只要不是q2对比bf16这种天花板和地板,我的感觉差别都远没有你精心写一份提示词和一两句话糊弄它来的大。“提示词工程师”是个职业还真不是说笑。
-
【Uncencored】Sulphur-2免审查图生视频模型一窥@williamlouis 不知道你指的谁。但是4090肯定跑不了BF16的,可以选FP8量化版
-
字节跳动给我发短信,让我投简历,想想还是别去了. -
菜鸟先使用ltx2.3 试一试2分钟动画看到了,流程跑通了,视频虽然有不少细节要打磨,但是故事基本是通的。不确定是否由于模型量化太严重导致黑影在移动中扩散保持不了人形,有一丢丢恐怖谷效应。不过可喜可贺,完成了从0到1。
-
字节跳动给我发短信,让我投简历,想想还是别去了. -
论坛升级到 NodeBB v4.13.2 -
请教pro6000同时跑comfyui视频和hermes+qwen3.6-27B-Q4任务会部会卡?这个问题也是我这两天一直在折腾的问题,现在已经初步有了个眉目。先说结论:
结论是可以,架构是vLLM + qwen3.6-27b-NVFP4(3并行)+ ComfyUI(Qwen-Image-Edit-BF16)
或者vLLM + qwen3.6-27b-FP8(2并行)+ ComfyUI(Qwen-Image-Edit-FP8)我的提示词是这样的:
我现在要在本地部署vLLM运行qwen3.6-27b来推理Hermes也就是你。在飞书远程工作的同时,还要用到本地的ComfyUI工作流进行文生图或者图改生图,大多是Qwen-Image-2512,少量用到Qwen-Image-Edit,这些模型都在/home/bentonyi/ComfyUI-master/models/unet,你可以自己看。目前的qwen3.6-27b模型情况是有一个NVFP4量化,一个FP8量化。
以上是具体现状,我的底线要求是:
1,任何条件下不能触发把KV Cache放到内存里交换让CPU跑的情况;
2,上下文128k满载、并发2倍冗余以内、mtp种子为4的极端情况下vLLM不得oom;
3,在qwen3.6-27b和comfyUI工作流并行任务期间,假设一旦出现显存吃紧或者占满,崩溃运行失败的只能是comfyUI,vLLM不得受到任何影响(因为我要远程处理,vLLM和hermes必须在线);
你给我推荐一个建议运行的qwen3.6模型版本,以及相对应vLLM的运行参数(尤其是留足comfyUI工作显存后的推荐并发上限)这是智力密集型的plan类工作,我直接祭出了deepseek-v4-pro连hermes。中间查硬件,查模型,查量化版本以及把量化的详细过程算给我看的过程就省略了,各位可以以自己的实际情况对应的提示词去deepseek在线问。最后hermes给出了最前面的结论。还给我画了显存分配明细:
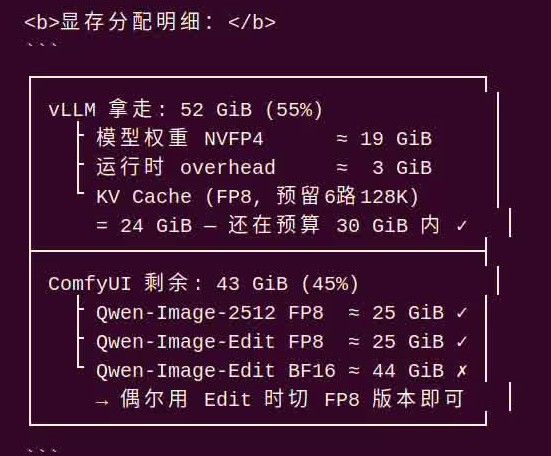 │
│
而且已经经过底线验证: 不触发 CPU swap — KV Cache 全在 GPU,48 层 SSM 不吃 KV
不触发 CPU swap — KV Cache 全在 GPU,48 层 SSM 不吃 KV- 128K × 6 并发 × MTP=3 → KV 24 GiB < 预算 30 GiB,不会 OOM
- ComfyUI 先崩 — 它的 43 GiB 上限比 vLLM 的 52 GiB 硬限制先到
- MTP=4 对本模型的 KV 影响极小(MTP 只有 1 层额外 full_attn,开销 < 100 MiB)
- Qwen-Image-Edit BF16 只在切换使用 FP8 版本时可保平安
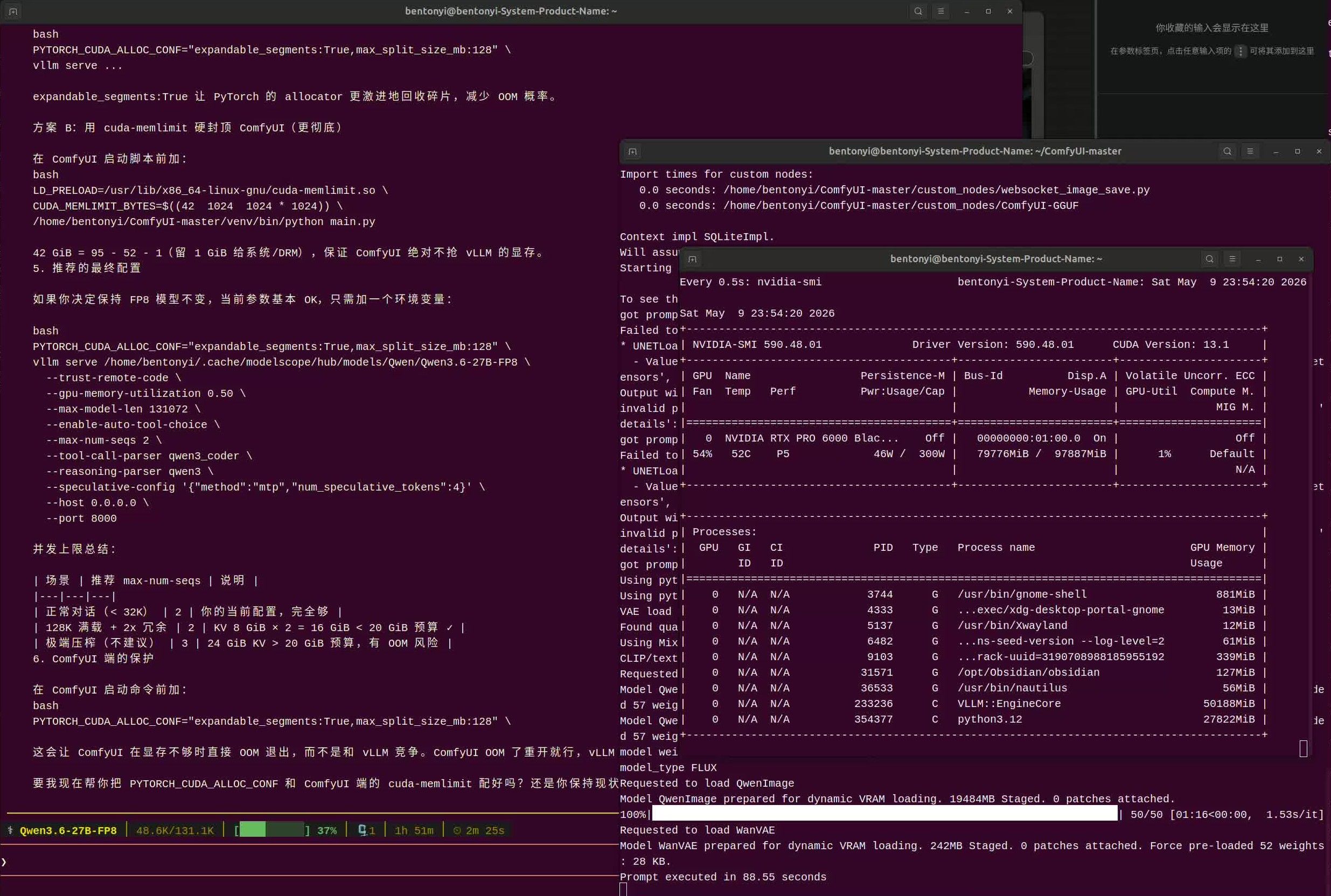
最后这张图是我的实际测试,显存占用和ds说得几乎一模一样。 -
Pro6000和Tuf4090矿工测试。和老婆出来短途自驾放松一下,家里的设备不想闲着,挖了挖最近比较火的Pearl(PRL)珍珠币顺便测试一下设备。Pro6000 Max-Q单卡21小时数据如图
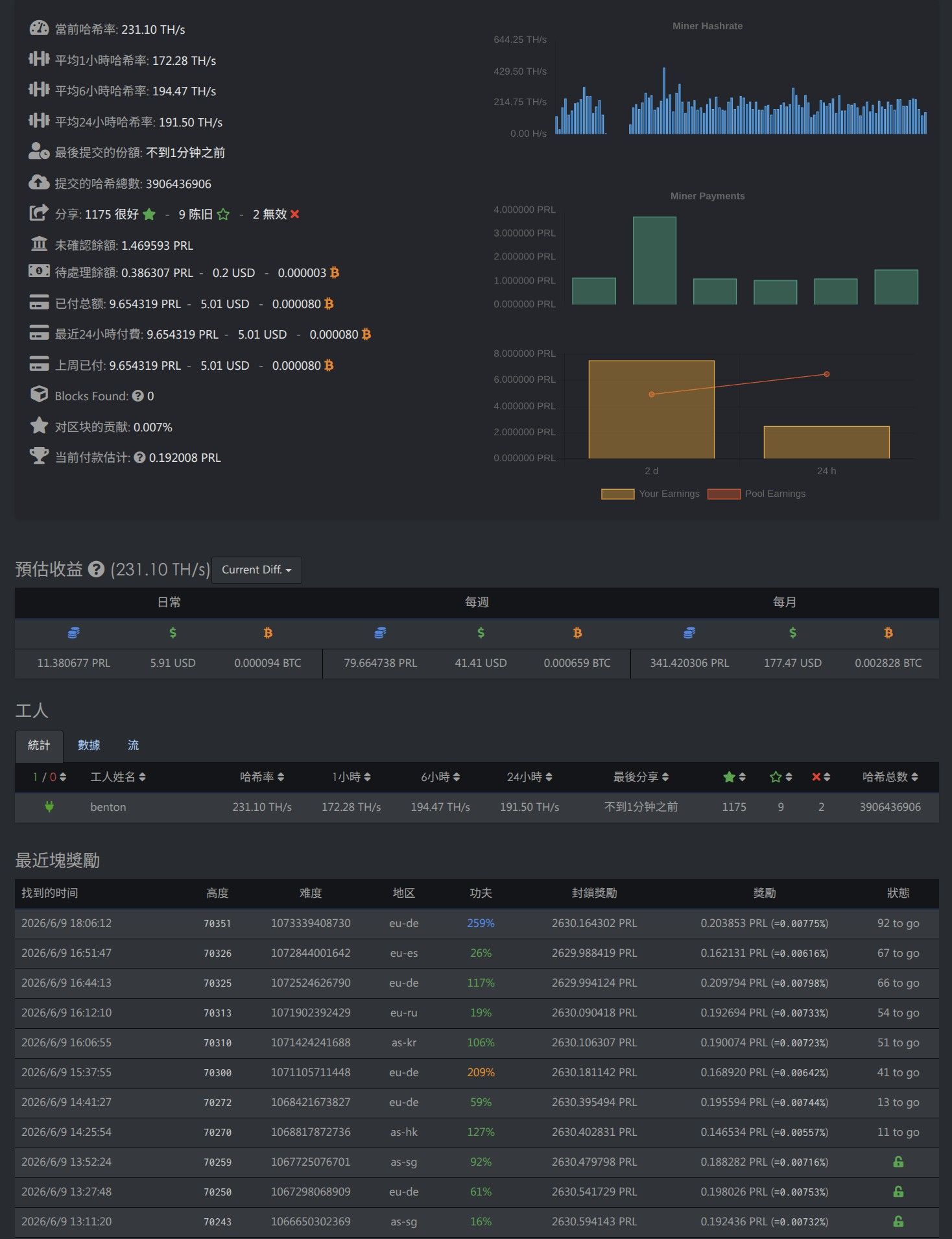
从图1的服务器端可以看到平均6小时哈希算力194.47TH/s。
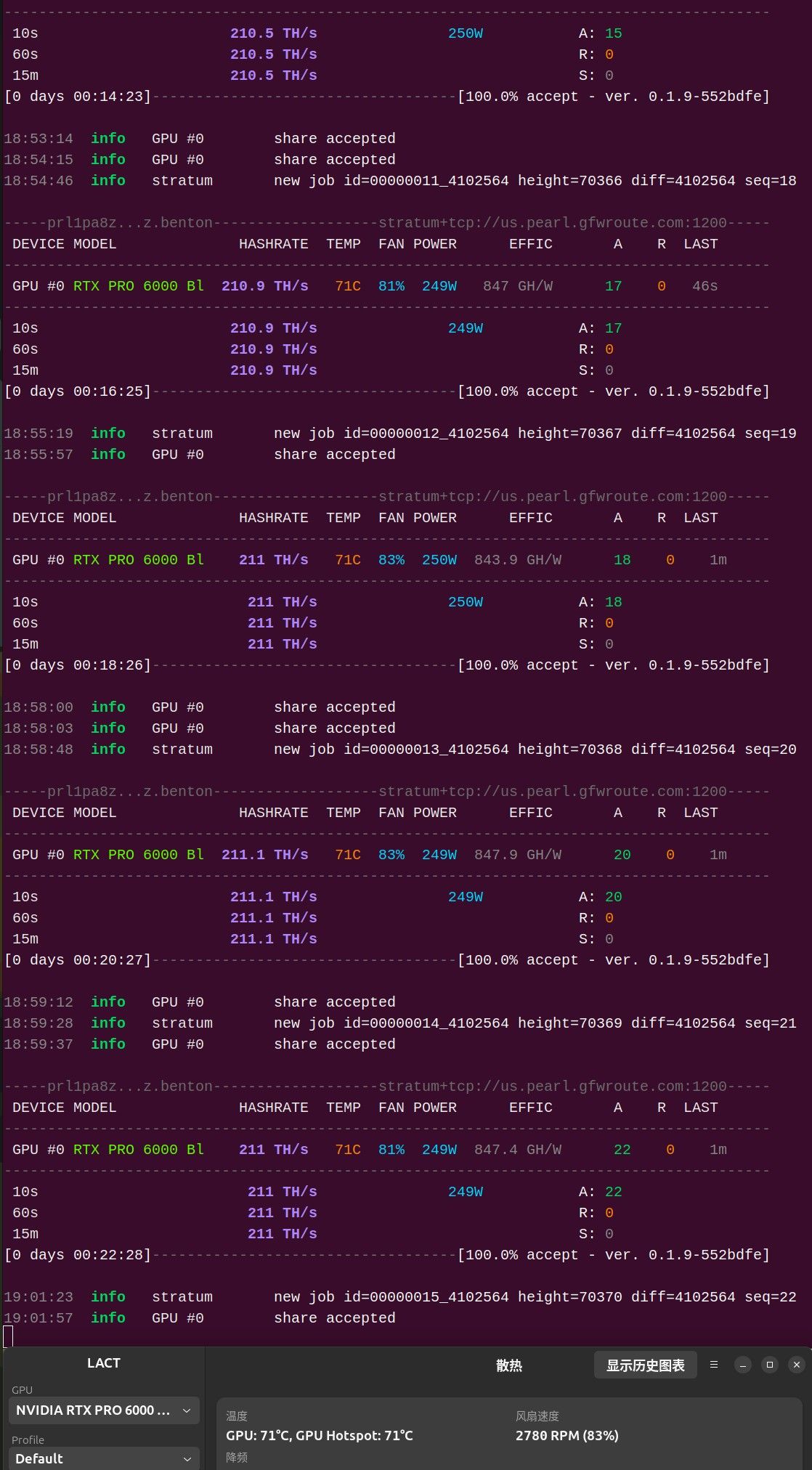
为了保护寿命,功耗帽调到了最低,250w。GPU温度和GPU Hotspot都能长期保持71摄氏度。另外有275w和300w的10分钟测试,数据记录如下:
设置275w时,GPU:76摄氏度,GPU Hotspot:76摄氏度,风扇86%,214~227TH/s;
设置300w(100%)时,GPU:80摄氏度,GPU Hotspot:79摄氏度,风扇94%,231~249TH/s;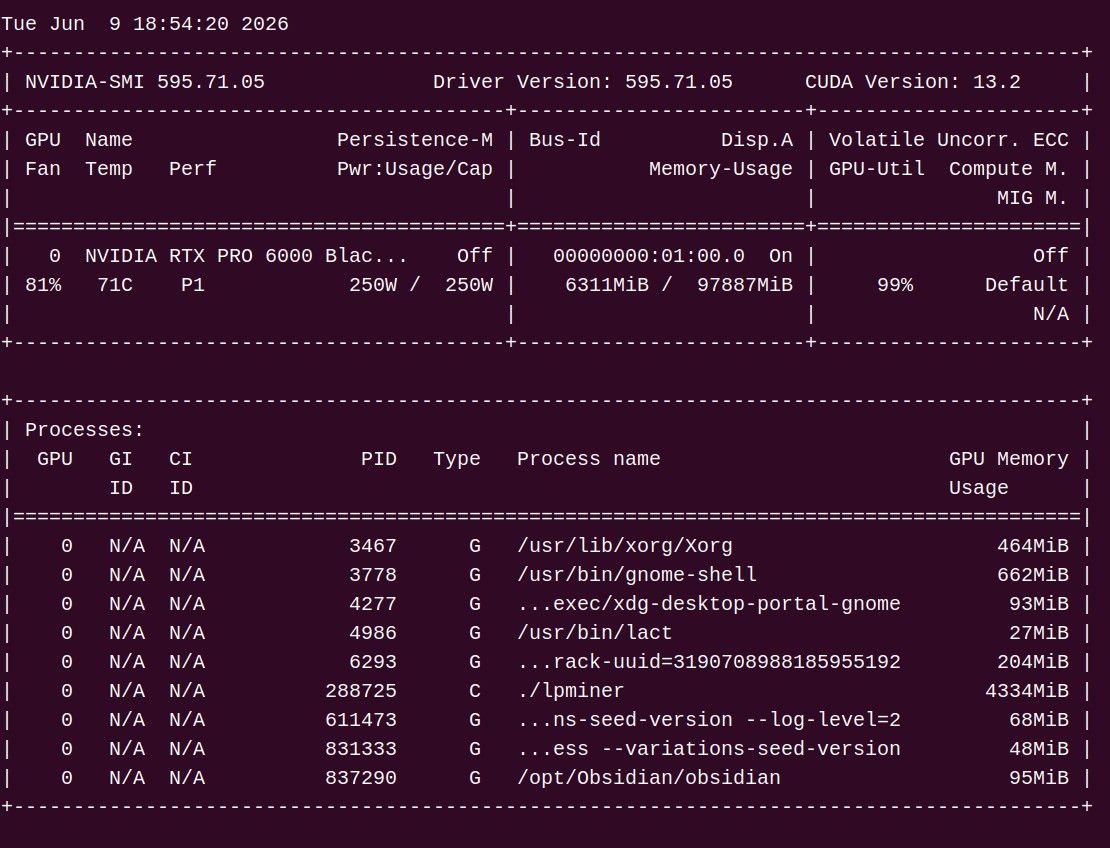
但是另一张4090的数据其实在挖矿上"出乎意料地"相比Pro6000并没有落多少下风,除了在产出能耗比上落后Pro6000一大截以外,不论是温控还是算力都非常能打,确实属于力大飞砖的典范了。以下是ASUS Gaming TUF 4090 o24G卡在设定不同功耗帽下的记录:
设置300w时,GPU:64摄氏度,GPU Hotspot:75摄氏度,VRAM:61摄氏度,风扇82%,平均哈希算力199~202TH/s,EFFIC在667GH/W左右;
设置350w时,GPU:66摄氏度,GPU Hotspot:78摄氏度,VRAM:63摄氏度,风扇85%,222~224TH/s,EFFIC:629~631GH/W;
设置380w时,GPU:68摄氏度,GPU Hotspot:81摄氏度,VRAM:64摄氏度,风扇88%,224~231TH/s,EFFIC:510~521GH/W;
设置450w(100%)时,GPU:74摄氏度,GPU Hotspot:89摄氏度,VRAM:68摄氏度,风扇95%,240~245TH/s,EFFIC:440~444GH/W;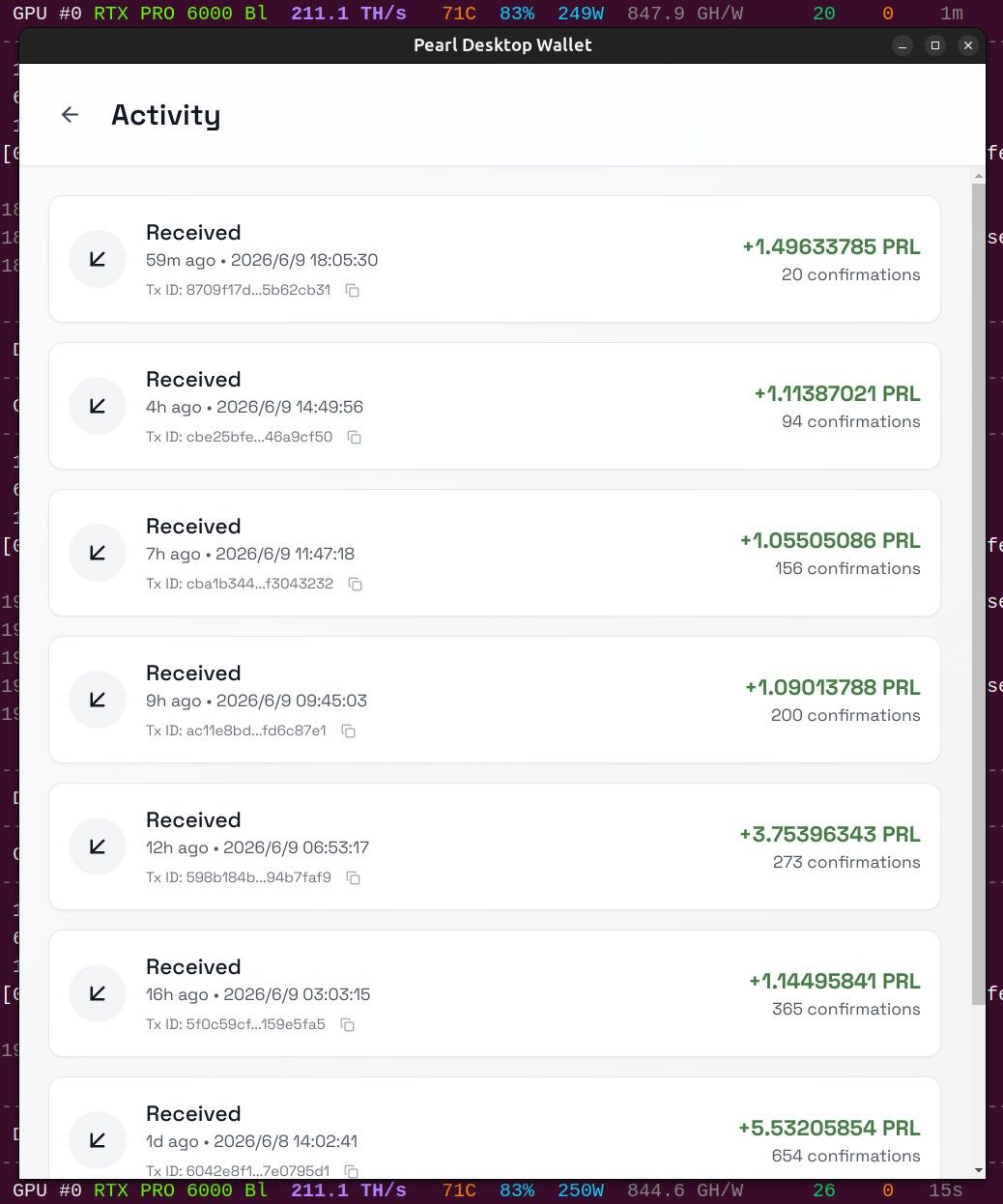
以上是收益情况,总得来说包住电费之外能挣个菜钱。闲来无事心血来潮,数据给大家做个参考。