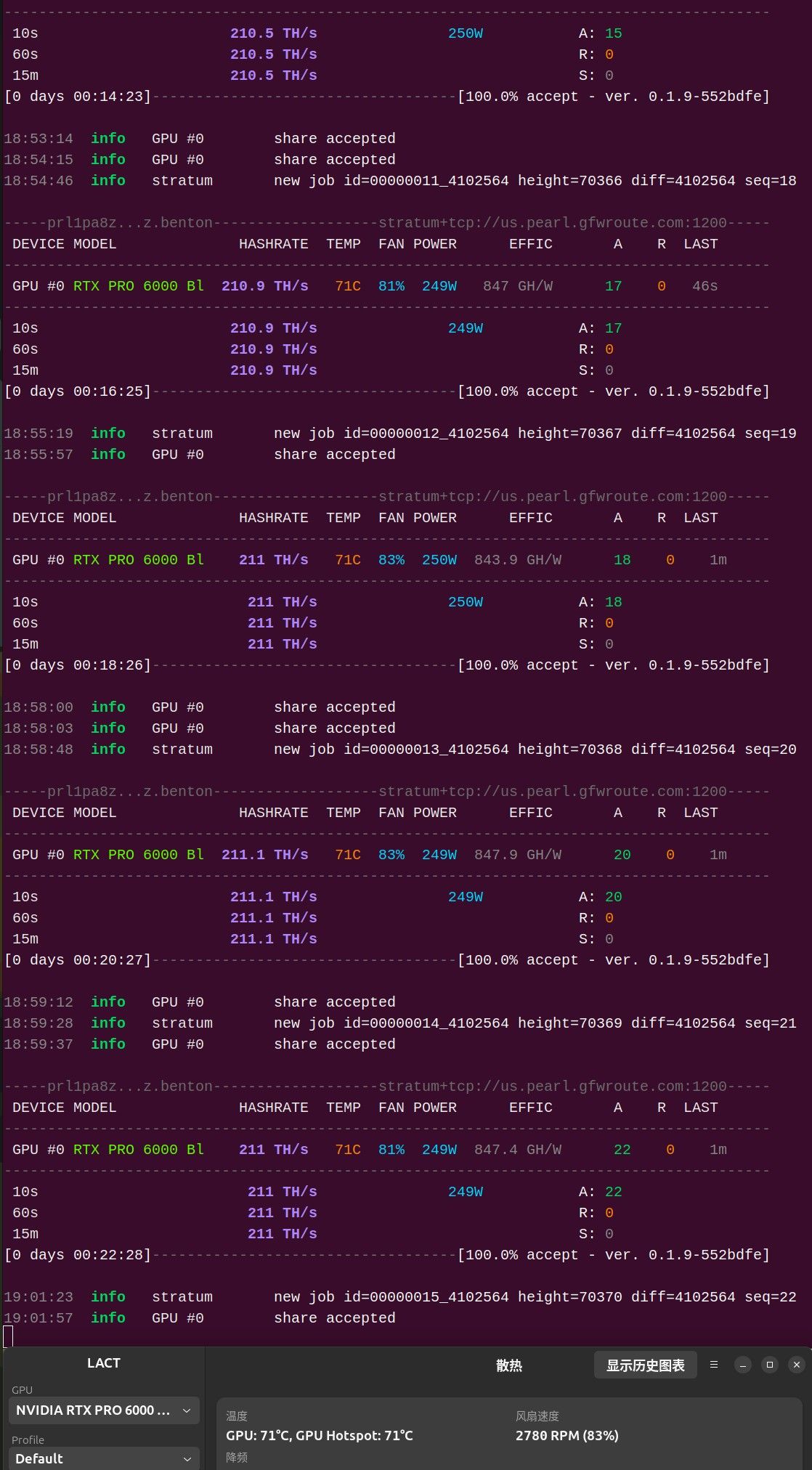
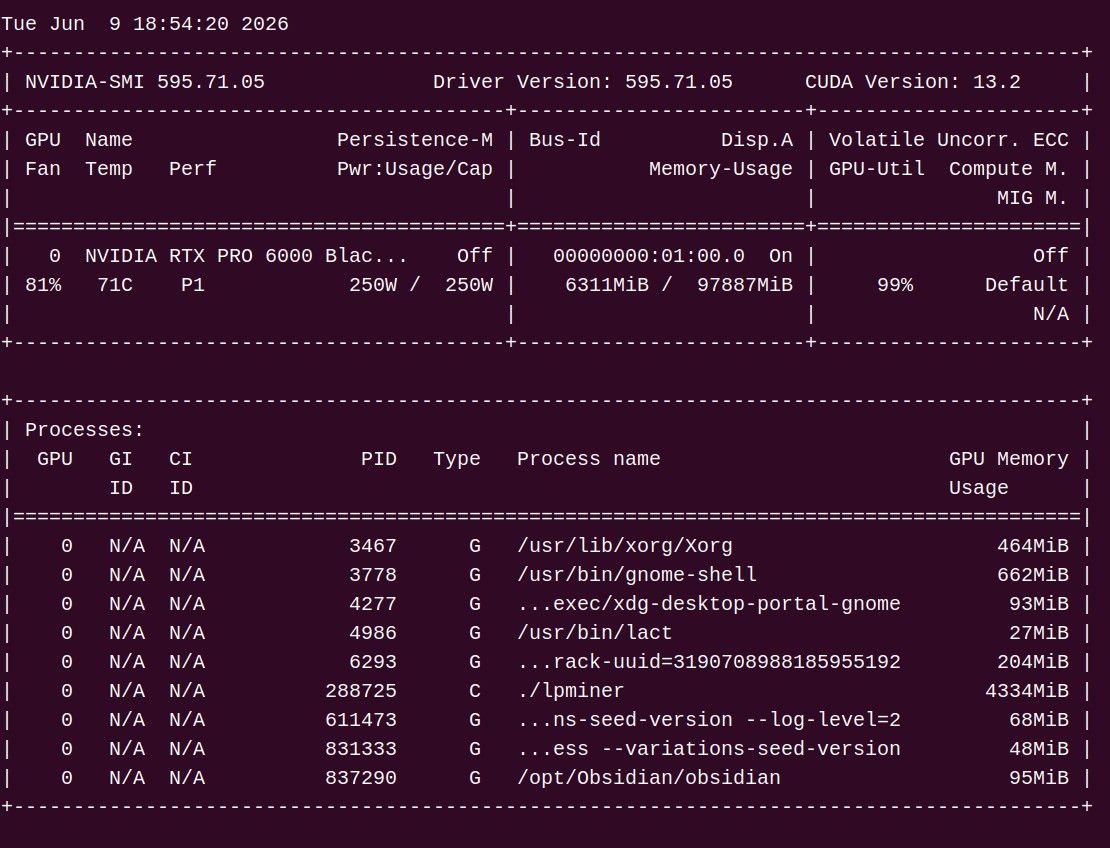
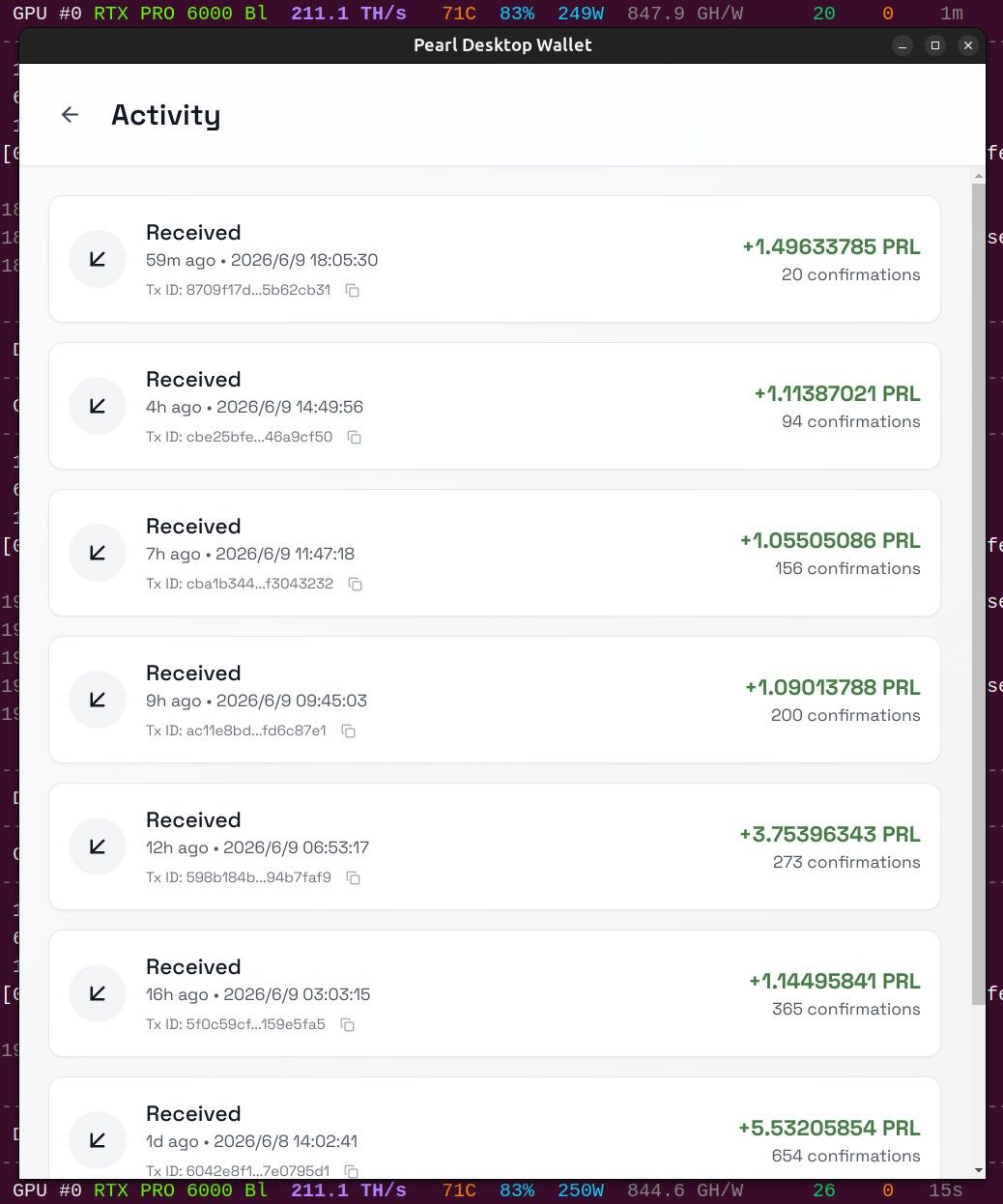
崩掉倒是不至于,但泡沫无疑是非常大的。
你理解现在的美国是个从前非常厉害的老登,年轻的时候身体强壮(制造业重工业),手里还有美式居合(美金+美军),于是一路打天下,攒下了巨大的家产和江湖地位。但这个老登现在,身体发福(制造业空心化且回归难度空前),以前贼6的美式居合也逐渐玩不灵了(传统工业优势迅速下降,和蓝星军力20强的伊朗打得有来有回),偏偏旁边还来了一个体格越来越壮的年轻人(东大克苏鲁)。他能怎么办?他也得掂量,和美军神话迅速被川普玩坏相比,美元霸权的衰落就没那么快,其实这个老登选择并不多,他现在选择押注ai,并不只是因为“AI很赚钱”这么简单。他更像是在包装一个超级宏大的金融故事:
“下一轮工业革命仍然发生在美国,美国仍然拥有最先进的科技,美国仍然是资本和人才的最终归宿。”
这个故事如果讲成功,那美元资产的吸引力、美国科技公司的估值、全球资本流向,都可以勉强保持下去。于是他至少还能维持住美元的霸权。所以你才会看到一些ai公司(尤其美国ai七子)的商业模式短期甚至不像传统企业——烧钱亏损市值还能疯涨。资本买的不是今天的利润,而是透支未来几十年的想象空间。
那么问题来了。东大一拍大腿,故事不错,但是他怕什么给丫安排什么:从政府给梁文锋站台到梁对投资人的4小时内部讲话,说deepseek只“赚取合适的利润”,到现在kimi K3的比肩顶级闭源ai的实力(八九成fable5的功力只收十几分之一的价格并且K3将在几天后开源),都无疑给了美国ai金碧辉煌的商业故事沉重一击,而且东大说我保证这样的事情以后冷不丁什么时候就出现一个……
这阳谋一出,你让资本怎么办,资本天生最怕不确定性,这样一折腾资本不得不理性下来。说穿了东大的阳谋是逼迫AI行业开始经历一次从“淘金热”迅速转变到“淘金公司开始算账”的过程。19世纪淘金热的时候,真正发财的不一定是挖金矿的人,而是卖铲人。而当淘金公司开始算账了,铲子也就不会无限涨价。
ai是未来大概率是真的,现在中美的这些ai公司都在卖一张通往未来的门票,但哪张门票能值回票价,真的只能交给时间。