
@fcme 谢谢回复,我现在也是如此。hermes里配了deepseek和gemini,复杂问题都先切到deepseek,一般几个来回都能发现和解决问题。Qwen 27B主要执行一些routine tasks。
但就是个执念:)
@fcme 谢谢回复,我现在也是如此。hermes里配了deepseek和gemini,复杂问题都先切到deepseek,一般几个来回都能发现和解决问题。Qwen 27B主要执行一些routine tasks。
但就是个执念:)
我是llama.cpp + Qwen3.6-27B + hermes 重度使用者,每天至少1个小时以上。基本上智能家居+网络配置+日常电脑任务+记账 都转到AI上了。三者配合最大的问题还是prompt重算的问题,初略统计,基本上context累计到40-50K以上(尤其是频繁工具调用),就会开始出现prompt重算,之后越聊会越频繁。到最后基本就不可用了。为了缓解这个问题,频繁调试llama.cpp启动参数,都无法彻底解决。
好在一直都有人在致力于优化,我相信终会得到解决。以下是近期一些prompt重算问题的进展:
https://huggingface.co/froggeric/Qwen-Fixed-Chat-Templates 更新到了v21版本,我更新它之后,解决了hermes新版读取memory报错的一个bug(hermes自己分析是prompt/template 格式问题)。但对prompt重算改善不大。
https://github.com/ggml-org/llama.cpp/issues/22746#issuecomment-4843582985 这个issue持续有人在跟进,并提供了patch。开源的意义就在于此。
@terry 我直接把2pin线拔了,世界安静了:)
试验了下,在室温22度/ATX全塔机箱情况下,跑Qwen3.6-35B-A3B 半个小时,CPU参与大模型运算,占用率50%左右。我的E5 2666v3 温度55度左右,MOS散热片只是微烫。所以如果CPU不鸡血,AI非重度使用情况下,我觉得这个风扇索性直接停掉。
但为了以防万一,我最后决定在Mos散热器上方加挂一个120mm抽风风扇,促进空气流动。
@williamlouis 谢谢 ,开拓思路了。
,开拓思路了。
跟随坛友脚本,618购入了华南金牌X99-CD3主板。质量确实还可以。几个不足之处及应对:
还有一个问题暂时无解,即MOS小风扇转速太快导致噪音很大,且是2pin接口没法在BIOS里调整。自行搜索+AI,推荐的方法是使用降压线,或者干脆拔掉。论坛里其他使用该系列主板的坛友有相关经验吗?
这个问题也困扰我很久,目前用chat template 补丁,还是有不少改善:
https://lcz.me/post/5404
@CHIA-AN-YANG 与你情况相同 暂时无解,睡一觉明天再说。
暂时无解,睡一觉明天再说。
@kevon 我之前显卡是5060Ti 16G,也是Qwen3.6-27B-Q4太慢,最终转向Qwen36-35B-A3B-Q4,还不错,速度能到60+t/s,接Hermes完全可用。智力是差一些,执行长链条的任务会掉链子(比如调用无头浏览器执行一系列操作),但一般性的任务还行。 奈何被这论坛洗脑,按捺不住还是换了7900XTX,27B-Q4是爽了。但是又想Q6和Q8了,本地AI就是坑啊。
我是昨天git clone的最新版本,编译的时候不能用
DCMAKE_HIP_ARCHITECTURES=gfx1100
换成
DDFLASH27B_HIP_ARCHITECTURES=gfx1100 编译就ok了。
但是我bench速度只有不到50t/s,还不如llama.cpp+Vulkan。还在研究怎么进一步优化。
Colt 说:
cmake -B server/build -S server -DCMAKE_BUILD_TYPE=Release -DDFLASH27B_GPU_BACKEND=hip -DCMAKE_HIP_ARCHITECTURES=gfx1100 -DROCM_PATH=/opt/rocm-7.2.3 -DDFLASH27B_HIP_SM80_EQUIV=ON -DCMAKE_C_STANDARD=11 -DCMAKE_CXX_STANDARD=17 -DGGML_CCACHE=OFF
还是靠Hermes,它5秒就定位问题,然后搞定了。编译的时候不能用 -DCMAKE_HIP_ARCHITECTURES=gfx1100。
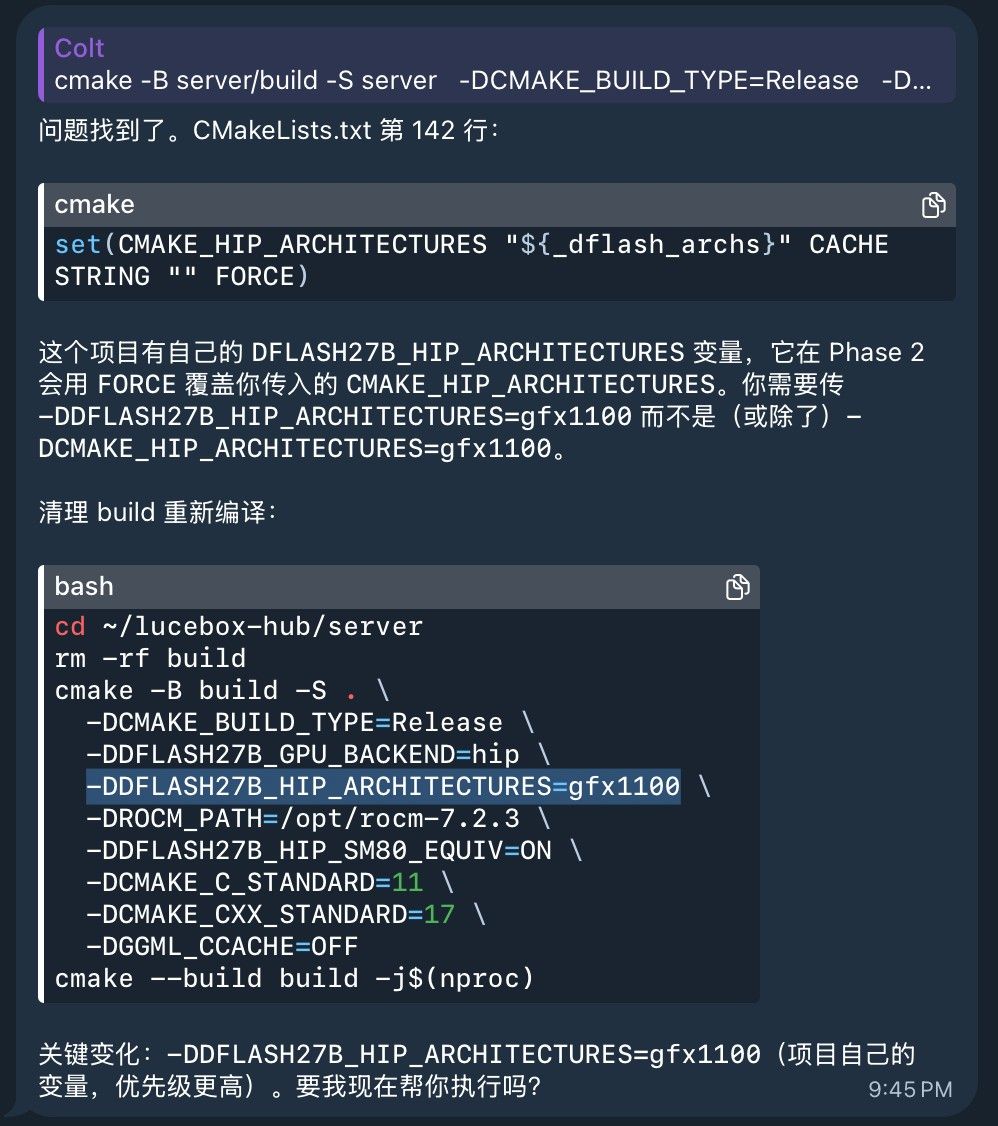
同为7900XTX,想抄作业,ubuntu26.04,之前已安装了ROCm 7.2.3,并编译llama.cpp 正常运行。这次在编译和运行test_dflash 遭遇不少挫折,最终通过如下命令编译成功:
cmake -B server/build -S server -DCMAKE_BUILD_TYPE=Release -DDFLASH27B_GPU_BACKEND=hip -DCMAKE_HIP_ARCHITECTURES=gfx1100 -DROCM_PATH=/opt/rocm-7.2.3 -DDFLASH27B_HIP_SM80_EQUIV=ON -DCMAKE_C_STANDARD=11 -DCMAKE_CXX_STANDARD=17 -DGGML_CCACHE=OFF
cmake --build server/build --target test_dflash -j$(nproc)
但是跑bench全部失败,单独运行test_dflash,错误信息如下:
LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH HSA_OVERRIDE_GFX_VERSION=11.0.0 DFLASH27B_DRAFT_SWA=2048 DFLASH27B_PREFILL_UBATCH=32 /home/user/lucebox-hub/server/build/test_dflash /data/models/Qwen/Qwen3.6-27B-Q4_K_M.gguf /data/models/Lucebox/dflash-draft-3.6-q8_0.gguf /tmp/dflash_bench/he_prompt_Qwen_Qwen3.5-27B_00.bin 128 /tmp/out_test.bin --fa-window 0 --ddtree --ddtree-budget=8
[cfg] seq_verify=0 fast_rollback=1 ddtree=1 budget=8 temp=1.00 chain_seed=1 fa_window=2048 draft_swa=2048 draft_ctx_max=4096 draft_feature_mirror=0 peer_access=0 target_gpu=0 draft_gpu=0
ggml_cuda_init: found 1 ROCm devices (Total VRAM: 24560 MiB):
Device 0: Radeon RX 7900 XTX, gfx1100 (0x1100), VMM: no, Wave Size: 32, VRAM: 24560 MiB
[loader] eos_id=248046 eos_chat_id=-1
[target] target loaded: layers [0,64) output=1, 850 tensors on GPU 14.99 GiB, tok_embd 682 MiB CPU-only (q4_K)
[draft] loaded
[draft] SWA layers: 4/5 (window=2048)
[prompt] 125 tokens
[prefill] token-seg ubatch=32
Segmentation fault (core dumped) LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH HSA_OVERRIDE_GFX_VERSION=11.0.0 DFLASH27B_DRAFT_SWA=2048 DFLASH27B_PREFILL_UBATCH=32 /home/colt/lucebox-hub/server/build/test_dflash /data/models/Qwen/Qwen3.6-27B-Q4_K_M.gguf /data/models/Lucebox/dflash-draft-3.6-q8_0.gguf he_prompt_Qwen_Qwen3.5-27B_00.bin 128 /tmp/out_test.bin --fa-window 0 --ddtree --ddtree-budget=8
dmesg 错误日志
traps: test_dflash[35252] general protection fault ip:755a83ab097f sp:7ffd64484780 error:0 in libamdhip64.so.7.2.70203[2b097f,755a83823000+481000]
问遍AI,不得其解。目前尚无头绪,不确定是否为ROCm的版本导致。我看楼主也是7.2版本,请教楼主是否曾经遇到类似问题。不到万不得已,实在不想折腾退回ROCm 6.3。
@Chan-Ivan 请问楼主,散热有没有问题啊?看图两张7900XTX之间还有多少空间?
更新下,又发现了一个基于 froggeric 的模板再优化的版本:https://huggingface.co/spiritbuun/buun-Qwen3.6-chat_template 。自己用了两天,如果是一般性的聊天,几乎不再会缓存重建。但调用browser等工具引发大量token引入的情况下,还是会发生。不过已经改善良多了,感谢作者。
下载地址: https://huggingface.co/spiritbuun/buun-Qwen3.6-chat_template/tree/main
另外,我让Hermes监控llama.cpp的输出日志,自己跑两组测试,看看还可以调整哪些参数进一步优化缓存重建的问题。 它调试分析后建议就我的硬件情况,可增加如下参数 --ctx-checkpoints 32 --checkpoint-min-step 256 --cache-ram 12288。大家也可以自己试试。
~/llama.cpp/build/bin/llama-server -m models/Qwen/MTP/Qwen3.6-27B-Q4_K_M.gguf \
--spec-type draft-mtp --spec-draft-n-max 3 \
--flash-attn --n-gpu-layers 99 on --threads 6 --parallel 1 \
-ctk q8_0 -ctv q4_0 --ctx-size 96000 \
-b 3072 -ub 1024 --no-warmup --no-mmap \
--host 0.0.0.0 --port 8080 \
--reasoning off --jinja --chat-template-file models/Qwen/chat_template.jinja
MTP加持下,本地跑 Qwen3.6-27B-Q4_K_M 速度50+tokens/s,搭配hermes很够用。但是每聊那么几句,控制台总是输出上下文缓存不命中的信息,类似:
17.27.663.317 W slot update_slots: id 0 | task 2894 | forcing full prompt re-processing due to lack of cache data (likely due to SWA or hybrid/recurrent memory, see https://github.com/ggm-org/llama.cpp/pull/13194#issuecomment-2868343055)
17.27.663.319 W slot update_slots: id 0 | task 2894 | erased invalidated context checkpoint (pos_min = 51198, pos_max = 51198, n_tokens = 51199, n_swa = 0, pos_next = 0, size = 231.851 MiB)
......
然后就是缓慢的 prompt processing 和 created context checkpoint 过程。持续几十秒到几分钟不等,显卡风扇呼呼转。 聊得越久,context越大,出现得越频繁。这种情况非常影响思路连贯性,乃至情绪。研究了几个晚上,问遍国内外AI模型,尝试了各种参数组合,都不得其果。
昨天意外刷到了 Qwen-Fixed-Chat-Templates 的介绍,一番试用后,发现效果明显,聊了近一个小时,反复网络搜索+工具调用,缓存不命中的情况只出现个位数次数。感觉流畅很多,不敢独享,记录下来,希望对遇到类似问题的朋友有用。
特别感谢 https://huggingface.co/froggeric/Qwen-Fixed-Chat-Templates 作者。下载方式:
hf download froggeric/Qwen-Fixed-Chat-Templates chat_template.jinja --local-dir models/Qwen
至于它的原理,Huggingface 页面上有详细介绍。我偷懒让Gemini去总结,回复如下:
