我的装备看这个帖子:
https://lcz.me/topic/117/小小秀一下我的ai-rig/12
这个帖子主要是分享一下用这套装备能怎么跑大模型(LLM),有哪些组合,能大概跑出来什么样的效果等等。
GPU
- RTX 4090 48G (独立显卡)
- AMD Radeon AI PRO R9700 32G (独立显卡)
- AMD Radeon 8060S Graphics 128G(AI MAX 395的集成显卡)
各自的特点:
- AI Max 395:价格14000RMB左右,集成显卡代号8060S,共享内存128G,内存最大,能通吃许多大模型, 但算力最低,内存带宽260G左右,也是最低,所以跑大模型的速度最慢;
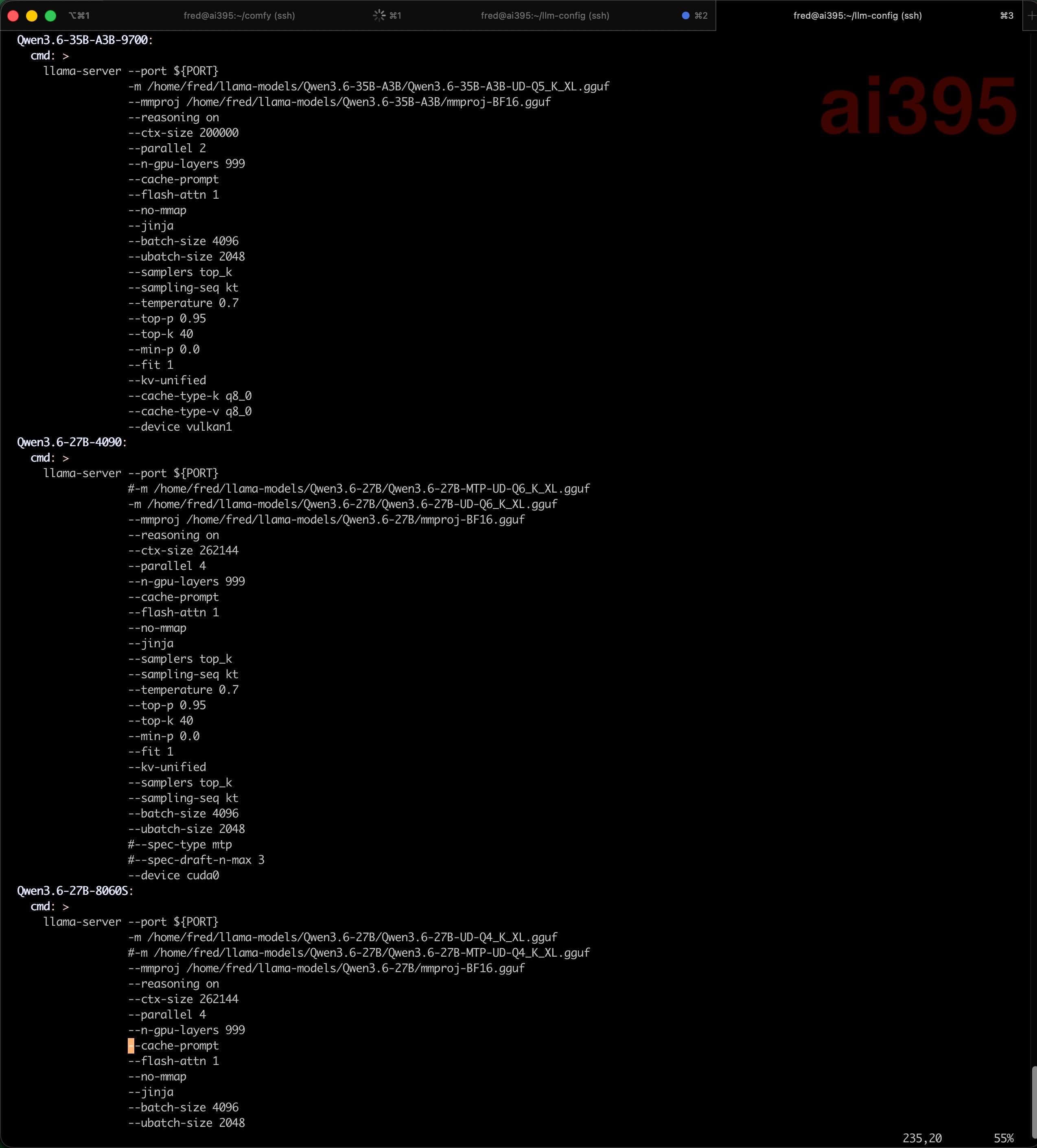
- 4090 48G:价格30000RMB左右,最贵,最快,显存带宽1TB左右,生态最好,vLLM可以跑得飞起,但48G显存吃不下超大模型,但跑27B模型或者30B模型,可以把上下文放256K,非常爽;
- R9700 32G:价格11000RMB左右,32G显存,速度尚可,性价比高,但算力和显存带宽(660G左右),都不如4090,因此速度介于8060S集成显卡和4090之间,能跑27B模型,选择Q4量化模型,上下文也能到256K。
玩法
分3类:
- 小模型单卡玩法,这就不说了,就是用一个卡跑一个模型;
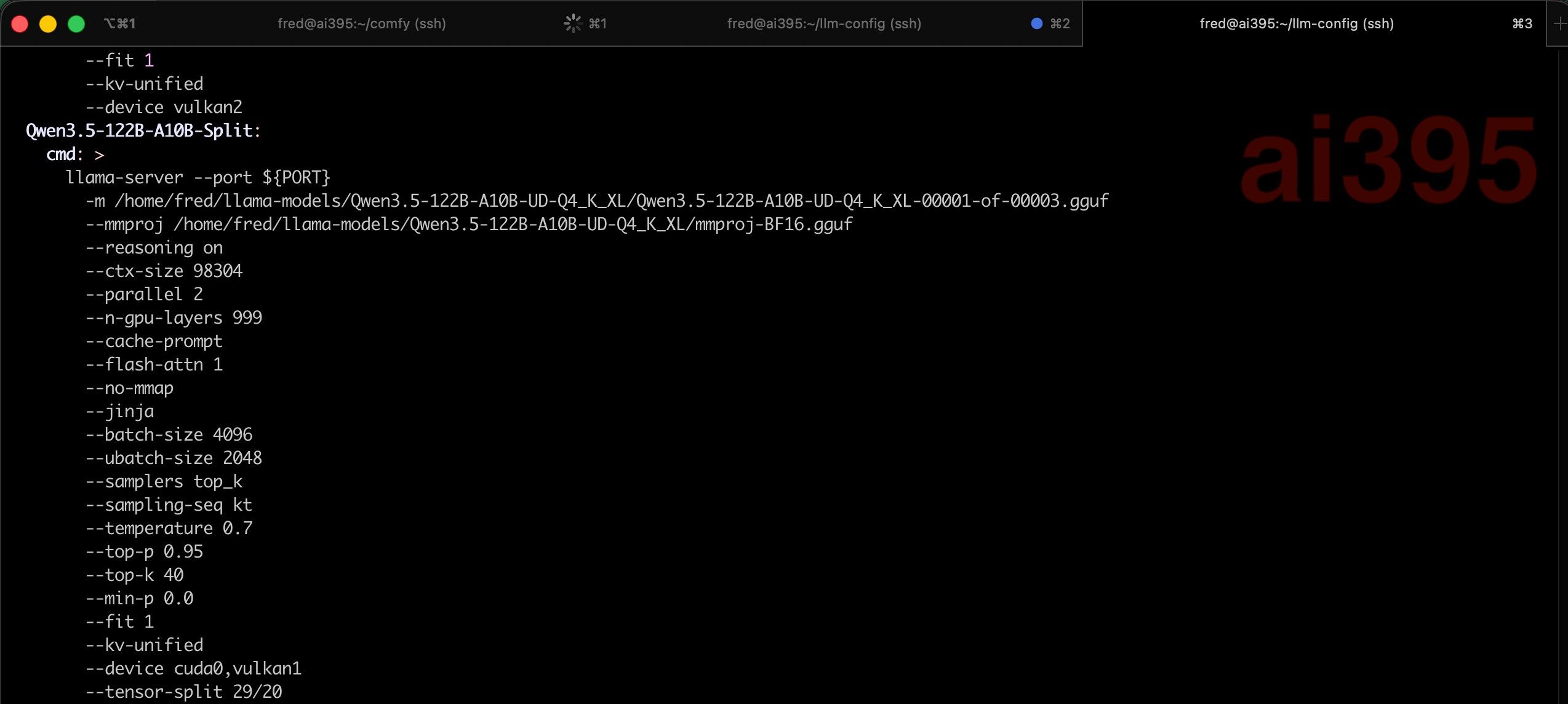
- 中等模型分2卡玩法,例如Qwen3.5-122B模型,本来可以直接跑在AI MAX 395的集成显卡上,但我嫌他性能太差,然而4090和R9700两个卡,任何一个的显存又不够单跑这个模型,但2个卡加起来80G的VRAM就够了,因此可以将它用llama.cpp的
-ts参数,分层到2块卡上跑,效果惊人地快; - 超大模型分卡分3卡玩法,例如MiniMax M2.7这种,下载下来哪怕是Q4的量化版本,都有120多GB,连AI MAX 395的128GB都放不下(需要留内存给系统和kv cache),这种情况,可以把同一个模型分成3部分,让4090承担大头,AI MAX395承担中头,R9700承担小头。这样的性能会被AI MAX 395的集成显卡拖后腿,但是能跑,而且如果不用长上下文的Agent,仅用来聊天(利用超大知识库),性能也可以接受(吐字不慢)。
后面我就把这几种方法跑出来的效果给大家汇报一下。
测试工具
llama-benchy: 我用这个工具,它是通过openai的兼容api端点做压测,可以对任何推理引擎做压测(我是vLLM和llama.cpp),它能反映最终用户(例如Hermes Agent)能真正感受到的速度。
GitHub - eugr/llama-benchy: llama-benchy - llama-bench style benchmarking tool for all backends
压测结果
| 模型 | 参数量 | 量化方式 | 权重大小 | 推理框架 | GPU | PROMPT PREFILL (pp8192) | TOKEN GENERATION (tg512) |
|---|---|---|---|---|---|---|---|
| MiniMax2.7 | 230B-A10B | UD-IQ4_XS | 102GB | llama.cpp (-ts) | 4090+R9700+8060S | 781.68 | 27.74 |
| Qwen3.5-122B-A10B | 122B-A10B | UD-Q4_K_XL | 73GB | llama.cpp | 8060S | 352.36 | 20.96 |
| Qwen3.5-122B-A10B | 122B-A10B | UD-Q4_K_XL | 73GB | llama.cpp (-ts) | 4090+R9700 | 2234.51 | 53.63 |
| Qwen3.6-35B-A3B | 35B-A3B | Q5_K_XL | 25G | llama.cpp | 4090 | 7978.24 | 162.10 |
| Qwen3.6-35B-A3B | 35B-A3B | Q5_K_XL | 25G | llama.cpp | R9700 | 2880.76 | 79.05 |
| Qwen3.6-35B-A3B | 35B-A3B | Q5_K_XL | 25G | llama.cpp | 8060S | 946.44 | 50.77 |
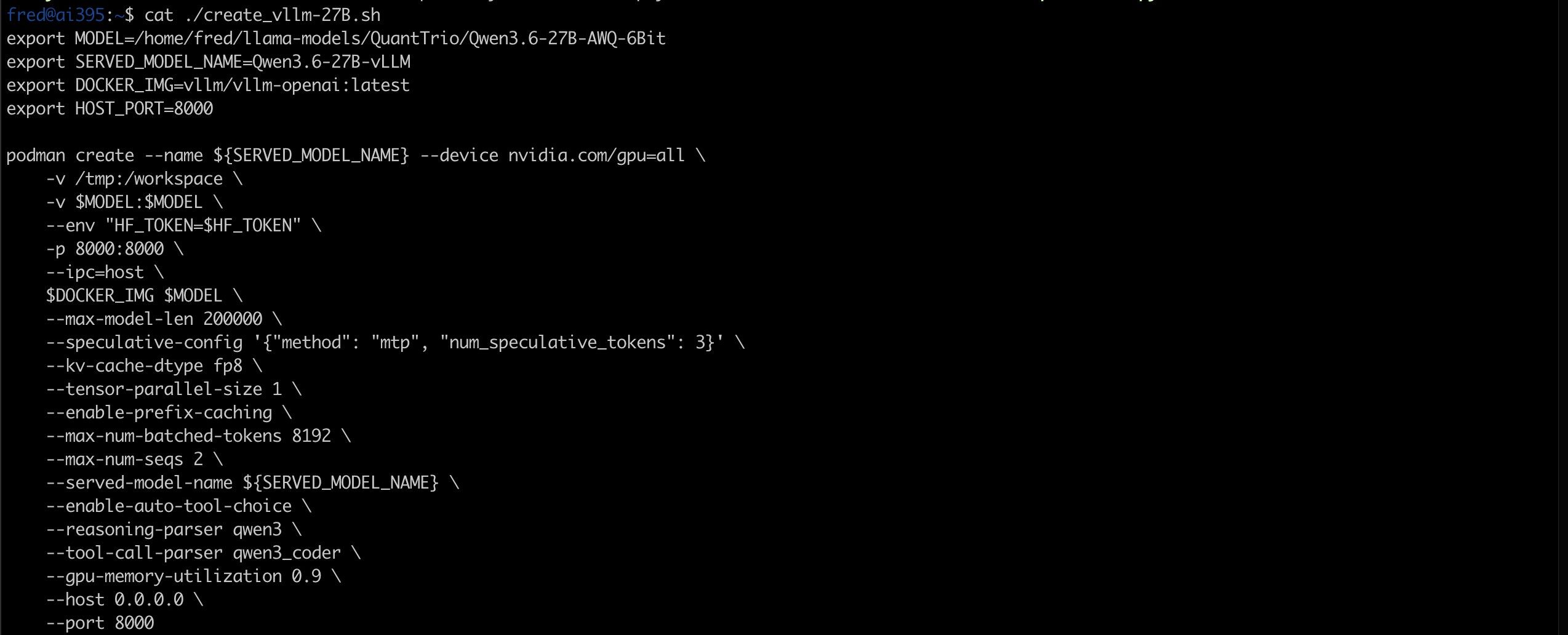
| Qwen3.6-27B | 27B | AWQ-6Bit | 26GB | vLLM | 4090 | 2557.59 | 115.47 (with MTP) |
| Qwen3.6-27B | 27B | UD-Q6_K_XL | 25GB | llama.cpp | 4090 | 2402.65 | 33.88 |
| Qwen3.6-27B | 27B | UD-Q4_K_XL | 17GB | llama.cpp | R9700 | 914.31 | 26.56 |
| Qwen3.6-27B | 27B | UD-Q4_K_XL | 17GB | llama.cpp | 8060S | 281.44 | 11.83 |
结论
这个结果其实就和特哥常常讲的一样,有多少钱卖多少钱的设备:买贵的吃不了亏,买便宜的占不了太多便宜。
以Qwen3.6-27B为例:
- 跑在AI MAX 395的8086S上,PP才281个,吐字才11个,这个机器14000RMB,你买到了128G的大显存,还得到了一台不错的windows/linux主机,但是速度没法和独立显卡相比;
- 跑在R9700上,PP一下子914个,吐字有26个每秒,这才是可用的速度,但代价是11000RMB;
- 跑在4090上,这生态上的优势马上就出来了,用vLLM打开成熟的MTP支持,多请求PP一下子2557个,吐字115个(不要去折腾A卡的vLLM了,我尝试过,Qwen3.6支持度不行,上下文有限, 单请求速度不如llama.cpp),即使跑在llama.cpp上,PP速度也能到2402,只是吐字速度稍慢,才33个(受限与1TB显存带宽以及没有成熟的MTP)。这个卡30000RMB左右,比R9700贵了2倍左右,但你得到的效果也是2倍。
所以最后还是看自己,显卡这个市场现在基本上是一分钱一分货(除非被骗),不要纠结。自己想干啥,就买啥。
 各位老大是否了解, 在国内能买到这个这吗?
各位老大是否了解, 在国内能买到这个这吗?