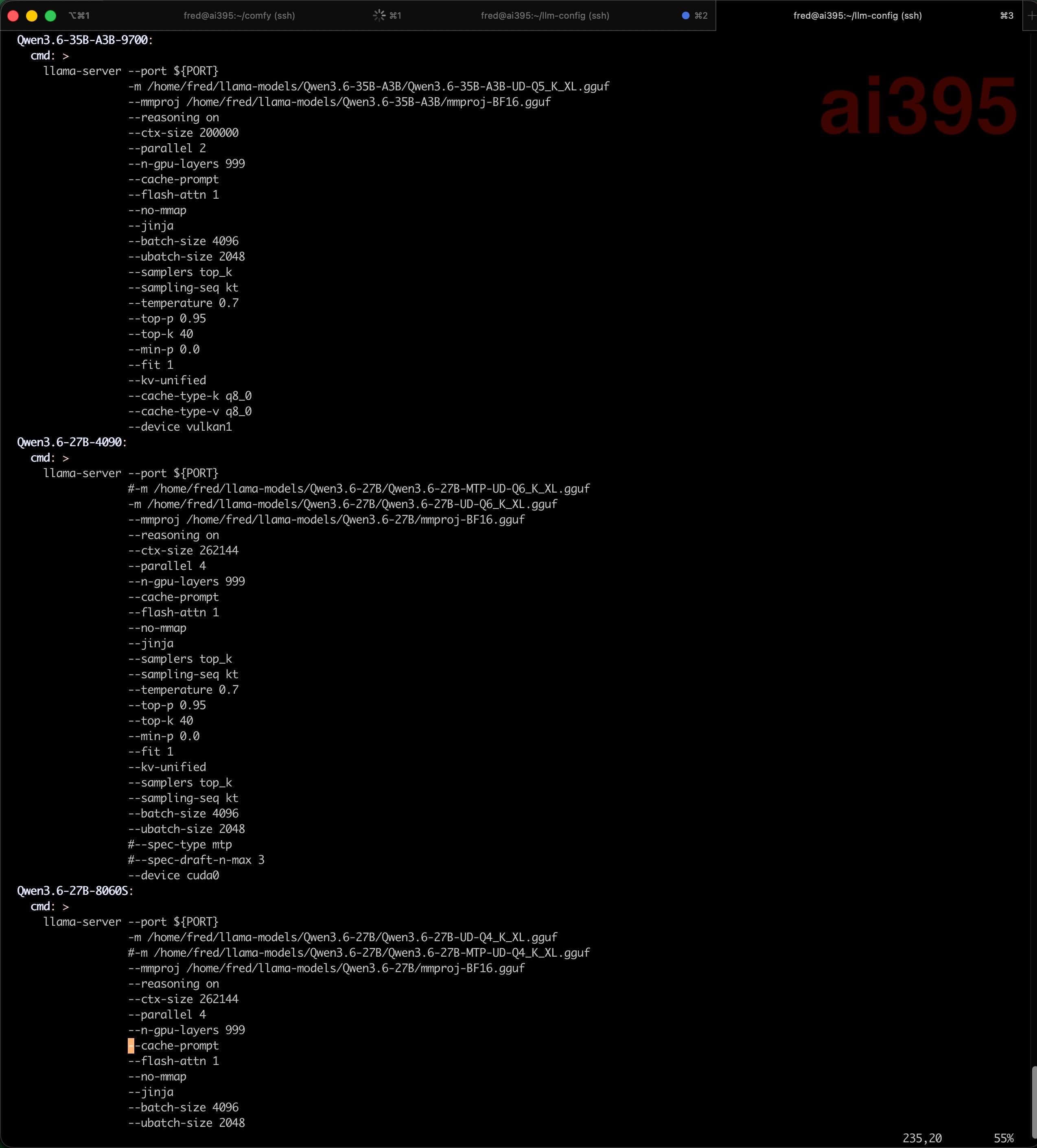
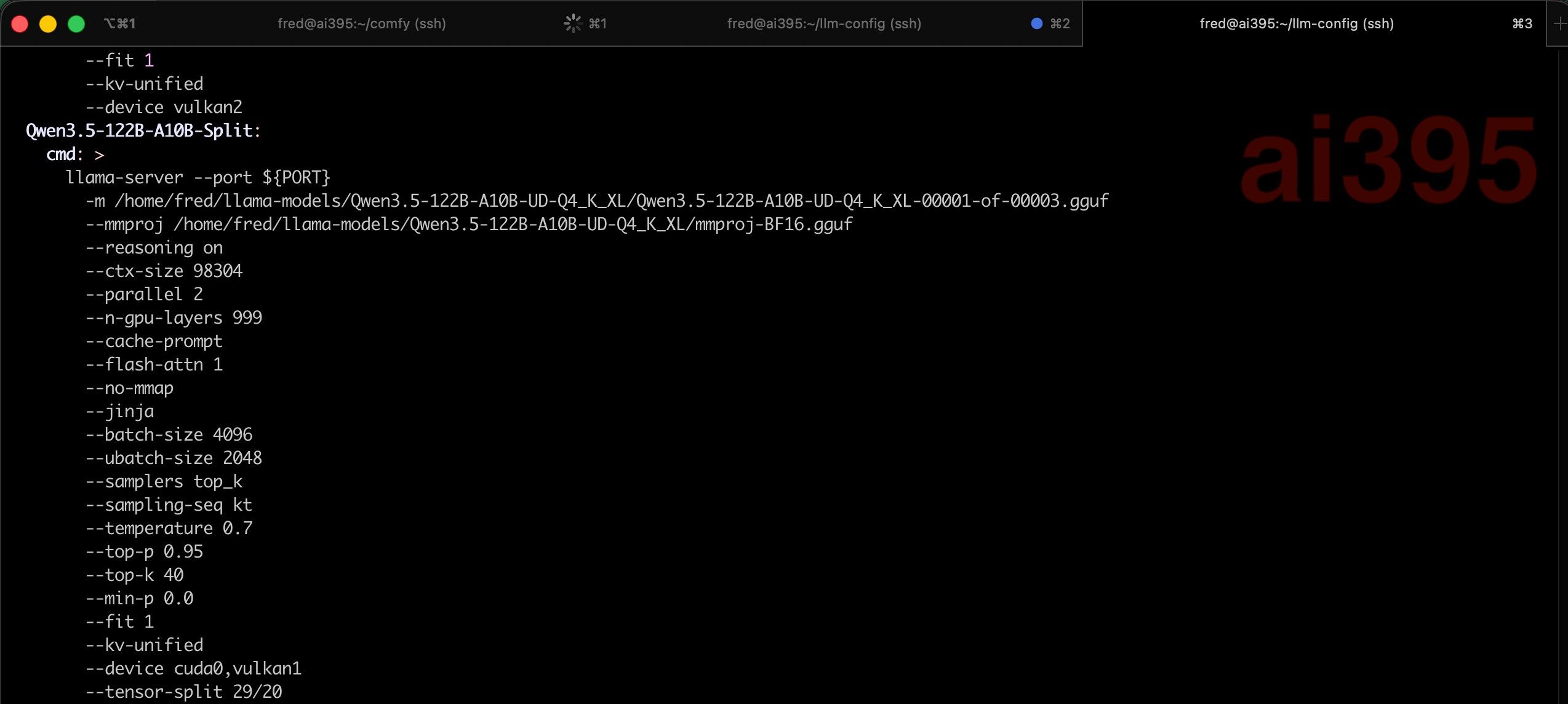
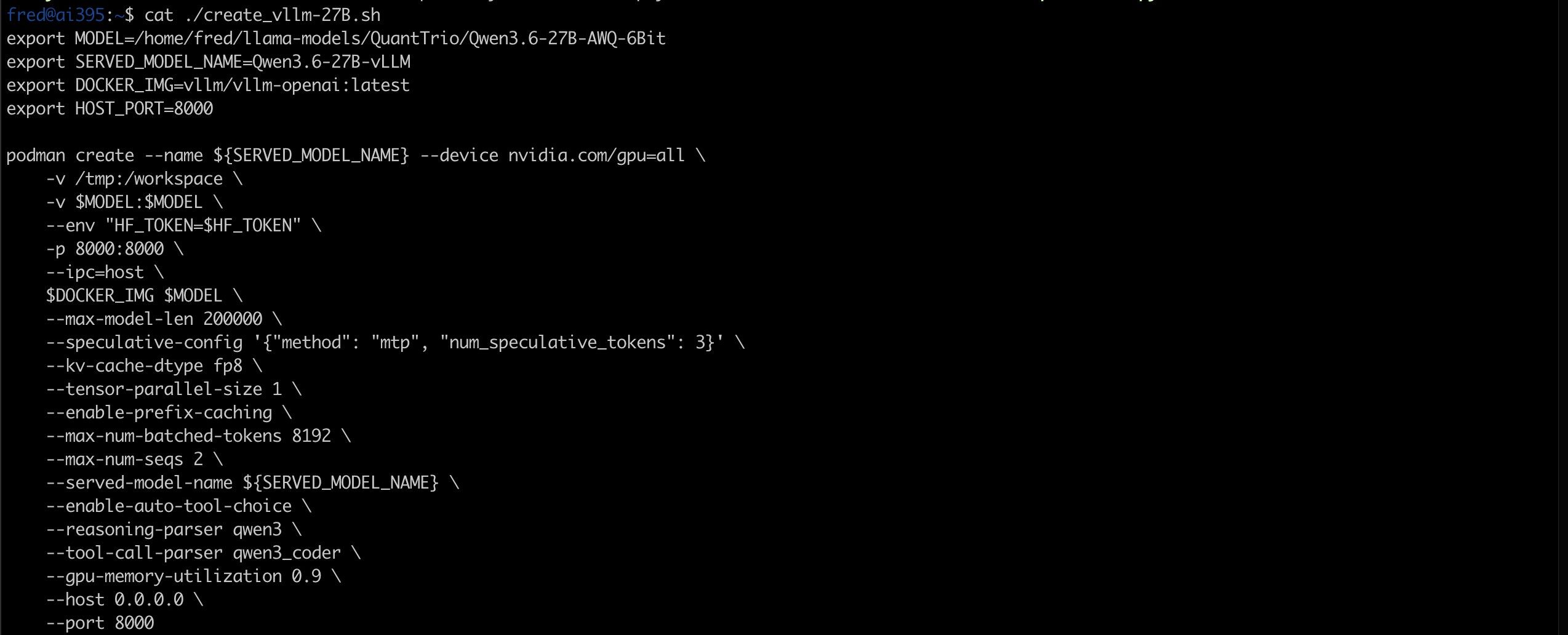
问下,我的笔记本mac他的显存可以给到23gb左右,我发现4bit量化的qwen 3.6 27b明显强于qwen 3.5 9b 8bit换成3.5也类似。我只有2w rmb的预算是在买个mac 64gb还是上英伟达显卡,算了装台湾人上辉达显卡还是mac,2w人民币预算。我不想折腾Claude,封号太严重了,Gemini确实生成代码质量不太高,而且客户要求隐私。
你这个需求有2万预算绰绰有余了。目前情况下一定是上独立显卡不管是R9700还是英伟达的某个魔改卡,肯定比mac的效果好。
如果羡慕claude code的效果,又不想用官方模型,可以试试这个:https://github.com/Alishahryar1/free-claude-code 这个项目,把本地LLM伪装成claude code的官方网关,顶在你的本地llama.cpp之前,模拟出全功能的Opus、Sonnet、Haiku模型。你开发的客户端可以用claude code,享受全量功能和插件(包括automode也能开)。
但更原生不折腾的方法也有,用trae.CN做编程,直接对接llama.cpp就是了(推荐)。