这部分说具体折腾过程。
1. 为什么 D1581 没继续用来带 4090D
D1581 不是废物。做 NAS、轻服务、低功耗常驻都可以。
但带 4090D 48G 长期跑本地大模型,我觉得不合适。
不是点不亮,也不是完全不能跑,而是整个使用状态都在将就:
平台老
机箱和散热不舒服
电源和走线不舒服
PCIe 和扩展余量有限
系统响应和维护体验一般
后续折腾空间小
大模型推理大头确实在 GPU,但宿主平台也不是完全没影响。模型加载、prompt processing、磁盘 IO、驱动环境、远程服务、散热稳定性,最后都会影响日常体验。
所以 D1581 最后回到 NAS 和轻服务位置。
2. 为什么选 X99 AD4 + E5-2690 v4
X99 AD4 + E5-2690 v4 不是性能信仰。
我的要求很简单:
能稳定跑 Ubuntu 24.04
能插 4090D
能复用旧 ECC DDR4
能远程管理
能常驻 llama-server
不要给 GPU 添太多麻烦
从这个角度看,X99 作为低成本 GPU 宿主是合适的。
E5-2690 v4 单路 14 核 28 线程,今天看不算强。但我的目标不是让 CPU 跑推理,而是让它稳定承载 4090D。旧 ECC 内存还能继续用,这一点对成本很有帮助。
3. 为什么 4090D 48G 给 LLM
买 4090D 48G 前,真正纠结的是显存,不是算力。
如果只是游戏和 ComfyUI,4080S 16G 还能继续用。但本地大模型不一样。
我的目标是跑 Qwen3.6-27B,并尽量保留:
Q8_0 量化
较长上下文
KV Cache 不要压得太狠
MTP 加速
本地 API 常驻
coding / agent 场景稳定
这些条件叠起来以后,16G 显存肯定不合适。24G 能玩,但会频繁在模型量化、上下文长度、KV Cache 和速度之间算账。
48G 的价值不是跑分好看,而是让 27B Q8_0 进入比较舒服的长期使用状态。
4. Qwen3.6-27B 当前配置
我现在跑的是:
Huihui-Qwen3.6-27B-abliterated-MTP-GGUF
Q8_0
llama.cpp
Ubuntu 24.04
4090D 48G
目前比较稳定的思路是:
主模型:Q8_0
KV Cache:q8_0
Flash Attention:开
MTP:开
spec-draft-n-max:2
parallel:1
日常上下文:64K
大文档备用:262K
262K 配置大概如下:
/home/ivanyin/AI/llama.cpp/build/bin/llama-server \
-m "/home/ivanyin/AI/GGUF/huihui-ai/Huihui-Qwen3.6-27B-abliterated-MTP-GGUF/Huihui-Qwen3.6-27B-abliterated-ggml-model-Q8_0.gguf" \
--alias huihui-q8 \
--host 0.0.0.0 --port 8080 --no-webui \
-ngl all --parallel 1 \
-c 262144 -fa on \
-ctk q8_0 -ctv q8_0 \
-b 2048 -ub 512 \
--spec-type draft-mtp --spec-draft-n-max 2 \
--jinja \
--reasoning off \
--chat-template-kwargs '{"preserve_thinking":false}'
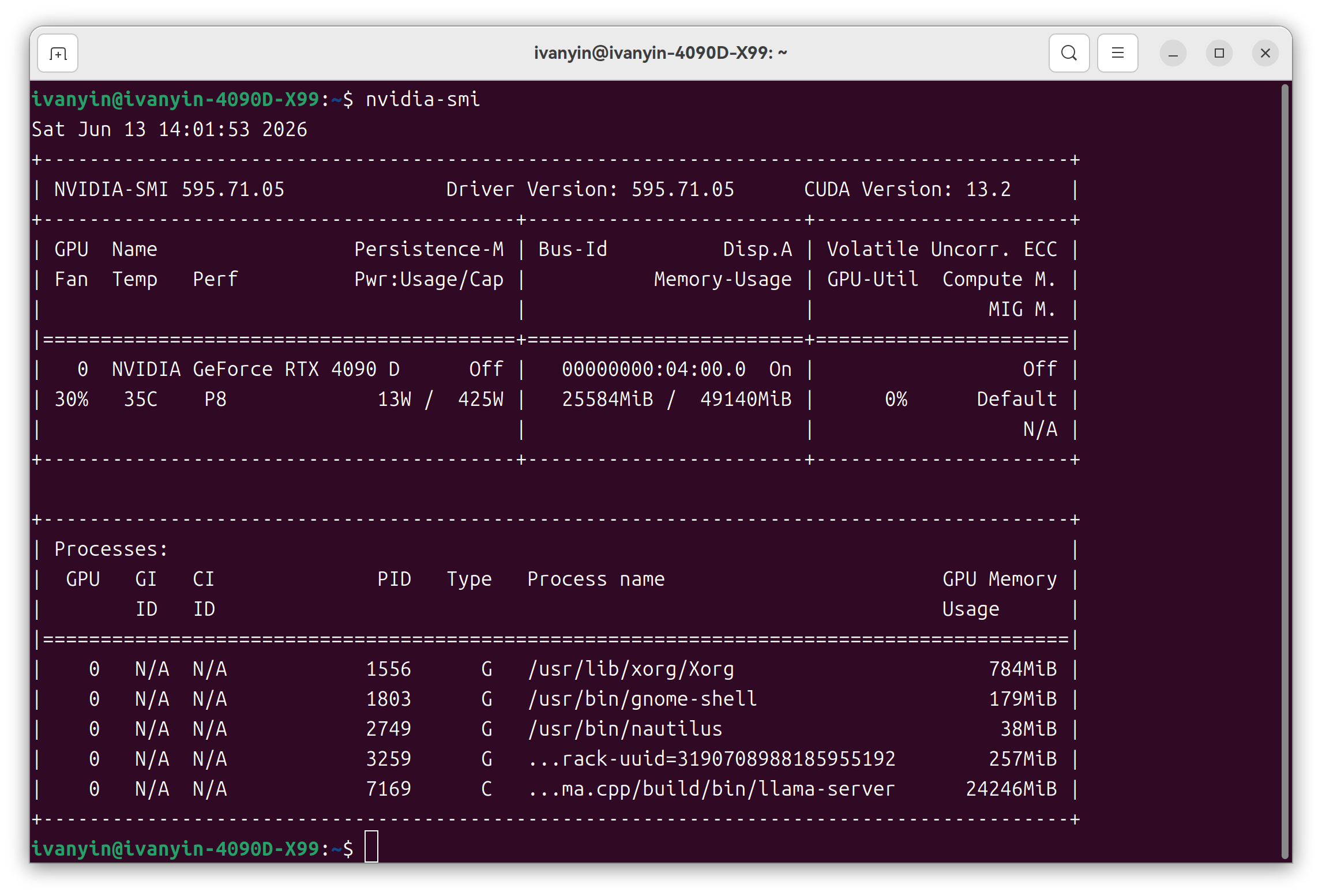
这套配置下,262K 上下文显存大概 40GB 出头,4090D 48G 还有余量。
但我现在不建议日常默认 262K。长上下文的麻烦不完全在生成速度,更多时候在 prompt processing。一次性塞很多内容进去,前处理会明显拖慢。262K 更像是备用能力,不是每天都要拉满。
我现在更常用的是:
日常 coding / agent:64K,reasoning off
大文档 / 大项目:262K,reasoning off
创作 / 剧情 / 分镜:64K,可按需开 reasoning
5. MTP 为什么固定 N=2
Qwen3.6 的 MTP 确实有用。
我现在固定:
--spec-type draft-mtp --spec-draft-n-max 2
自己的取舍大概是:
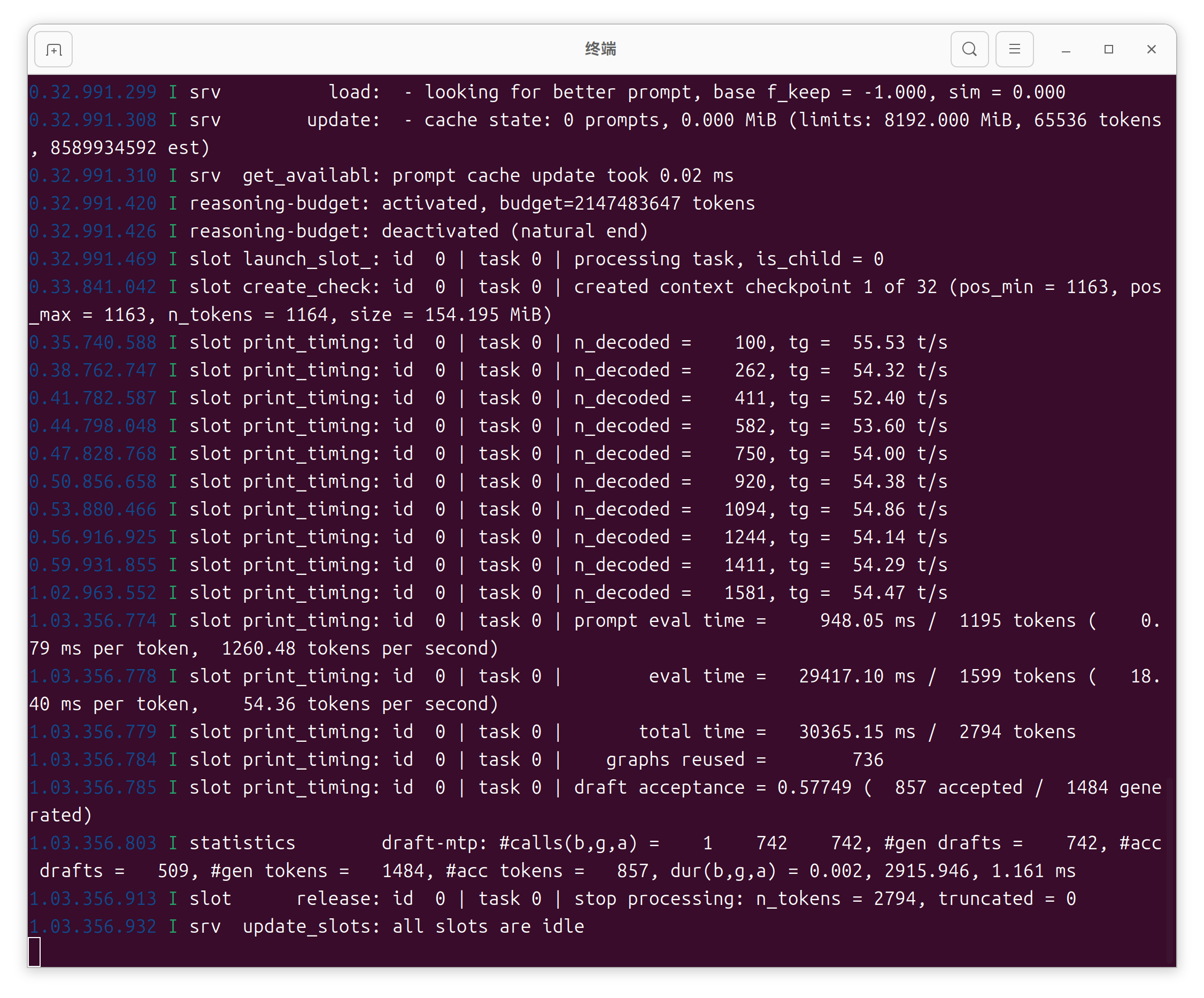
无 MTP:约 29.7 t/s
N=1:稳,加速明显
N=2:约 46.8 t/s,速度、接受率、稳定性比较平衡
N=4:有时更快,但接受率下降
N=5:拒绝太多,不适合长期干活
跑 benchmark 可以试 N=4。
但日常 coding、agent、工具调用,我更愿意要 N=2。
本地模型长期用,不是只看最高 t/s。体感等待、输出稳定性、服务可靠性,都要算进去。
6. KV Cache 为什么选 q8_0
KV Cache 我最后选:
-ctk q8_0 -ctv q8_0
f16 当然更保守,但 262K 下显存占用太高。
q4_0 更省显存,但我都上 48G 了,也没必要一开始压这么狠。
q8_0 这个点比较舒服:
比 f16 省显存
比 q4_0 更让我放心
速度没有明显损失
适合 27B Q8_0 + 长上下文
7. Thinking 不无脑开
写代码、OpenCode、工具调用这些场景,我基本关掉:
--reasoning off
--chat-template-kwargs '{"preserve_thinking":false}'
原因很简单:这些场景更需要直接、稳定、可复现。Thinking 会吃 token,但不一定带来更好的结果。
创作类任务可以开,但必须限制 budget:
--reasoning on \
--reasoning-budget 256 \
--chat-template-kwargs '{"preserve_thinking":true}'
本地推理的 token 都是自己的时间、电费和等待。不是越会想越好。
8. 4080S 和 Mac mini 的位置
4080S 这台机器不是纯生图机,它还是我的游戏机:
MSI B550M 迫击炮
Ryzen 9 5900X
32GB 内存
RTX 4080 Super 16G
它跑 27B LLM 会比较尴尬,但跑游戏、ComfyUI、SDXL、LoRA、ControlNet、局部重绘、提示词调试都很舒服。让它继续做桌面主力,比被 LLM 常驻占显存更合理。
Mac mini M4 则更像 API 工作台:
调用 DeepSeek API
调用本地 Qwen3.6 API
调用其他在线模型 API
写程序
写文章
整理资料
SSH 到 Ubuntu 机器
打开 ComfyUI 和本地模型前端
重计算交给 4090D 和 4080S,Mac mini 负责调度和使用。这个分工目前比较舒服。

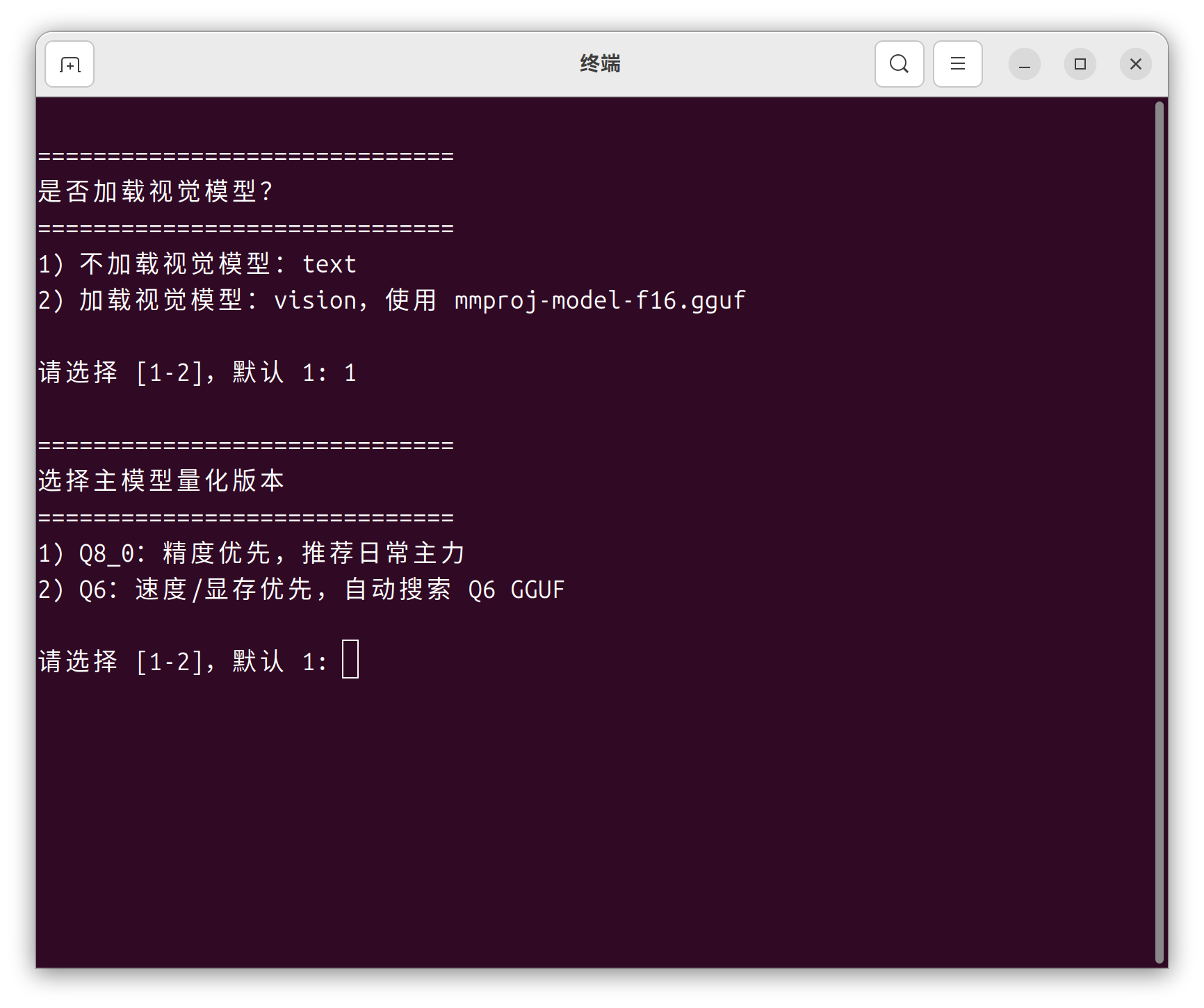
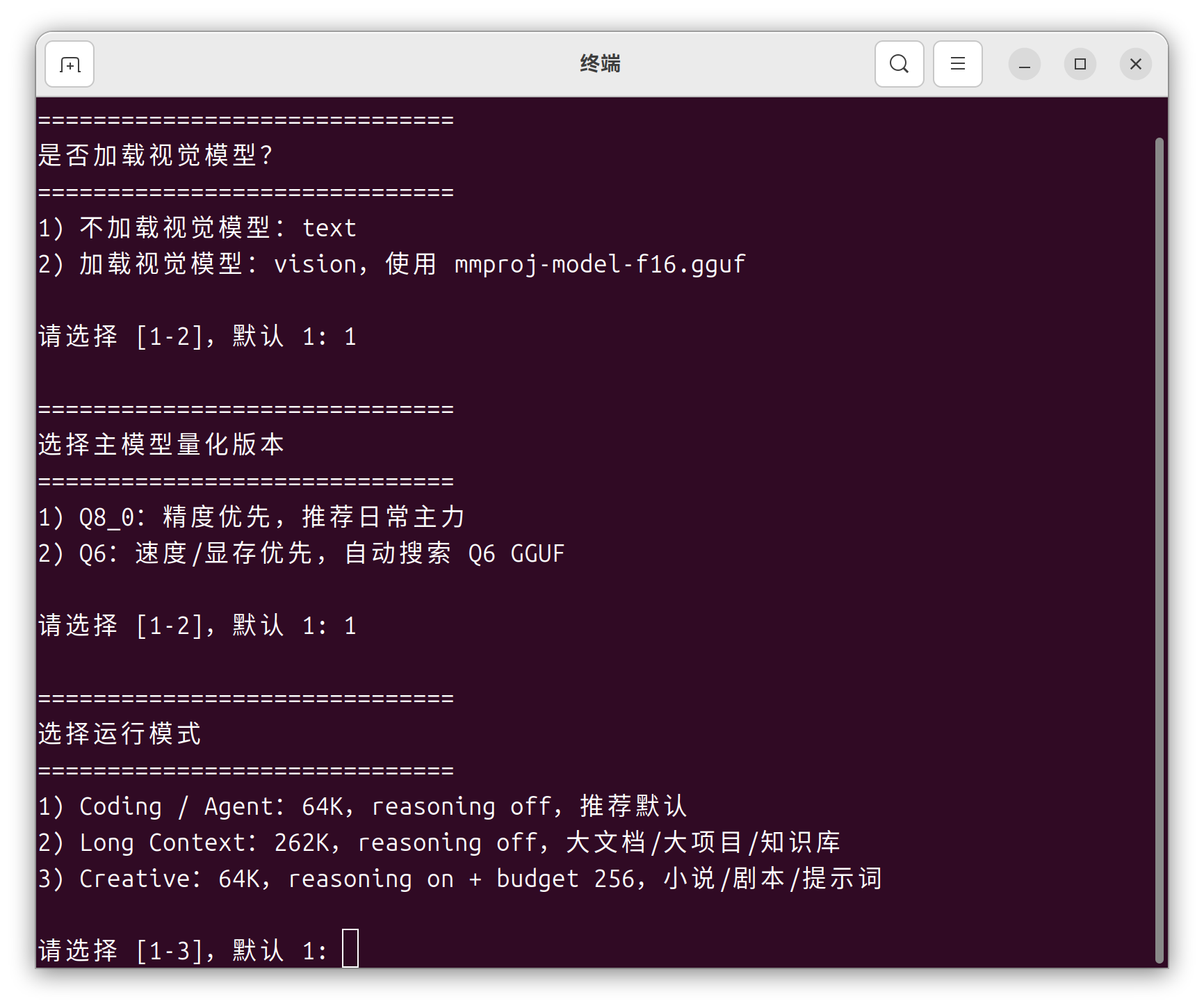
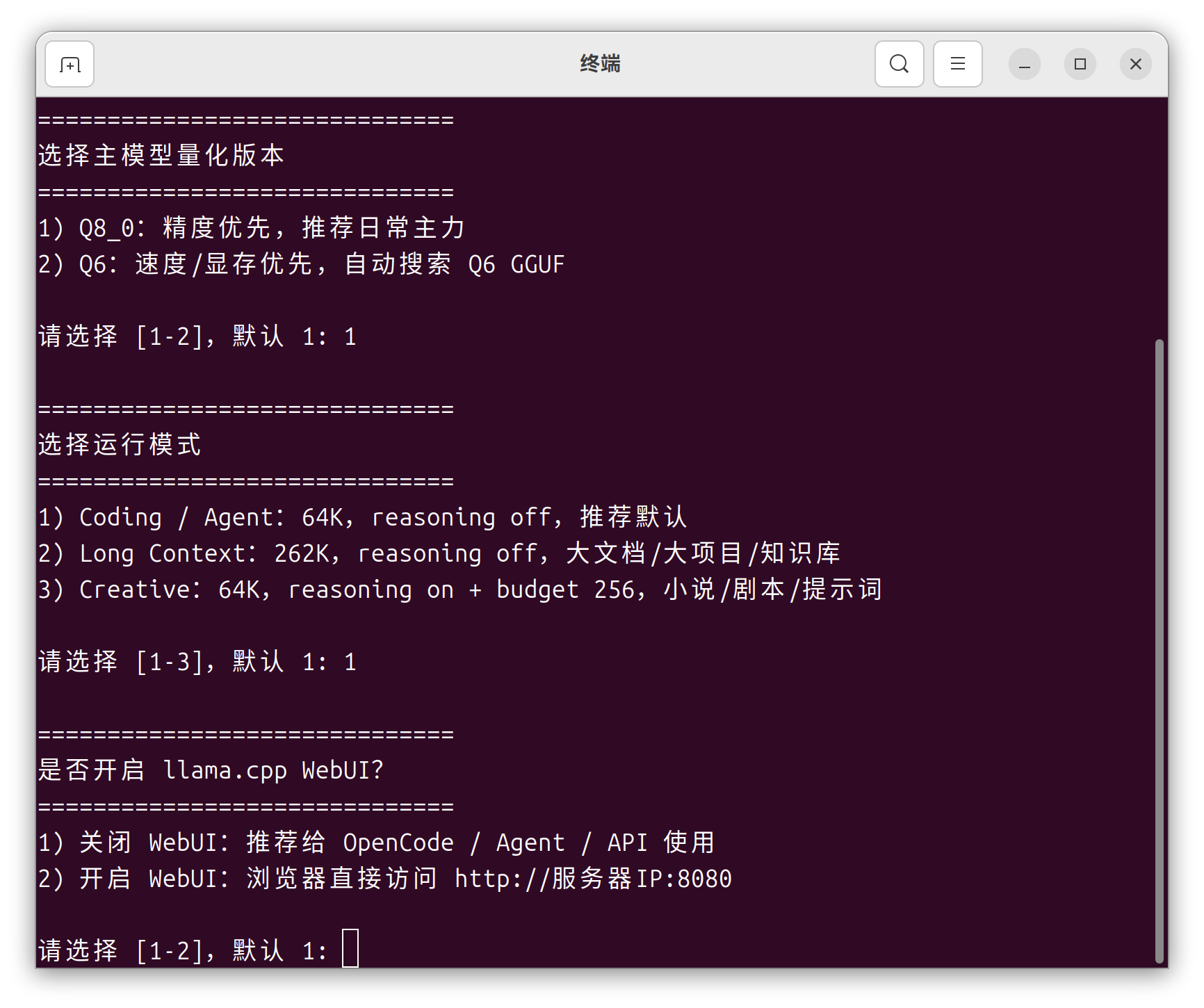
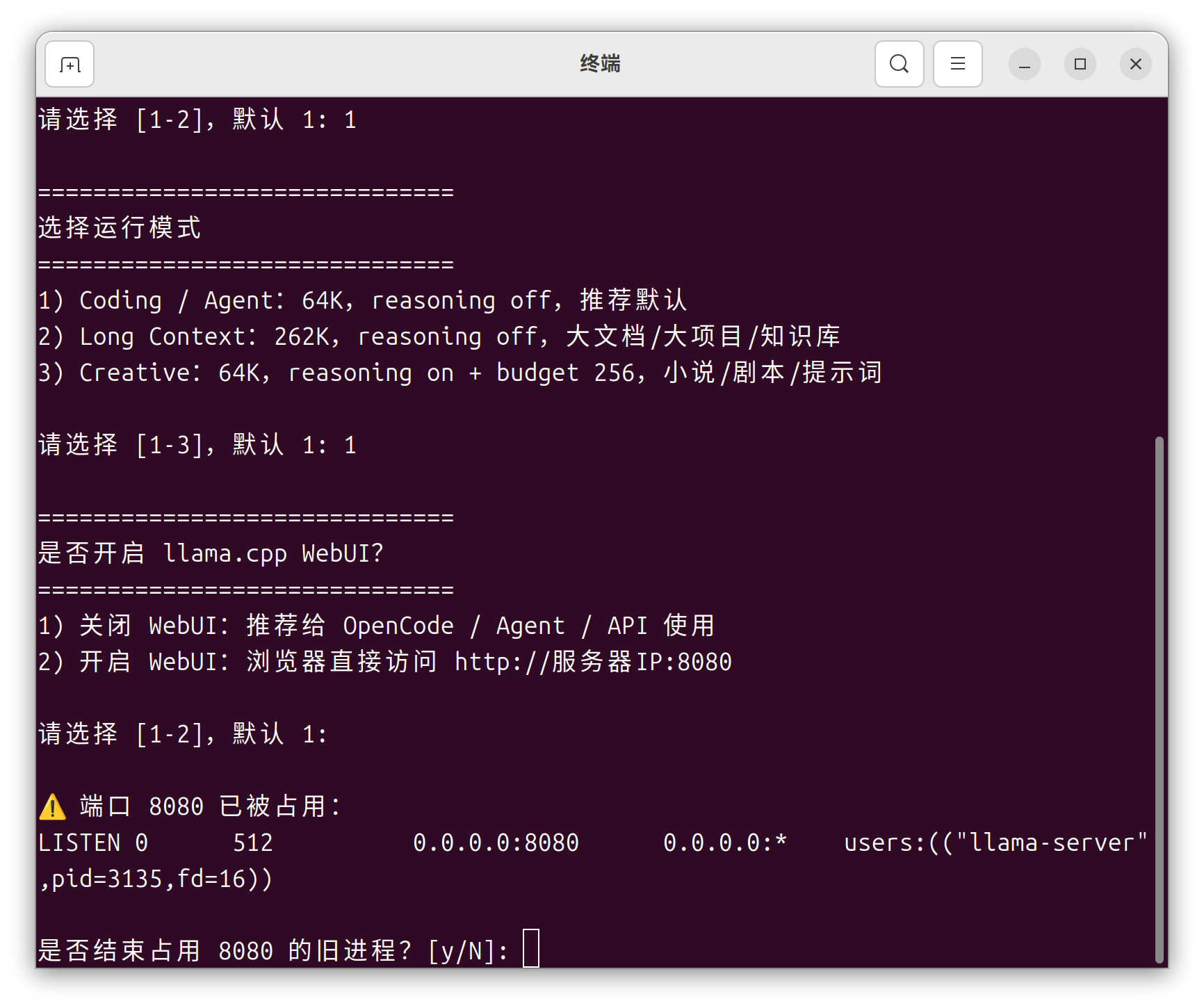
 ️ 使用提示:模型和 llama.cpp 的路径请根据自己电脑的实际地址修改(懒得手改的话,直接把路径要求连同文件一起扔给 Hermes 就行)。
️ 使用提示:模型和 llama.cpp 的路径请根据自己电脑的实际地址修改(懒得手改的话,直接把路径要求连同文件一起扔给 Hermes 就行)。