
3 slot
对,3 slot
3 slot
对,3 slot
@Leon-Y prefill 呢?
忘了看了
@Leon-Y 3090的nvlink在哪里买?多少钱呀?
taobao, RMB2500
已经完成了吗? 还是在训练中? 效果怎么样? 建议将整个工程描述得更清晰些, 可以形成几个文章.
我理解 AI Agent 只是辅助训练, 后续还有对标识正确性的检验, 模型的质量, 以及应用场景和方法等等.
还在训练中,这几天就忙着搭了基于 hermes自动迭代,踩了不少坑
注意:此文由AI辅助生成,不喜勿喷
各位同好大家好,今天在这里和大家分享一个我最近利用Hermes Agent构建、自建算力训练的计算机视觉多级分类项目。
古泉(目前主要是明清钱币)的图像识别在实际应用中一直是一个强类间干扰、细粒度的分类难点。目前,项目已跑通 52 万张有效图像 的全流程训练,整体架构设计、特征对齐与 Hermes Agent 托管的自动化闭环已平稳落地。
一、 训练管线设计:多阶段递进式微调
为了最大化特征提取效率,整个微调管线分为三个递进的阶段:
二、 无监督自训练闭环
面对 50 万级别的数据量,人肉标注成本极其高昂。我设计了一套无监督自迭代标注流程,让图片数据集在无人工介入的状态下实现“滚雪球”式增长:
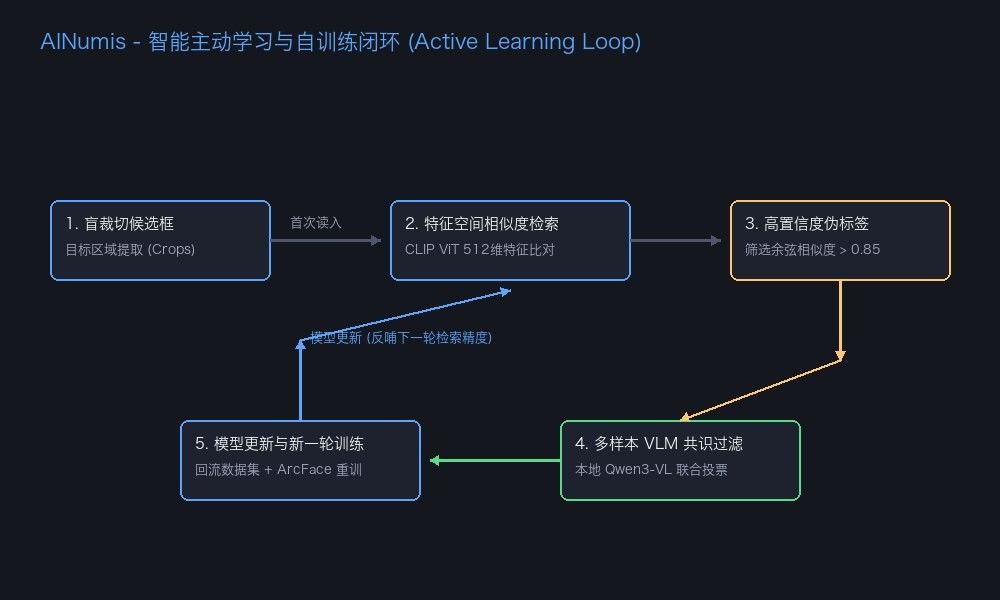
该闭环利用阶段性产出的特征向量在海量无标记数据中进行高置信度判定。对于处于决策边界的模糊样本,则由后台调用本地大语言模型服务进行多维度的共识投票清洗,洗净标签噪声后自动并入数据集进行重训,实现模型精度的自我进化。
三、 基于 Hermes Agent 的自愈式自动化运维
在大规模模型微调中,工程中断与硬件异常是最耗费精力的部分。为此,引入了 Hermes Agent 作为整个训练管线的托管核心,实现了完全自愈的运行模式:
Hermes Agent 作为基础架构中的“AI 运维与算法助理”,彻底将我从冗长、繁琐的“盯日志改 Bug”中解放出来,让研究精力可以 100% 聚焦在算法架构本身。
欢迎对图像检索、细粒度度量学习以及 AI Agent 托管训练方向感兴趣的同行多提宝贵意见,共同探讨!
硬件信息可以参考我之前的帖子 https://lcz.me/topic/466/双3090-ollama-加载-q8-视觉模型瞬间断电重启-求老哥们把脉
@Leon-Y 你用Corsair RM1000X给两张3090+主板供电吗?第二张卡用那个接口供电?
Corsair RM1000X有6个CPU/PCIe接口,两个3090只占了4个
asked hermes to learn https://github.com/noonghunna/club-3090 and changed PSU to Corsair RM1000X
it works now!!!

