前端 Hermes 0.12->0.13 跑在wsl2
后端 lama.cpp version: 8940 (78433f606) built with Clang 19.1.5 for Windows x86_64
系统 Win11 24H2
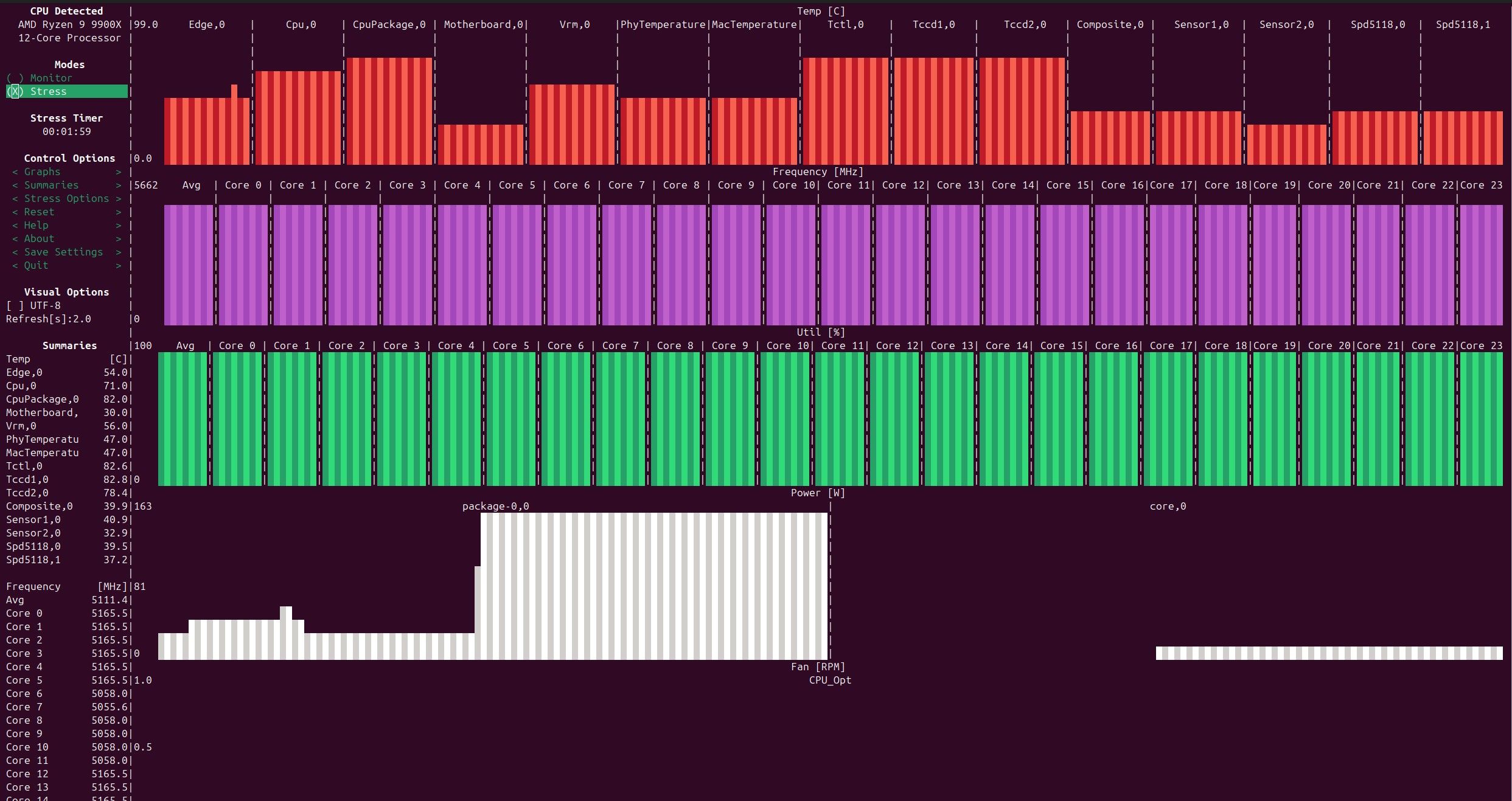
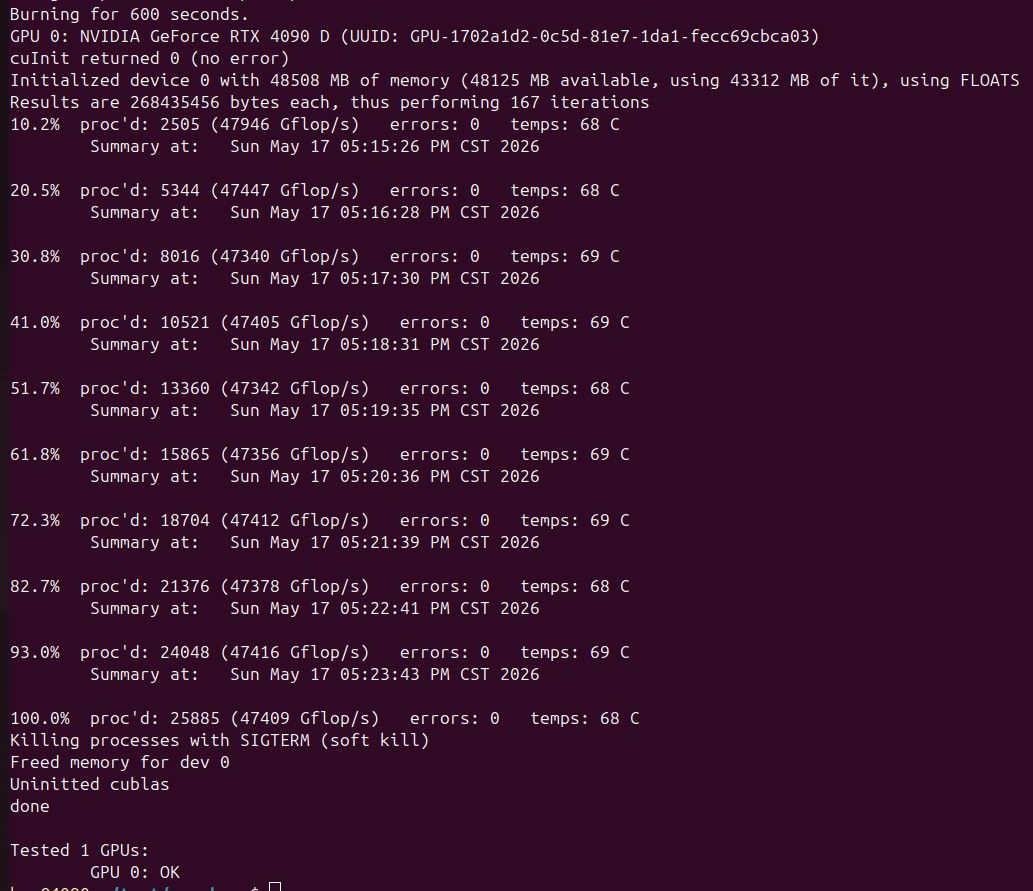
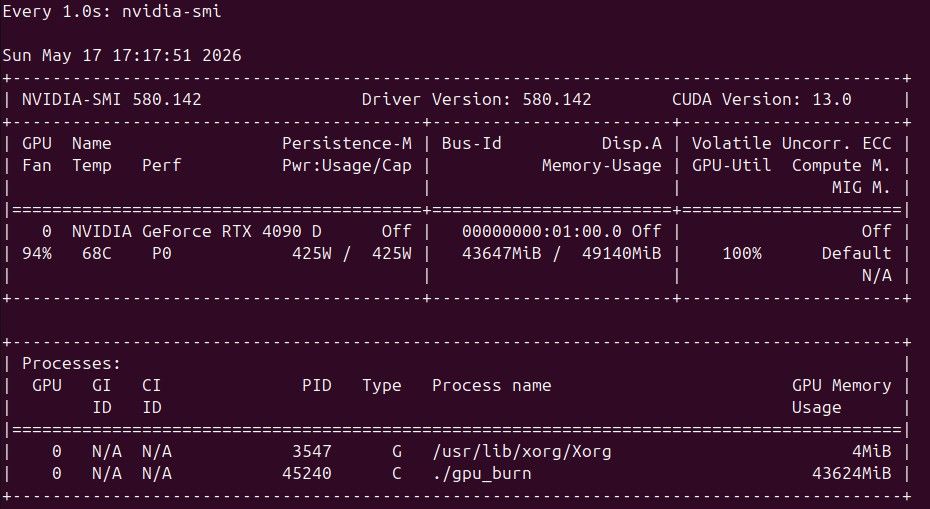
硬件 98x3d 24G*2 5090dd 24G
llama-server启动参数
set "LLAMA_ARGS_NORMAL=-ngl all -c 81920 --flash-attn on -n -1 --keep -1 --batch-size 512 --ubatch-size 512 --parallel 1 --cache-ram 32768 --cache-type-k q8_0 --cache-type-v q8_0 --no-mmap --mlock --jinja"
模型 Qwen3.6 27B Q4
每天下班到家7点,一刻不停一直玩Hermes到3点,持续了一周,白天上班也会抽2-3小时玩,谈一谈体会,
一上手是非常惊艳的,Hermes + Qwen3.6展现了非常强的协同水准,让人感觉给他一个手脚就可以放进人形机器人当大脑。简单任务自我排障、纠错和通过本地编码完成任务的能力很强。
然后说说缺点,也可能是我不会用,
1、llama开了cache mem参数就是希望长上下文不爆KV缓存,放到内存可能每次prefill的速度都会受影响。当然这个是环境原因。
2、需要调用外部平台api的,如果是模型完全不懂的会web搜索找官方文档或者去git上看源码。如果模型了解该api,但是外部平台api版本迭代了,Hermes就会按照自己的逻辑处理,最后的质量不一定能保证。我也训练了专门的skill触发器要求hermes在连续尝试失败后调用在线api问deepseek并联网搜索,指令遵循度不高。当然也可以尝试用Gateway Hook的方式,还没有测试。
3、申请授权的逻辑非常迷,有的操作我认为需要授权它自己就干了,例如修改配置文件,有的操作不需要授权(任务过程中的中间步骤),哪怕我点了always,还是会找我授权。也可能是我不会用,设置有问题。
4、Hermes自我排障过程中,会不停尝试各种解决办法,产生很多临时文件,自己不会去清理,临时文件存放的位置也非常随意,可能和LLM有关系。
5、预训练了skill,写好了脚本,用于执行复杂的多层嵌套任务(我目前是3层),还只是非异步任务,会碰到各种各样的问题,Hermes会自说自话找其他路径解决(质量差),而不是中断任务去定位当前的问题,并向我汇报等我来决策。
6、干活儿干一半,不说话了,有时候是还在跑,我如果和它对话就会interrupt当前的job,有时候是它自己停了,我还在担心会不会打断它在那里傻等。我平时是通过观察gpu负载看它是不是在干活儿的,一方面有的任务是cpu的,负载太低观察不了,有时候也会出现明明应该调用大模型但是gpu延迟很久负载才起来的情况。
总结一下,
1、生产的工作流,最好还是自己coding,起码自己review,验证无误,agent只负责执行、整理、提交之类的sop任务。
2、上下文大小和prefill的速度非常重要,在线api像特哥说的,白菜价了,就别折腾本地后端了,花了很长时间调优就是浪费生命,你的时间更值钱。
3、Hermes一周使用下来,从整体来说给我的感觉是惊艳,看到了未来的星辰大海,上面说的缺点瑕不掩瑜(而且大概率是我自己菜),社区更新速度非常快。
这台电脑本来是买来打游戏的,和hermes一比,游戏太无聊了。
P.S. 感谢老特提供这个交流的平台和毫无保留的分享。
个人观点经验,不喜轻喷哈,准备装新机子去了。
============================================
对了,请教一下各位大神,有没有在线API能实现类似网页版LLM的工作流的效果的,
即 “提示词 -> 思考 -> 联网搜索 -> 思考 -> 联网搜索 -> 思考 -> 回答“
不胜感激~