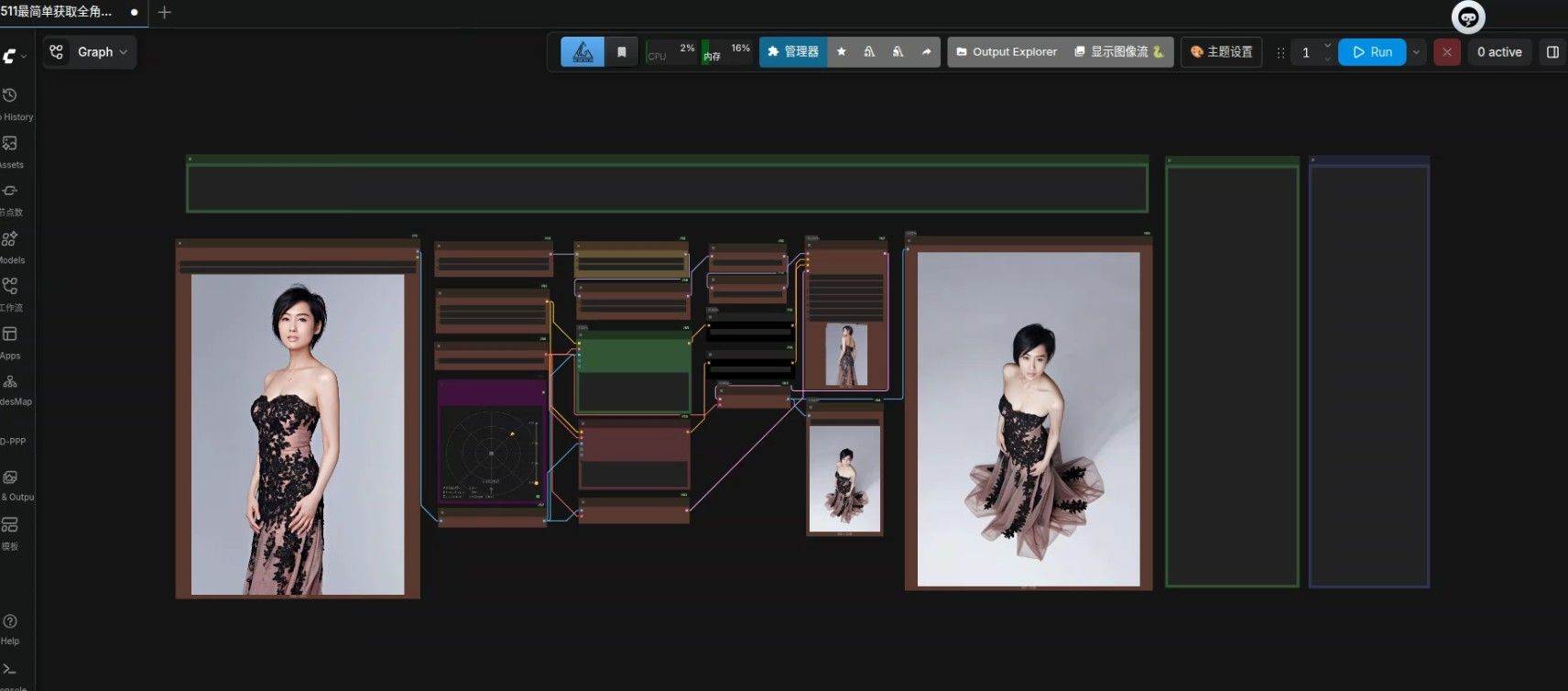
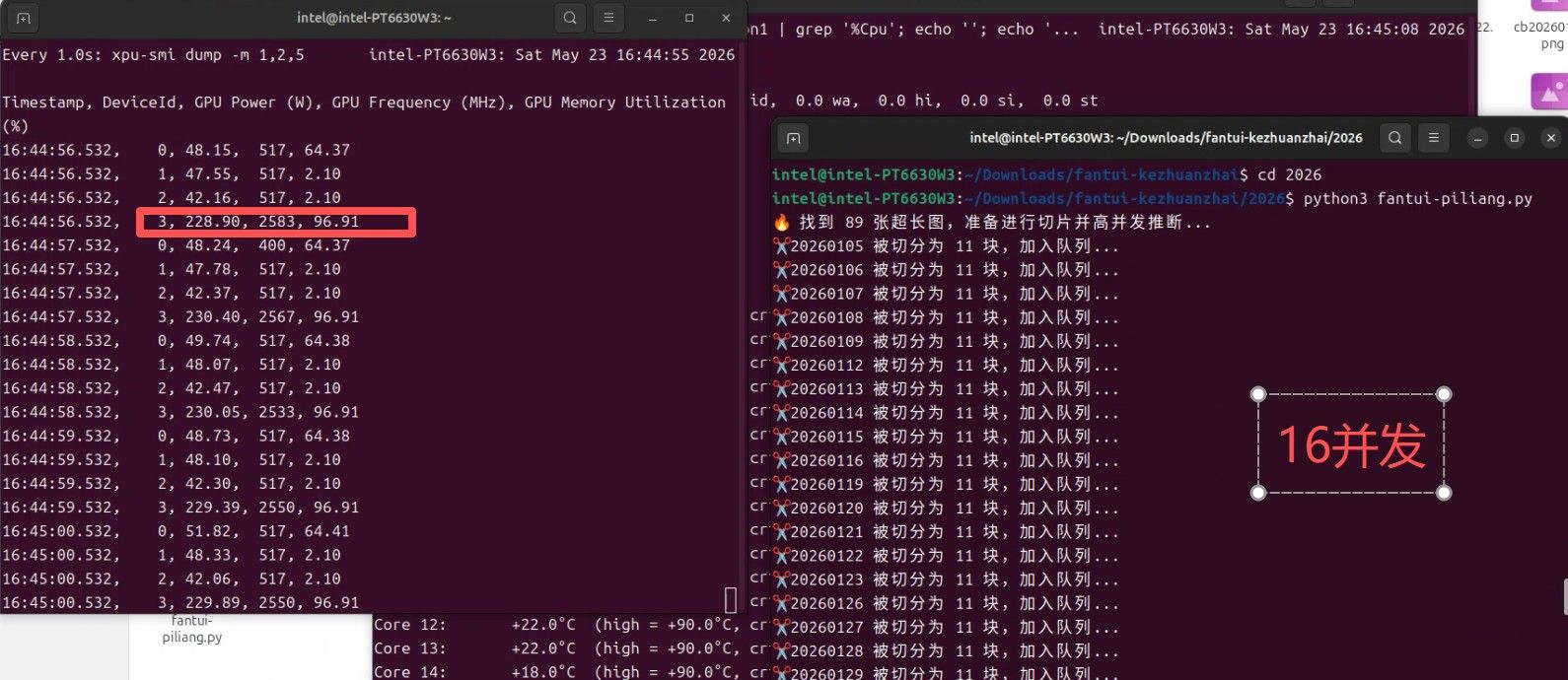
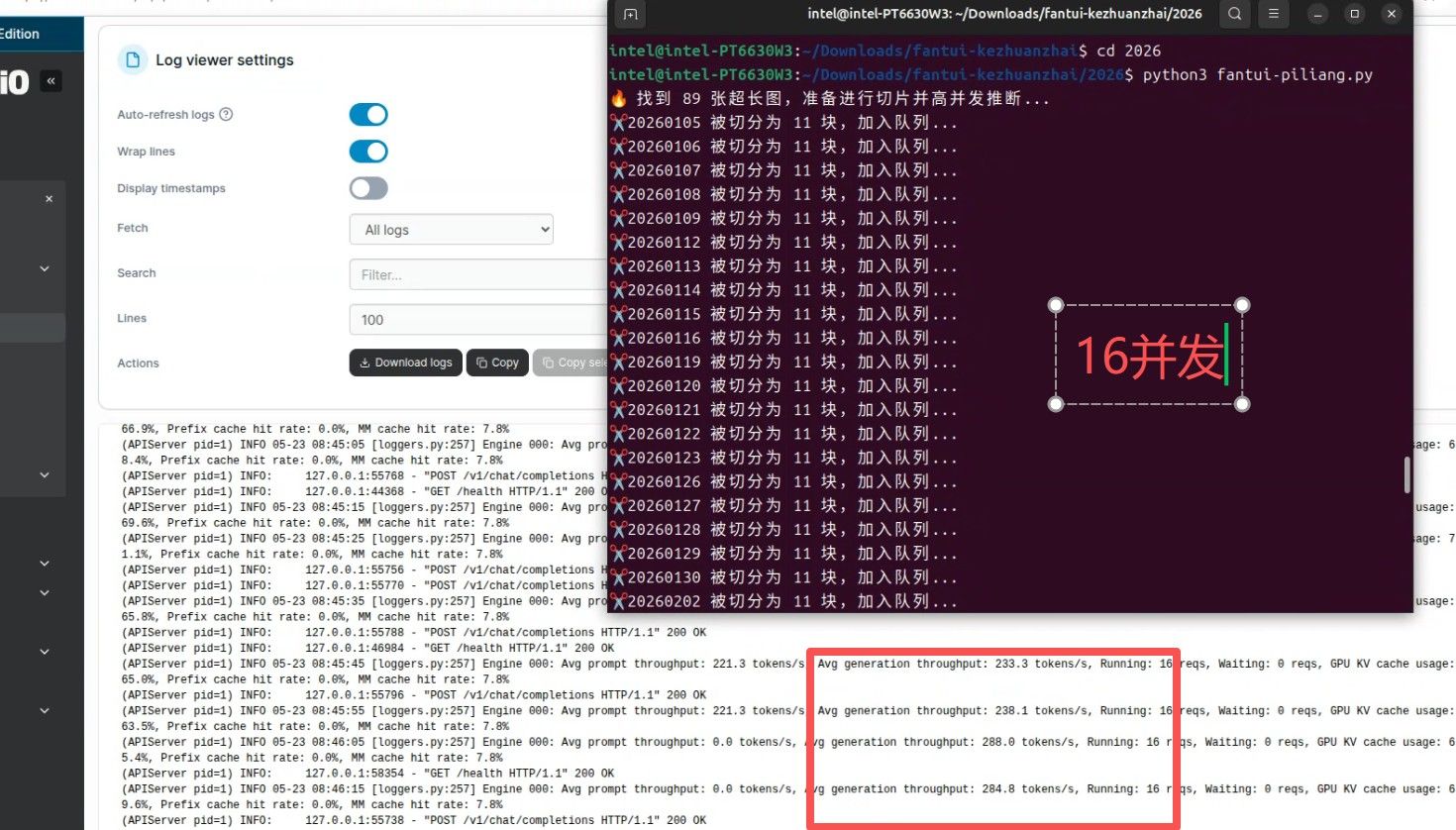
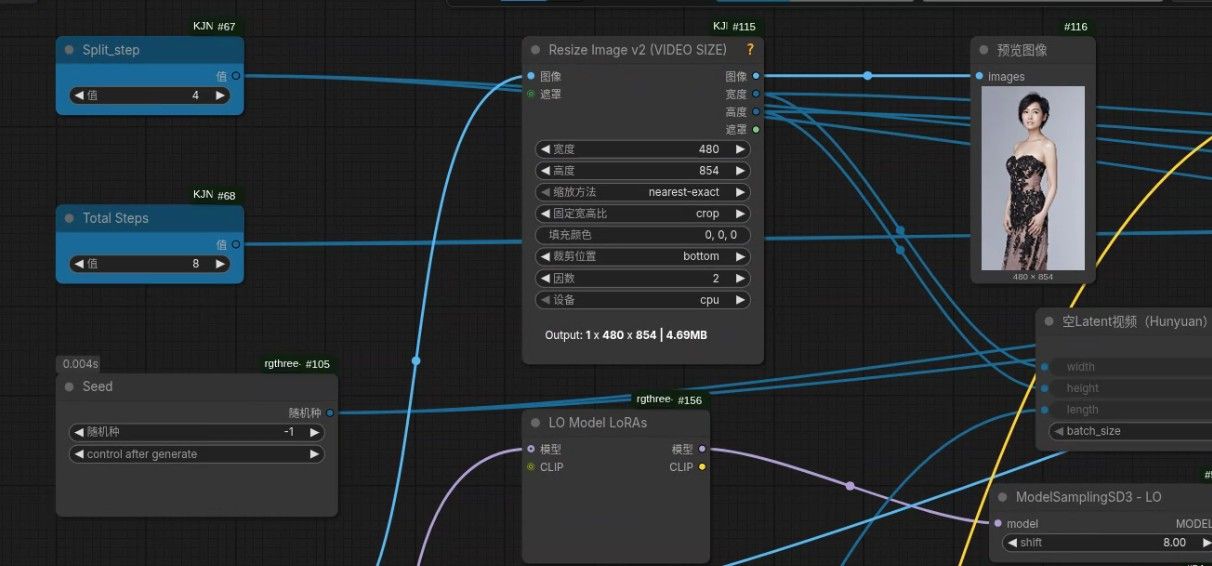
为了方便大家测试,我把流共享出来:
{
"id": "803716fc-9d9d-4d02-817c-855cdd6b4855",
"revision": 0,
"last_node_id": 27,
"last_link_id": 30,
"nodes": [
{
"id": 2,
"type": "FluxKontextMultiReferenceLatentMethod",
"pos": [
797.1906256982577,
12.11786329545784
],
"size": [
309.6734375,
70
],
"flags": {},
"order": 15,
"mode": 0,
"inputs": [
{
"label": "条件",
"name": "conditioning",
"type": "CONDITIONING",
"link": 2
},
{
"label": "参考Latent方法",
"name": "reference_latents_method",
"type": "COMBO",
"widget": {
"name": "reference_latents_method"
},
"link": null
}
],
"outputs": [
{
"label": "条件",
"name": "CONDITIONING",
"type": "CONDITIONING",
"links": [
13
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "FluxKontextMultiReferenceLatentMethod",
"ue_properties": {
"widget_ue_connectable": {
"reference_latents_method": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65
},
"widgets_values": [
"index_timestep_zero"
],
"color": "#222",
"bgcolor": "#000"
},
{
"id": 3,
"type": "FluxKontextMultiReferenceLatentMethod",
"pos": [
797.1906256982577,
-117.88213670454216
],
"size": [
309.6734375,
70
],
"flags": {},
"order": 16,
"mode": 0,
"inputs": [
{
"label": "条件",
"name": "conditioning",
"type": "CONDITIONING",
"link": 3
},
{
"label": "参考Latent方法",
"name": "reference_latents_method",
"type": "COMBO",
"widget": {
"name": "reference_latents_method"
},
"link": null
}
],
"outputs": [
{
"label": "条件",
"name": "CONDITIONING",
"type": "CONDITIONING",
"links": [
12
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "FluxKontextMultiReferenceLatentMethod",
"ue_properties": {
"widget_ue_connectable": {
"reference_latents_method": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65
},
"widgets_values": [
"index_timestep_zero"
],
"color": "#222",
"bgcolor": "#000"
},
{
"id": 4,
"type": "CFGNorm",
"pos": [
807.1906256982578,
-247.88213670454212
],
"size": [
270,
68.33333333333334
],
"flags": {},
"order": 17,
"mode": 0,
"inputs": [
{
"label": "模型",
"name": "model",
"type": "MODEL",
"link": 4
},
{
"label": "强度",
"name": "strength",
"type": "FLOAT",
"widget": {
"name": "strength"
},
"link": null
}
],
"outputs": [
{
"label": "修正后的模型",
"name": "patched_model",
"type": "MODEL",
"links": [
11
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "CFGNorm",
"ue_properties": {
"widget_ue_connectable": {
"strength": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [
1
],
"color": "#332922",
"bgcolor": "#593930"
},
{
"id": 17,
"type": "UNETLoader",
"pos": [
-145.99967296522877,
-365.28072730924794
],
"size": [
412.4183876274179,
93.12632424766274
],
"flags": {},
"order": 0,
"mode": 0,
"inputs": [
{
"label": "UNET名称",
"name": "unet_name",
"type": "COMBO",
"widget": {
"name": "unet_name"
},
"link": null
},
{
"label": "剪枝类型",
"name": "weight_dtype",
"type": "COMBO",
"widget": {
"name": "weight_dtype"
},
"link": null
}
],
"outputs": [
{
"label": "模型",
"name": "MODEL",
"type": "MODEL",
"slot_index": 0,
"links": [
23
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "UNETLoader",
"ue_properties": {
"widget_ue_connectable": {
"unet_name": true,
"weight_dtype": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"models": [
{
"name": "qwen_image_edit_2511_bf16.safetensors",
"url": "https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI/resolve/main/split_files/diffusion_models/qwen_image_edit_2511_bf16.safetensors",
"directory": "diffusion_models"
}
],
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [
"qwen_image_edit_2511_fp8mixed.safetensors",
"default"
],
"color": "#332922",
"bgcolor": "#593930"
},
{
"id": 16,
"type": "LoraLoaderModelOnly",
"pos": [
339.08373304272516,
-365.4385152699498
],
"size": [
396.1328125,
96.66666666666667
],
"flags": {},
"order": 8,
"mode": 0,
"inputs": [
{
"label": "模型",
"name": "model",
"type": "MODEL",
"link": 23
},
{
"label": "LoRA名称",
"name": "lora_name",
"type": "COMBO",
"widget": {
"name": "lora_name"
},
"link": null
},
{
"label": "模型强度",
"name": "strength_model",
"type": "FLOAT",
"widget": {
"name": "strength_model"
},
"link": null
}
],
"outputs": [
{
"label": "模型",
"name": "MODEL",
"type": "MODEL",
"links": [
22
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "LoraLoaderModelOnly",
"ue_properties": {
"widget_ue_connectable": {
"lora_name": true,
"strength_model": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"models": [
{
"name": "Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors",
"url": "https://huggingface.co/lightx2v/Qwen-Image-Edit-2511-Lightning/resolve/main/Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors",
"directory": "loras"
}
],
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65
},
"widgets_values": [
"角度切换(VNCSS)-qwen-image-edit-2511-multiple-angles-lora.safetensors",
1
],
"color": "#432",
"bgcolor": "#653"
},
{
"id": 18,
"type": "CLIPLoader",
"pos": [
-142.2511206355773,
-201.03371333749183
],
"size": [
396.1328125,
125
],
"flags": {},
"order": 1,
"mode": 0,
"inputs": [
{
"label": "CLIP名称",
"name": "clip_name",
"type": "COMBO",
"widget": {
"name": "clip_name"
},
"link": null
},
{
"label": "类型",
"name": "type",
"type": "COMBO",
"widget": {
"name": "type"
},
"link": null
}
],
"outputs": [
{
"label": "CLIP",
"name": "CLIP",
"type": "CLIP",
"links": [
5,
18
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "CLIPLoader",
"ue_properties": {
"widget_ue_connectable": {
"clip_name": true,
"type": true,
"device": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"models": [
{
"name": "qwen_2.5_vl_7b_fp8_scaled.safetensors",
"url": "https://huggingface.co/Comfy-Org/HunyuanVideo_1.5_repackaged/resolve/main/split_files/text_encoders/qwen_2.5_vl_7b_fp8_scaled.safetensors",
"directory": "text_encoders"
}
],
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [
"qwen_2.5_vl_7b_fp8_scaled.safetensors",
"qwen_image",
"default"
],
"color": "#332922",
"bgcolor": "#593930"
},
{
"id": 14,
"type": "VAELoader",
"pos": [
-146.39059612263827,
-17.514527994231976
],
"size": [
396.1328125,
68.33333333333334
],
"flags": {},
"order": 2,
"mode": 0,
"inputs": [
{
"label": "vae名称",
"name": "vae_name",
"type": "COMBO",
"widget": {
"name": "vae_name"
},
"link": null
}
],
"outputs": [
{
"name": "VAE",
"type": "VAE",
"slot_index": 0,
"links": [
6,
9,
16,
19
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "VAELoader",
"ue_properties": {
"widget_ue_connectable": {
"vae_name": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"models": [
{
"name": "qwen_image_vae.safetensors",
"url": "https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/vae/qwen_image_vae.safetensors",
"directory": "vae"
}
],
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [
"qwen_image_vae.safetensors"
],
"color": "#332922",
"bgcolor": "#593930"
},
{
"id": 8,
"type": "FluxKontextImageScale",
"pos": [
-133.49182202879047,
560.4714628108627
],
"size": [
377.0828198681851,
37.03860129882946
],
"flags": {},
"order": 9,
"mode": 0,
"inputs": [
{
"label": "图像",
"name": "image",
"type": "IMAGE",
"link": 10
}
],
"outputs": [
{
"label": "图像",
"name": "IMAGE",
"type": "IMAGE",
"links": [
7,
8,
20
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "FluxKontextImageScale",
"ue_properties": {
"widget_ue_connectable": {},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [],
"color": "#332922",
"bgcolor": "#593930"
},
{
"id": 15,
"type": "LoraLoaderModelOnly",
"pos": [
347.0952420840532,
-220.09228397794982
],
"size": [
396.1328125,
96.66666666666667
],
"flags": {},
"order": 10,
"mode": 0,
"inputs": [
{
"label": "模型",
"name": "model",
"type": "MODEL",
"link": 22
},
{
"label": "LoRA名称",
"name": "lora_name",
"type": "COMBO",
"widget": {
"name": "lora_name"
},
"link": null
},
{
"label": "模型强度",
"name": "strength_model",
"type": "FLOAT",
"widget": {
"name": "strength_model"
},
"link": null
}
],
"outputs": [
{
"label": "模型",
"name": "MODEL",
"type": "MODEL",
"links": [
1
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "LoraLoaderModelOnly",
"ue_properties": {
"widget_ue_connectable": {
"lora_name": true,
"strength_model": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"models": [
{
"name": "Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors",
"url": "https://huggingface.co/lightx2v/Qwen-Image-Edit-2511-Lightning/resolve/main/Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors",
"directory": "loras"
}
],
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [
"Qwen-Image-Edit-2511-Lightning-4steps-V1.0-fp32.safetensors",
1
],
"color": "#332922",
"bgcolor": "#593930"
},
{
"id": 5,
"type": "TextEncodeQwenImageEditPlus",
"pos": [
354.4459050818072,
251.866217681473
],
"size": [
388.2640212658655,
214.48069935058538
],
"flags": {},
"order": 11,
"mode": 0,
"inputs": [
{
"label": "CLIP",
"name": "clip",
"type": "CLIP",
"link": 5
},
{
"label": "VAE",
"name": "vae",
"shape": 7,
"type": "VAE",
"link": 6
},
{
"label": "图像1",
"name": "image1",
"shape": 7,
"type": "IMAGE",
"link": 7
},
{
"label": "图像2",
"name": "image2",
"shape": 7,
"type": "IMAGE",
"link": null
},
{
"label": "图像3",
"name": "image3",
"shape": 7,
"type": "IMAGE",
"link": null
},
{
"label": "提示词",
"name": "prompt",
"type": "STRING",
"widget": {
"name": "prompt"
},
"link": null
}
],
"outputs": [
{
"label": "条件",
"name": "CONDITIONING",
"type": "CONDITIONING",
"links": [
2
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "TextEncodeQwenImageEditPlus",
"ue_properties": {
"widget_ue_connectable": {
"prompt": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65
},
"widgets_values": [
""
],
"color": "#322",
"bgcolor": "#533"
},
{
"id": 7,
"type": "VAEEncode",
"pos": [
354.7124804040489,
524.2547847261422
],
"size": [
384.81499821657553,
60
],
"flags": {},
"order": 12,
"mode": 0,
"inputs": [
{
"label": "图像",
"name": "pixels",
"type": "IMAGE",
"link": 8
},
{
"label": "VAE",
"name": "vae",
"type": "VAE",
"link": 9
}
],
"outputs": [
{
"label": "Latent",
"name": "LATENT",
"type": "LATENT",
"links": [
14
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "VAEEncode",
"ue_properties": {
"widget_ue_connectable": {},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [],
"color": "#332922",
"bgcolor": "#593930"
},
{
"id": 1,
"type": "ModelSamplingAuraFlow",
"pos": [
807.1906256982578,
-357.88213670454206
],
"size": [
270,
68.33333333333334
],
"flags": {},
"order": 14,
"mode": 0,
"inputs": [
{
"label": "模型",
"name": "model",
"type": "MODEL",
"link": 1
},
{
"label": "偏移",
"name": "shift",
"type": "FLOAT",
"widget": {
"name": "shift"
},
"link": null
}
],
"outputs": [
{
"label": "模型",
"name": "MODEL",
"type": "MODEL",
"links": [
4
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "ModelSamplingAuraFlow",
"ue_properties": {
"widget_ue_connectable": {
"shift": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [
3.1
],
"color": "#332922",
"bgcolor": "#593930"
},
{
"id": 9,
"type": "KSampler",
"pos": [
1140.647653458271,
-367.5409128410178
],
"size": [
286.8991258117685,
486
],
"flags": {},
"order": 18,
"mode": 0,
"inputs": [
{
"label": "模型",
"name": "model",
"type": "MODEL",
"link": 11
},
{
"label": "正面条件",
"name": "positive",
"type": "CONDITIONING",
"link": 12
},
{
"label": "负面条件",
"name": "negative",
"type": "CONDITIONING",
"link": 13
},
{
"label": "Latent",
"name": "latent_image",
"type": "LATENT",
"link": 14
},
{
"label": "随机种",
"name": "seed",
"type": "INT",
"widget": {
"name": "seed"
},
"link": null
},
{
"label": "步数",
"name": "steps",
"type": "INT",
"widget": {
"name": "steps"
},
"link": null
},
{
"label": "CFG",
"name": "cfg",
"type": "FLOAT",
"widget": {
"name": "cfg"
},
"link": null
},
{
"label": "采样器",
"name": "sampler_name",
"type": "COMBO",
"widget": {
"name": "sampler_name"
},
"link": null
},
{
"label": "调度器",
"name": "scheduler",
"type": "COMBO",
"widget": {
"name": "scheduler"
},
"link": null
},
{
"label": "降噪",
"name": "denoise",
"type": "FLOAT",
"widget": {
"name": "denoise"
},
"link": null
}
],
"outputs": [
{
"label": "Latent",
"name": "LATENT",
"type": "LATENT",
"links": [
15
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "KSampler",
"ue_properties": {
"widget_ue_connectable": {
"seed": true,
"steps": true,
"cfg": true,
"sampler_name": true,
"scheduler": true,
"denoise": true
},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [
173815537092855,
"randomize",
4,
1,
"euler",
"simple",
1
],
"color": "#332922",
"bgcolor": "#593930"
},
{
"id": 10,
"type": "VAEDecode",
"pos": [
835.9280787755798,
137.81632044395135
],
"size": [
255.0718204517343,
46
],
"flags": {
"collapsed": false
},
"order": 19,
"mode": 0,
"inputs": [
{
"label": "Latent",
"name": "samples",
"type": "LATENT",
"link": 15
},
{
"label": "VAE",
"name": "vae",
"type": "VAE",
"link": 16
}
],
"outputs": [
{
"label": "图像",
"name": "IMAGE",
"type": "IMAGE",
"slot_index": 0,
"links": [
17,
29
]
}
],
"properties": {
"cnr_id": "comfy-core",
"ver": "0.5.1",
"Node name for S&R": "VAEDecode",
"ue_properties": {
"widget_ue_connectable": {},
"version": "7.5.2",
"input_ue_unconnectable": {}
},
"enableTabs": false,
"tabWidth": 65,
"tabXOffset": 10,
"hasSecondTab": false,
"secondTabText": "Send Back",
"secondTabOffset": 80,
"secondTabWidth": 65,
"ttNbgOverride": {
"color": "#332922",
"bgcolor": "#593930",
"groupcolor": "#b06634"
}
},
"widgets_values": [],
"color": "#332922",
"bgcolor": "#593930"
},
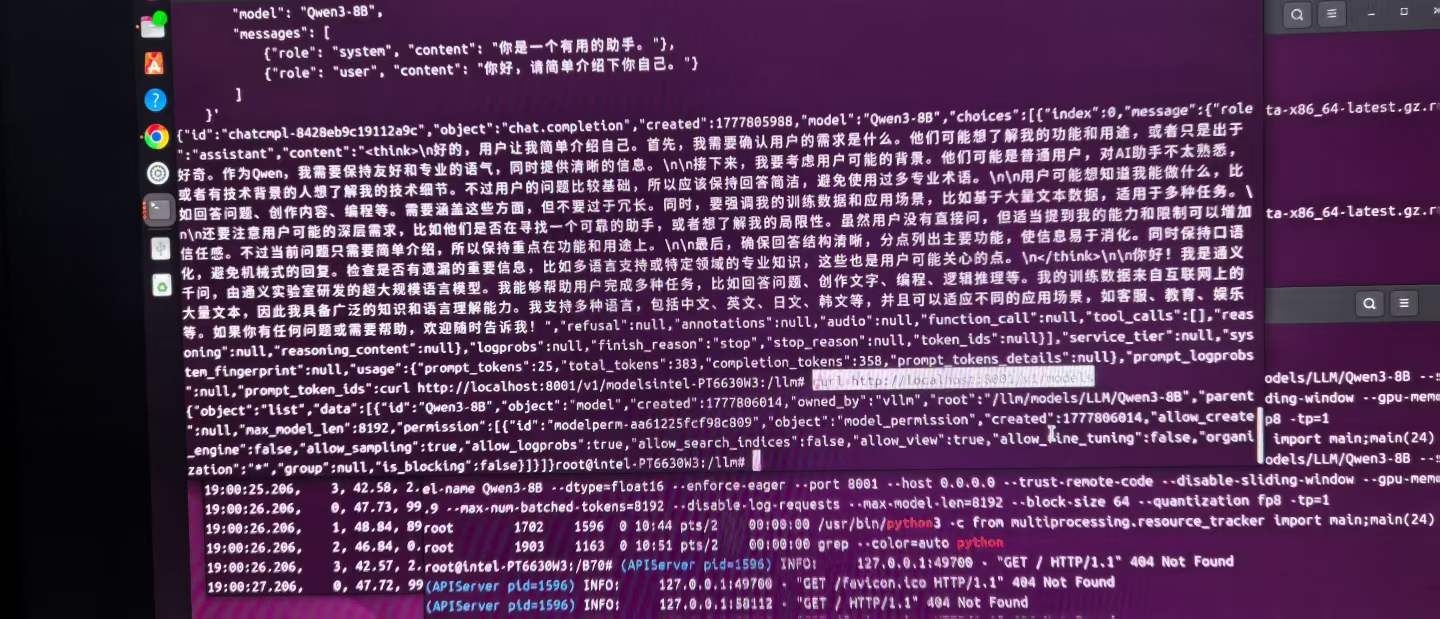
貌似不行,那就再开一个贴再贴一半吧。 我没有权限上传文件,只能贴代码了。





![da5ea6d2-5fb1-474f-bc18-91ca83b8f844[1].jpeg](https://upload.lcz.me/uploads/b86d3e2b-4456-4043-9bb5-df23bd46e120.jpeg)
![64ab71ee-809c-4fb4-83f4-bc54e5f49b25[1].jpeg](https://upload.lcz.me/uploads/173f6ad4-3d33-4f16-91b3-6c6f0cea5419.jpeg)
![45c32027-bcfa-4d8e-a7b2-5c51850b8c1e[1].jpeg](https://upload.lcz.me/uploads/3b61cb62-c4a6-489c-ad5b-454119705190.jpeg)
![37e86144-a85e-49b6-b6ab-d5c34b268ae8[1].jpeg](https://upload.lcz.me/uploads/241c6714-361a-430b-b440-2253a75fa152.jpeg)
![c1746571-5620-47ab-ba5a-65a9e33987ab[1].jpeg](https://upload.lcz.me/uploads/be2b8848-0de4-40df-bb74-3e13caa0bc4b.jpeg)
![2330b65a-9a65-4106-b82f-83bd4f74f39d[1].jpeg](https://upload.lcz.me/uploads/2901c117-2003-4b77-8ad9-0be6ef488fd5.jpeg)
![0eab9876-94ed-4e85-8c44-1df8fdd42d35[1].jpeg](https://upload.lcz.me/uploads/3b3f4455-a12f-432c-9dd6-1786eb65b68e.jpeg)
![8c935b46-dd78-4719-ba7b-51f6561e3099[1].jpeg](https://upload.lcz.me/uploads/4736d1fe-65b5-47d9-8875-f28f093731f0.jpeg)
![1dd7f10b-2d29-4696-9f06-e97e49bce01b[1].jpeg](https://upload.lcz.me/uploads/f623fbb8-214e-4e13-9f76-eb1f01c49655.jpeg)
![914b4289-9f63-4852-986b-93252852dcd5[1].jpeg](https://upload.lcz.me/uploads/765bc7ab-c505-43d4-b945-1f48e9d490ab.jpeg)
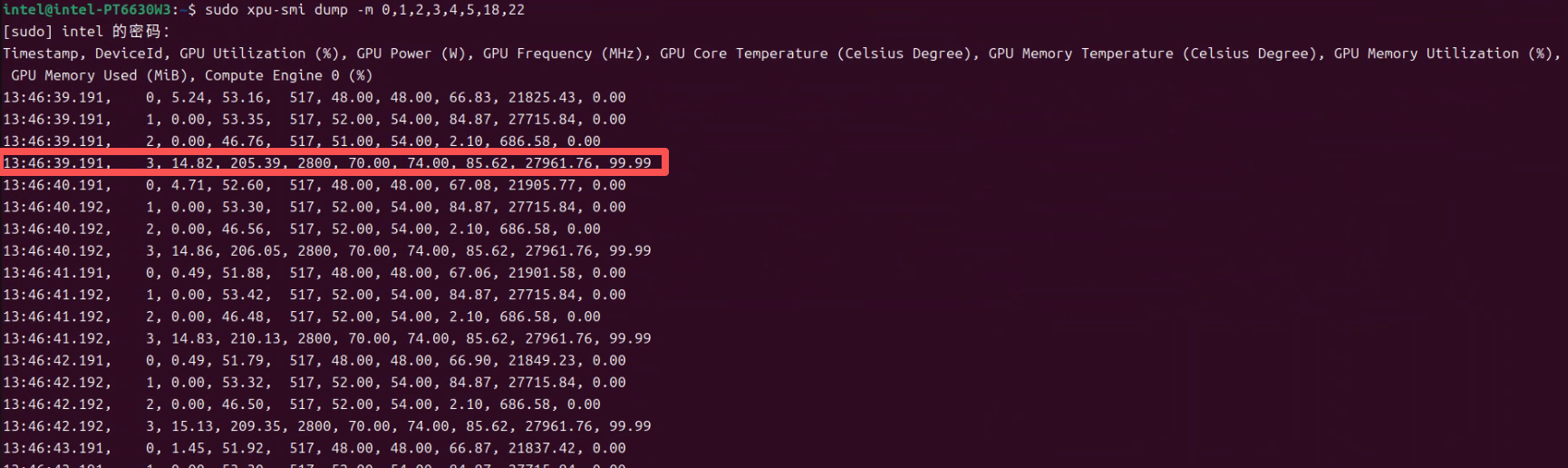
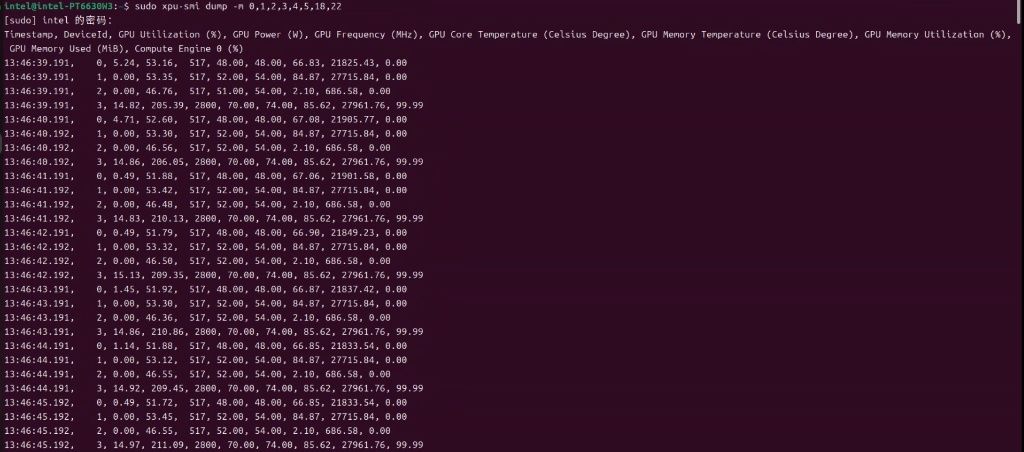
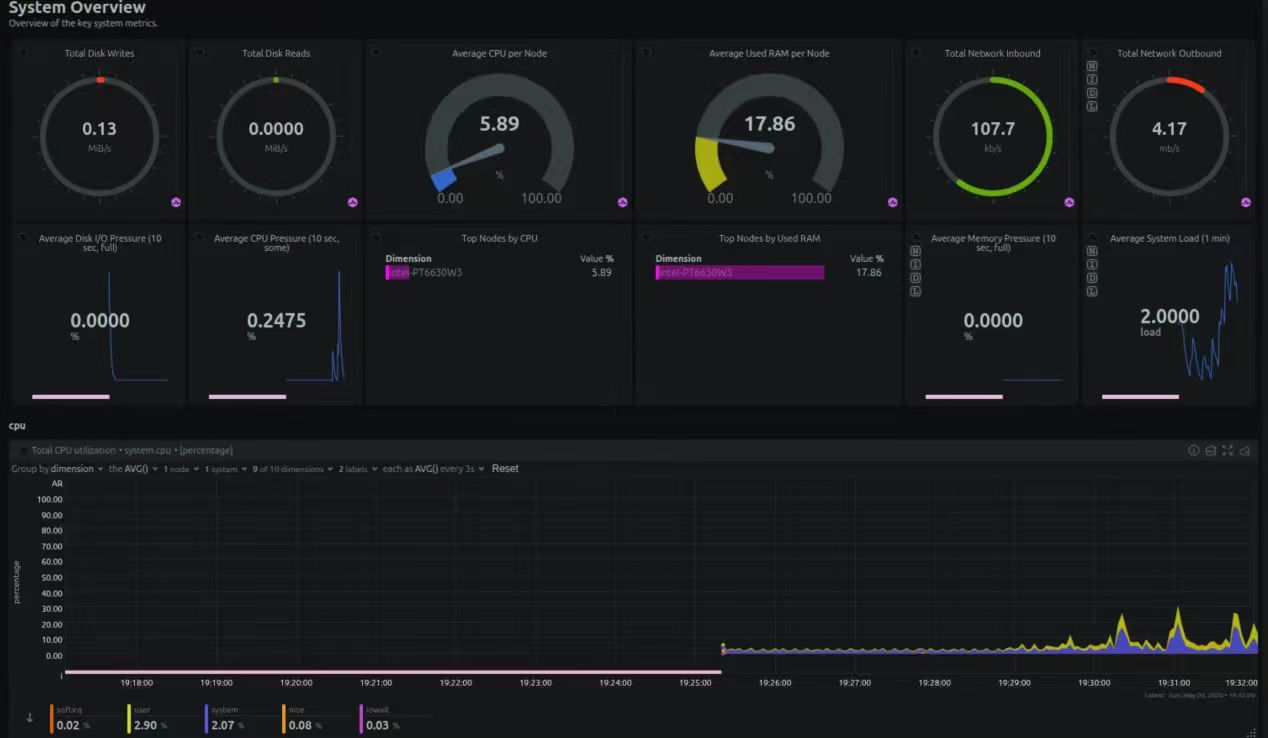
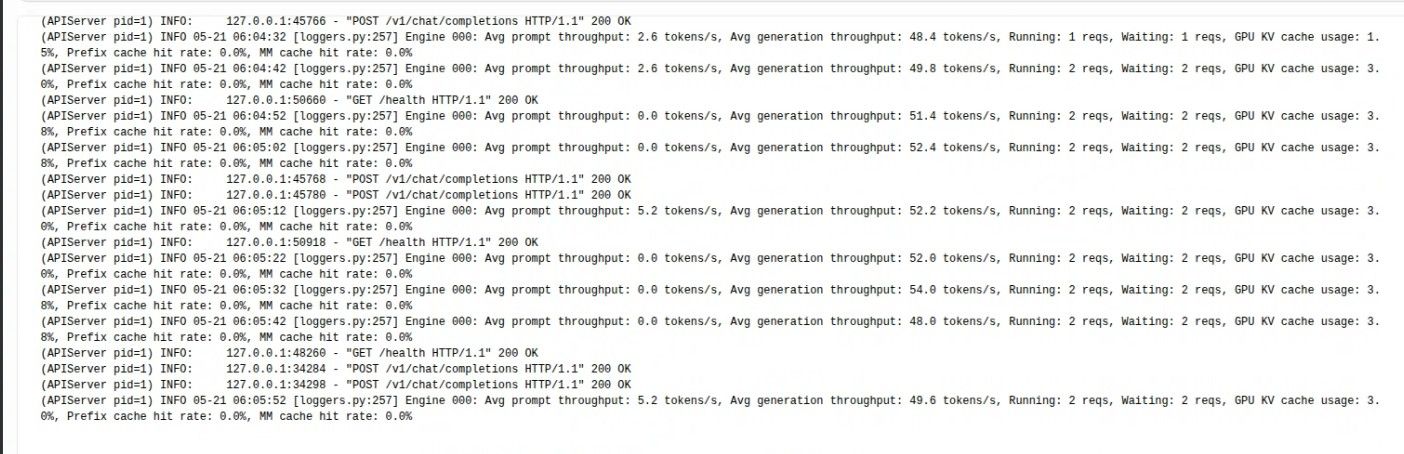 下边白底的这个是docker 的日志截图。
下边白底的这个是docker 的日志截图。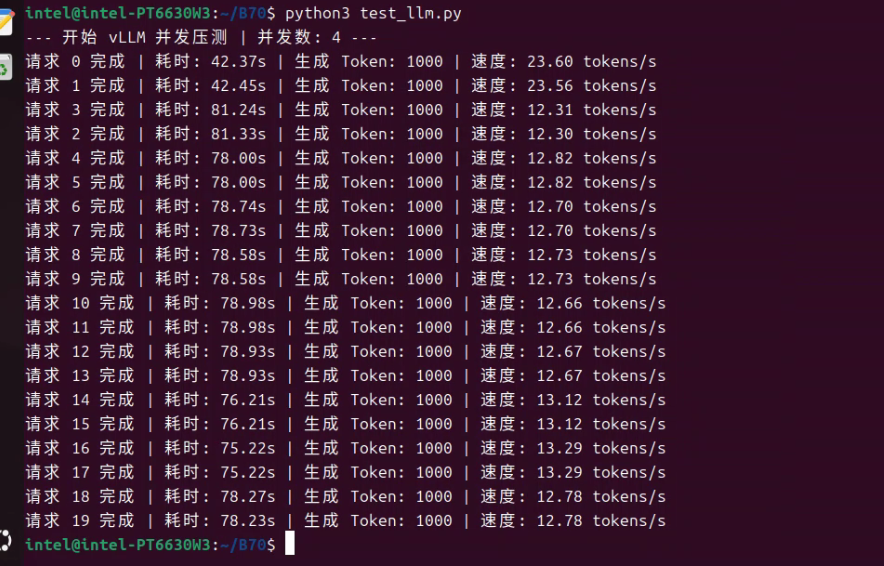 感觉还是相当稳的。 工作室和个人用,够了。 comfyui 我去找个‘公平’的测试方法。或者大家有啥测试方法不?
感觉还是相当稳的。 工作室和个人用,够了。 comfyui 我去找个‘公平’的测试方法。或者大家有啥测试方法不?