
型 类型 等效 / 真实规模 Q4 体积 核心最强场景 ROCm 速度 tok/s
GLM-4.7-FlashX MoE 27B(24 + 档) 16.5GB 代码、Agent、多并发商用 33~42
Qwen3.6-27B 稠密 27B 纯稠密 17GB 中文数理、图文、论文精读 16~22
DeepSeek-V2-Lite 24B 稠密 标准 24B 16.2GB 数学、算法、编程刷题 22~28
Qwen3.5-35B-A3B MoE 24~26B 21.2GB 超长文档、外文翻译、图文 26~31
Mistral-Small 24B 稠密 标准 24B 14.8GB 英文、创意写作、高速对话 28~36
Yi-34B 稠密 等效 25B 19GB 中英双语、海外文献
-
24B左右的模型推荐,其实没必要删帖,本来就是讨论,不讨论怎么分得出对错好坏 -
有没有大神折腾windows r9700的?折腾了几天放弃了, windows下面可以用vulkan, 用35ba3b的性能还可以,用27b性能下降严重。
也安装rocm成功, 但是总有各种各样的小毛病,折腾了一阵,累人。
是直装的,不通过wsl2。 各种修补,发挥不了全力,gpu核心占用只能用到一半左右。
又退回ubuntu了。 -
双AI Pro R9700 32g,Qwen 3.6 27b q4 KM q8 KV Ubuntu24 Hermes agent速度不正常, 用vulkan, mtp可以达到52tok/s, 用rocm 也可以达到45tok/s. 我说的是单卡的情况,双卡不清楚,但是不到20的速度肯定不正常。3.6 27b模型
-
【交作业】Z390 + 7900XTX,跑vulkan + MTP + 128K上下文,opencode速度33~49tps尚可,但是没人说Qwen3.6 27b MTP不支持视觉啊,换35b-vl-mtp就有视觉了,70~80 tps 快的飞起支持视觉 千问3.5以上都支持
-
版主7900XTX 24G 蓝宝石 白金版 折腾日记。折腾过程从入手到成功全过程。部分版主个人开发架构分享。同一个模型,rocm的v cache还是q4,结果智力反而更高一点。
不过日常用rocm的tokens速度是比vulkan慢点。 -
版主7900XTX 24G 蓝宝石 白金版 折腾日记。折腾过程从入手到成功全过程。部分版主个人开发架构分享。用rocm比vulkan聪明一点,7个答案都给出了。计算时间差不多。
rocm也是q5,但是k q5,v q4让我逐步推理:
五个位置 1-5(从左到右),条件:- A 不在两端 → A ∈ {2,3,4}
- B 在 C 左边且不相邻 → B < C,C - B ≥ 2
- D 和 E 相邻 → |D - E| = 1
- E 不在最右 → E ≠ 5
- C 不在最左 → C ≠ 1
关键推导:
C 只能在 3 或 5:
• C=2:B < 2 且 2-B ≥ 2 → B ≤ 0,不可能
• C=4:B ≤ 2,但无论怎么排,D和E都无法相邻
• C=5:B ≤ 3,可行
• C=3:B=1,也可行
经穷举,共有 7 种满足条件的排列:
编号 排列
1 D, E, B, A, C
2 E, D, B, A, C
3 B, D, E, A, C
4 B, E, D, A, C
5 B, A, D, E, C
6 B, A, E, D, C
7 B, A, C, E, D
结论:题目条件不足以确定唯一顺序。 7 种排列都满足全部 5 个条件。
如果你确认题目没有遗漏条件,可以告诉我,我帮你再检查一下是否某个条件我理解有误。
-
版主7900XTX 24G 蓝宝石 白金版 折腾日记。折腾过程从入手到成功全过程。部分版主个人开发架构分享。我的是r9700 ,我用的是Q5 KM
-
版主7900XTX 24G 蓝宝石 白金版 折腾日记。折腾过程从入手到成功全过程。部分版主个人开发架构分享。deepseek 得出 共7组解:
| # | 左→右 | |:-:|:-----:| | 1 | B A C E D | | 2 | B D E A C | | 3 | B E D A C | | 4 | B A D E C | | 5 | B A E D C | | 6 | D E B A C | | 7 | E D B A C |本地Qwen3.6 b27 得出答案:有三种可能
1. B A C E D 2. B A E D C 3. B E D A C答案不全,但是没错
-
R9700到货,AI+Hermes部署llama.cpp+Qwen3.6-27B-Q4_K_M一次成功!上MTP版本, Q4KM ,直接上50t/s , 提速明显
-
r9700 32G速度总算达标了,27B MTP,能上50t/s好的,谢谢。不同框架都试了,llama,ollama,vllm,lm stduio,然后35b,32b,30b,27b ,然后带MTP,然后q4、q5、q6, 说试了20多个模型感觉说少了,哈哈。一直没时间找测试的软件。自己瞎测一个,感觉不好用的就pass了,也没有调过参数。后面才知道参数对速度影响也挺大的。现在基本确定27b mtp版本的,推理能力和响应速度都不错。
-
r9700 32G速度总算达标了,27B MTP,能上50t/sllama不知道有什么标准测试, 都是自己随便跑一下简单测试。如果有标准测试只要时间不是太长,都可以测一下,有个对比。 模型前后换了20多个了,每个都跑很长时间的测试,时间也不允许。
-
r9700 32G速度总算达标了,27B MTP,能上50t/s最大功耗限制在280W, 不限制应该还能更高点。 不过性能损失应该很小。
-c 65536 -ngl 99
--reasoning auto
--spec-type draft-mtp --spec-draft-n-max 3
--flash-attn on
-ub 512 \ -
r9700 32G速度总算达标了,27B MTP,能上50t/sQ4_K_M · 1500 tokens 测试结果
| 指标 | 值 | |-------------|------------------------------------| | 生成速度 | 53.5 tok/s 🚀 | | 总耗时 | 28.0s | | MTP 接受率 | 60.8%(1592 draft / 968 accepted) | | Prompt 处理 | 115.4 tok/s(prompt cache 命中) |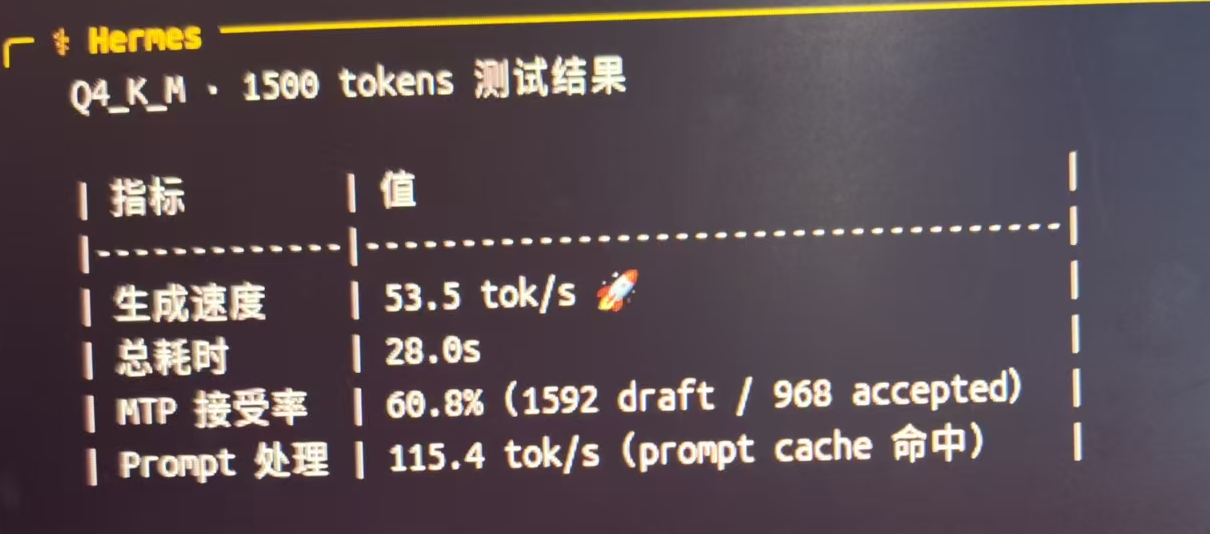
draft=3
-
有没有大神折腾windows r9700的?还没开始折腾,有时间了也想试试
-
换了好几个模型,有些简单问题AI就是很难回答上来@sospda 同样一辆车, 有的人跑赛道是10分钟, 有的人跑同样的赛道是5分钟。 有的人抱怨这个车真是垃圾,太难操控。 有的人精进自己的能力,去熟悉这辆车的操作,把它的性能发挥到最大。 智人跟猴子最大的不同,就是会使用工具,现代人跟智人的不同,就是现代人知道如何更好地去使用工具。
说那么多有啥用,你测试过没?要多久?如果没有试过,可以试试。
同一个问题, 不同的模型反应速度不同, 足以证明在该问题下不同的模型的智能程度。
也说明了,在该问题下,有些模型还有进步空间。
这有什么问题吗?
我发现了这一现象,提出来,不代表我就不去提升我的技能。
这是两码事。
-
R9700 ai pro 32G 跑Qwen3.6 27B q6k 速度实测原来上面用的vulkan在跑,怪不得快一些。
用rocm就又慢回去了。总结:为什么 Vulkan 可能更快?
因素 Vulkan 后端 (e.g., llama.cpp) ROCm 后端 (e.g., vLLM, PyTorch)
启动开销 |较低,轻量级初始化 |较高,需加载完整运行时库
内核优化 |JIT 编译,针对当前模型定制 |预编译通用内核,可能非最优
数据搬运 |直接控制显存,效率高 |多层抽象,可能有额外开销
适用场景 |桌面级 GPU,中小模型,低延迟需求 |数据中心 GPU,大模型,高吞吐需求
生态成熟度 |消费级显卡支持良好 |数据中心 GPU 优化更好
建议如果您的目标是低延迟对话(Chat):Vulkan 后端通常是更好的选择,尤其是对于 7B-13B 模型。 如果您的目标是高吞吐服务(Server):ROCm 后端(如 vLLM)可能在多用户并发场景下表现更好,因为它更好地支持批处理和显存优化。 -
R9700 ai pro 32G 跑Qwen3.6 27B q6k 速度实测Qwen3.6-27B 词元生成速度测试
| 指标 | 值 | |----------|------------------------| | 生成词元 | 559 个(全文自然结束) | | 耗 时 | 13.82 秒 | | 速 度 | 40.44 tok/s | 比上次的 31 tok/s 还快了一些,可能是因为长上下文下 MTP 的并行预测效率更高。用MTP版本,速度更快。

-
R9700 ai pro 32G 跑Qwen3.6 27B q6k 速度实测