
还没赚过钱,所以还没这个烦恼,哈哈
W
weidong
@weidong
-
各位你们油管赚的钱怎么转回内陆账户,听说港卡转内陆账户都有1千美元的监管限制 -
兄弟们,小白也成功安装了我的9700,这里是实践过程.都是血与泪啊..这方面我感觉chatgpt完全不行,谷歌gemini可以,claude也还可以
-
ubuntu26.04下7900xtx跑comfyui工作流阶段总结@terry 试了下快很多,出来效果差不多
-
ubuntu26.04下7900xtx跑comfyui工作流阶段总结把VAE节点换了,现在快很多了,8秒20分钟
-
ubuntu26.04下7900xtx跑comfyui工作流阶段总结@terry 我现在这个应该是VAE解码问题,不知道为啥,40分钟里面有35分钟是在VAE解码的,GPU100%,显存54%,cpu17%,ram53%,VAE解码由fb16换到fp16也一样慢,而且还黑屏,锤哥有碰到过这样的问题吗
-
ubuntu26.04下7900xtx跑comfyui工作流阶段总结今天把数字人也弄好了,原工作流https://www.runninghub.cn/post/2030978580729040897/?inviteCode=3vhsgtbl
为了适配7900xtx的显存,换了LTX-2.3-22B-distilled-1.1-Q3_K_M.gguf模型,clip用CPU来计算
不过感觉有点慢4秒钟,40分钟,还得优化
LTX 2.3 数字人对口型 — 首跑成功总结 软硬件环境
软硬件环境CPU
• 项目: CPU
• 详情: Intel i5-12400F
GPU
• 项目: GPU
• 详情: AMD Radeon RX 7900 XTX(24.6GB VRAM)
内存
• 项目: 内存
• 详情: 45GB DDR4
系统
• 项目: 系统
• 详情: Linux 7.0.0-15-generic
深度学习
• 项目: 深度学习
• 详情: PyTorch 2.12.0 + ROCm 7.2(gfx1100)
ComfyUI
• 项目: ComfyUI
• 详情: v0.20.1 + frontend 1.42.15
启动参数
• 项目: 启动参数
• 详情: --force-upcast-attention --preview-method none
 模型
模型UNet
• 模型: UNet
• 文件: LTX-2.3-22B-distilled-1.1-Q3_K_M.gguf
• 大小: ~14GB
Video VAE
• 模型: Video VAE
• 文件: LTX23_video_vae_bf16.safetensors
• 大小: 1.4GB
Audio VAE
• 模型: Audio VAE
• 文件: LTX23_audio_vae_bf16.safetensors
• 大小: 693MB
CLIP文本
• 模型: CLIP文本
• 文件: gemma_3_12B_it_fp4_mixed.safetensors + ltx-2.3_text_projection_bf16.safetensors
• 大小: 共~7.5GB
人声分离
• 模型: 人声分离
• 文件: MelBandRoformer_fp16.safetensors
• 大小: ~
- CLIP 放在 device=cpu,省 6.8GB VRAM

 工作流 & 参数
工作流 & 参数核心节点链:
LoadImage(4000×6000)
→ ImageScaleByAspectRatio V2(最长边1280, round64) → 896×1280
→ LTXVImgToVideoInplace(strength=0.7)
→ LTXVConcatAVLatent(视频latent + 音频latent)LoadAudio(spk_1778665696.wav, 22kHz单声道)
→ TrimAudioDuration(4.0s)
→ [LazySwitch1way] → MelBandRoFormer(人声分离)
→ LTXVAudioVAEEncode → SetLatentNoiseMask合并后 → SamplerCustomAdvanced(8步) → LTXVSeparateAVLatent
→ VAE解码 → VHS_VideoCombine(30fps, h264, crf=19)
关键参数:Int(98)=duration
• 参数: Int(98)=duration
• 值: 4(当前)
Int(104)=fps
• 参数: Int(104)=fps
• 值: 30
帧数公式
• 参数: 帧数公式
• 值: a×b+1 = 4×30+1 = 121帧
时长
• 参数: 时长
• 值: 4.033秒
分辨率参数: 分辨率
• 值: 896×1280(2:3竖屏)
采样器
• 参数: 采样器
• 值: euler_ancestral_cfg_pp
步数
• 参数: 步数
• 值: 8步
CFG
• 参数: CFG
• 值: 1.0
NAG
• 参数: NAG
• 值: scale=11, alpha=0.25, tau=2.5
Sigmas
• 参数: Sigmas
• 值: 1.0, 0.99375, 0.9875, 0.98125, 0.975, 0.909375, 0.725, 0.421875, 0.0
Prompt
• 参数: Prompt
• 值: "美女对着镜头说话"
VHS pingpong
• 参数: VHS pingpong
- CLIP 放在 device=cpu,省 6.8GB VRAM
-
ubuntu26.04下7900xtx跑comfyui工作流阶段总结@陈鸿 上传不了附件,我这些工作流很基础的,你搭好环境可以下锤哥上传的那个刘悦工作流,跑不通的地方让hermes调试,配合gemini做指导,简单的工作流很快可以跑通的,我现在是用github上的一些做短视频和短剧的项目,修改用本地comfyui生成内容,功能上不合适的可以继续魔改
-
gemini3.5flash先薅点免费羊毛这个是在线api,谷歌提供的免费,有用量限制,轻度用的话基本够了
-
gemini3.5flash先薅点免费羊毛Google AI Studio 免费版 API Key(Free Tier)。对于 Flash 系列模型(包括最新的 gemini-3.5-flash),每天的免费用量限制如下:
每日请求限制:1,500 次 / 天 (Requests Per Day)
每分钟速率限制:15 次 / 分钟 (Requests Per Minute)
每分钟 Token 限制:1,000,000 Token / 分钟 (Tokens Per Minute) -
LTX2.3工作流分享,刘悦大神出品感谢锤哥分享,学习了
-
ubuntu26.04下7900xtx跑comfyui工作流阶段总结我这工作流很奇怪,那些连线总是显示不出来,但点一下那些框框就出来了,不影响跑
-
ubuntu26.04下7900xtx跑comfyui工作流阶段总结走了些弯路,折腾了一段时间wan模型,听锤哥的果断换了ltx,目前flux和ltx2.3还有数字人都跑通了,数字人是下载刘悦的在本地修改后跑通的,效果还不错。
ComfyUI 工作流成果总结
最后更新:2026-05-18
硬件环境 Hardware
组件 规格 CPU Intel Core i5-12400F (12核) 内存 48GB (MemoryMax,) GPU AMD Radeon RX 7900 XTX (24GB VRAM) 系统盘 Kingston NV2 1TB NVMe (279G分区, 39G余量) 外置盘 zyz盘 448GB exfat (94%满, 已挂载) ROCm ROCm 7.2 PyTorch 2.12.0+rocm7.2 软件环境 Software
组件 版本/配置 OS Linux 7.0.0-15-generic ComfyUI v0.20.1+ (API + 浏览器) ComfyUI 端口 8188 (--listen 0.0.0.0) 启动参数 --disable-async-offload(不加--lowvram)环境变量 TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=0
工作流总览
共 5 个工作流,全部存在
/root/ComfyUI/workflows_hermes/1. Flux1.dev-fp8 文生图
文件:
flux1_t2i.json模型与位置:
模型 类型 大小 位置 flux1-dev-fp8.safetensors checkpoint (模型+CLIP+VAE) 17GB /root/ComfyUI/models/checkpoints/参数设置:
- 分辨率: 1024×1024
- 采样器: euler
- 调度器: normal
- 步数: 20
- CFG: 3.5
- 去噪: 1.0
节点结构: CheckpointLoaderSimple → CLIPTextEncode×2 + EmptyLatentImage → KSampler → VAEDecode → SaveImage
2. Flux2 Klein 4B 文生图
文件:
flux2_t2i.json模型与位置:
模型 类型 大小 位置 flux-2-klein-4b.safetensors U-Net (diffusion model) 7.3GB /root/ComfyUI/models/diffusion_models/qwen_3_4b.safetensors CLIP/T5文本编码器 7.5GB /root/ComfyUI/models/text_encoders/flux2-vae.safetensors VAE解码器 321MB /root/ComfyUI/models/vae/参数设置:
- 分辨率: 1024×1024
- 采样器: euler
- 调度器: simple
- 步数: 20
- CFG: 3.5
- 去噪: 1.0
节点结构: UNETLoader + CLIPLoader(type=flux2) + VAELoader → CLIPTextEncode×2 + EmptyLatentImage → KSampler → VAEDecode → SaveImage
注意: 文本编码器必须用
qwen_3_4b.safetensors+ CLIPLoader(type="flux2")。不要用DualCLIPLoader或UMT5,那会报错。
3. LTX 2.3 文生视频 Text-to-Video
文件:
ltx23_t2v.json模型与位置:
模型 类型 大小 位置 ltx-2.3-22b-distilled-1.1-Q3_K_M.gguf U-Net GGUF 9.9GB /root/ComfyUI/models/unet/本地gemma-3-12b-it-Q4_K_M.gguf CLIP文本编码器 GGUF 6.8GB /root/ComfyUI/models/clip/本地ltx-2.3_text_projection_bf16.safetensors 文本投影 75B /root/ComfyUI/models/clip/(symlink)LTX23_video_vae_bf16.safetensors VAE 1.4GB /root/ComfyUI/models/vae/参数设置:
- 分辨率: 544×960
- 帧数: 49 (约2秒)
- 帧率: 24fps
- 采样器: euler
- 步数: 8
- CFG: 1.0
- max_shift: 2.05, base_shift: 0.95
- VAE分块: 4×4 tiles, overlap=2
- 输出: MP4 H.264
节点结构: UnetLoaderGGUF + DualCLIPLoaderGGUF(type=ltxv) + VAELoader → EmptyLTXVLatentVideo → CLIPTextEncode×2 → LTXVConditioning → LTXVScheduler → CFGGuider + RandomNoise + KSamplerSelect → SamplerCustomAdvanced → LTXVCropGuides → LTXVTiledVAEDecode → VHS_VideoCombine
4. LTX 2.3 图生视频 Image-to-Video
文件:
ltx23_i2v.json模型与位置 (同T2V基础上增加):
模型 类型 大小 位置 同上 + ltx-2-19b-lora-camera-control-static.safetensors LoRA 2.1GB /root/ComfyUI/models/loras/本地参数设置:
- 分辨率: 544×960
- 帧数: 49 (约2秒)
- 帧率: 24fps
- 采样器: euler, 8步
- CFG: 1.0
- 静态相机LoRA: strength=0.8
- Inplace注入: strength=1.0
- 输入:
your_photo.png(自动resize到544×960)
节点结构: UnetLoaderGGUF + DualCLIPLoaderGGUF → LoraLoaderModelOnly + LoadImage → ImageResizeKJv2 + EmptyLTXVLatentVideo → LTXVImgToVideoInplace → (同T2V采样→解码→合成)
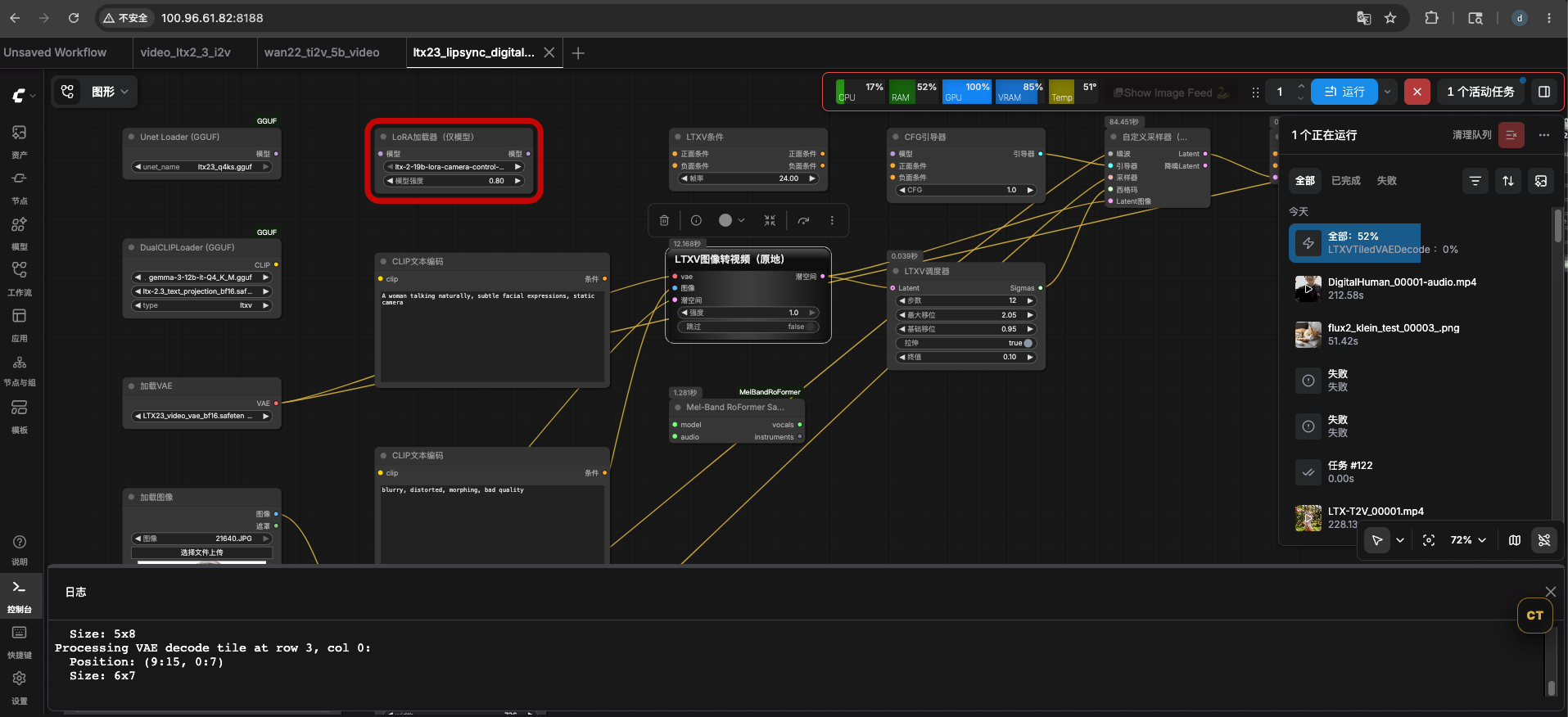
5. LTX 2.3 数字人 LipSync (图+音频→视频)
文件:
ltx23_lipsync_digitalhuman.json模型与位置 (同I2V基础上增加):
模型 类型 大小 位置 ltx23_q4ks.gguf (LTX-2.3-distilled-Q4_K_S.gguf) U-Net GGUF 16GB /root/ComfyUI/models/unet/软链→zyz盘MelBandRoformer_fp16.safetensors 音频人声分离 436MB /root/ComfyUI/models/diffusion_models/软链→MelBandRoformer/其他模型同I2V 参数设置:
- 分辨率: 544×960
- 帧数: 73 (约3秒)
- 帧率: 24fps
- 采样器: euler, 12步
- CFG: 1.0
- 静态相机LoRA: strength=0.8
- 输入:
your_photo.png+your_audio.wav - 音频处理: MelBandRoFormer 分离人声 → VHS_VideoCombine.audio 直接合并
- 音频时长裁剪: 3.0秒 (匹配73帧@24fps)
重要: 音频不走latent注入(LTXVAudioVAEEncode输出NestedTensor不兼容GGUF),而是走MelBandRoFormer分离后直拼。VHS_VideoCombine的
pingpong为必填参数,缺了会导致静默失败。
VRAM占用估算
工作流 模型 总VRAM 可用 Flux1.dev-fp8 17GB checkpoint ~17GB 余~7GBFlux2 Klein 4B 7.3G+7.5G+321M ~15GB 余~9GBLTX T2V (Q3_K_M) 9.9G+6.8G ~17GB 余~7GBLTX I2V (Q3_K_M) 9.9G+6.8G+2.1G ~19GB 余~5GBLTX 数字人 (Q4_K_S) 16G+6.8G+2.1G+436M ~23GB  ️ 余~1GB
️ 余~1GBQ4_K_S 数字人峰值 ~23GB 非常紧,建议先用 Q3_K_M 测试再换 Q4_K_S。
最大视频时长 (480p 720×480)
将latent从544×960改为720×480,latent缩小~35%:
- Q3_K_M: ~12秒 (290帧)
- Q4_K_S: ~8秒 (193帧)
已知问题
- 动作迁移 (ICLoRA): 需要原生FP8模型22GB,24GB VRAM装不下。ICLoRA不兼容GGUF路径,当前无法实现完整的动作迁移。
- 音频latent注入: LTXVAudioVAEEncode输出NestedTensor,与GGUF U-Net不兼容。已绕过走MeldBandRoFormer直拼。
- VHS_VideoCombine:
pingpong必填,缺了静默失败。LTXVSeparateAVLatent无音频时访问latents[1]会IndexError——I2V应跳过此节点。 - Flux2文本编码器: 必须用
qwen_3_4b.safetensors+ CLIPLoader(type="flux2")。不能用DualCLIPLoader。 - zyz盘依赖: 数字人工作流的Q4_K_S模型在zyz盘软链,拔盘后工作流不可用。Q3_K_M版在本地可独立运行。
-
软路由及内网穿透 - 请教各位老大我最近也在折腾网络,tailscale很简单但网络延时高,我在考虑用软路由搭个vpn服务器,然后每个电脑安装个客户端组网
-
请教:uburntu26.04+7900xtx,comfyui跑不通@williamlouis 关键我也没用过ubuntu24.04,哈哈.目前新的系统感觉用着还是挺好的
-
请教:uburntu26.04+7900xtx,comfyui跑不通@yongjun-liu 干脆都升级到最新版吧,省心,而且rocm7.2的优化挺多的,据说速度也快一些
-
请教:uburntu26.04+7900xtx,comfyui跑不通@terry 好的,谢谢锤总建议
-
请教:uburntu26.04+7900xtx,comfyui跑不通@yongjun-liu 要哪方面文件呢,我配置的时候忘记切图这些了。我的整个顺序是这样的,装完ubuntu26.04后就安装hermes,hermes跑起来后就全都通过hermes来完成所有的配置了。安装pytorch和rocm还有comfyui以及下载模型全都是用hermes去完成的,Wan2.2-TI2V-5B GGUF Q8、LTXV 13B目前用的是这两个模型都没有任何问题。
-
VoxCPM2 語音克隆 TTS 生成音色不穩定我觉得indextts挺好用的,在苹果下生成速度还过得去
-
经验分享,7900xtx折腾历程看了锤哥的视频,果断把5060ti16G卖了,贴了几百块换了7900xtx,折腾comfyui,安装了最新的ubuntu26.04,安装上hermes,就让它自己安装、调试comfyui,开始不太顺利,rocm用的是6.X,老是出现内存崩溃,allocator latency碎片化,也各种查ai,我是每个问题问gemini和chatgpt、deepseek三个ai,这次感觉GPT最不靠谱,它们一开始都认为我软件太新,GPT还建议我用回24的ubuntu,最后还是gemini建议试试rocm7.X,然后把pytorch也升级到2.11,采用轻量小模型,没想到很顺利搞定了,生图生视频都稳定没问题。下一步计划提升下质量
-
请教:uburntu26.04+7900xtx,comfyui跑不通没问过豆包,gemini这次比较给力,chatgpt、deepseek三个我每个问题都问三遍,最后还是gemini帮了大忙。问题彻底解决,听锤哥的,买了个7900xtx挑战难度,还好都搞通了,ubuntu26.04+pytorch2.11+rocm7.2,跑comfyui的FLUX klein-4b和LTX-video 2b-distilled是完全没问题了,下一步看模型上有没有兼顾质量的再提升提升