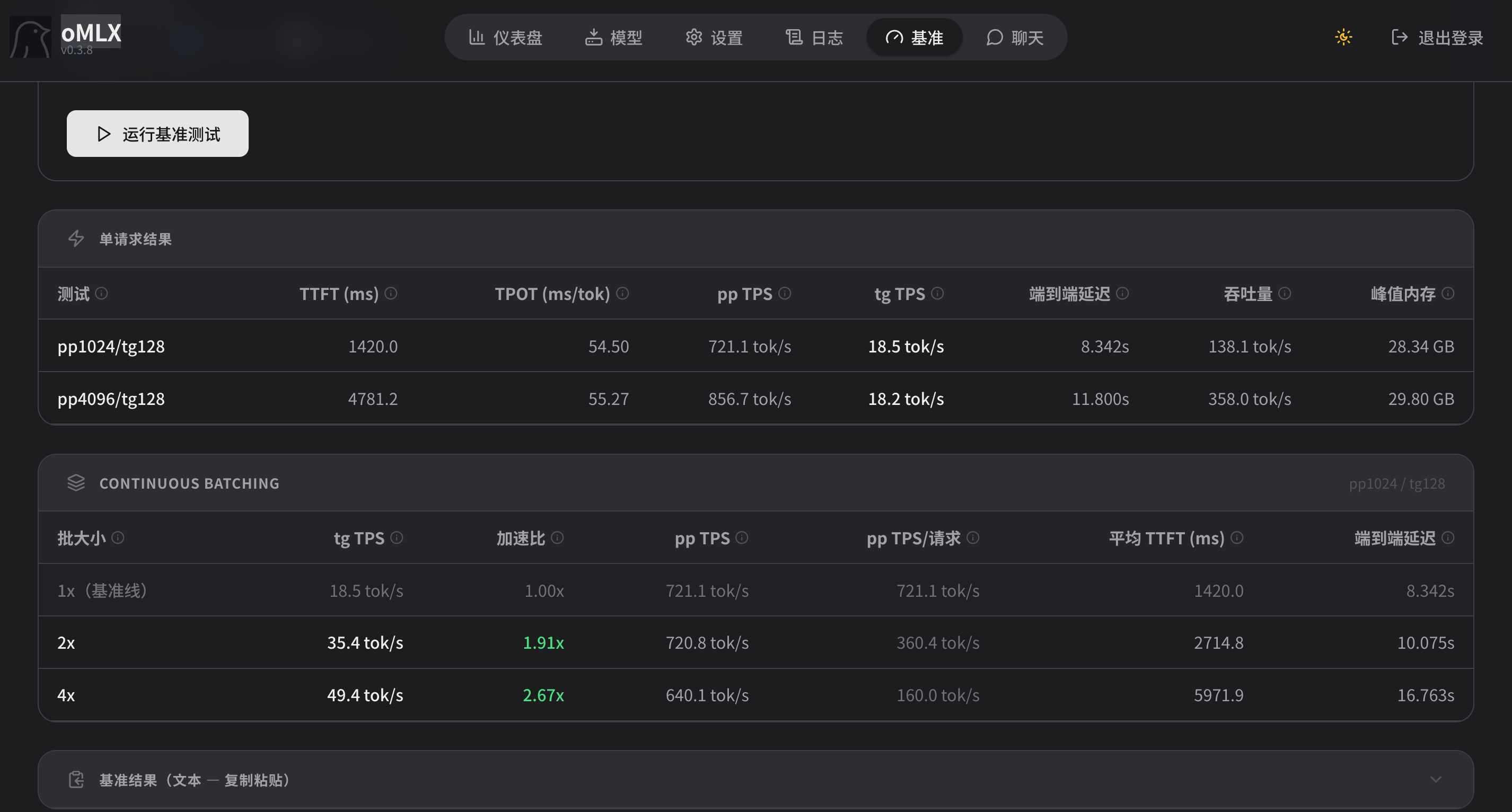
M5 Max 跑 Qwen 122b a10b Q4 的话, 如果内存够, 不大可能只有 20-25t/s.
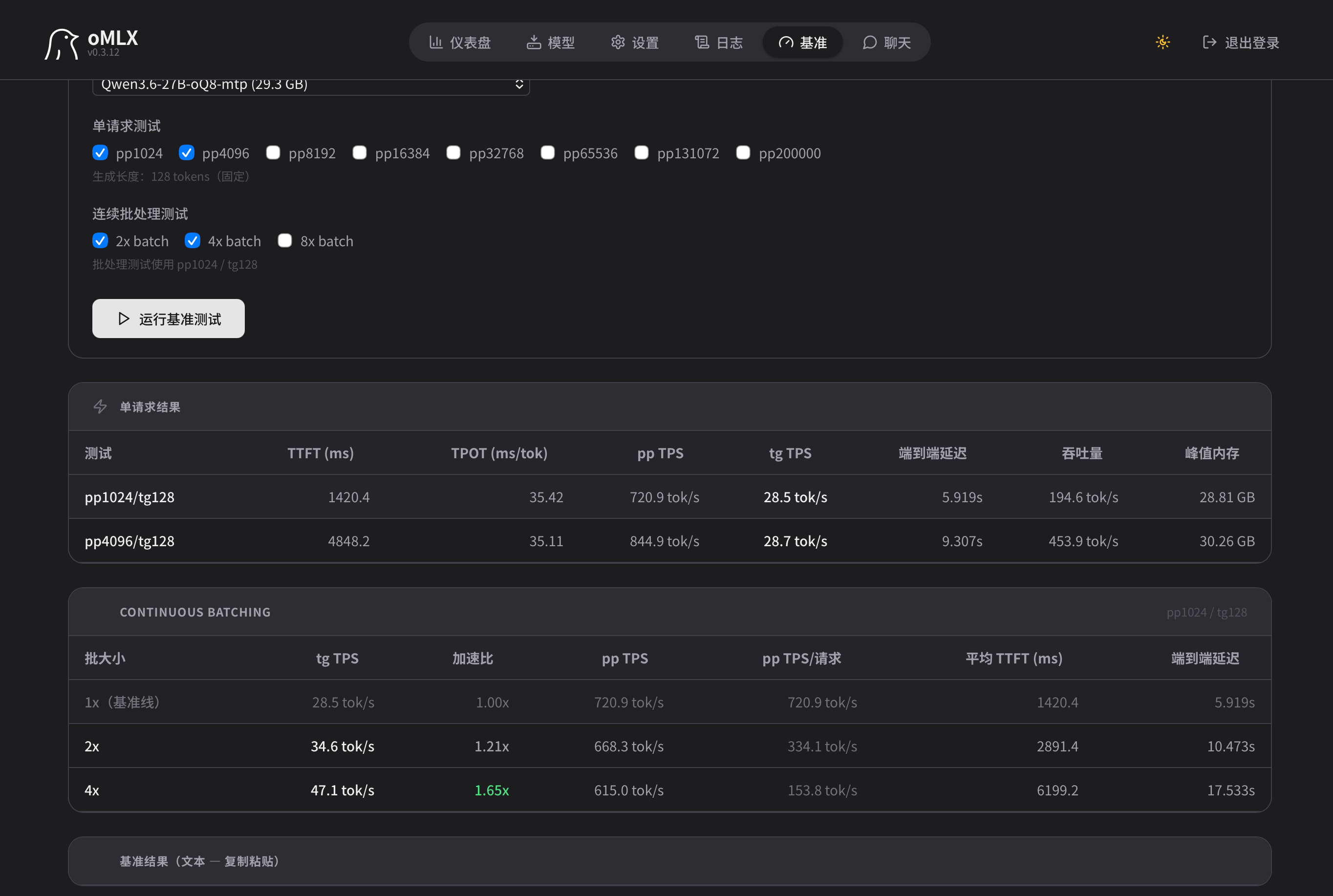
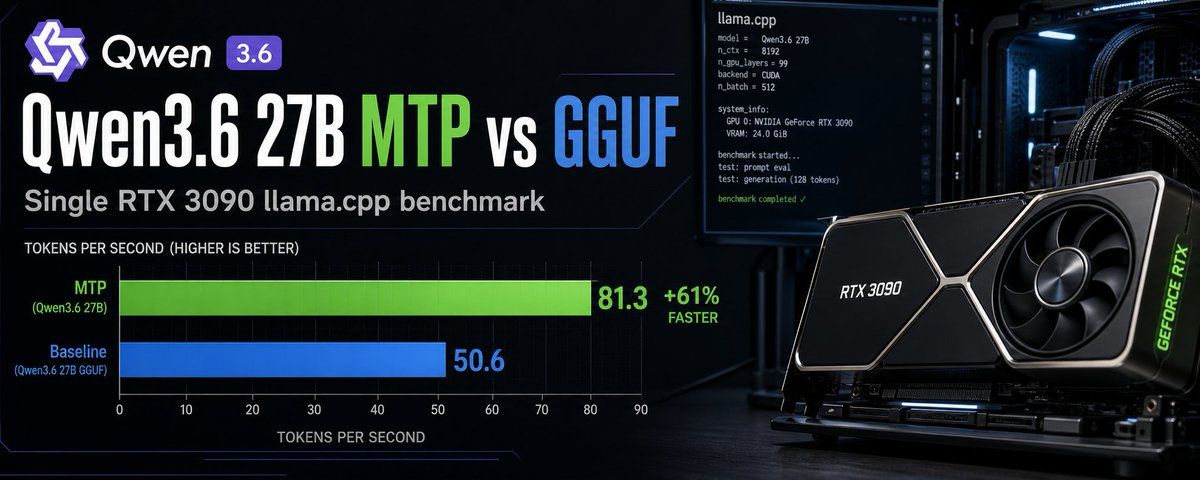
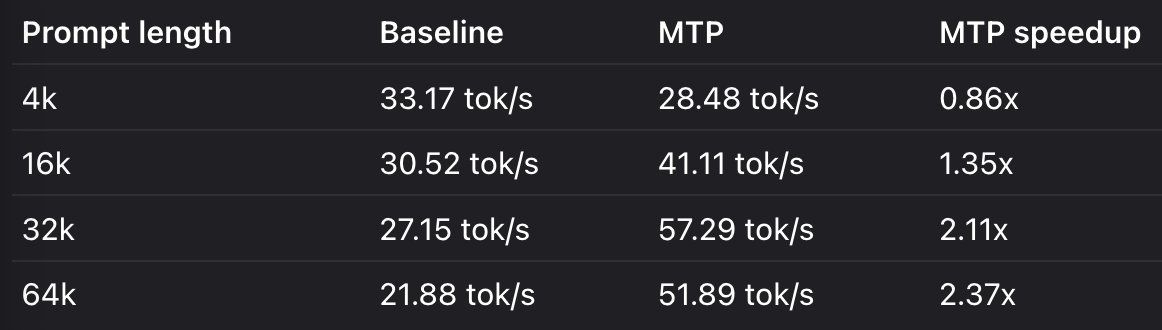
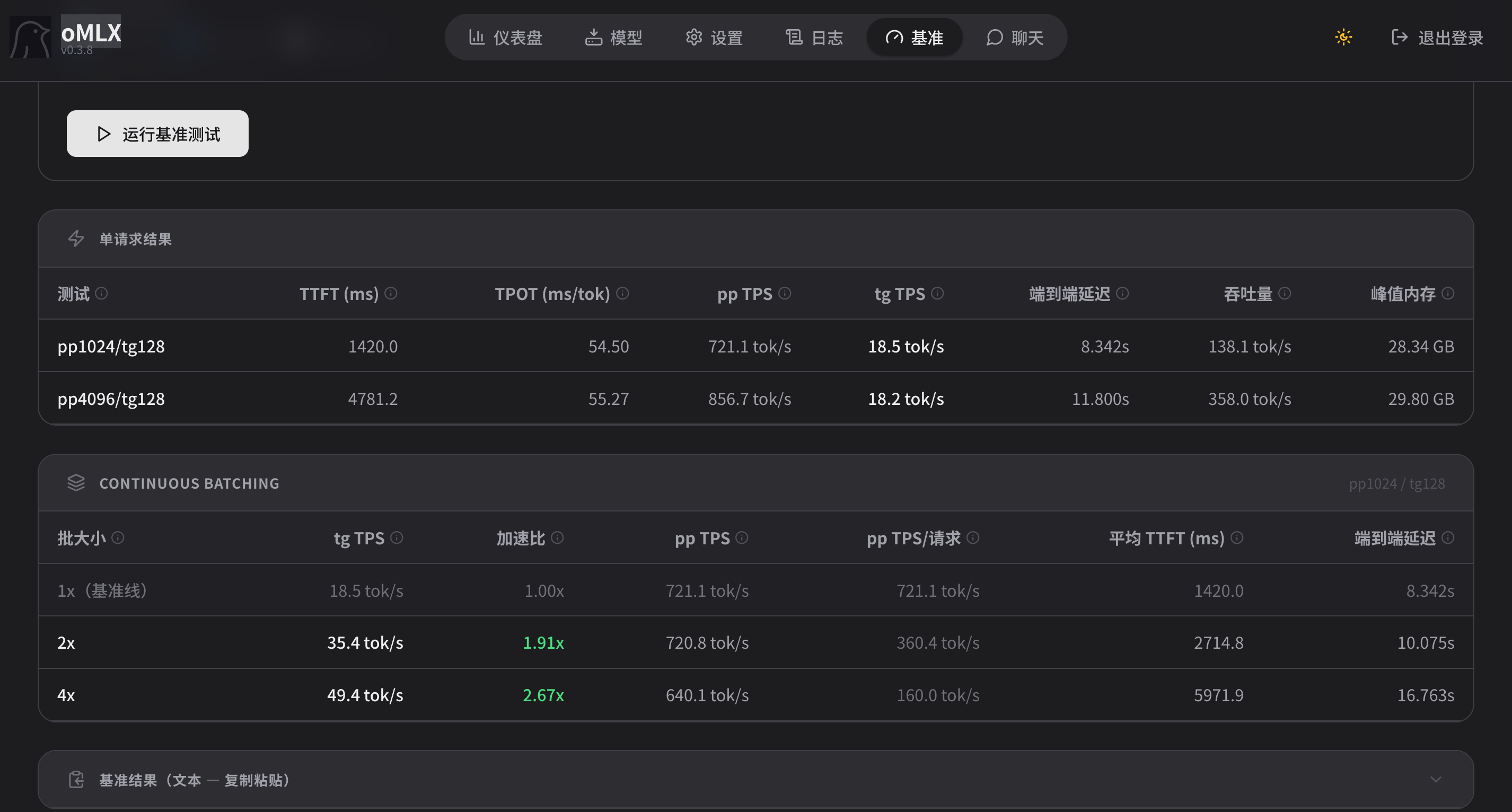
我的M5 pro 跑 Qwen 27b 稠密加上MTP之后, 还能跑到20以上, 64k上下文时候掉到 17多.
按这个速度推理, M5 max 是我显存带宽的两倍, 它能到 40t/s 以上.
122b A10b 肯定比27b 稠密要快, 应该能跑到 60t/s以上, 我估计.
另外, 122A10 的智力应该不如 27b 稠密, 只是知识面更宽.
请教一下Tony的Qwen27B MTP用的哪个版本的模型?我下了oQ8-mtp,omlx经常退出,看日志好像是mtp的bug,求推荐稳定运行的模型版本,谢谢!