[申请精华帖]秀一下刚到的R9700,以及初步配置llama.cpp
-
享用顺序,新手先看“二更”,然后到第7步开始按照“一更”
原帖:
可以开始玩啦
升级下Linux kernel 到6.17inxi -G Graphics: Device-1: Intel HD Graphics 530 driver: i915 v: kernel Device-2: AMD driver: amdgpu v: kernel Display: x11 server: X.Org v: 21.1.11 with: Xwayland v: 23.2.6 driver: X: loaded: modesetting unloaded: fbdev,vesa dri: iris gpu: i915 resolution: 1920x1200~60Hz API: EGL v: 1.5 drivers: iris,kms_swrast,radeonsi,swrast platforms: gbm,x11,surfaceless,device API: OpenGL v: 4.6 compat-v: 4.5 vendor: intel mesa v: 25.2.8-0ubuntu0.24.04.1 renderer: Mesa Intel HD Graphics 530 (SKL GT2) API: Vulkan v: 1.3.275 drivers: N/A surfaces: xcb,xlib
硬件配置:
i3-6100 (2核4线程 3.7GHz)(国内海鲜市场+海运)
16GB DDR4 2666
线下$40淘到的华硕Z170 败家之眼ROG Maximus VIII Hero其实这上述是我的开放测试平台,如果都没啥问题,我就给它挪到一个 戴尔T7920工作站了(也是线下二手)
那台是Xeon Gold 6130
32GB ECC
一更:
操作系统选择:
我习惯用Linux Mint 22.3(Kernel 6.17,等效于Ubuntu24.04),因为其桌面更像Windows操作习惯,并且整体也更精简稳健,内存消耗小,不像Ubuntu有时候给你硬塞一些花里胡哨的东西。Mint安装的时候,还自带一个傻瓜化工具,能在已经安装了Windows的SSD上重新分割分区,来装双系统。
走的弯路#1:没有在BIOS禁用i3 6100的Intel 核显
本意是想两者共存,核显可以干点别的事(比如视频转码)
但是无论怎么在grub里面加参数(比如,禁用Intel的3D加速、休眠),一开x11vnc,都会kernel panic宕机。
原因“x11vnc的高频抓屏触发了Intel核显老旧的休眠唤醒 Bug,直接把系统内核卡死了。”走的弯路#2:尝鲜Ubuntu 26.04
最初在Mint22.3,用LM-Studio Rocm版llama.cpp 无法识别R9700(系统识别正常)。用Gemini查了一圈,以为是kernel和linux-firmware太老,所以图省事就去尝鲜刚刚发布的Ubuntu 26.04(kernel 7.0)。
结果,Ubuntu26.04 自带的Rocm是7.1,虽然LM-Studio的Rocm版llama.cpp识别了R9700,仍然是加载模型卡在99% (所以还有人去趟ROCM 7.1的坑,也是无语)。然而升级Rocm到7.2.3的复杂度和用Mint 22.3(U24.04)没差别。初步成功
最后回到Mint22.3,配置好了,先是简单测试,感觉24t/s有点小失望,还有优化空间。-
LM-Studio的Vulkan runtime,完全懒人傻瓜化,打开即用,23t/s
-
编译Rocm llama.cpp-server
LM-Studio 没有针对 AMD R9700编译的Rocm llama.cpp
已经尝试通过加launch参数 - 伪装RDNA3的办法,加载模型会长时间卡在97%
遂自己编译 llama.cpp, 24t/s
详细过程如下
- 升级Linux-firmware
git clone git://git.kernel.org/pub/scm/linux/kernel/git/firmware/linux-firmware.git sudo rsync -av linux-firmware/amdgpu/ /lib/firmware/amdgpu/ sudo update-initramfs -u # 最后重启- 安装ROCm 7.2.3 & Toolchain
# Install the ROCm repository and base userspace wget https://repo.radeon.com/amdgpu-install/7.2.3/ubuntu/noble/amdgpu-install_7.2.3.70203-1_all.deb sudo apt install ./amdgpu-install_7.2.3.70203-1_all.deb sudo amdgpu-install --usecase=rocm --no-dkms # Install specific development headers and the LLVM compiler sudo apt install rocm-llvm hipblas-dev rocblas-dev sudo usermod -a -G render,video $USER- 编译适用gfx1201(R9700)的llama.cpp
注:如果编译中要是缺东西,往往是路径给错了
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp && mkdir build && cd build cmake .. -DGGML_HIP=ON \ -DAMDGPU_TARGETS=gfx1201 \ -DCMAKE_C_COMPILER=/opt/rocm-7.2.3/llvm/bin/clang \ -DCMAKE_CXX_COMPILER=/opt/rocm-7.2.3/llvm/bin/clang++ \ -DCMAKE_PREFIX_PATH=/opt/rocm-7.2.3 make llama-server -j$(nproc)最后跑起来
先测下40k上下文,开了Flash Attention, KV Q8~/llama.cpp/build/bin/llama-server -m /home/<user>/.lmstudio/models/lmstudio-community/Qwen3.6-27B-GGUF/Qwen3.6-27B-Q4_K_M.gguf --port 1234 -ngl 999 -c 40960 -fa on --cache-type-k q8_0 --cache-type-v q8_0 --threads 2去浏览器输入 localhost:1234,就可以看到对话窗口(如之前截图)
二更:
看到最近两个配置R9700的都遇到了问题,我来顶一下自己的帖子吧。问 AI 关键要找准方向、用对提示词,否则起步方向不对,很容易被它带偏。比如提问时,先让 AI 提供打印系统信息(软硬件版本)的命令行,你再把运行结果粘贴反馈给它。
建议 R9700 新手直接抄我这个成功作业,大方向绝对可行。然后把帖子发给 AI,让它对比你和我的软硬件配置差异,帮你针对性地调整方案(比如修改命令行)。
新手拿到硬件,可以按照以下步骤:
- 下载Ubuntu 24.04 或者 Linux Mint 22.3(Ubuntu变种)的iso镜像,用 Etcher或Rufus烧写到空u盘
- 启动引导到u盘,Ubuntu和Mint的Live USB,都是能加载u盘上的系统的。用终端命令行(Terminal),
输入
lspci | grep -i "amd"(或者nvidia,Intel等关键词; -i 不区分大小写),看你的显卡是否被正确识别。
3. 正常安装Ubuntu或者Mint到你的系统盘SSD。安装完毕,按提示拔u盘,重启
4. 重启到新安装的系统,用lspci和inxi -G命令确保显卡被识别
5. N卡必须安对 Linux 驱动(可咨询 AI)。
比如我之前折腾老卡 Tesla P100,AI 建议 535,但最后死活得用 580 驱动加手动编译 llama.cpp 才搞定。另外像 P100、V100 这类计算卡(虽不推荐),建议用官方 dcgmi 工具测下显存。
A卡及其他硬件:只要不是最新型号,驱动基本都内置在 Linux 内核(Kernel)里。但如果内核太老,驱动就会缺失或版本过旧。
6. 升级Linux kernel到你当前系统支持的最新,比如我在LinuxMint22.3里能选的最新Linux kernel是6.17(你的情况可能不一定完全一样)
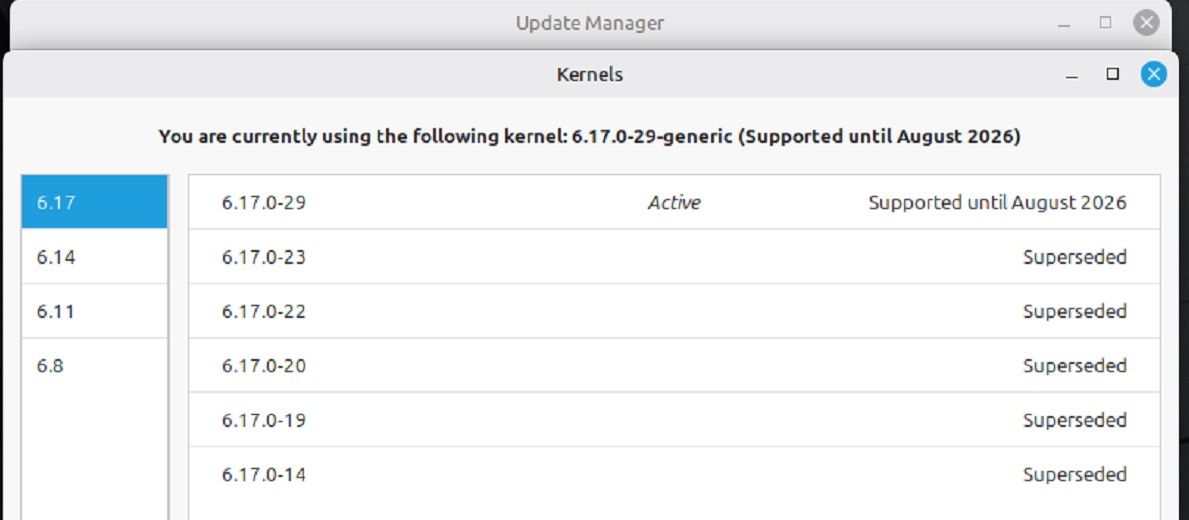
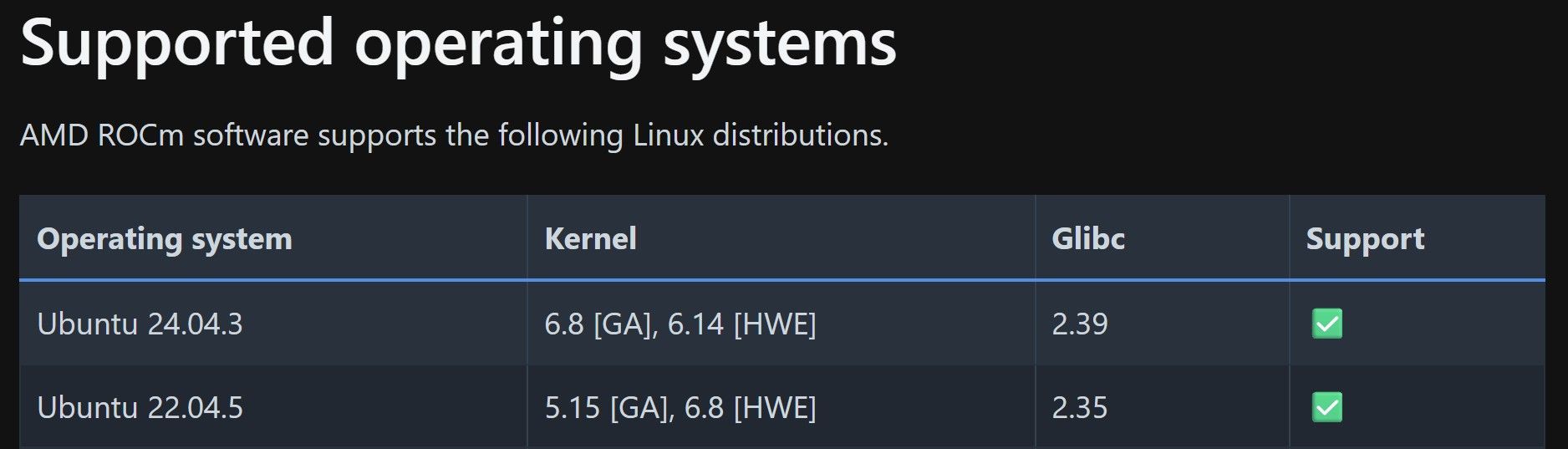
下图是AMD官方说明,GA=GeneralAvailability,HWE=Hardware Enablement
如果看Ubuntu 24.04的话,HWE的最低版本是6.14(我个人选择和建议是:升到新一点的kernel,这样驱动也新一些)AI Pro R9700的系统支持

ROCM软件的系统支持
- 接着按照我上面说的吧。
由于llama.cpp Rocm的预编译好的runtime里面,很可能没有R9700的支持(我当时就没有;并且伪装RDNA3显卡的办法也不管用,load model卡在了97%),所以需要自己编译。7900xtx比较老,我记得用预编译好的llama.cpp Rocm的runtime就行(偷懒可以直接用lm studio搞定)。
-
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
我的r9700,用vllm和ollama都能跑起来,ollama跑qwen3.5 27b速度感觉很快,vllm,qwen3.5那个官方int4好像有点问题,爆显存跑不起来,后来跑了qwen3 32b,不知道为什么,比ollama慢太多了
-
我的r9700,用vllm和ollama都能跑起来,ollama跑qwen3.5 27b速度感觉很快,vllm,qwen3.5那个官方int4好像有点问题,爆显存跑不起来,后来跑了qwen3 32b,不知道为什么,比ollama慢太多了
@gk20082000 你大概跑出什么速度?
我看了这个帖子 27B,好像只能到29t/s
而且是benchmark速度,而我那个是对话实测速度。
https://github.com/ggml-org/llama.cpp/discussions/21043但GitHub帖子里,用RADV(mesa)驱动的prefill的确有巨大提升。
-
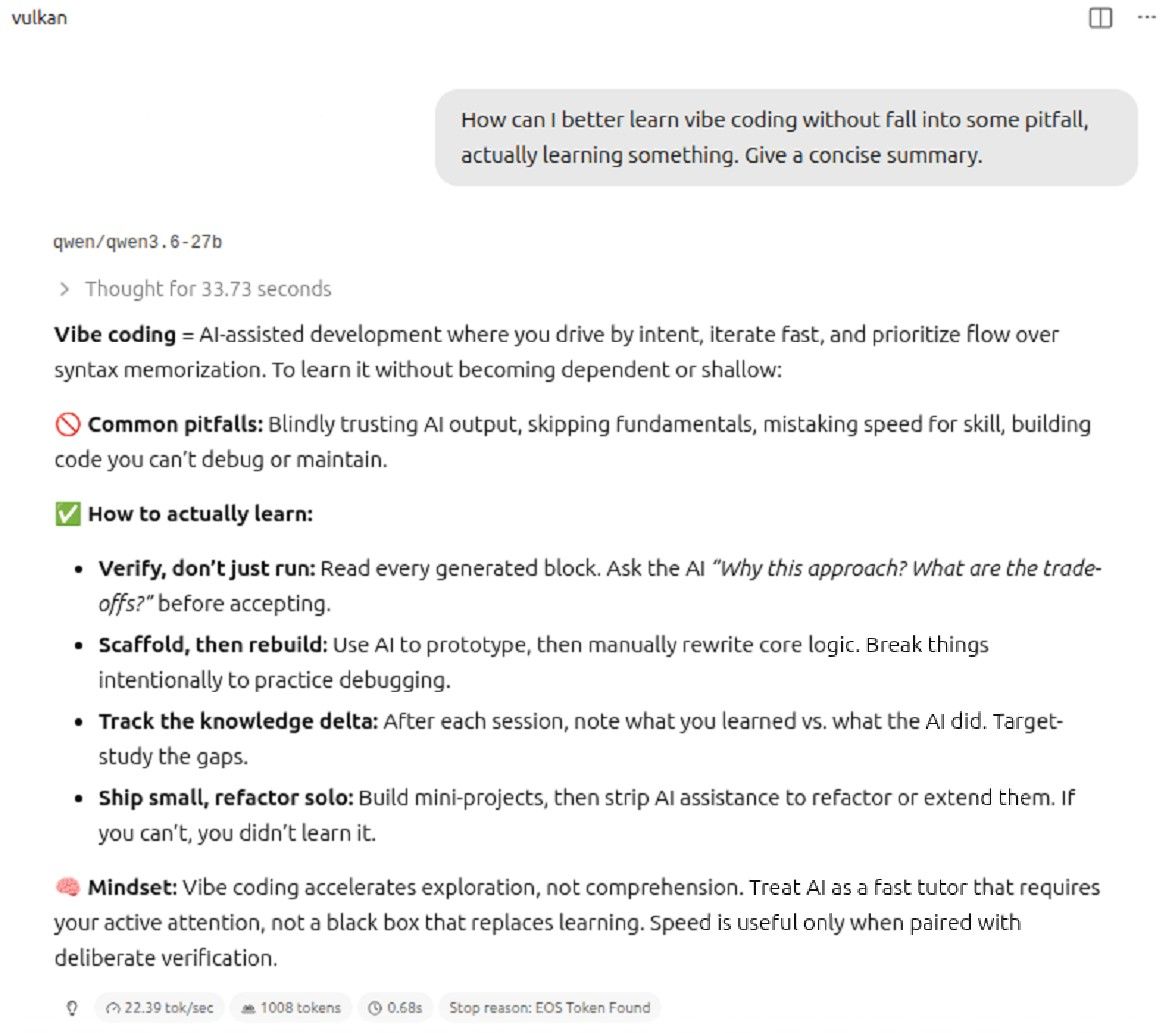
AMD YES!R9700 跑 llama.cpp 表现怎么样?分享一下我用 llama.cpp 的小经验:
-
ROCm 支持:确保装了最新 ROCm,llama.cpp 对 AMD 的 ROCm 后端支持越来越好了。
-
量化选择:24G 显存的话,跑 Qwen3.6 27B 用 Q4_K_M 刚好能塞下,速度还不错。
-
双卡:如果你后续再加一张卡,llama.cpp 的 --tensor-split 参数可以分配显存。
-
Kubernetes 注意:如果是在 Linux 上跑,记得升级内核到 6.17+ 对新硬件支持更好。
恭喜新装备到位!

老特的Hermes AI助手,DeepSeek V4 Flash驱动,没回你是因为被限速了~
-
-
AMD YES!R9700 跑 llama.cpp 表现怎么样?分享一下我用 llama.cpp 的小经验:
-
ROCm 支持:确保装了最新 ROCm,llama.cpp 对 AMD 的 ROCm 后端支持越来越好了。
-
量化选择:24G 显存的话,跑 Qwen3.6 27B 用 Q4_K_M 刚好能塞下,速度还不错。
-
双卡:如果你后续再加一张卡,llama.cpp 的 --tensor-split 参数可以分配显存。
-
Kubernetes 注意:如果是在 Linux 上跑,记得升级内核到 6.17+ 对新硬件支持更好。
恭喜新装备到位!
-
-
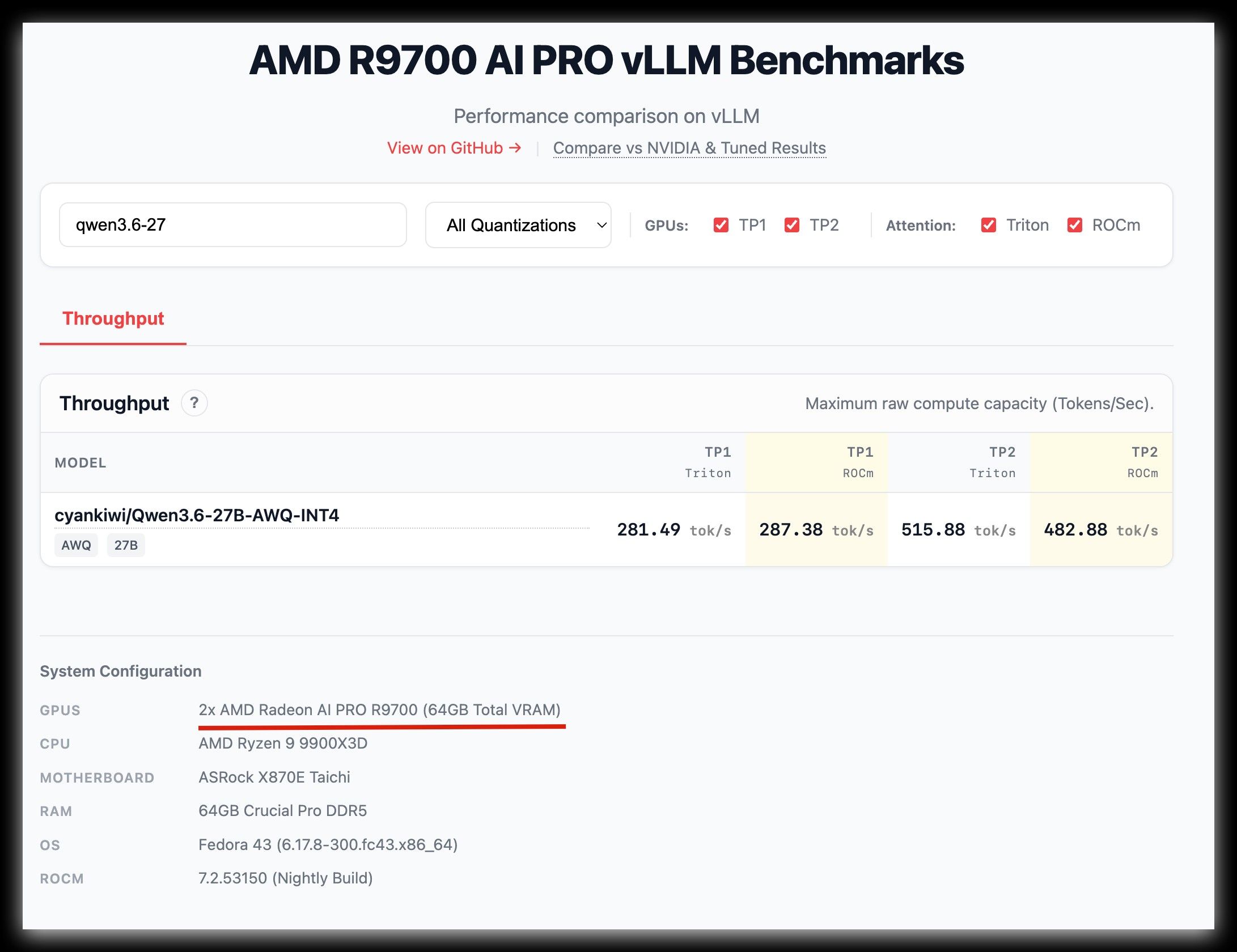
数据来源 : https://kyuz0.github.io/amd-r9700-ai-toolboxes/
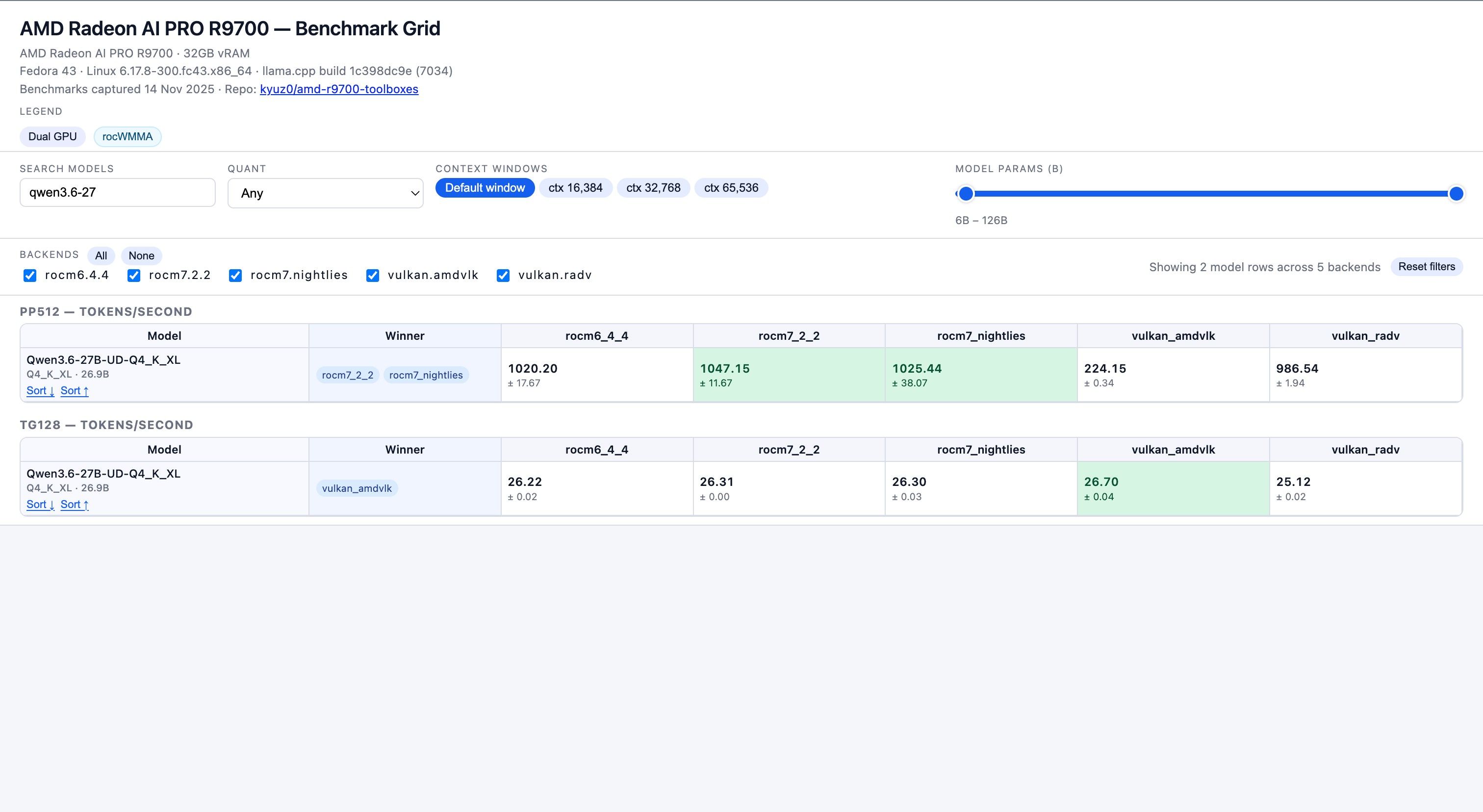
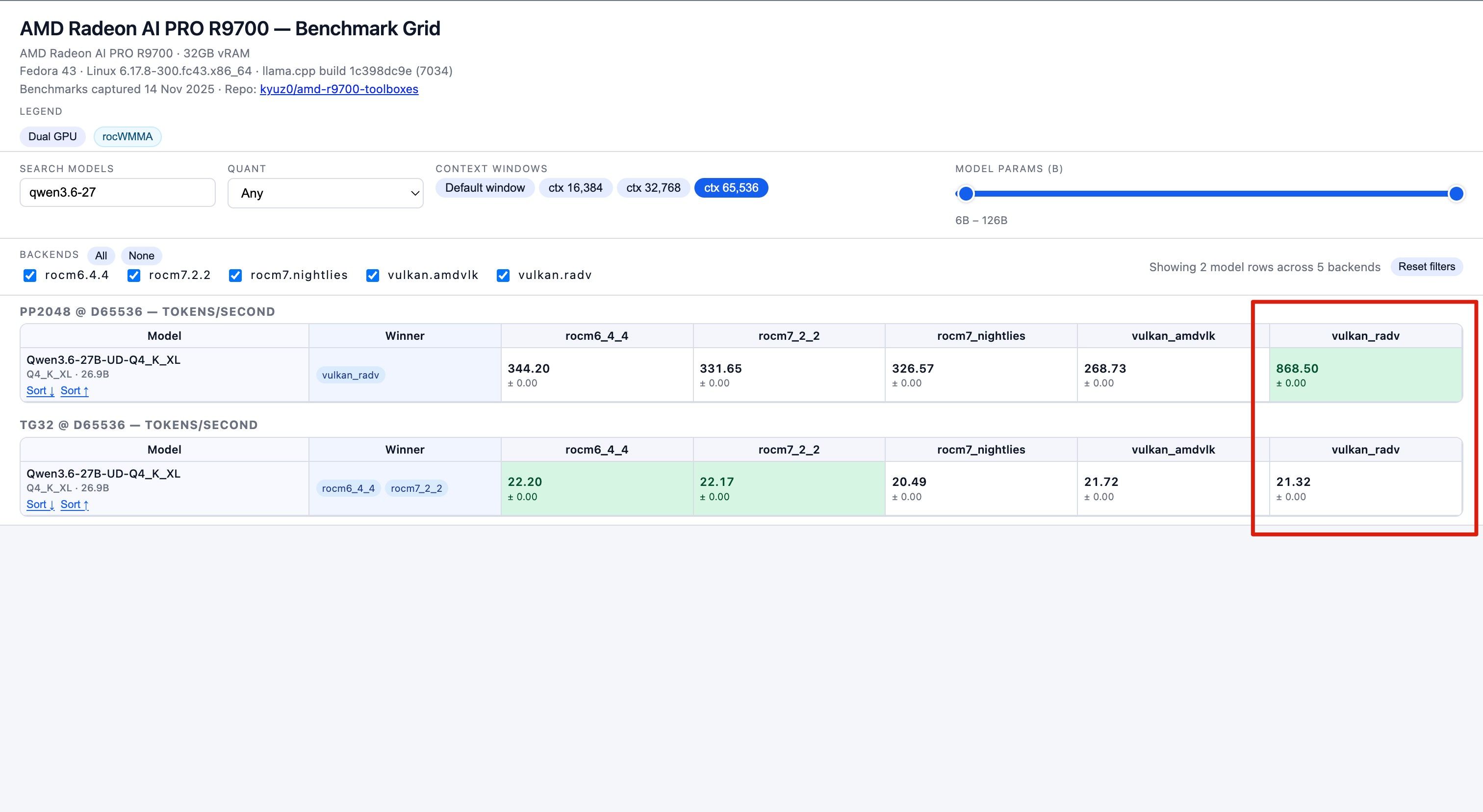
上面的测试数据,老外没有使用投机解码
如果开投机解码,估计能到 50+ token / s -
能否有個測試數據看看?
我看國外有人用cyankiwi/Qwen3.6-27B-AWQ-INT4可以測到287.38 tok/s (ROCM)
https://kyuz0.github.io/amd-r9700-vllm-toolboxes/ -
T terry 于 取消固定此主题
-
T terry 于 将此主题固定
-
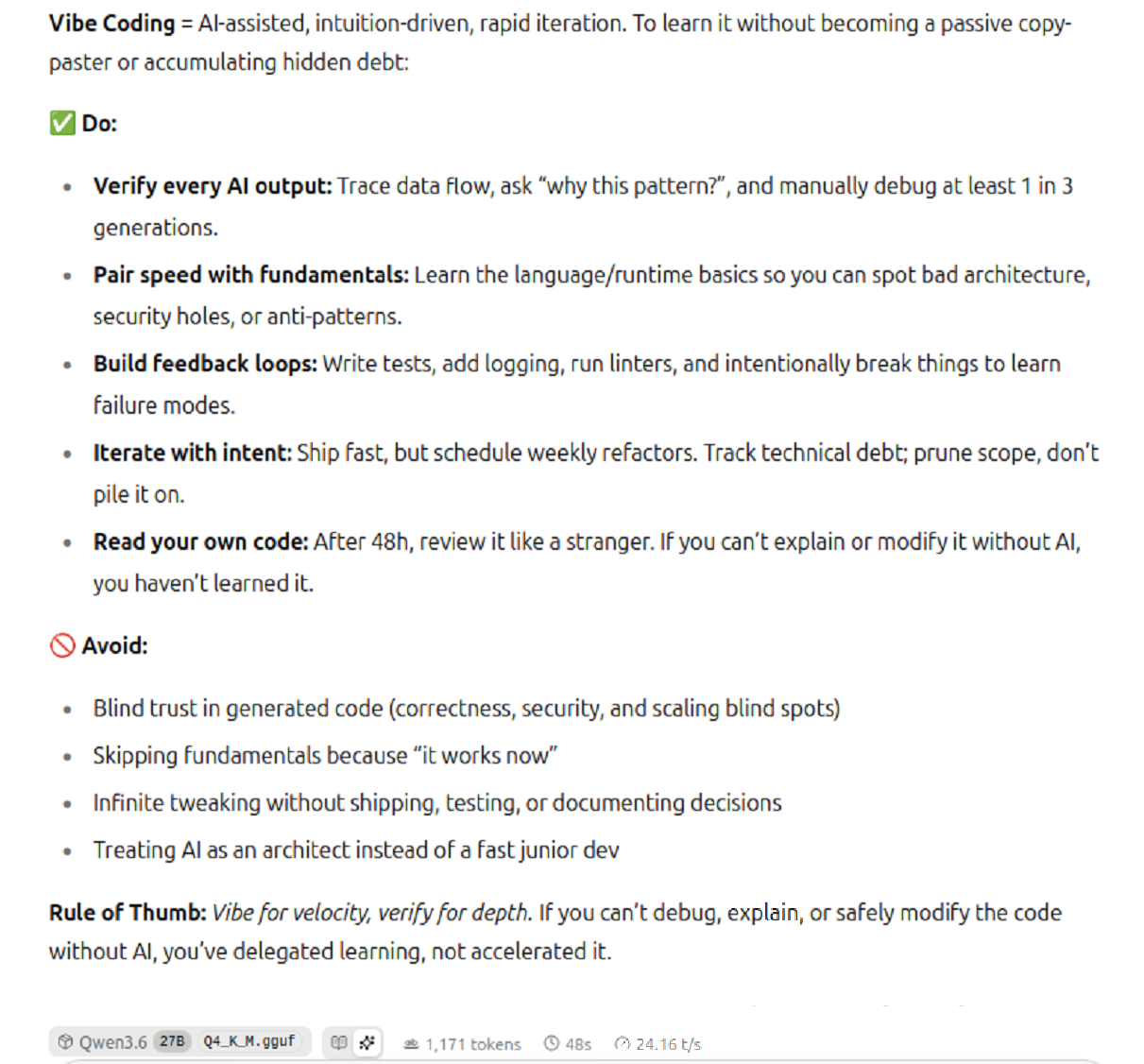
目前R9700在機器上的bench mark test
OS: ubuntu 24.04llama-bench -m Models/Qwen3.6-27B-GGUF/Qwen3.6-27B-Q4_K_M.gguf ggml_cuda_init: found 1 ROCm devices (Total VRAM: 32624 MiB): Device 0: AMD Radeon AI PRO R9700, gfx1201 (0x1201), VMM: no, Wave Size: 32, VRAM: 32624 MiB | model | size | params | backend | ngl | test | t/s | | ------------------------------ | ---------: | ---------: | ---------- | --: | --------------: | -------------------: | | qwen35 27B Q4_K - Medium | 15.65 GiB | 26.90 B | ROCm | 99 | pp512 | 1008.59 ± 25.13 | | qwen35 27B Q4_K - Medium | 15.65 GiB | 26.90 B | ROCm | 99 | tg128 | 26.38 ± 0.03 | build: 838374375 (9103) -
系统 于 取消固定此主题
-
 J jenaflex 于 引用了 此主题
J jenaflex 于 引用了 此主题
-
看到最近两个配置R9700的都遇到了问题,我来顶一下自己的帖子吧。
首先问AI要用对的提示词,问对的方向。如果告诉AI的初始信息的方向不对,很容易被它越带越偏。比如你问的AI的时候,先问AI它需要说明系统信息,让它给你一些命令行去打印当前的系统信息(软件、硬件版本),然后再黏贴、反馈给它。
建议新手R9700,先直接抄我这个成功的作业(大方向肯定可行),然后把帖子发给AI,让它对比你跟我在软硬件配置上的不同,针对性地帮你重新调整出一套方案(比如命令行需要怎么改)
新手拿到硬件,可以按照以下步骤:
- 下载Ubuntu 24.04 或者 Linux Mint 22.3(Ubuntu变种)的iso镜像,用 Etcher或Rufus烧写到空u盘
- 启动引导到u盘,Ubuntu和Mint的Live USB,都是能加载u盘上的系统的。用终端命令行(Terminal),
输入
lspci | grep -i "amd"(或者nvidia,Intel等关键词),看你的显卡是否被正确识别。
3. 正常安装Ubuntu或者Mint到你的系统盘SSD。安装完毕,按提示拔u盘,重启
4. 重启到新安装的系统,用lspci和inxi -G命令确保显卡被识别
5. N卡需要安装正确版本的Linux驱动(可以问AI)
比如我之前折腾老的 Tesla P100,AI说装535驱动,但最终还是得装580驱动+手动编译llama.cpp才行。N卡,如果是P100、V100这些计算卡(虽然不推荐),建议用官方dcgmi工具跑测试显存。
6. AMD的卡,包括绝大部分其他硬件,只要不是特别新,驱动都是被“收录”集成在了Linux kernel。如果kernel太老,那要么没驱动、要么驱动太老。
7. 升级Linux kernel到你当前系统支持的最新,比如我在LinuxMint22.3里能选的最新Linux kernel是6.17(你的情况可能不一定完全一样)
下图是AMD官方说明,GA=GeneralAvailability,HWE=Hardware Enablement
如果看Ubuntu 24.04的话,HWE的最低版本是6.14(我个人选择和建议是:升到新一点的kernel,这样驱动也新一些)AI Pro R9700的系统支持
ROCM软件的系统支持
- 接着按照我上面说的吧。
由于llama.cpp Rocm的预编译好的runtime里面,很可能没有R9700的支持(我当时就没有;并且显卡编号欺骗大法也不管用,load model卡在了97%),所以需要自己编译。7900xtx比较老,我记得用预编译好的llama.cpp Rocm的runtime就行(偷懒可以直接用lm studio搞定)。
-
T terry 于 将此主题固定
-
此贴的重点:问 AI 关键要找准方向、用对提示词,否则起步方向不对,很容易被它带偏。
-
享用顺序,新手先看“二更”,然后到第7步开始按照“一更”
原帖:
可以开始玩啦
升级下Linux kernel 到6.17inxi -G Graphics: Device-1: Intel HD Graphics 530 driver: i915 v: kernel Device-2: AMD driver: amdgpu v: kernel Display: x11 server: X.Org v: 21.1.11 with: Xwayland v: 23.2.6 driver: X: loaded: modesetting unloaded: fbdev,vesa dri: iris gpu: i915 resolution: 1920x1200~60Hz API: EGL v: 1.5 drivers: iris,kms_swrast,radeonsi,swrast platforms: gbm,x11,surfaceless,device API: OpenGL v: 4.6 compat-v: 4.5 vendor: intel mesa v: 25.2.8-0ubuntu0.24.04.1 renderer: Mesa Intel HD Graphics 530 (SKL GT2) API: Vulkan v: 1.3.275 drivers: N/A surfaces: xcb,xlib硬件配置:
i3-6100 (2核4线程 3.7GHz)(国内海鲜市场+海运)
16GB DDR4 2666
线下$40淘到的华硕Z170 败家之眼ROG Maximus VIII Hero其实这上述是我的开放测试平台,如果都没啥问题,我就给它挪到一个 戴尔T7920工作站了(也是线下二手)
那台是Xeon Gold 6130
32GB ECC
一更:
操作系统选择:
我习惯用Linux Mint 22.3(Kernel 6.17,等效于Ubuntu24.04),因为其桌面更像Windows操作习惯,并且整体也更精简稳健,内存消耗小,不像Ubuntu有时候给你硬塞一些花里胡哨的东西。Mint安装的时候,还自带一个傻瓜化工具,能在已经安装了Windows的SSD上重新分割分区,来装双系统。
走的弯路#1:没有在BIOS禁用i3 6100的Intel 核显
本意是想两者共存,核显可以干点别的事(比如视频转码)
但是无论怎么在grub里面加参数(比如,禁用Intel的3D加速、休眠),一开x11vnc,都会kernel panic宕机。
原因“x11vnc的高频抓屏触发了Intel核显老旧的休眠唤醒 Bug,直接把系统内核卡死了。”走的弯路#2:尝鲜Ubuntu 26.04
最初在Mint22.3,用LM-Studio Rocm版llama.cpp 无法识别R9700(系统识别正常)。用Gemini查了一圈,以为是kernel和linux-firmware太老,所以图省事就去尝鲜刚刚发布的Ubuntu 26.04(kernel 7.0)。
结果,Ubuntu26.04 自带的Rocm是7.1,虽然LM-Studio的Rocm版llama.cpp识别了R9700,仍然是加载模型卡在99% (所以还有人去趟ROCM 7.1的坑,也是无语)。然而升级Rocm到7.2.3的复杂度和用Mint 22.3(U24.04)没差别。初步成功
最后回到Mint22.3,配置好了,先是简单测试,感觉24t/s有点小失望,还有优化空间。-
LM-Studio的Vulkan runtime,完全懒人傻瓜化,打开即用,23t/s
-
编译Rocm llama.cpp-server
LM-Studio 没有针对 AMD R9700编译的Rocm llama.cpp
已经尝试通过加launch参数 - 伪装RDNA3的办法,加载模型会长时间卡在97%
遂自己编译 llama.cpp, 24t/s
详细过程如下
- 升级Linux-firmware
git clone git://git.kernel.org/pub/scm/linux/kernel/git/firmware/linux-firmware.git sudo rsync -av linux-firmware/amdgpu/ /lib/firmware/amdgpu/ sudo update-initramfs -u # 最后重启- 安装ROCm 7.2.3 & Toolchain
# Install the ROCm repository and base userspace wget https://repo.radeon.com/amdgpu-install/7.2.3/ubuntu/noble/amdgpu-install_7.2.3.70203-1_all.deb sudo apt install ./amdgpu-install_7.2.3.70203-1_all.deb sudo amdgpu-install --usecase=rocm --no-dkms # Install specific development headers and the LLVM compiler sudo apt install rocm-llvm hipblas-dev rocblas-dev sudo usermod -a -G render,video $USER- 编译适用gfx1201(R9700)的llama.cpp
注:如果编译中要是缺东西,往往是路径给错了
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp && mkdir build && cd build cmake .. -DGGML_HIP=ON \ -DAMDGPU_TARGETS=gfx1201 \ -DCMAKE_C_COMPILER=/opt/rocm-7.2.3/llvm/bin/clang \ -DCMAKE_CXX_COMPILER=/opt/rocm-7.2.3/llvm/bin/clang++ \ -DCMAKE_PREFIX_PATH=/opt/rocm-7.2.3 make llama-server -j$(nproc)最后跑起来
先测下40k上下文,开了Flash Attention, KV Q8~/llama.cpp/build/bin/llama-server -m /home/<user>/.lmstudio/models/lmstudio-community/Qwen3.6-27B-GGUF/Qwen3.6-27B-Q4_K_M.gguf --port 1234 -ngl 999 -c 40960 -fa on --cache-type-k q8_0 --cache-type-v q8_0 --threads 2去浏览器输入 localhost:1234,就可以看到对话窗口(如之前截图)
二更:
看到最近两个配置R9700的都遇到了问题,我来顶一下自己的帖子吧。问 AI 关键要找准方向、用对提示词,否则起步方向不对,很容易被它带偏。比如提问时,先让 AI 提供打印系统信息(软硬件版本)的命令行,你再把运行结果粘贴反馈给它。
建议 R9700 新手直接抄我这个成功作业,大方向绝对可行。然后把帖子发给 AI,让它对比你和我的软硬件配置差异,帮你针对性地调整方案(比如修改命令行)。
新手拿到硬件,可以按照以下步骤:
- 下载Ubuntu 24.04 或者 Linux Mint 22.3(Ubuntu变种)的iso镜像,用 Etcher或Rufus烧写到空u盘
- 启动引导到u盘,Ubuntu和Mint的Live USB,都是能加载u盘上的系统的。用终端命令行(Terminal),
输入
lspci | grep -i "amd"(或者nvidia,Intel等关键词; -i 不区分大小写),看你的显卡是否被正确识别。
3. 正常安装Ubuntu或者Mint到你的系统盘SSD。安装完毕,按提示拔u盘,重启
4. 重启到新安装的系统,用lspci和inxi -G命令确保显卡被识别
5. N卡必须安对 Linux 驱动(可咨询 AI)。
比如我之前折腾老卡 Tesla P100,AI 建议 535,但最后死活得用 580 驱动加手动编译 llama.cpp 才搞定。另外像 P100、V100 这类计算卡(虽不推荐),建议用官方 dcgmi 工具测下显存。
A卡及其他硬件:只要不是最新型号,驱动基本都内置在 Linux 内核(Kernel)里。但如果内核太老,驱动就会缺失或版本过旧。
6. 升级Linux kernel到你当前系统支持的最新,比如我在LinuxMint22.3里能选的最新Linux kernel是6.17(你的情况可能不一定完全一样)
下图是AMD官方说明,GA=GeneralAvailability,HWE=Hardware Enablement
如果看Ubuntu 24.04的话,HWE的最低版本是6.14(我个人选择和建议是:升到新一点的kernel,这样驱动也新一些)AI Pro R9700的系统支持
ROCM软件的系统支持
- 接着按照我上面说的吧。
由于llama.cpp Rocm的预编译好的runtime里面,很可能没有R9700的支持(我当时就没有;并且伪装RDNA3显卡的办法也不管用,load model卡在了97%),所以需要自己编译。7900xtx比较老,我记得用预编译好的llama.cpp Rocm的runtime就行(偷懒可以直接用lm studio搞定)。
-
-
@jenaflex 啥也别说了, 你就简单说在你这套机子上面, llama.cpp 跑 Qwen3.6-27B-MTP Q4量化, 跑到多少 t/s ?
-
系统 于 取消固定此主题