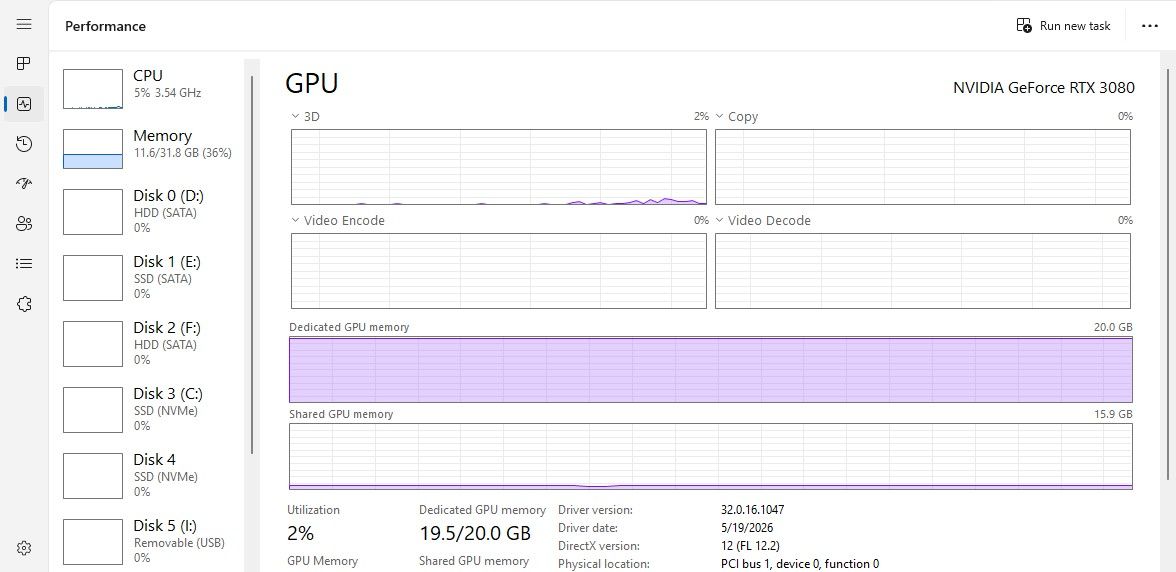
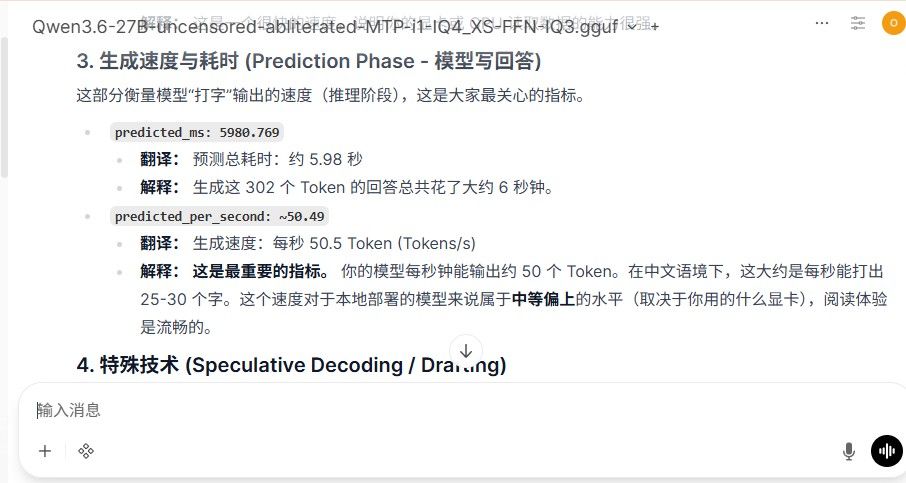
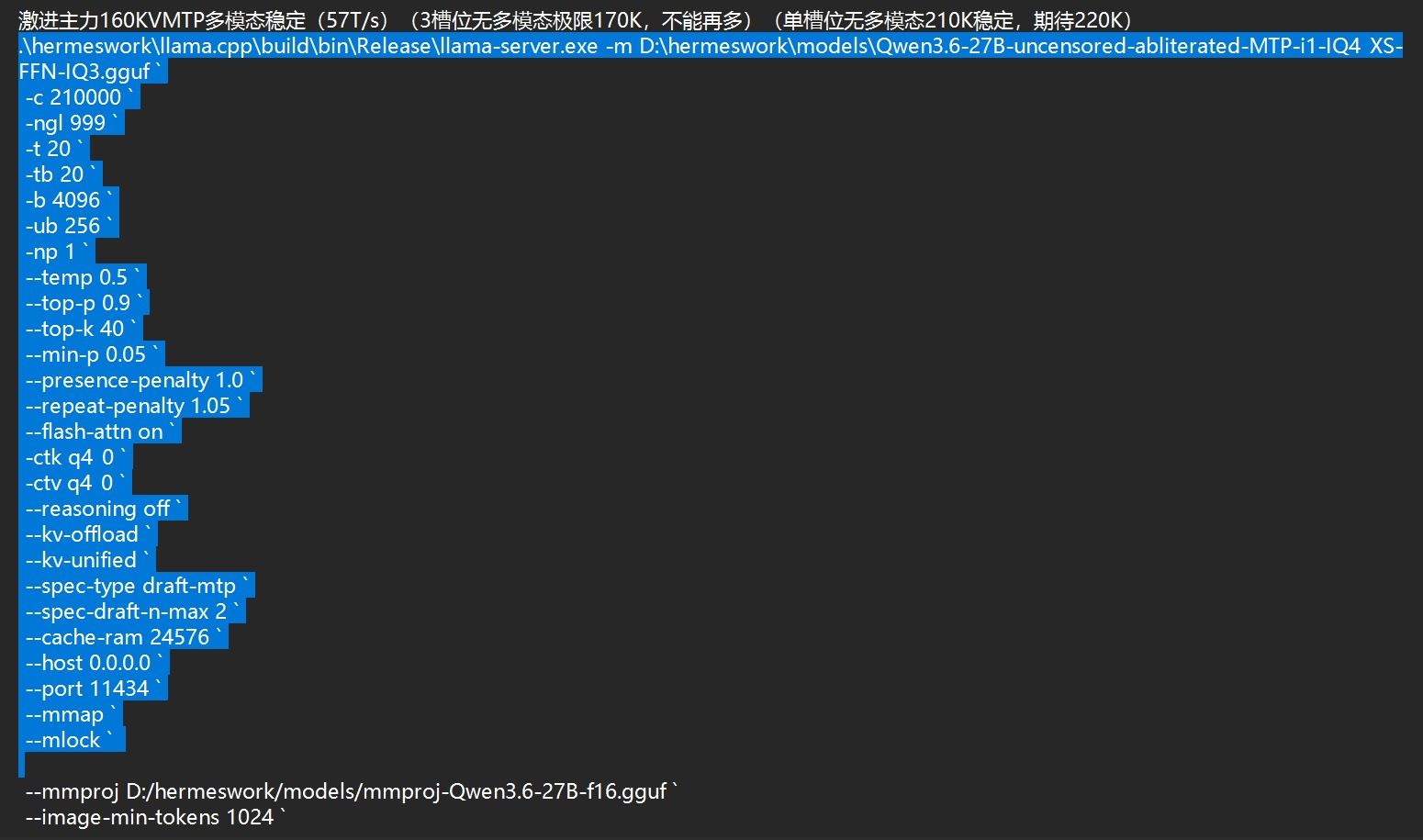
RTX3080 20g,qwen3.6 27B 45-50T/S 35B多模态256K 110T/S
-
感谢楼主分享。
prefill性能不到500,从性价比上来讲可以接受,但是容易多轮对话之后每次LLM调用都要罚站10~20秒。但反过来想,如果使用localLLM只是用于背景进程任务,对实时性要求不高的话,也是可以接受的。
还有就是MTP对于prefill有一定的负面影响,也需要去衡量。
-
最新优化,我觉得又白嫖了KV了,多模态MTP,长时间N多轮对话直到KV到99%都稳定运行,KV已经可以达到190K.。。。我继续让他做中型的代码任务,
35B我觉得可以弃用了,MTP基本无效,不时出点“什么缩进错误”,或者“干脆我重写好了”,
隔壁帖子提到的forcing full prompt re-processing due to lack of cache dataforcing full prompt re-processing due to lack of cache data现象,终于是出现了,不过也就一扫而过,没有感到任何异常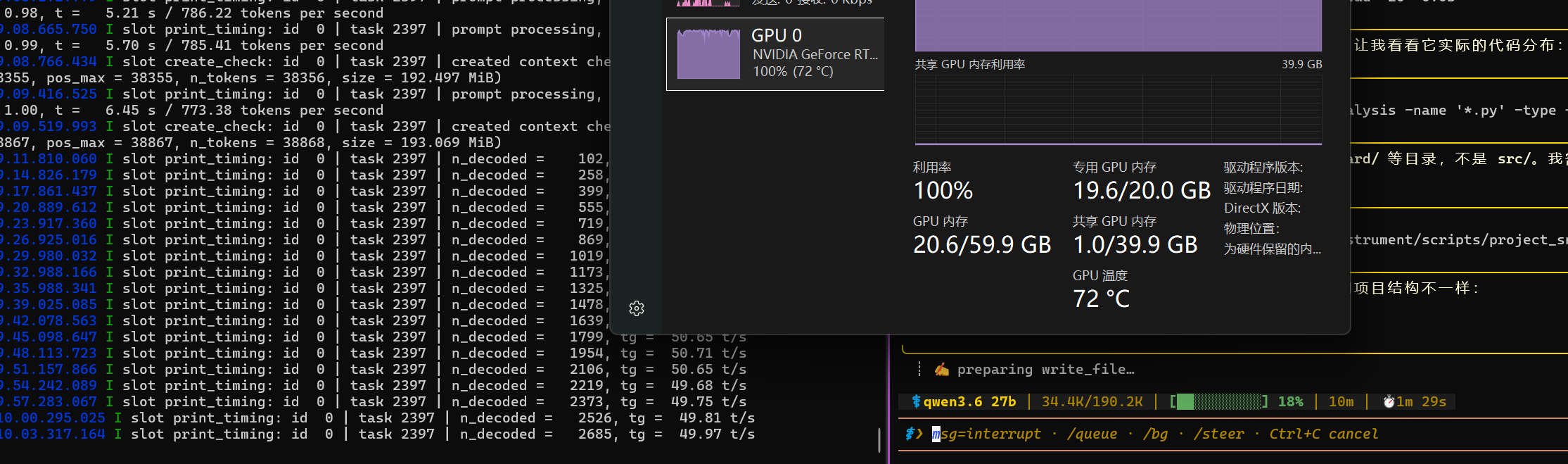
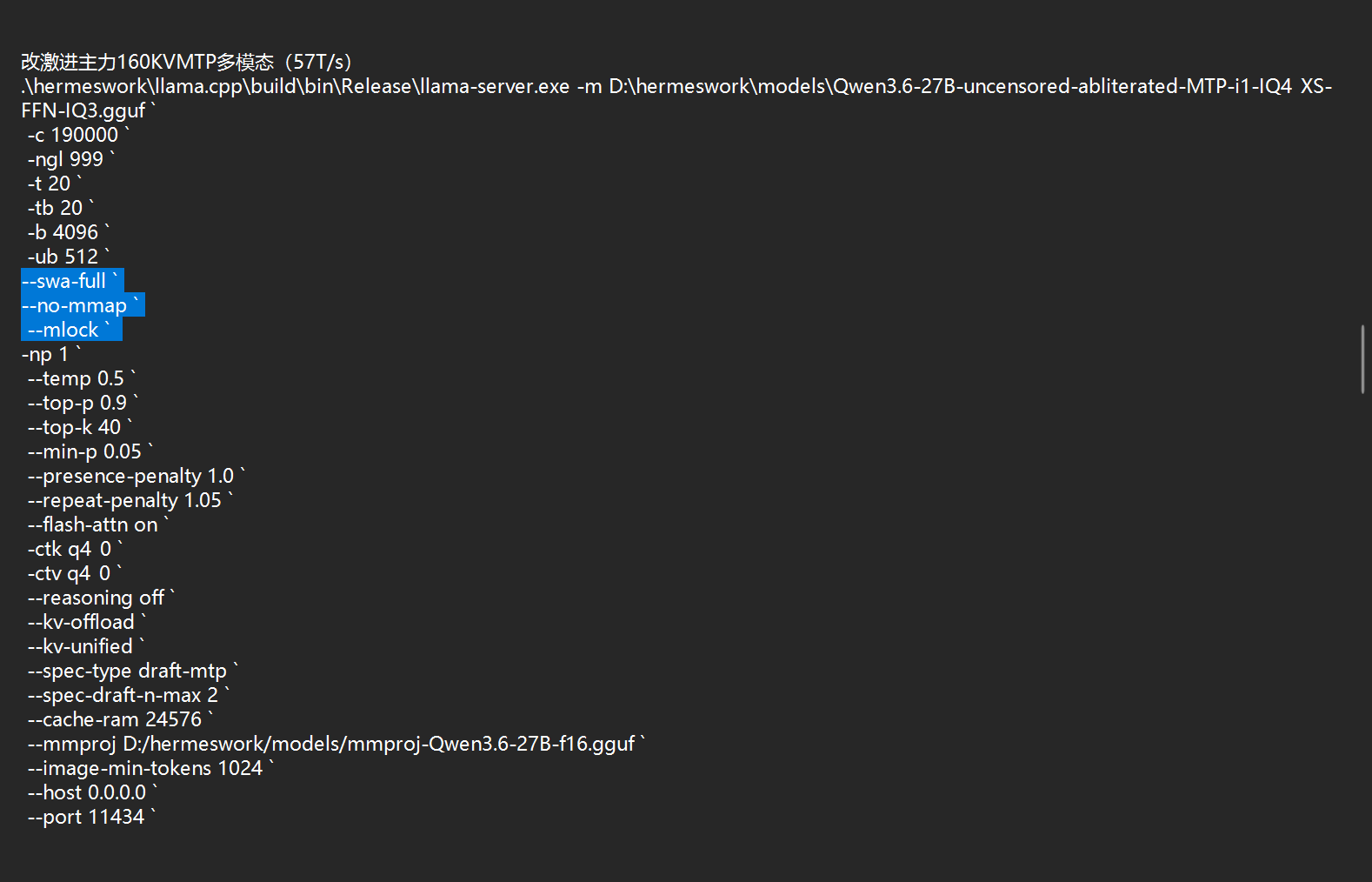
改了高亮的地方 -
我目前使用HERMES的方法是对话式的,还没达到大佬们自动生产脚本的程度,目前的体验已经比在线的要好,要快,能力一点不弱,甚至更强,因为它读我给它的PDF,又快又准,理解得又好,甚至有的时候我对PDF那个环节拿不准,让他帮我找解决方法比我去看还快,之前一旦对话到后期,显存占用19.7M无论共享显存是0.2G还是多少,就有几率出现个位数的T/S,这个时候就比较煎熬了,因为这个时候项目代码有的还没更新完,停又不好停,但是现在这个设置,达到19.7G显存占用后,速度几乎还能保持35T/S左右,甚至现在共享显存已经到了1G了,还是很稳,对话过程的延时基本就是一两秒就开始给我回复了,到此刻,正式结束HERMES 跑QWEN3.6 27B的参数优化,谢谢大家看我唠叨
-
我目前使用HERMES的方法是对话式的,还没达到大佬们自动生产脚本的程度,目前的体验已经比在线的要好,要快,能力一点不弱,甚至更强,因为它读我给它的PDF,又快又准,理解得又好,甚至有的时候我对PDF那个环节拿不准,让他帮我找解决方法比我去看还快,之前一旦对话到后期,显存占用19.7M无论共享显存是0.2G还是多少,就有几率出现个位数的T/S,这个时候就比较煎熬了,因为这个时候项目代码有的还没更新完,停又不好停,但是现在这个设置,达到19.7G显存占用后,速度几乎还能保持35T/S左右,甚至现在共享显存已经到了1G了,还是很稳,对话过程的延时基本就是一两秒就开始给我回复了,到此刻,正式结束HERMES 跑QWEN3.6 27B的参数优化,谢谢大家看我唠叨
我目前使用HERMES的方法是对话式的,还没达到大佬们自动生产脚本的程度,目前的体验已经比在线的要好,要快,能力一点不弱,甚至更强,因为它读我给它的PDF,又快又准,理解得又好,甚至有的时候我对PDF那个环节拿不准,让他帮我找解决方法比我去看还快,之前一旦对话到后期,显存占用19.7M无论共享显存是0.2G还是多少,就有几率出现个位数的T/S,这个时候就比较煎熬了,因为这个时候项目代码有的还没更新完,停又不好停,但是现在这个设置,达到19.7G显存占用后,速度几乎还能保持35T/S左右,甚至现在共享显存已经到了1G了,还是很稳,对话过程的延时基本就是一两秒就开始给我回复了,到此刻,正式结束HERMES 跑QWEN3.6 27B的参数优化,谢谢大家看我唠叨
你是怎样测试的?
-
最新优化,我觉得又白嫖了KV了,多模态MTP,长时间N多轮对话直到KV到99%都稳定运行,KV已经可以达到190K.。。。我继续让他做中型的代码任务,
35B我觉得可以弃用了,MTP基本无效,不时出点“什么缩进错误”,或者“干脆我重写好了”,
隔壁帖子提到的forcing full prompt re-processing due to lack of cache dataforcing full prompt re-processing due to lack of cache data现象,终于是出现了,不过也就一扫而过,没有感到任何异常
改了高亮的地方 -
我目前使用HERMES的方法是对话式的,还没达到大佬们自动生产脚本的程度,目前的体验已经比在线的要好,要快,能力一点不弱,甚至更强,因为它读我给它的PDF,又快又准,理解得又好,甚至有的时候我对PDF那个环节拿不准,让他帮我找解决方法比我去看还快,之前一旦对话到后期,显存占用19.7M无论共享显存是0.2G还是多少,就有几率出现个位数的T/S,这个时候就比较煎熬了,因为这个时候项目代码有的还没更新完,停又不好停,但是现在这个设置,达到19.7G显存占用后,速度几乎还能保持35T/S左右,甚至现在共享显存已经到了1G了,还是很稳,对话过程的延时基本就是一两秒就开始给我回复了,到此刻,正式结束HERMES 跑QWEN3.6 27B的参数优化,谢谢大家看我唠叨
-
我目前使用HERMES的方法是对话式的,还没达到大佬们自动生产脚本的程度,目前的体验已经比在线的要好,要快,能力一点不弱,甚至更强,因为它读我给它的PDF,又快又准,理解得又好,甚至有的时候我对PDF那个环节拿不准,让他帮我找解决方法比我去看还快,之前一旦对话到后期,显存占用19.7M无论共享显存是0.2G还是多少,就有几率出现个位数的T/S,这个时候就比较煎熬了,因为这个时候项目代码有的还没更新完,停又不好停,但是现在这个设置,达到19.7G显存占用后,速度几乎还能保持35T/S左右,甚至现在共享显存已经到了1G了,还是很稳,对话过程的延时基本就是一两秒就开始给我回复了,到此刻,正式结束HERMES 跑QWEN3.6 27B的参数优化,谢谢大家看我唠叨
你是怎样测试的?
@applejuice 就是命令行和hermes对话,让它建立项目做具体事情,做不好就骂,很奇怪,骂他比表扬他更有效,直到kv接近到99%,然后让它总结,写进度,退出,再次命令行进入,让它根据他自己写的项目进度继续做,每次重新打开第一次会话是比较久的,不过这个不影响了,毕竟190k上下文,已经可以撑很久,
那么问题来了,大家是怎么用的?为什么我的上下文基本是线性向上的,其实dashboard 的输入token曲线就能看出来
-
感谢大佬,已经抄作业成功,同款20GB显存RTX3080 ,190K上下文,能跑50token/s左右,比LM Studio快太多了!