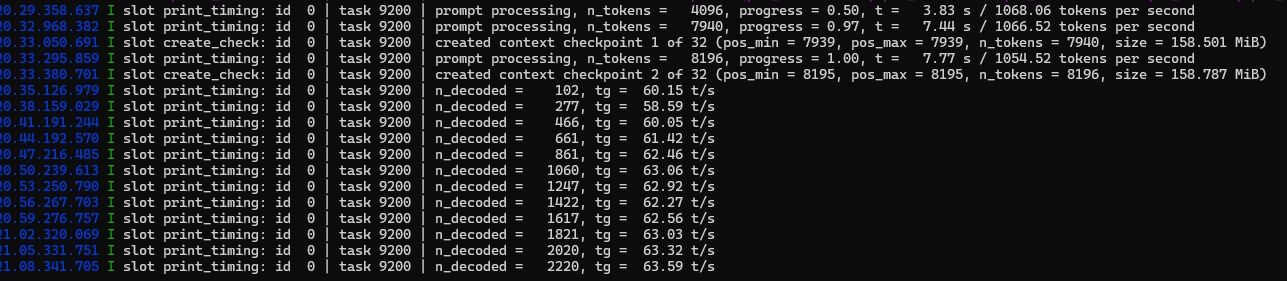
RTX3080 20g,qwen3.6 27B 45-50T/S 35B多模态256K 110T/S
-
以我这次的折腾,单卡跑27B MTP长期稳定极限是120K上下文,也很容易触发上下文压缩的,不知道有没有大神有解决方法,
我刚才豆包了一下,原来可以将模型权重分别载入两张卡,这样还是有意义啊,但是我主板第二PCIE是3.0的,这就很尴尬了,NVLINK能买到估计也不便宜
-
@vosrock 3080好像没有nvlink
nvlink 现在都在1100+-我就是为了nvlink 多付3000-4000
因为 huananzhi 单路x99 pcie3.0 距离都不适用nvlink...
有点超预算所以有点后悔@applejuice 他说的3090,3090可以nvlink,个人感觉透出产出比不高,没实践过
-
@applejuice 他说的3090,3090可以nvlink,个人感觉透出产出比不高,没实践过
-
@rock-shi 我也只折腾过AI
如果下决定前 知道要多付出4000元 我就选r9700了但是据ai 解答 长上下文 如果 超过24gb nvlink 也有帮助
收益太少 是真的@applejuice 也不能这么说,肯定是有舍有得。像我这两个3080,当时买的时候感觉挺落后的,实际上玩起来的时候说不定有很多其他卡不适配的应用场景,整体速度感觉也还不错。
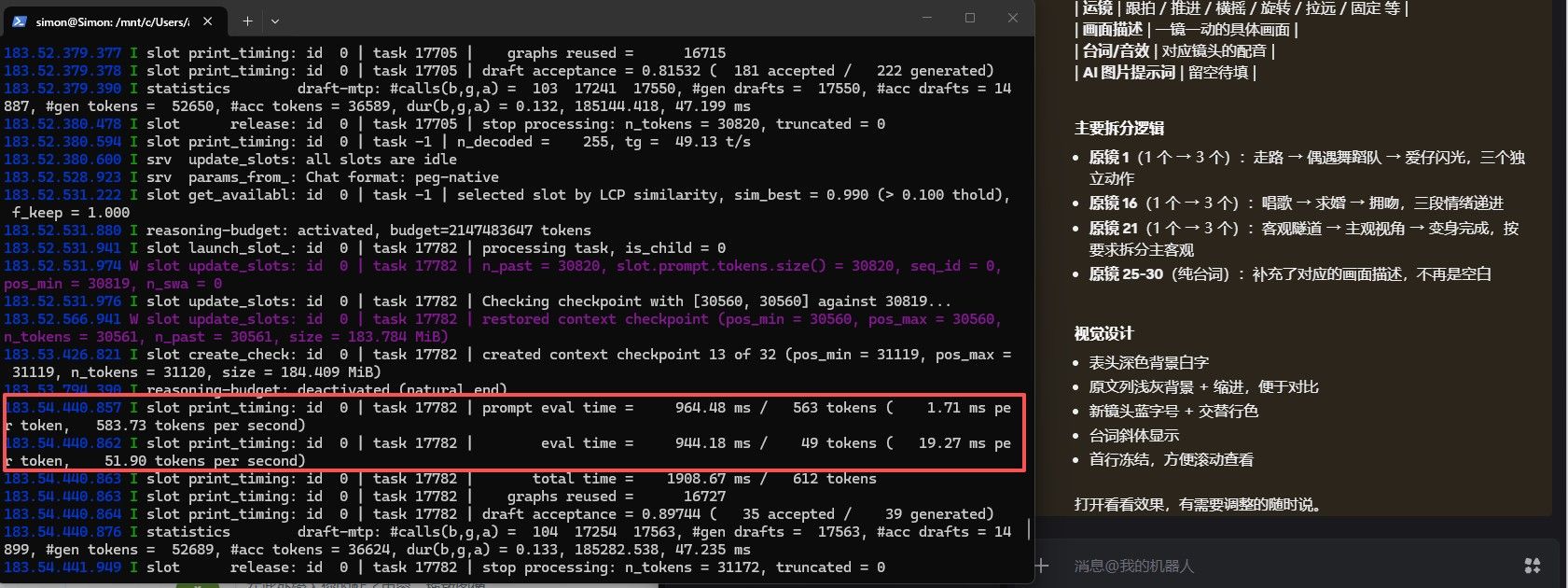
-
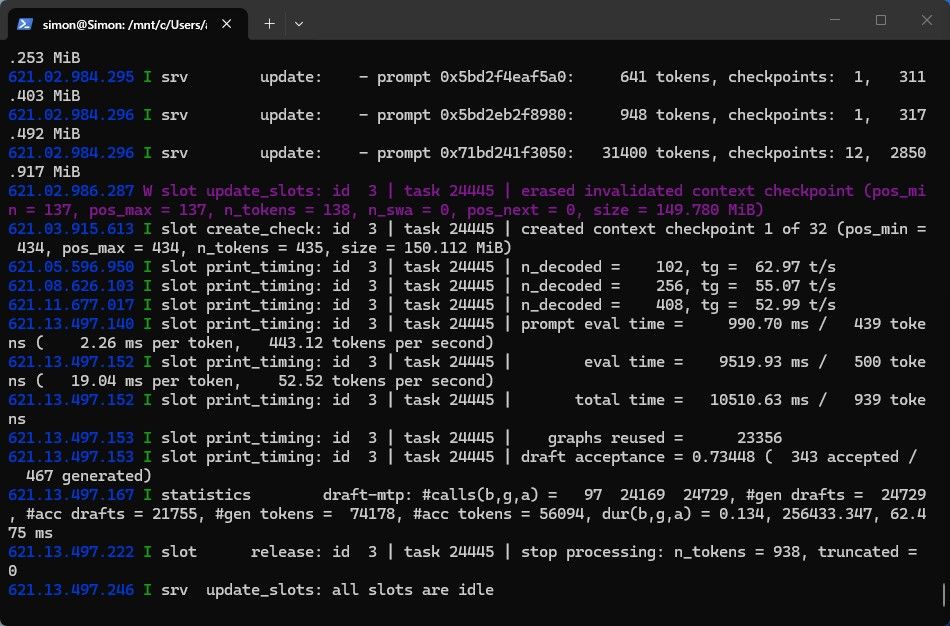
用27B跑项目的前期,工作习惯,框架大体搭好,然后用35B,开满上下文,不用MTP,速度就是这个样子,截图的这个状态实际上下文已经跑到了150K了,这只是单卡,还是不要搞双卡了,哥们 -
钱已经花了 等我机器到也测一测
@applejuice 双卡3090+nvlink绝对牛逼。期待一波反馈
-
钱已经花了 等我机器到也测一测
@applejuice 原来您是双3090啊,那不一样,完全是两个世界了,我估计跑COMFYuI都能有不错的体验啊,单3080其实LTX2.3也能跑一下,体验都还可以的,这张卡其实我是去年拿来跑视频的敢信
-
@applejuice 你的3090加nvlink 有效果吗?能不能说一下提升情况
-
@applejuice 你的3090加nvlink 有效果吗?能不能说一下提升情况
-
@applejuice 你的3090加nvlink 有效果吗?能不能说一下提升情况
-
系统 取消固定了该主题
-
@im17me 还没到啊. 我国外
@applejuice 48g我的天,后面还可以关注DFlash,你这跑27b速度不得到80t/s
-
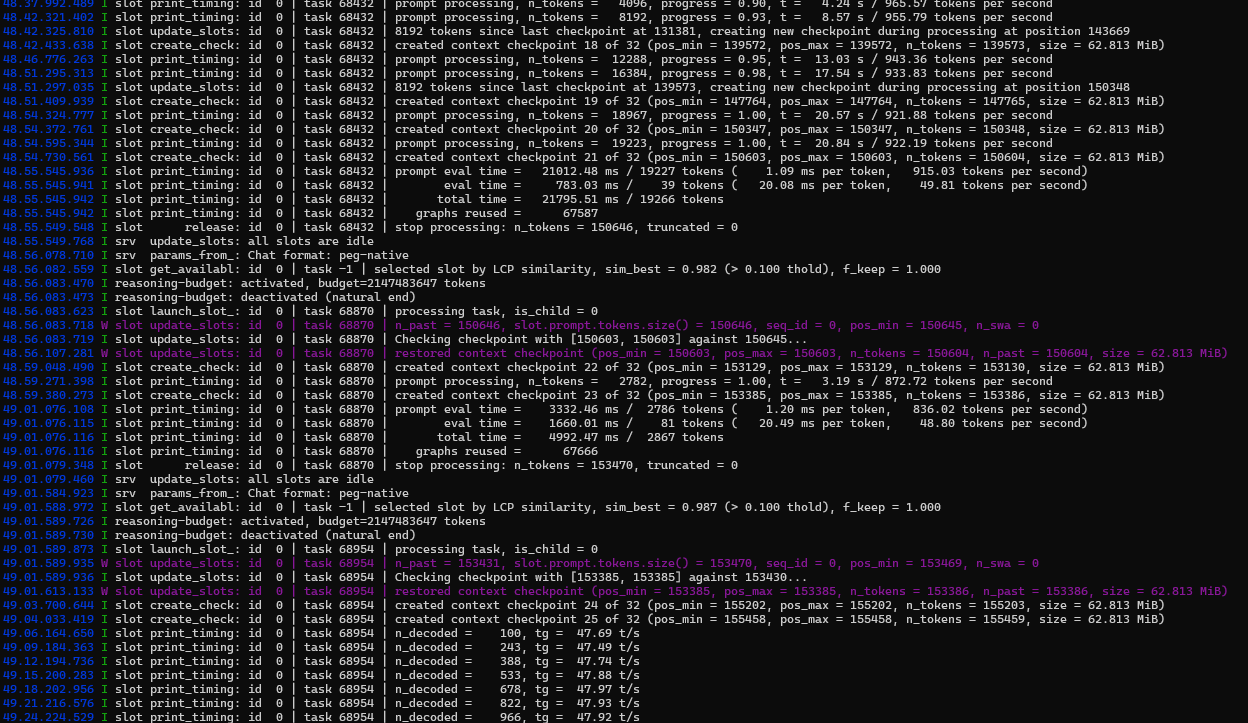
隔壁帖子SKY大佬提供的模型Qwen3.6-27B-uncensored-abliterated-MTP-i1-IQ4_XS-FFN-IQ3,27B多模态MTP的速度,KV现在是150K上限,跑到了100K左右,显存峰值才19。3G,也就是说还可以继续加,不过这个速度这个精度还多模态,已经无遗憾了