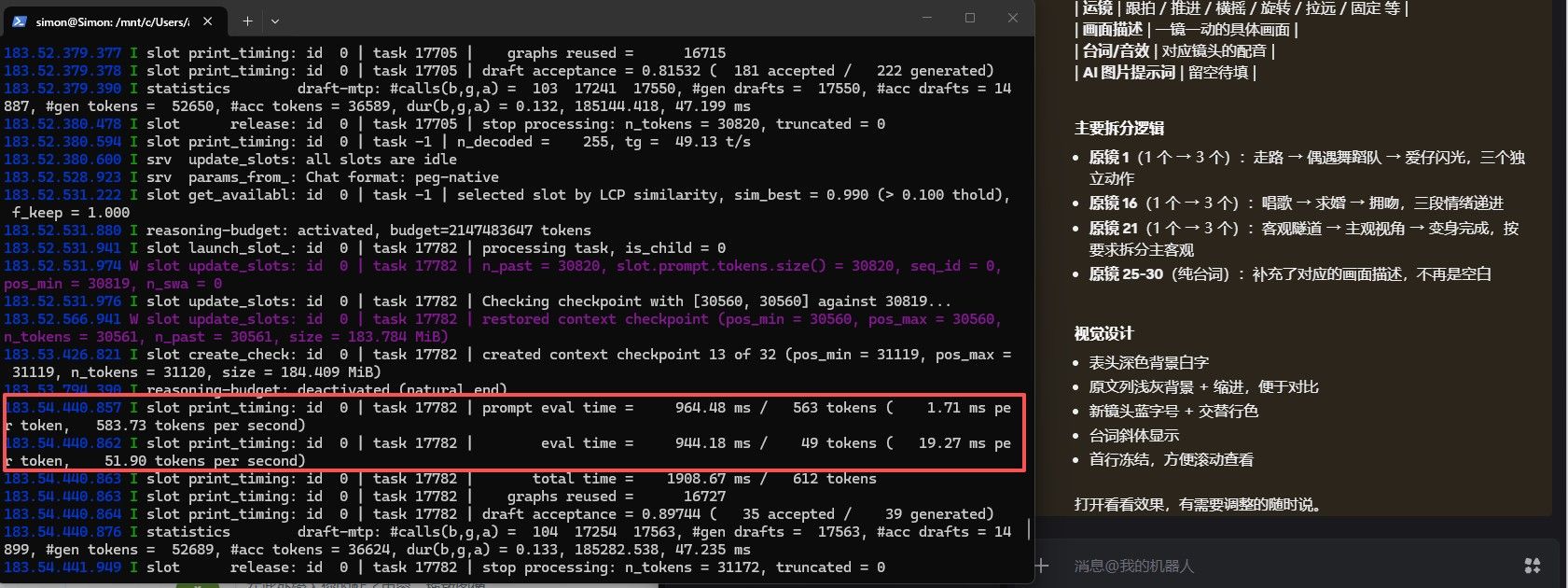
RTX3080 20g,qwen3.6 27B 60-40T/S 本地爽玩配置
-
@applejuice 他说的3090,3090可以nvlink,个人感觉透出产出比不高,没实践过
-
@rock-shi 我也只折腾过AI
如果下决定前 知道要多付出4000元 我就选r9700了但是据ai 解答 长上下文 如果 超过24gb nvlink 也有帮助
收益太少 是真的 -
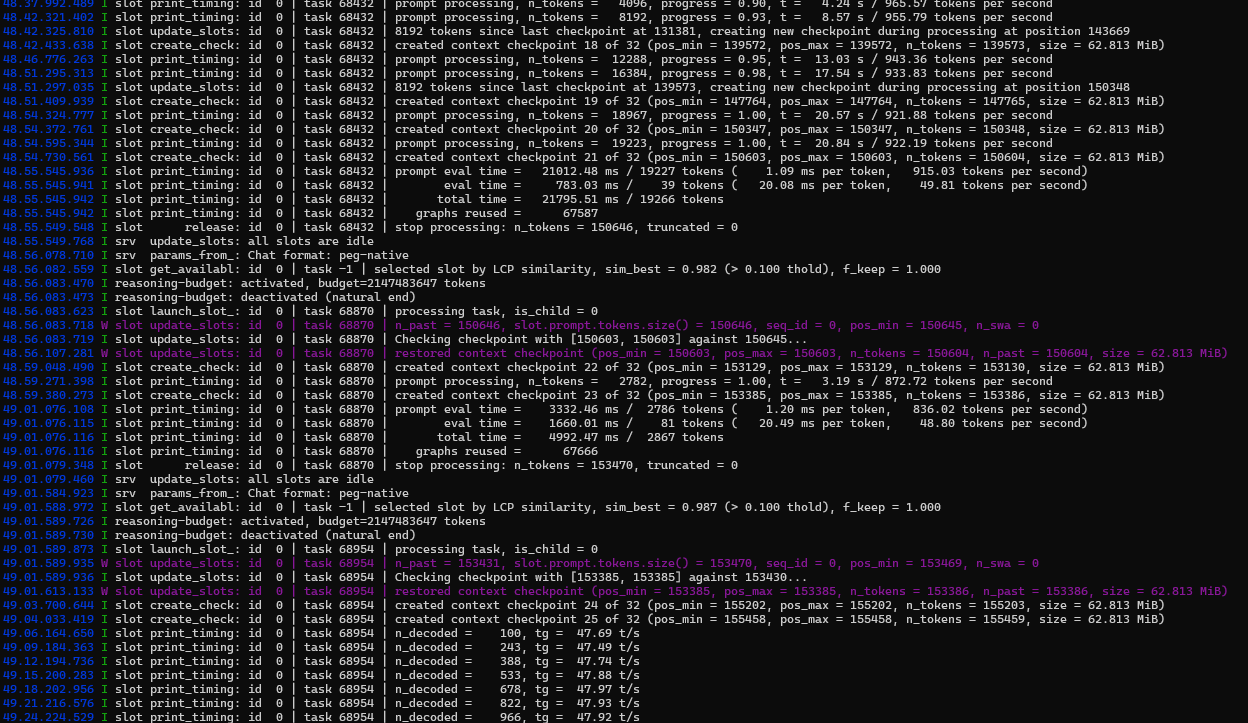
用27B跑项目的前期,工作习惯,框架大体搭好,然后用35B,开满上下文,不用MTP,速度就是这个样子,截图的这个状态实际上下文已经跑到了150K了,这只是单卡,还是不要搞双卡了,哥们 -
钱已经花了 等我机器到也测一测
-
钱已经花了 等我机器到也测一测
-
@applejuice 你的3090加nvlink 有效果吗?能不能说一下提升情况
-
@applejuice 你的3090加nvlink 有效果吗?能不能说一下提升情况
-
@applejuice 你的3090加nvlink 有效果吗?能不能说一下提升情况
-
系统 于 取消固定此主题
-
@im17me 还没到啊. 我国外
-
隔壁帖子SKY大佬提供的模型Qwen3.6-27B-uncensored-abliterated-MTP-i1-IQ4_XS-FFN-IQ3,27B多模态MTP的速度,KV现在是150K上限,跑到了100K左右,显存峰值才19。3G,也就是说还可以继续加,不过这个速度这个精度还多模态,已经无遗憾了

-
感谢楼主分享。
prefill性能不到500,从性价比上来讲可以接受,但是容易多轮对话之后每次LLM调用都要罚站10~20秒。但反过来想,如果使用localLLM只是用于背景进程任务,对实时性要求不高的话,也是可以接受的。
还有就是MTP对于prefill有一定的负面影响,也需要去衡量。
-
最新优化,我觉得又白嫖了KV了,多模态MTP,长时间N多轮对话直到KV到99%都稳定运行,KV已经可以达到190K.。。。我继续让他做中型的代码任务,
35B我觉得可以弃用了,MTP基本无效,不时出点“什么缩进错误”,或者“干脆我重写好了”,
隔壁帖子提到的forcing full prompt re-processing due to lack of cache dataforcing full prompt re-processing due to lack of cache data现象,终于是出现了,不过也就一扫而过,没有感到任何异常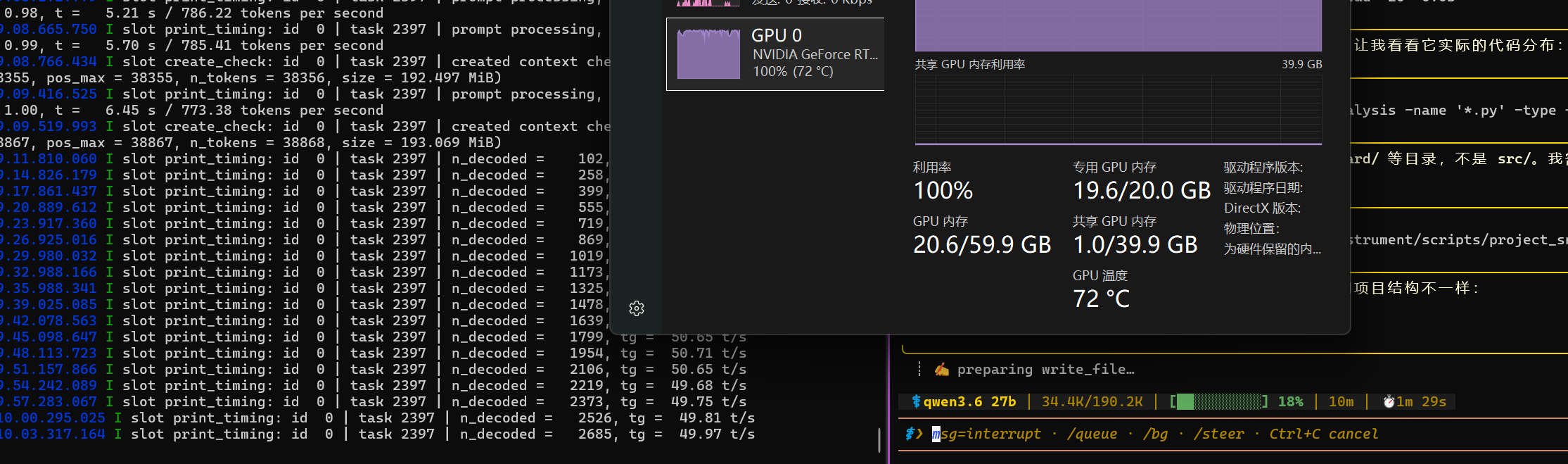
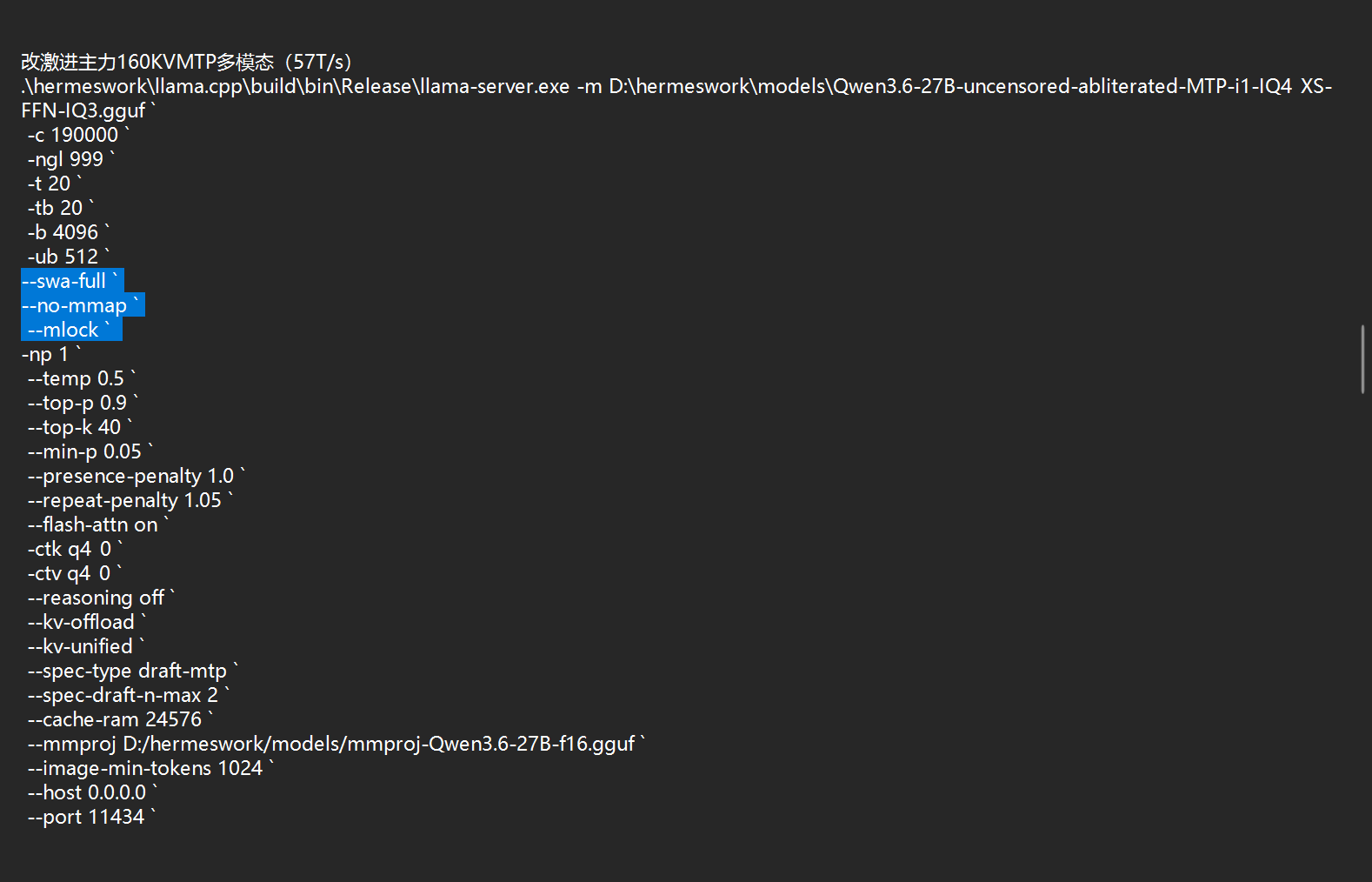
改了高亮的地方 -
我目前使用HERMES的方法是对话式的,还没达到大佬们自动生产脚本的程度,目前的体验已经比在线的要好,要快,能力一点不弱,甚至更强,因为它读我给它的PDF,又快又准,理解得又好,甚至有的时候我对PDF那个环节拿不准,让他帮我找解决方法比我去看还快,之前一旦对话到后期,显存占用19.7M无论共享显存是0.2G还是多少,就有几率出现个位数的T/S,这个时候就比较煎熬了,因为这个时候项目代码有的还没更新完,停又不好停,但是现在这个设置,达到19.7G显存占用后,速度几乎还能保持35T/S左右,甚至现在共享显存已经到了1G了,还是很稳,对话过程的延时基本就是一两秒就开始给我回复了,到此刻,正式结束HERMES 跑QWEN3.6 27B的参数优化,谢谢大家看我唠叨
-
我目前使用HERMES的方法是对话式的,还没达到大佬们自动生产脚本的程度,目前的体验已经比在线的要好,要快,能力一点不弱,甚至更强,因为它读我给它的PDF,又快又准,理解得又好,甚至有的时候我对PDF那个环节拿不准,让他帮我找解决方法比我去看还快,之前一旦对话到后期,显存占用19.7M无论共享显存是0.2G还是多少,就有几率出现个位数的T/S,这个时候就比较煎熬了,因为这个时候项目代码有的还没更新完,停又不好停,但是现在这个设置,达到19.7G显存占用后,速度几乎还能保持35T/S左右,甚至现在共享显存已经到了1G了,还是很稳,对话过程的延时基本就是一两秒就开始给我回复了,到此刻,正式结束HERMES 跑QWEN3.6 27B的参数优化,谢谢大家看我唠叨
我目前使用HERMES的方法是对话式的,还没达到大佬们自动生产脚本的程度,目前的体验已经比在线的要好,要快,能力一点不弱,甚至更强,因为它读我给它的PDF,又快又准,理解得又好,甚至有的时候我对PDF那个环节拿不准,让他帮我找解决方法比我去看还快,之前一旦对话到后期,显存占用19.7M无论共享显存是0.2G还是多少,就有几率出现个位数的T/S,这个时候就比较煎熬了,因为这个时候项目代码有的还没更新完,停又不好停,但是现在这个设置,达到19.7G显存占用后,速度几乎还能保持35T/S左右,甚至现在共享显存已经到了1G了,还是很稳,对话过程的延时基本就是一两秒就开始给我回复了,到此刻,正式结束HERMES 跑QWEN3.6 27B的参数优化,谢谢大家看我唠叨
你是怎样测试的?
-
最新优化,我觉得又白嫖了KV了,多模态MTP,长时间N多轮对话直到KV到99%都稳定运行,KV已经可以达到190K.。。。我继续让他做中型的代码任务,
35B我觉得可以弃用了,MTP基本无效,不时出点“什么缩进错误”,或者“干脆我重写好了”,
隔壁帖子提到的forcing full prompt re-processing due to lack of cache dataforcing full prompt re-processing due to lack of cache data现象,终于是出现了,不过也就一扫而过,没有感到任何异常
改了高亮的地方