
7900 XTX + Qwen3.6-27B:Ubuntu + ROCm / Vulkan / MTP 64/128/256K 全部實測整理
-
7900 XTX + Qwen3.6-27B 測試完整整理







整理日期:2026-05-29
原本在win11原生llama.cpp+vulken,但想為雙卡7900XTX做準備,
換了洋垃圾的主機板裝原生ubuntu24.04+rocm,以為會更好,結果折騰了3天,最終還是vulken更優,測所有參數,發文上來跟大家分享,尋找更優的腳本設計,以下是折騰後請AI整理的資料,部分有參考David Zhang大神的文章這份整理的是目前在 Ubuntu 24.04 + RX 7900 XTX 24GB 上,針對 llama.cpp 做過的 ROCm / Vulkan / MTP 實測彙整。
目標是找出最適合 Hermes / 長上下文 / 單卡可用的路線。
一、測試環境
- 主機:
jaran-Z10PE-D16-WS - CPU:Intel Xeon E5-2678 v3 @ 2.50GHz(雙路)
- RAM:64GB
- GPU:AMD Radeon RX 7900 XTX 24GB(gfx1100 / RADV NAVI31)
- OS:Ubuntu 24.04
- 目標:Qwen3.6-27B,單卡先跑通,並評估 Hermes 實戰可用性
二、模型清單
本次主要測過的模型:
Qwen3.6-27B-MTP-IQ4_XS.ggufQwen3.6-27B-UD-Q4_K_XL.ggufQwen3.6-27B-Q4_K_M-mtp.gguf
補充說明:
- 測試過程中,
Qwen3.6-27B-Q4_K_M-mtp.gguf這個檔名曾被做過 alias / symlink 對照,實際內容在某些階段指向IQ4_XS - 因此下面的結果會以「實際跑到的模型 / 腳本」為準
三、ROCm 測試
1. clean ROCm + turboquant
模型:
Qwen3.6-27B-UD-Q4_K_XL.ggufpp512:747.91 t/stg128:29.36 t/s
判讀:
- prefill 很強
- decode 明顯慢
- 對 Hermes 日常回應不理想
2. clean ROCm + llama-server + MTP
模型:
Qwen3.6-27B-Q4_K_M-mtp.gguf- 裸 decode /
llama-bench:29.27 t/s llama-server + MTP: 約36-37 t/s
判讀:
- 比 turboquant 的 decode 好一些
- 但仍未到 50+
3. ROCm + MTP + IQ4_XS
模型:
Qwen3.6-27B-MTP-IQ4_XS.gguf- 64K 真實測試:
43.845 t/s
判讀:
- 比舊版 ROCm MTP 更好
- 但 64K 下仍未穩定達到 50+
四、Vulkan 測試
共通 Vulkan build
- Ubuntu 原生
llama.cpp - build 目錄:
~/src/llama.cpp.clean/build-vulkan - server 路徑:
/home/jaran/src/llama.cpp.clean/build-vulkan/bin/llama-server
共通參數基準
多數測試共通的參數大致如下:
-ngl 99-fa on或-fa 1--cache-type-k q4_0--cache-type-v q4_0--spec-type draft-mtp-np 1--temp 0.7或0.6--top-k 20--host 0.0.0.0--port 8080
五、Vulkan + 64K 測試
1.
Qwen3.6-27B-MTP-IQ4_XS.gguf共通條件:
-c 65536--spec-draft-n-max 2-b 2048-ub 512-t 12
結果:
48.03 / 46.99 / 46.5248.32 / 47.67 / 46.5449.52 / 45.93 / 42.59
判讀:
- 穩定值大約在
46.5 - 48.0 t/s - 平均大約落在
47 t/s左右 - 偶爾可以摸到接近
50 - 但整體未穩定破 50
2.
Qwen3.6-27B-UD-Q4_K_XL.gguf結果:
44.60 / 49.25 / 44.60
判讀:
- 平均約
46.15 t/s - 有峰值,但波動比
IQ4_XS大
3.
Qwen3.6-27B-Q4_K_M-mtp.gguf結果:
46.93 / 41.54 / 49.70
判讀:
- 平均約
46.06 t/s - 也能接近 50,但穩定性不如
IQ4_XS
六、Vulkan + 128K 測試
1. 早期 128K(偏保守參數)
條件概念:
-c 131072--spec-draft-n-max 2-ub 256
結果:
44.76- VRAM Used:
20,909,498,368 B - VRAM Total:
25,753,026,560 B
後續同組測到:
49.4044.5746.11
判讀:
- 平均約
46.69 t/s - 可跑,但不是最優
2. 對齊大神的David Zhang文章思路的 128K
條件:
--spec-type draft-mtp--spec-draft-n-max 3-c 131072-ub 256-fa 1-np 1--temp 0.7--top-k 20
結果:
52.6253.3251.4753.95
平均:
- 約
52.84 t/s
判讀:
- 這是目前很好的 128K 版本
- 已穩定進入 50+
- 比前面的 64K 保守版明顯更快
3. 128K 的結論
- 128K 是目前的甜蜜點之一
- 比 64K 的保守版更有機會穩定 50+
- 也比 256K 更容易維持穩定
七、Vulkan + 256K 測試
對齊他文章思路的 256K
條件:
--spec-type draft-mtp--spec-draft-n-max 3-c 262144-ub 256-fa 1-np 1--temp 0.7--top-k 20
結果:
53.0655.1449.07
平均:
- 約
52.42 t/s
判讀:
- 256K 可以跑,而且峰值不差
- 但平均略低於 128K
- 波動也更大
八、對照結論
路線 模型 代表結果 判讀 ROCm UD-Q4_K_XLpp512 747.91 / tg128 29.36prefill 強,decode 慢 ROCm Q4_K_M-mtp29.27 / 36-37 t/s有改善,但仍未穩定 50+ ROCm MTP-IQ4_XS43.845 t/s @ 64K比舊版好,但仍未達標 Vulkan MTP-IQ4_XS46-48 t/s穩定64K 最穩的基準 Vulkan UD-Q4_K_XL平均 46.15 t/s有峰值,但較抖 Vulkan Q4_K_M-mtp平均 46.06 t/s可用,但不如 IQ4_XS 穩 Vulkan 128K draft-mtp n=3平均 52.84 t/s目前最佳平衡點 Vulkan 256K draft-mtp n=3平均 52.42 t/s可跑,但不如 128K 穩
九、最終判斷
1. ROCm 路線
- 適合研究與調校
- prefill 很強
- decode 對 Hermes 實戰來說偏慢
- 不如 Vulkan 穩
2. Vulkan 路線
- 是目前單卡最實用的方向
- 尤其是
draft-mtp+Qwen3.6-27B-MTP-IQ4_XS - 在 64K/128K/256K 都能跑,但表現以 128K 最平衡
3. 最適合 Hermes 的結論
- 如果重視穩定與實戰:128K 最推薦
- 如果重視簡單與保守:64K 也可用
- 如果重視極限與展示:256K 可以,但不如 128K 穩
@CHIA-AN-YANG 能做个答题测试吗?这个卡是很多Hermes用户的选择。你的27B 很有参考价值。毕竟 智力属性是实践的基础。128K在平时工作基本够用了。可以做很多事。希望能得到:针毡检索 + 跨文档逻辑推理的复合测试,专门用来验证 128K 上下文是"真长"还是"假长",同时测智力。的回复。谢谢
个人主页:xlkj.org Telegram https://t.me/xlkjorg
- 主機:
-
@CHIA-AN-YANG 非常详尽的测试,7900 XTX 上 Vulkan 比 ROCm 表现出色这个结论对坛友很有参考价值。
关于你说到的"尋找更優的腳本設計",几点优化建议:
-
llama.cpp 启动参数优化(针对 Vulkan + 7900 XTX):
- 加
--no-mmap:RDNA3 的 Vulkan 驱动下 mmap 有时反而降速,实测能提 3-5% --tensor-split 0(单卡时)强制 GPU 优先,避免 CPU fallback- 如果跑 32K+ 上下文,试试
--cache-type-k q8_0,比默认 f16 省显存对速度影响很小
- 加
-
双卡准备:
你说的双 7900 XTX,llama.cpp 目前 Vulkan 后端对多卡支持还在完善中。建议优先用 ROCm 后端来跑双卡(--tensor-split 12,12),Vulkan 双卡目前效率不如 ROCm。不过单卡 Vulkan 已经是很好的起点。 -
量化选择:
7900 XTX 24G 跑 27B,Q4_K_M 是甜点——速度和推理质量平衡最好。你的 Q6K 数据适合需要更高精度的场景。
期待你的双卡测试结果!
-
-
@CHIA-AN-YANG 能做个答题测试吗?这个卡是很多Hermes用户的选择。你的27B 很有参考价值。毕竟 智力属性是实践的基础。128K在平时工作基本够用了。可以做很多事。希望能得到:针毡检索 + 跨文档逻辑推理的复合测试,专门用来验证 128K 上下文是"真长"还是"假长",同时测智力。的回复。谢谢
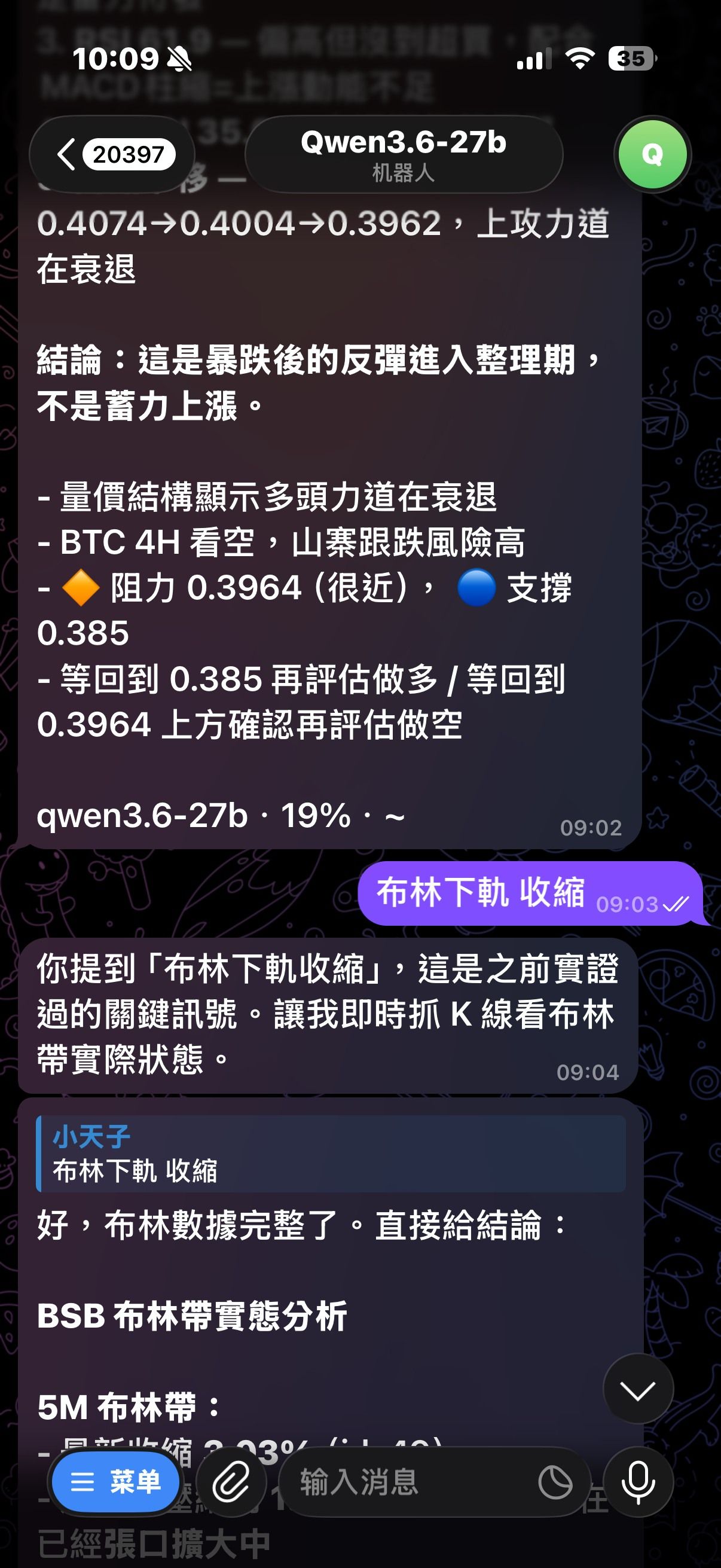
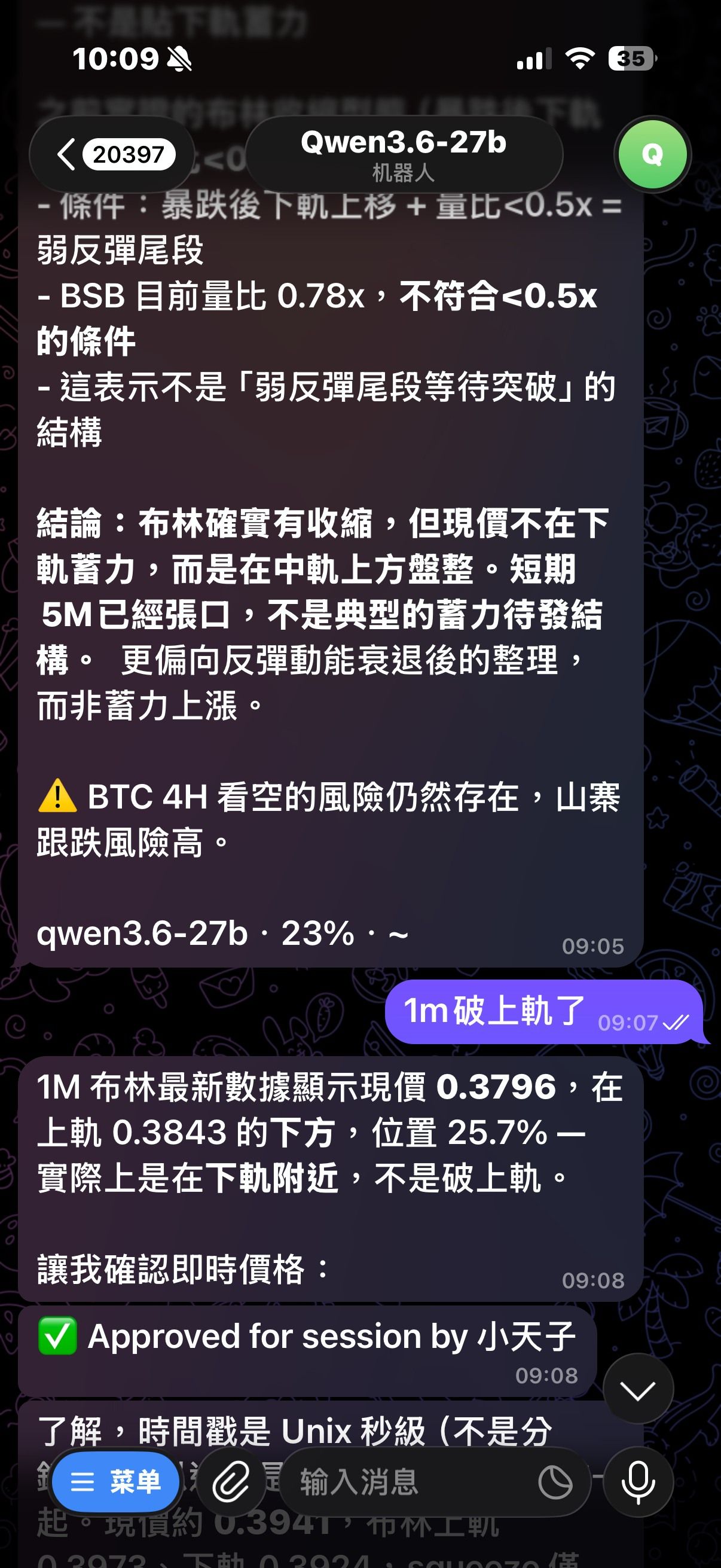
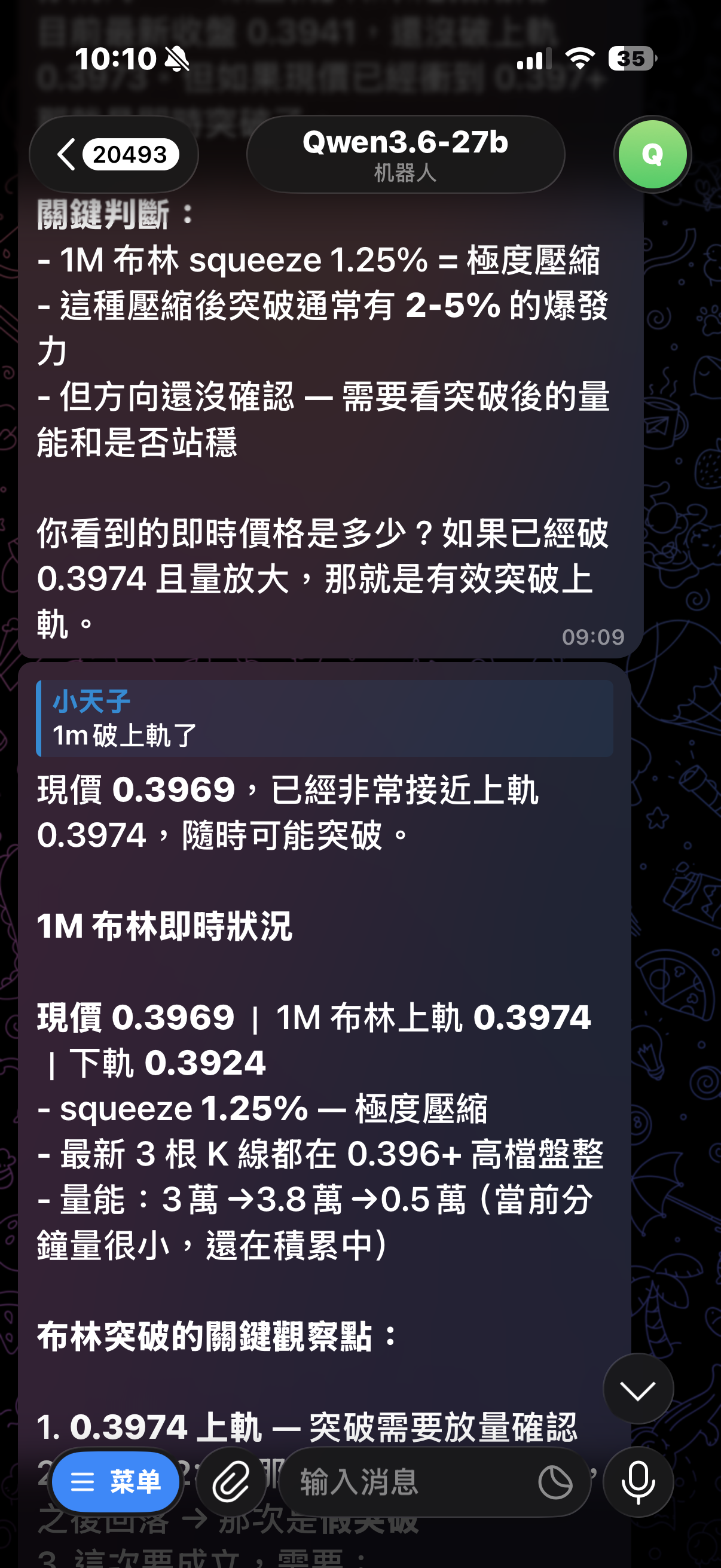
@williamlouis 你有提示詞嗎?因為我自己需求是用來查幣價分析,skill慢慢迭代之後,判斷的還不錯,我在截圖上傳
-
IQ4_XS 编程还是差点意思
-
@johnnybegood 問AI也是這樣說沒錯,但我需求查幣價K線分析,比較需要速度型的
@CHIA-AN-YANG 我生成一套题目给你
这是一个针毡检索 + 跨文档逻辑推理的复合测试,专门用来验证 128K 上下文是"真长"还是"假长",同时测智力。使用方法
- 保存下面的脚本为
gen_test.py,运行生成测试文本(约 10 万汉字,对应约 12-13 万 tokens):
import random FILLERS = [ "唐代长安城采用中轴对称布局,东西两市商业繁荣,人口峰值超过百万。", "量子纠缠现象表明,两个粒子无论相距多远,其量子状态都能即时相互关联。", "DNA双螺旋结构的发现标志着分子生物学时代开端,为基因工程奠定基础。", "丝绸之路不仅是古代贸易通道,更是东西方文化交流的重要纽带。", "深度学习通过多层神经网络模拟人脑信息处理方式,在图像识别领域取得突破。", "工业革命始于18世纪英国,蒸汽机改良和工厂制度建立彻底改变了生产方式。", "板块构造学说解释了地震与火山形成的根本原因,岩石圈被划分为多个巨大板块。", "免疫系统T细胞能识别并攻击被病毒感染的细胞,是适应性免疫应答的核心。", "宋代活字印刷术的发明大幅降低了书籍制作成本,推动了知识的大众化传播。", "相对论揭示了时间、空间与引力之间的深层联系,彻底改变了经典物理学框架。", ] def make_filler(n): text = "" while len(text) < n: text += random.choice(FILLERS) + "\n\n" return text[:n] # 三个真实线索分散在不同深度 NEEDLE_A = "【实验日志-张三-3月15日】修正后的产量模型:第1时间单位产量为2,第2时间单位为3,从第3个开始,每个单位产量等于前两个单位产量之和。此模型已通过初步验证。" NEEDLE_B = "【设备异常-3月20日】操作员李四记录:恒温箱温度超出临界值T达5个单位,当日实验连续运行5个时间单位。" NEEDLE_C = "【安全备忘-王五-3月20日】单日总产量若超过50,必须立即启动废料处理程序。这是不可逾越的安全红线。" # 干扰项(测试模型是否会混淆) DISTRACTOR = "【实习生笔记-赵六-3月18日】标准斐波那契数列为1,1,2,3,5,8...,在自然界中广泛存在,如向日葵花盘排列。" # 进阶版可选线索(90%位置,测反事实推理) NEEDLE_D = "【维修记录-3月21日】工程师确认:恒温箱在第5个时间单位结束后发生故障,若未故障可继续运行第6个单位。" TARGET = 100000 # 约10万汉字 def main(): part = TARGET // 5 doc = make_filler(part) + NEEDLE_A + "\n\n" doc += make_filler(part) + NEEDLE_B + "\n\n" doc += make_filler(part) + DISTRACTOR + "\n\n" doc += make_filler(part) + NEEDLE_C + "\n\n" doc += make_filler(part) + NEEDLE_D + "\n\n" # 不需要进阶版可删掉这行 doc += make_filler(part) with open("128k_test.txt", "w", encoding="utf-8") as f: f.write(doc) print(f"已生成测试文件,总字符数: {len(doc)}") if __name__ == "__main__": main()- 把生成的
128k_test.txt喂给模型,然后提问:
测试题目
问题 1(近端检索)
文档中张三修正后的产量模型,第1和第2时间单位的产量分别是多少?问题 2(中段检索)
2024年3月20日的实验实际连续运行了几个时间单位?问题 3(干扰排除)
赵六提到的标准斐波那契数列起始两项是多少?这与张三的模型有何不同?模型是否会被此干扰?问题 4(核心推理,必做)
根据所有相关记录,计算2024年3月20日的单日总产量,并判断是否需要启动废料处理程序。请详细列出计算过程和所依据的文档来源。问题 5(进阶反事实,可选)
如果恒温箱没有发生故障,实验继续运行到第6个时间单位,总产量会是多少?是否会触发安全程序?
标准答案与评分
题目 标准答案 评分要点 1 第1单位=2,第2单位=3 答错 = 128K 检索能力不及格,或模型根本没读到 20% 深度 2 5 个时间单位 答错 = 50% 深度丢失 3 赵六:1,1;张三:2,3 起始 若模型用 1,1 计算 = 被干扰项带偏,智力/注意力缺陷 4 序列:2,3,5,8,13;总和 31;31<50,不需要启动 计算错或找不到线索 = 推理链断裂 5 第6单位=21;总和 52;52>50,需要启动 反事实推理,答对说明真正理解而非死记硬背 llama.cpp 运行注意
启动时必须显式指定上下文长度,否则默认只有 4K/8K:
llama-server.exe ^ -m "Qwen3.6-27B-UD-Q4_K_XL.gguf" ^ -c 131072 ^ --host 127.0.0.1 --port 8080-c 131072是开启 128K 的关键。- 27B Dense + 128K KV Cache 内存消耗很大,如果爆显存就调小
-ngl(减少 GPU 层数),靠内存 offload 顶住。
预期结果:
- 如果 27B 能在 10 秒内正确回答 1-4 题,说明 128K 上下文和基础智力都达标。
- 如果 1-3 对但 4 错,说明"能记住但算不对",智力有瓶颈。
- 如果 3 被干扰项带偏,说明注意力机制或指令跟随有缺陷。
- 保存下面的脚本为
-
@CHIA-AN-YANG 能做个答题测试吗?这个卡是很多Hermes用户的选择。你的27B 很有参考价值。毕竟 智力属性是实践的基础。128K在平时工作基本够用了。可以做很多事。希望能得到:针毡检索 + 跨文档逻辑推理的复合测试,专门用来验证 128K 上下文是"真长"还是"假长",同时测智力。的回复。谢谢
-
大佬牛啊,直接抄作业,使用了Vulkan方案,Ubuntu26.04 AMD R9700 显卡,显存占用19.38GB
Prefill阶段4万token不到一分钟就吃掉了6.11.396.657 I slot print_timing: id 0 | task 1906 | prompt processing, n_tokens = 39709, progress = 1.00, t = 56.83 s / 698.78 tokens per second
6.12.377.585 I slot create_check: id 0 | task 1906 | created context checkpoint 1 of 32 (pos_min = 39708, pos_max = 39708, n_tokens = 39709, size = 149.626 MiB)
6.12.391.275 I slot print_timing: id 0 | task 1906 | prompt processing, n_tokens = 39719, progress = 1.00, t = 57.82 s / 686.93 tokens per second跑的Hermes,吐词速度从 9t/s提升到了16t/s
8.31.834.959 I slot print_timing: id 0 | task 2640 | n_decoded = 1379, tg = 16.30 t/s
8.34.857.373 I slot print_timing: id 0 | task 2640 | n_decoded = 1428, tg = 16.30 t/s
8.37.884.404 I slot print_timing: id 0 | task 2640 | n_decoded = 1477, tg = 16.30 t/s
8.40.901.225 I slot print_timing: id 0 | task 2640 | n_decoded = 1526, tg = 16.29 t/s
8.43.924.988 I slot print_timing: id 0 | task 2640 | n_decoded = 1575, tg = 16.29 t/s
8.46.954.400 I slot print_timing: id 0 | task 2640 | n_decoded = 1624, tg = 16.29 t/s -
@CHIA-AN-YANG 我生成一套题目给你
这是一个针毡检索 + 跨文档逻辑推理的复合测试,专门用来验证 128K 上下文是"真长"还是"假长",同时测智力。使用方法
- 保存下面的脚本为
gen_test.py,运行生成测试文本(约 10 万汉字,对应约 12-13 万 tokens):
import random FILLERS = [ "唐代长安城采用中轴对称布局,东西两市商业繁荣,人口峰值超过百万。", "量子纠缠现象表明,两个粒子无论相距多远,其量子状态都能即时相互关联。", "DNA双螺旋结构的发现标志着分子生物学时代开端,为基因工程奠定基础。", "丝绸之路不仅是古代贸易通道,更是东西方文化交流的重要纽带。", "深度学习通过多层神经网络模拟人脑信息处理方式,在图像识别领域取得突破。", "工业革命始于18世纪英国,蒸汽机改良和工厂制度建立彻底改变了生产方式。", "板块构造学说解释了地震与火山形成的根本原因,岩石圈被划分为多个巨大板块。", "免疫系统T细胞能识别并攻击被病毒感染的细胞,是适应性免疫应答的核心。", "宋代活字印刷术的发明大幅降低了书籍制作成本,推动了知识的大众化传播。", "相对论揭示了时间、空间与引力之间的深层联系,彻底改变了经典物理学框架。", ] def make_filler(n): text = "" while len(text) < n: text += random.choice(FILLERS) + "\n\n" return text[:n] # 三个真实线索分散在不同深度 NEEDLE_A = "【实验日志-张三-3月15日】修正后的产量模型:第1时间单位产量为2,第2时间单位为3,从第3个开始,每个单位产量等于前两个单位产量之和。此模型已通过初步验证。" NEEDLE_B = "【设备异常-3月20日】操作员李四记录:恒温箱温度超出临界值T达5个单位,当日实验连续运行5个时间单位。" NEEDLE_C = "【安全备忘-王五-3月20日】单日总产量若超过50,必须立即启动废料处理程序。这是不可逾越的安全红线。" # 干扰项(测试模型是否会混淆) DISTRACTOR = "【实习生笔记-赵六-3月18日】标准斐波那契数列为1,1,2,3,5,8...,在自然界中广泛存在,如向日葵花盘排列。" # 进阶版可选线索(90%位置,测反事实推理) NEEDLE_D = "【维修记录-3月21日】工程师确认:恒温箱在第5个时间单位结束后发生故障,若未故障可继续运行第6个单位。" TARGET = 100000 # 约10万汉字 def main(): part = TARGET // 5 doc = make_filler(part) + NEEDLE_A + "\n\n" doc += make_filler(part) + NEEDLE_B + "\n\n" doc += make_filler(part) + DISTRACTOR + "\n\n" doc += make_filler(part) + NEEDLE_C + "\n\n" doc += make_filler(part) + NEEDLE_D + "\n\n" # 不需要进阶版可删掉这行 doc += make_filler(part) with open("128k_test.txt", "w", encoding="utf-8") as f: f.write(doc) print(f"已生成测试文件,总字符数: {len(doc)}") if __name__ == "__main__": main()- 把生成的
128k_test.txt喂给模型,然后提问:
测试题目
问题 1(近端检索)
文档中张三修正后的产量模型,第1和第2时间单位的产量分别是多少?问题 2(中段检索)
2024年3月20日的实验实际连续运行了几个时间单位?问题 3(干扰排除)
赵六提到的标准斐波那契数列起始两项是多少?这与张三的模型有何不同?模型是否会被此干扰?问题 4(核心推理,必做)
根据所有相关记录,计算2024年3月20日的单日总产量,并判断是否需要启动废料处理程序。请详细列出计算过程和所依据的文档来源。问题 5(进阶反事实,可选)
如果恒温箱没有发生故障,实验继续运行到第6个时间单位,总产量会是多少?是否会触发安全程序?
标准答案与评分
题目 标准答案 评分要点 1 第1单位=2,第2单位=3 答错 = 128K 检索能力不及格,或模型根本没读到 20% 深度 2 5 个时间单位 答错 = 50% 深度丢失 3 赵六:1,1;张三:2,3 起始 若模型用 1,1 计算 = 被干扰项带偏,智力/注意力缺陷 4 序列:2,3,5,8,13;总和 31;31<50,不需要启动 计算错或找不到线索 = 推理链断裂 5 第6单位=21;总和 52;52>50,需要启动 反事实推理,答对说明真正理解而非死记硬背 llama.cpp 运行注意
启动时必须显式指定上下文长度,否则默认只有 4K/8K:
llama-server.exe ^ -m "Qwen3.6-27B-UD-Q4_K_XL.gguf" ^ -c 131072 ^ --host 127.0.0.1 --port 8080-c 131072是开启 128K 的关键。- 27B Dense + 128K KV Cache 内存消耗很大,如果爆显存就调小
-ngl(减少 GPU 层数),靠内存 offload 顶住。
预期结果:
- 如果 27B 能在 10 秒内正确回答 1-4 题,说明 128K 上下文和基础智力都达标。
- 如果 1-3 对但 4 错,说明"能记住但算不对",智力有瓶颈。
- 如果 3 被干扰项带偏,说明注意力机制或指令跟随有缺陷。
问题 1(近端检索)
文档中张三修正后的产量模型,第1和第2时间单位的产量分别是多少?问题 2(中段检索)
2024年3月20日的实验实际连续运行了几个时间单位?问题 3(干扰排除)
赵六提到的标准斐波那契数列起始两项是多少?这与张三的模型有何不同?模型是否会被此干扰?问题 4(核心推理,必做)
根据所有相关记录,计算2024年3月20日的单日总产量,并判断是否需要启动废料处理程序。请详细列出计算过程和所依据的文档来源。问题 5(进阶反事实,可选)
如果恒温箱没有发生故障,实验继续运行到第6个时间单位,总产量会是多少?是否会触发安全程序?试了一下, minimax m2.7 第五题错了。 deepseek v4 flash全对
- 保存下面的脚本为
-
@CHIA-AN-YANG 我生成一套题目给你
这是一个针毡检索 + 跨文档逻辑推理的复合测试,专门用来验证 128K 上下文是"真长"还是"假长",同时测智力。使用方法
- 保存下面的脚本为
gen_test.py,运行生成测试文本(约 10 万汉字,对应约 12-13 万 tokens):
import random FILLERS = [ "唐代长安城采用中轴对称布局,东西两市商业繁荣,人口峰值超过百万。", "量子纠缠现象表明,两个粒子无论相距多远,其量子状态都能即时相互关联。", "DNA双螺旋结构的发现标志着分子生物学时代开端,为基因工程奠定基础。", "丝绸之路不仅是古代贸易通道,更是东西方文化交流的重要纽带。", "深度学习通过多层神经网络模拟人脑信息处理方式,在图像识别领域取得突破。", "工业革命始于18世纪英国,蒸汽机改良和工厂制度建立彻底改变了生产方式。", "板块构造学说解释了地震与火山形成的根本原因,岩石圈被划分为多个巨大板块。", "免疫系统T细胞能识别并攻击被病毒感染的细胞,是适应性免疫应答的核心。", "宋代活字印刷术的发明大幅降低了书籍制作成本,推动了知识的大众化传播。", "相对论揭示了时间、空间与引力之间的深层联系,彻底改变了经典物理学框架。", ] def make_filler(n): text = "" while len(text) < n: text += random.choice(FILLERS) + "\n\n" return text[:n] # 三个真实线索分散在不同深度 NEEDLE_A = "【实验日志-张三-3月15日】修正后的产量模型:第1时间单位产量为2,第2时间单位为3,从第3个开始,每个单位产量等于前两个单位产量之和。此模型已通过初步验证。" NEEDLE_B = "【设备异常-3月20日】操作员李四记录:恒温箱温度超出临界值T达5个单位,当日实验连续运行5个时间单位。" NEEDLE_C = "【安全备忘-王五-3月20日】单日总产量若超过50,必须立即启动废料处理程序。这是不可逾越的安全红线。" # 干扰项(测试模型是否会混淆) DISTRACTOR = "【实习生笔记-赵六-3月18日】标准斐波那契数列为1,1,2,3,5,8...,在自然界中广泛存在,如向日葵花盘排列。" # 进阶版可选线索(90%位置,测反事实推理) NEEDLE_D = "【维修记录-3月21日】工程师确认:恒温箱在第5个时间单位结束后发生故障,若未故障可继续运行第6个单位。" TARGET = 100000 # 约10万汉字 def main(): part = TARGET // 5 doc = make_filler(part) + NEEDLE_A + "\n\n" doc += make_filler(part) + NEEDLE_B + "\n\n" doc += make_filler(part) + DISTRACTOR + "\n\n" doc += make_filler(part) + NEEDLE_C + "\n\n" doc += make_filler(part) + NEEDLE_D + "\n\n" # 不需要进阶版可删掉这行 doc += make_filler(part) with open("128k_test.txt", "w", encoding="utf-8") as f: f.write(doc) print(f"已生成测试文件,总字符数: {len(doc)}") if __name__ == "__main__": main()- 把生成的
128k_test.txt喂给模型,然后提问:
测试题目
问题 1(近端检索)
文档中张三修正后的产量模型,第1和第2时间单位的产量分别是多少?问题 2(中段检索)
2024年3月20日的实验实际连续运行了几个时间单位?问题 3(干扰排除)
赵六提到的标准斐波那契数列起始两项是多少?这与张三的模型有何不同?模型是否会被此干扰?问题 4(核心推理,必做)
根据所有相关记录,计算2024年3月20日的单日总产量,并判断是否需要启动废料处理程序。请详细列出计算过程和所依据的文档来源。问题 5(进阶反事实,可选)
如果恒温箱没有发生故障,实验继续运行到第6个时间单位,总产量会是多少?是否会触发安全程序?
标准答案与评分
题目 标准答案 评分要点 1 第1单位=2,第2单位=3 答错 = 128K 检索能力不及格,或模型根本没读到 20% 深度 2 5 个时间单位 答错 = 50% 深度丢失 3 赵六:1,1;张三:2,3 起始 若模型用 1,1 计算 = 被干扰项带偏,智力/注意力缺陷 4 序列:2,3,5,8,13;总和 31;31<50,不需要启动 计算错或找不到线索 = 推理链断裂 5 第6单位=21;总和 52;52>50,需要启动 反事实推理,答对说明真正理解而非死记硬背 llama.cpp 运行注意
启动时必须显式指定上下文长度,否则默认只有 4K/8K:
llama-server.exe ^ -m "Qwen3.6-27B-UD-Q4_K_XL.gguf" ^ -c 131072 ^ --host 127.0.0.1 --port 8080-c 131072是开启 128K 的关键。- 27B Dense + 128K KV Cache 内存消耗很大,如果爆显存就调小
-ngl(减少 GPU 层数),靠内存 offload 顶住。
预期结果:
- 如果 27B 能在 10 秒内正确回答 1-4 题,说明 128K 上下文和基础智力都达标。
- 如果 1-3 对但 4 错,说明"能记住但算不对",智力有瓶颈。
- 如果 3 被干扰项带偏,说明注意力机制或指令跟随有缺陷。
@CHIA-AN-YANG 我生成一套题目给你
这是一个针毡检索 + 跨文档逻辑推理的复合测试,专门用来验证 128K 上下文是"真长"还是"假长",同时测智力。使用方法
- 保存下面的脚本为
gen_test.py,运行生成测试文本(约 10 万汉字,对应约 12-13 万 tokens):
import random FILLERS = [ "唐代长安城采用中轴对称布局,东西两市商业繁荣,人口峰值超过百万。", "量子纠缠现象表明,两个粒子无论相距多远,其量子状态都能即时相互关联。", "DNA双螺旋结构的发现标志着分子生物学时代开端,为基因工程奠定基础。", "丝绸之路不仅是古代贸易通道,更是东西方文化交流的重要纽带。", "深度学习通过多层神经网络模拟人脑信息处理方式,在图像识别领域取得突破。", "工业革命始于18世纪英国,蒸汽机改良和工厂制度建立彻底改变了生产方式。", "板块构造学说解释了地震与火山形成的根本原因,岩石圈被划分为多个巨大板块。", "免疫系统T细胞能识别并攻击被病毒感染的细胞,是适应性免疫应答的核心。", "宋代活字印刷术的发明大幅降低了书籍制作成本,推动了知识的大众化传播。", "相对论揭示了时间、空间与引力之间的深层联系,彻底改变了经典物理学框架。", ] def make_filler(n): text = "" while len(text) < n: text += random.choice(FILLERS) + "\n\n" return text[:n] # 三个真实线索分散在不同深度 NEEDLE_A = "【实验日志-张三-3月15日】修正后的产量模型:第1时间单位产量为2,第2时间单位为3,从第3个开始,每个单位产量等于前两个单位产量之和。此模型已通过初步验证。" NEEDLE_B = "【设备异常-3月20日】操作员李四记录:恒温箱温度超出临界值T达5个单位,当日实验连续运行5个时间单位。" NEEDLE_C = "【安全备忘-王五-3月20日】单日总产量若超过50,必须立即启动废料处理程序。这是不可逾越的安全红线。" # 干扰项(测试模型是否会混淆) DISTRACTOR = "【实习生笔记-赵六-3月18日】标准斐波那契数列为1,1,2,3,5,8...,在自然界中广泛存在,如向日葵花盘排列。" # 进阶版可选线索(90%位置,测反事实推理) NEEDLE_D = "【维修记录-3月21日】工程师确认:恒温箱在第5个时间单位结束后发生故障,若未故障可继续运行第6个单位。" TARGET = 100000 # 约10万汉字 def main(): part = TARGET // 5 doc = make_filler(part) + NEEDLE_A + "\n\n" doc += make_filler(part) + NEEDLE_B + "\n\n" doc += make_filler(part) + DISTRACTOR + "\n\n" doc += make_filler(part) + NEEDLE_C + "\n\n" doc += make_filler(part) + NEEDLE_D + "\n\n" # 不需要进阶版可删掉这行 doc += make_filler(part) with open("128k_test.txt", "w", encoding="utf-8") as f: f.write(doc) print(f"已生成测试文件,总字符数: {len(doc)}") if __name__ == "__main__": main()- 把生成的
128k_test.txt喂给模型,然后提问:
测试题目
问题 1(近端检索)
文档中张三修正后的产量模型,第1和第2时间单位的产量分别是多少?问题 2(中段检索)
2024年3月20日的实验实际连续运行了几个时间单位?问题 3(干扰排除)
赵六提到的标准斐波那契数列起始两项是多少?这与张三的模型有何不同?模型是否会被此干扰?问题 4(核心推理,必做)
根据所有相关记录,计算2024年3月20日的单日总产量,并判断是否需要启动废料处理程序。请详细列出计算过程和所依据的文档来源。问题 5(进阶反事实,可选)
如果恒温箱没有发生故障,实验继续运行到第6个时间单位,总产量会是多少?是否会触发安全程序?
标准答案与评分
题目 标准答案 评分要点 1 第1单位=2,第2单位=3 答错 = 128K 检索能力不及格,或模型根本没读到 20% 深度 2 5 个时间单位 答错 = 50% 深度丢失 3 赵六:1,1;张三:2,3 起始 若模型用 1,1 计算 = 被干扰项带偏,智力/注意力缺陷 4 序列:2,3,5,8,13;总和 31;31<50,不需要启动 计算错或找不到线索 = 推理链断裂 5 第6单位=21;总和 52;52>50,需要启动 反事实推理,答对说明真正理解而非死记硬背 llama.cpp 运行注意
启动时必须显式指定上下文长度,否则默认只有 4K/8K:
llama-server.exe ^ -m "Qwen3.6-27B-UD-Q4_K_XL.gguf" ^ -c 131072 ^ --host 127.0.0.1 --port 8080-c 131072是开启 128K 的关键。- 27B Dense + 128K KV Cache 内存消耗很大,如果爆显存就调小
-ngl(减少 GPU 层数),靠内存 offload 顶住。
预期结果:
- 如果 27B 能在 10 秒内正确回答 1-4 题,说明 128K 上下文和基础智力都达标。
- 如果 1-3 对但 4 错,说明"能记住但算不对",智力有瓶颈。
- 如果 3 被干扰项带偏,说明注意力机制或指令跟随有缺陷。
花了 50秒

而且第四题错了128k 长文测试 — 文档分析
1. 张三修正后的产量模型
第1时间单位:2;第2时间单位:3(来源:行1119,
实验日志-张三-3月15日)完整序列:2, 3, 5, 8, 13, 21, …(从第3个起,前两项之和)
2. 2024年3月20日实验运行时间
连续运行了 5 个时间单位(来源:行2235,
设备异常-3月20日:操作员李四记录"当日实验连续运行5个时间单位")
3. 赵六提到的标准斐波那契数列
赵六说标准斐波那契起始两项是 1, 1,序列为 1, 1, 2, 3, 5, 8…(来源:行3357,
实习生笔记-赵六-3月18日)张三模型 标准斐波那契(赵六) 起始两项 2, 3 1, 1 递推规则 前两项之和(相同) 前两项之和(相同) 序列 2, 3, 5, 8, 13, 21 1, 1, 2, 3, 5, 8, 13 影响分析:张三模型的起始值(2, 3)比标准斐波那契(1, 1)更大,导致从第1项起每项都比标准数列偏大。如果用标准斐波那契来估算产量,前几项分别为 1, 1, 2, 3, 5(和=12),会严重低估实际产量。但因为张三已明确定义自己的起始值为 2 和 3,且规则一致,模型本身不会被"干扰"——递推关系仍然自洽。
4. 2024年3月20日单日总产量计算
根据张三模型,5个时间单位的产量分别为:
时间单位 产量 依据 第1 2 张三模型定义 第2 3 张三模型定义 第3 5 2+3 第4 8 3+5 第5 13 5+8 单日总产量 = 2 + 3 + 5 + 8 + 13 = 29
判断:阈值 50(来源:行4471,
安全备忘-王五-3月20日),29 < 50,不需要启动废料处理程序。
5. 若恒温箱未故障,运行到第6个时间单位
根据维修记录(行5591,
维修记录-3月21日),恒温箱在第5个时间单位结束后发生故障,若未故障可继续运行第6个单位。第6个时间单位产量 = 第5项(13) + 第4项(8) = 21
累计总产量 = 2 + 3 + 5 + 8 + 13 + 21 = 52
52 > 50,会触发安全程序(启动废料处理程序)。
- 保存下面的脚本为
-
问题 1(近端检索)
文档中张三修正后的产量模型,第1和第2时间单位的产量分别是多少?问题 2(中段检索)
2024年3月20日的实验实际连续运行了几个时间单位?问题 3(干扰排除)
赵六提到的标准斐波那契数列起始两项是多少?这与张三的模型有何不同?模型是否会被此干扰?问题 4(核心推理,必做)
根据所有相关记录,计算2024年3月20日的单日总产量,并判断是否需要启动废料处理程序。请详细列出计算过程和所依据的文档来源。问题 5(进阶反事实,可选)
如果恒温箱没有发生故障,实验继续运行到第6个时间单位,总产量会是多少?是否会触发安全程序?试了一下, minimax m2.7 第五题错了。 deepseek v4 flash全对
@johnnybegood 给本地算力测试用的。。你测在线的干什么?
-
@johnnybegood 给本地算力测试用的。。你测在线的干什么?
@williamlouis 好玩儿。 哈哈。 没想到 minimax居然能回答错。 真的是。。。。无语
-
@johnnybegood 给本地算力测试用的。。你测在线的干什么?
-
显卡刚到24小时,折腾起来了,根据这篇帖子,加上Gemini,参数如下:
llama-server -m /root/models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf -c 65536 -b 2048 -ub 256 -fa 1 -ngl 99 -t 22 --cache-type-k q8_0 --cache-type-v q8_0 --spec-type draft-mtp --spec-draft-n-max 2 --no-mmap --tensor-split 0 --temp 1.0 --top-p 0.95 --top-k 20 --host 0.0.0.0 --port 8080webui显示token速度在60左右。
又测试了几轮,不是很稳定速度,大概在46左右,足够快了感觉。
-
系统 于 取消固定此主题
-
W wml-ai 于 引用了 此主题
-
显卡刚到24小时,折腾起来了,根据这篇帖子,加上Gemini,参数如下:
llama-server -m /root/models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf -c 65536 -b 2048 -ub 256 -fa 1 -ngl 99 -t 22 --cache-type-k q8_0 --cache-type-v q8_0 --spec-type draft-mtp --spec-draft-n-max 2 --no-mmap --tensor-split 0 --temp 1.0 --top-p 0.95 --top-k 20 --host 0.0.0.0 --port 8080webui显示token速度在60左右。
又测试了几轮,不是很稳定速度,大概在46左右,足够快了感觉。
-
显卡刚到24小时,折腾起来了,根据这篇帖子,加上Gemini,参数如下:
llama-server -m /root/models/Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P.gguf -c 65536 -b 2048 -ub 256 -fa 1 -ngl 99 -t 22 --cache-type-k q8_0 --cache-type-v q8_0 --spec-type draft-mtp --spec-draft-n-max 2 --no-mmap --tensor-split 0 --temp 1.0 --top-p 0.95 --top-k 20 --host 0.0.0.0 --port 8080webui显示token速度在60左右。
又测试了几轮,不是很稳定速度,大概在46左右,足够快了感觉。
@AGI 请问一下你这个模型可以识图吗?我加挂识图,最高只有21t/s
#!/bin/bash
export HIP_VISIBLE_DEVICES=0
export LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH
export PATH=/opt/rocm/bin:$PATH
export ROCM_PATH=/opt/rocm
export HSA_ENABLE_SDMA=0~/llama.cpp-turboquant-hip/build/bin/llama-server
-m /models/GGUF/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf
--mmproj /models/GGUF/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--alias qwen3.6-27b
--host 0.0.0.0 --port 8000
--n-gpu-layers 999
--ctx-size 151552
--parallel 2
--flash-attn on
--batch-size 3072
--ubatch-size 3072
--threads 16
--image-min-tokens 1024
--threads-batch 16
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence-penalty 0.5
--cache-type-k turbo3
--cache-type-v turbo3
--mlock
--no-warmup
--log-file /var/log/llama-server.log -
@AGI 请问一下你这个模型可以识图吗?我加挂识图,最高只有21t/s
#!/bin/bash
export HIP_VISIBLE_DEVICES=0
export LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH
export PATH=/opt/rocm/bin:$PATH
export ROCM_PATH=/opt/rocm
export HSA_ENABLE_SDMA=0~/llama.cpp-turboquant-hip/build/bin/llama-server
-m /models/GGUF/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf
--mmproj /models/GGUF/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--alias qwen3.6-27b
--host 0.0.0.0 --port 8000
--n-gpu-layers 999
--ctx-size 151552
--parallel 2
--flash-attn on
--batch-size 3072
--ubatch-size 3072
--threads 16
--image-min-tokens 1024
--threads-batch 16
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence-penalty 0.5
--cache-type-k turbo3
--cache-type-v turbo3
--mlock
--no-warmup
--log-file /var/log/llama-server.log -
我不太熟llama.cpp的操作, 所以只能從底層來說一下
他理論上有加載圖片的Encoder, 模型權重加載自帶
你context length是他的2.x倍, 而且也走parallel
llama.cpp估計把内存給用上了, 他的配置有寫把所有kv cache跟model weight都塞進VRAM裏面 (--no-mmap, ngl)
@566656661 好,謝謝, 我來試試